






1. 项目概述
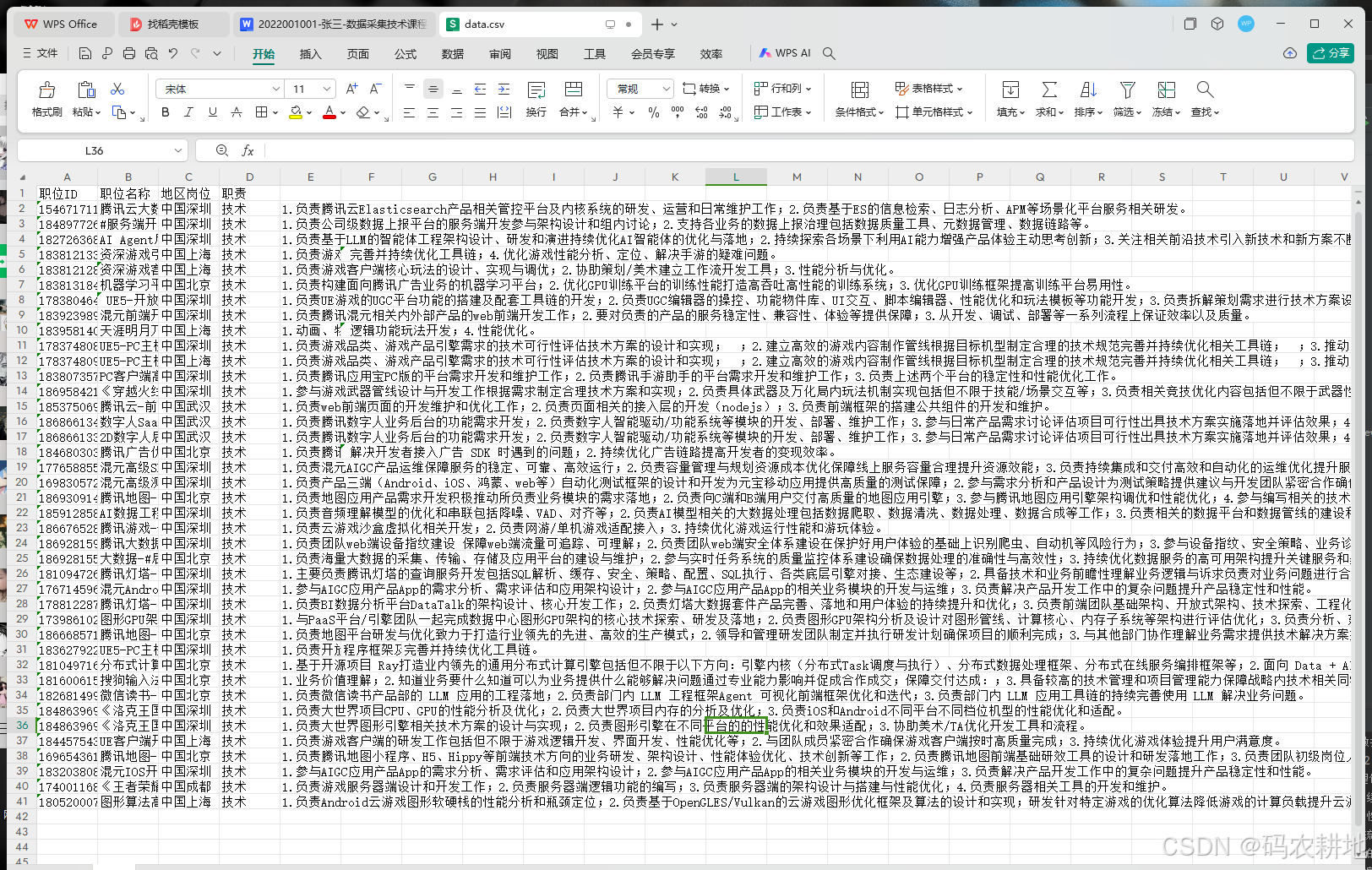
通过对Tecent招聘网站的职位数据进行爬取和解析,成功获取了多个职位的详细信息,并将其存储在本地 data.csv 文件中。每条记录包含职位的核心字段:职位 ID、职位名称、地区、岗位类别及岗位职责。这些数据经过清洗和格式化处理,保证了内容的规范性和可读性。从结果来看,爬取到的数据覆盖了不同地区和类别的职位信息,为全面了解腾讯的招聘需求提供了有效支持。此外,通过分页爬取的方式,确保了数据的完整性,避免遗漏重要信息。这些结果为后续的深入分析奠定了基础,比如职位需求的地区分布、岗位职责的关键词分析以及招聘趋势的可视化等。总体而言,采集到的数据能够充分反映腾讯当前的招聘情况,为相关领域的研究与决策提供了可靠依据。

2. 源码分析
2. 功能概述
该代码实现了以下功能:
- 爬取腾讯招聘官网的职位信息。
- 提取关键信息,如职位ID、名称、工作年限、地区、岗位和职责。
- 将爬取到的数据写入
data.csv文件,供后续分析和可视化使用。
3. 核心代码结构分析
3.1 文件初始化
with open("data.csv", "a+", encoding='utf-8') as f:
f.write(
"职位ID" + "," + "职位名称" + "," + "工作年限" + "," + "地区" + "岗位" + "," + "职责" + "," + '\n')
- 打开(或创建)一个
data.csv文件并添加表头。 - 表头包括:
职位ID、职位名称、工作年限、地区、岗位、职责。
3.2 请求头设置
headers = {
...
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}
- 设置了伪装为浏览器的
User-Agent和其他必要的 HTTP 头字段。 - 主要用于绕过服务器的反爬虫机制。
3.3 URL 和参数定义
url = "url已隐藏"
- 爬取目标 API 的接口地址。
params = {
"timestamp": "1734601759344",
"countryId": "",
# 此处略....1",
...
"pageIndex": "{}".format(i),
"pageSize": "10",
...
}
- 请求参数动态生成:
pageIndex用于分页(爬取多页数据)。- 其他参数如
categoryId和area用于筛选招聘岗位的类别和地区。
3.4 循环请求与数据提取
for i in range(1, 5): # 爬取前4页数据
response = requests.get(url)
res_data = response.json()
- 通过
requests.get发送 HTTP GET 请求,接收 JSON 响应数据。 - 提取响应数据并解析。
3.5 数据校验与处理
if res_data["Code"] == 200: # 检查响应状态码
data = res_data["Data"]["Posts"]
for msg in data:
post_id = msg["PostId"]
post_title = msg["RecruitPostName"]
RequireWorkYearsName = msg["RequireWorkYearsName"]
...
- 检查返回的状态码是否为
200(成功)。 - 从响应数据中提取关键字段:
PostId:职位ID。RecruitPostName:职位名称。RequireWorkYearsName:工作年限要求。CountryName和LocationName:地区信息。CategoryName:岗位类别。Responsibility:岗位职责。
3.6 数据写入
- 将提取到的字段以 CSV 格式追加到
data.csv文件中。 responsibility中替换了换行符和逗号,确保 CSV 格式不被破坏。
4. 功能亮点
- 数据格式化:
- 数据经过清洗(例如去掉职责中的换行符)后以 CSV 格式保存,便于后续分析和可视化。
- 分页爬取:
- 动态调整
pageIndex参数,实现多页数据的自动爬取。
- 动态调整
- 健壮性检查:
- 通过状态码
200校验接口响应,避免无效数据写入。
- 通过状态码
5. 改进建议
-
异常处理:
- 为网络请求和文件写入增加异常捕获,防止程序因网络问题或文件问题中断。
try: response = requests.get(url) response.raise_for_status() # 检查HTTP请求状态 except requests.exceptions.RequestException as e: print(f"请求失败:{e}") -
数据去重:
- 在写入前检查是否已存在相同记录,避免重复数据。
-
并发爬取:
- 使用
asyncio或threading实现并发爬取,提升效率。
- 使用
-
数据可视化:
- 读取
data.csv,使用pandas和matplotlib等工具进行分析和可视化。
- 读取



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









