






神经细胞
在当今的数字时代,神经网络已经成为许多领域的研究和应用的焦点。从语音识别到图像处理,从自然语言处理到智能推荐系统,神经网络的应用无处不在。它们仿佛是人工智能的魔法,能够模拟人类大脑的工作方式,从无序的数据中提取出有意义的信息。那么,究竟什么是神经网络?它是如何工作的?让我们一起去探索这个神秘而又令人着迷的世界。
科学技术的发展总是循序渐进的,对于上述复杂的问题也需要从最简单地方入手。为了故事顺利的发展,随机给出一张猩猩的图片用来识别。(因为下文会用到此图,暂且我叫它Caesar 中文名称:凯撒 )

我们之所以能一眼看出照片是只猩猩,属于动物类别,是因为我们大脑神经细胞中存有类似的"记忆"。大量类似的神经细胞相互作用,能让我们清楚的识别出图片的内容。在下"神笔马良"附体,画出了神经细胞结构。
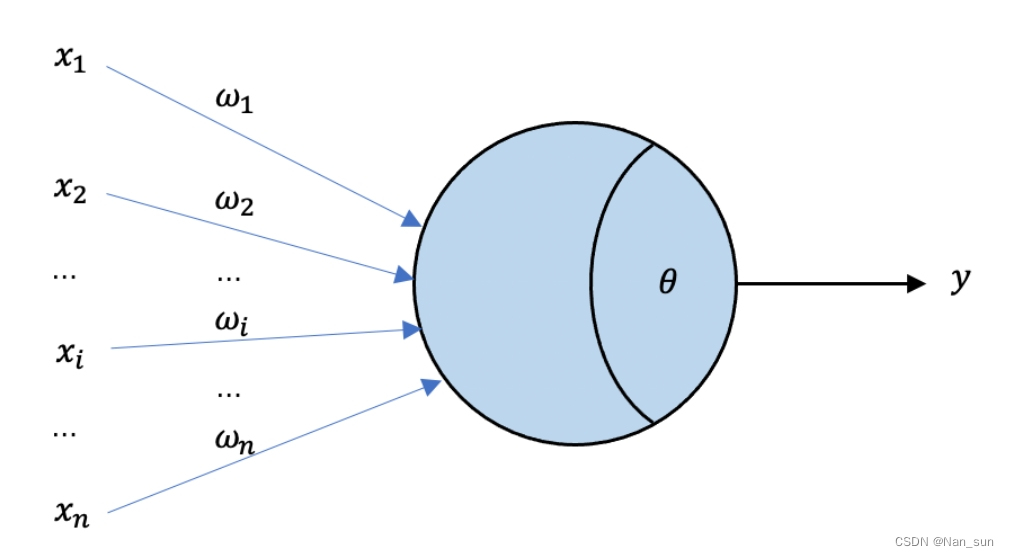
、
、
、
代表其他神经细胞。
- 蓝色的圆球状是神经细胞体。
尚且理解成细胞体内的一个”过滤器“ 吧,主要是用来影响细胞的”反应“y。
- w 代表树突,是神经细胞用来接收周围神经细胞产生"反应"的信息(相当于y)的通道 (尚且这么理解,稍后会对w作详细的介绍)
- y代表当前神经细胞"反应"。
- 图片信号经过神经细胞
、
、
、
的处理后传递给了蓝色神经细胞,蓝色细胞接收输入信号后发出了"反应"信号
,然后继续影响其他的神经细胞。大量的神经细胞相互作用,最终某些神经细胞得出图片的内容。
请记住上述所讲到的神经细胞的结构以及图片的处理流程,接下来我们将在计算机中实现!!!
小贴士:
站在生物学的角度,上述的结构以及理论看似是胡说八道,实际上确实如此。但是对于理解下文却起着至关重要的作用。我们可以抛开医学理论,暂时相信上述理论。
神经元
计算机虽然没有细胞,但是我们可以使用数学描述出一个神经细胞。为了区分生物学中的细胞,我们对此称之为神经元。
小贴士:
如果您还未获取到小学毕业证,那么接下来的部分可能并不适合您。还请出门右转(www.baidu.com)搜索小学数学课。
这个函数应该再熟悉不过了。如果我们将
看成一个神经细胞,如下图:
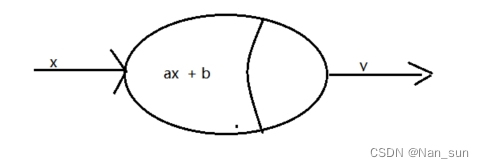
小贴士:
这里为什么要用并不是因为真实的业务场景使用的是此函数,只是单纯的大家都认识这个函数而已。稍后我们会接触一些常见的函数来代替
。为了更好的描述此版本的神经元,暂且我们叫它 ”第一个版本的神经元“。
上图是我们自创的神经元,虽然看起来很简单,其实一点也不复杂。在不讨论的实际效果的前提下,此神经元的结果优点在于足够的简单。但是缺点也很明显,
- 只能接受一个输入参数。然而"第一版神经细胞"可以接收多个输入。
的输入没有经过任何的操作直接传递给了神经元,然而"第一版神经细胞"经过了不同的
处理后在传递给神经元
如何修改成接受多个输入,那么神经元内的函数
则不能在使用,因为不知道写什么,所以暂时先空着。那么再次修改神经元结构如下图:
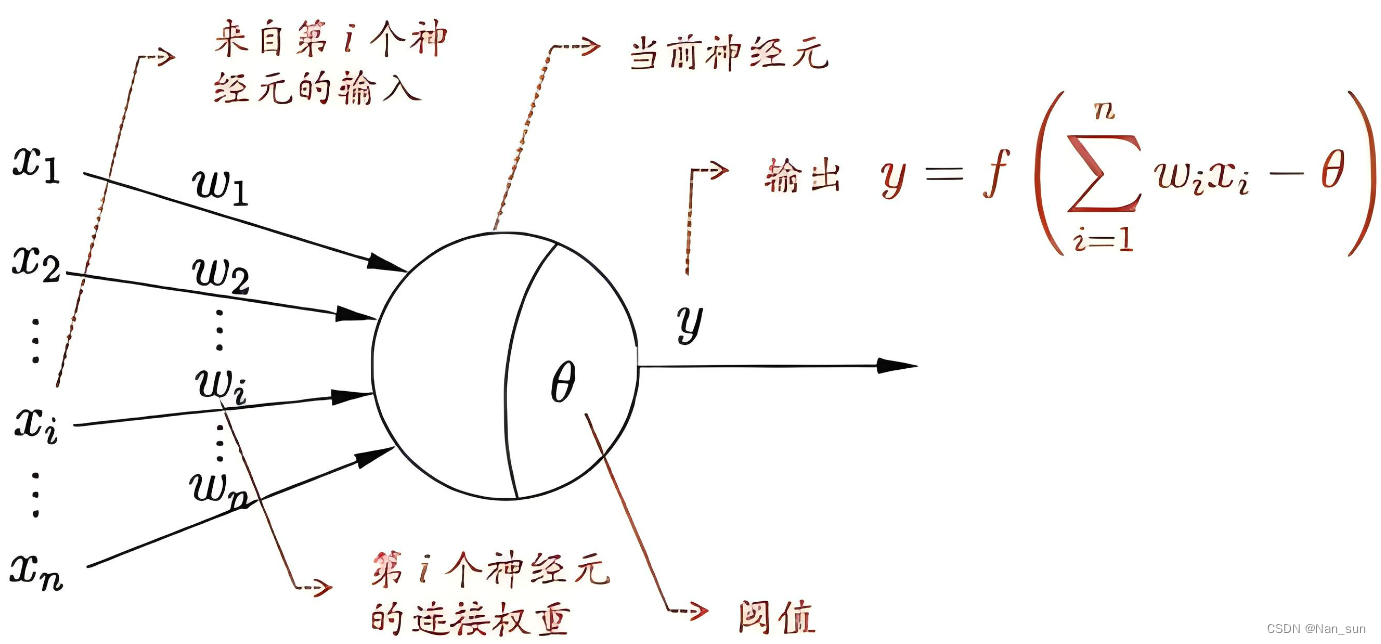
- 上一版本的神经元函数为
,
表示将输入
是一种结果,
是另外一种结果。
小贴士:
现在的神经元已经可以接收多个输入,而且
和
图像处理
有了M-P神经元,那么我们就可以去识别图片了。但是如何将图片输入给神经元呢?这里有两个问题需要解决。
- M-P神经元中的
- 一张图片怎样才能转换成
在 ”机器的神经细胞-神经元“的章节中提到过,机器的神经细胞结构是采用数学的方式进行描述。所以神经元的输入、
、
、
理所应当是数字、向量、函数 等数学领域的概念。知道了神经元的输入,接下来就是解决如何将一张图片转换成数字、向量等数学表示。
图像预处理
图像预处理是一个比较复杂的过程。由于篇幅有限,这里不对图片做任何的处理。就是用原图片!!!! 小男孩1995会在后续的博客文章中详细讲解如何对数据进行预处理。
通道分离
要想将图片数字化,我们首先需要简单了解一下图片像素的着色原理。很多人会有疑问,将图片数字化与像素有什么关系?其实将图片转换成数字的过程就是计算出每个像素颜色的值。
对于我们工作中所接触到最多的图片格式有.png、.jpg等。他们属于位图,也称为点阵图像或栅格图像,是一种由像素组成的图像。
可以简单的理解成图片是由一个一个像素点组成,每个像素点有不同的颜色。这些带有颜色的像素点按照一定的顺序排列就能展现出我们看到的图片内容。
小学自然与科学课本上写着红绿蓝是三基色,大自然中绝大多数的颜色都可以通过三种颜色按照指定的比例混合而成。因此这里我们将三种颜色分别用三个字母来代替:R(red)G(green)B(blue)。
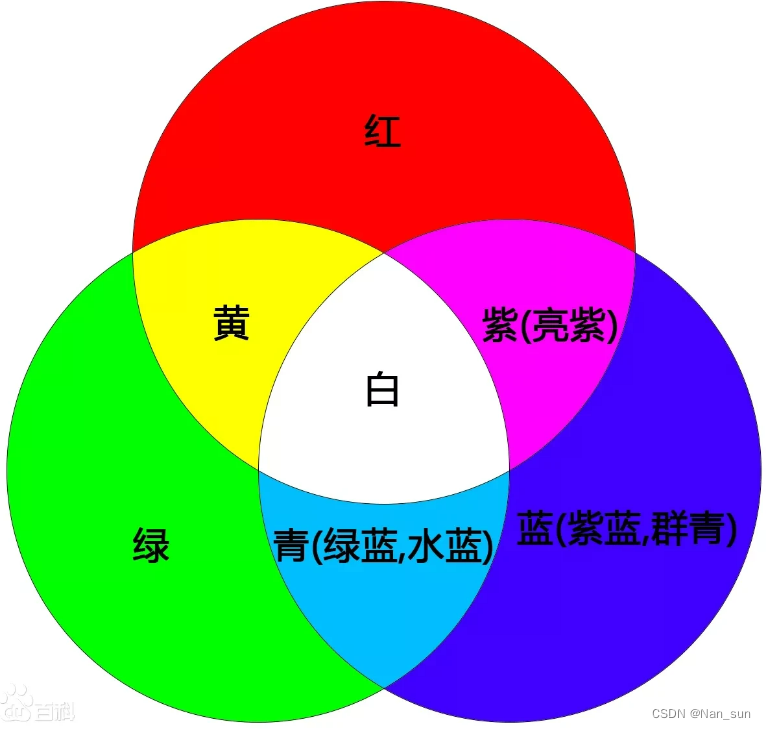
RGB三色是用8个数(00000000 ~ 11111111)表示颜色的值,故有256个级别。其实最高是0-255,0代表全白,255代表全黑。
三通道是指通过将一幅彩色图像分解成红、绿、蓝三个颜色通道,每个通道都包含了该颜色在原始图像中的亮度信息。这三个通道叠在一起便构成了一个完整的彩色图像。
例如凯撒图片中
- 牙齿中某些像素点是纯白色,那么这点的RBG值表示为(255,255,255)。三个通道的值都是255。
- 鼻头儿上某些像素点是纯黑色,那么这点的RBG值表示为(0,0,0)
- 以此类推...
小贴士:
在数字图像处理中,图像通道是指一个图像中的颜色信息被分离为不同的颜色分量。常见的图像通道包括RGB通道、灰度通道、HSV通道等。RGB通道是指将图像分离为红色、绿色和蓝色三个颜色通道,每个通道表示相应颜色的亮度。这种方式是最常见的方式,它对于彩色图像的处理非常重要。灰度通道是指将图像中的颜色信息转换为灰度亮度值,用单个通道表示整幅图像。这种方式比较适用于黑白图像或者在彩色图像中只需要考虑图像的亮度信息时。HSV通道是指将图像中的颜色信息分离为色调(H)、饱和度(S)和亮度(V)三个通道。这种方式在对颜色变化的控制上比RGB更加直观,更适用于图像处理中的颜色调整。在图像处理中,通常使用不同的通道来处理和操作图像。例如,使用灰度通道可以使图像变得更容易处理,因为只需要考虑单个通道,而使用RGB通道可以使图像更容易在彩色显示设备上显示。在处理和分析图像时,选择适当的通道和通道组合是非常重要的,可以帮助我们更好地理解和控制图像。
像素向量化
上述凯撒图片大小为374*346。横向有347个像素点,竖向有346个像素点。所以整个图片的像素点有 个。图片虽然只有16.7kb的大小,但是依然有120062个像素点组成。每个像素点又有三个通道组成,因此我们可以使用表格来表示像素点值:
| 像素 | R | G | B |
| 第1个像素点 | 255 | 255 | 255 |
| 第2个像素点 | 255 | 255 | 255 |
| ... | ... | ... | ... |
| 第120061个像素点 | 52 | 45 | 37 |
| 第120062个像素点 | 54 | 47 | 39 |
为了方便计算机计算,我们所有像素点的像素值按照顺序排列到一起即可得到如下的数列:
【255,255,255,255,255,255,...,...,...,52,45,37,54,47,39】总共有个数字。
from PIL import Image
# 读取图像
image = Image.open('example_image.jpg')
# 将图像转换为 RGB 模式
image_rgb = image.convert('RGB')
# 获取图像的大小
width, height = image.size
# 创建一个空数组来存储像素的 RGB 值
pixel_values = []
# 遍历图像的每个像素,并将 RGB 值添加到数组中
for y in range(height):
for x in range(width):
r, g, b = image_rgb.getpixel((x, y))
pixel_values.append((r, g, b))
# 将像素值的元组展开成一个扁平的列表
flattened_pixel_value = [value for pixel in pixel_value for value in pixel]
print(flattened_pixel_value)归一化
上面我们将图片转化成一系列的像素值,每个像素值的范围都在【0,255】的范围内。图片中有120062个像素点,转换数字表示后就有360,186个数值。大家想一个场景:
如果这些数值中有百分之九十的数都接近255,百分之九的数都接近0,只有百分之一的数处于0~255中间的位置,会导致什么问题?
比如一个分类任务,如果模型计算的结果是接近1那么输入的图片是一只猩猩。如果任务输出的结果是256,那么输出入的图片是狗。
- 如果前360,185个数相加后等于1,此时模型预测出来的结果倾向于猩猩。如果最后一个像素点的值是255,此时模型输出的结果就是一只狗。那么最后一个像素对整个预测结果发生了本质的变化。倒是模型不稳定。
- 如果我们模型在计算的过程中,计算的数值变的无穷大,超出了计算机所接受的范围,那么360,186个像素点的值加起来很有可能会超出这个范围。
当然还有很多的问题会出现,所以我们需要将数据进行一定的处理防止一系列的问题发生。这里简单的罗列了比较官方的描述:
- 加速收敛: 在训练过程中,如果特征的尺度相差较大,那么损失函数的等高线可能会变得细长,导致梯度下降算法收敛缓慢。通过归一化特征,可以使损失函数的等高线更加接近圆形,加速梯度下降算法的收敛。
- 防止数值溢出: 在一些模型中,特征的数值大小会影响计算结果的稳定性。如果特征值过大,可能会导致数值计算过程中的溢出或不稳定性问题。通过将特征归一化到合适的范围,可以减少这种情况的发生。
- 增加模型的稳定性: 特征归一化可以使模型对特征值的变化更加鲁棒。即使输入特征的分布发生变化,归一化后的特征仍然保持一定的稳定性,有助于模型的泛化能力。
- 提高模型的精度: 特征归一化可以消除特征之间的量纲影响,使得不同特征对模型的影响更加均衡,从而提高模型的精度和性能。
为了实现加速收敛、防止数值溢出、增加模型的稳定性、提高模型的精度等一系列的问题,比较常规的做法有如下:
- 最小-最大缩放(Min-Max Scaling): 最小-最大缩放是将特征缩放到一个指定的最小值和最大值之间的范围。具体公式为:
,其中
就是255,
就是0
- Z-score 标准化(Standardization): Z-score 标准化是将特征缩放到均值为 0、标准差为 1 的标准正态分布上。具体公式为:
,其中
为均值,
为标准差。稍后会讲解。
- Robust 标准化(Robust Scaling): Robust 标准化是一种对异常值更加稳健的归一化方法,它将特征缩放到一定的范围内,同时对异常值不敏感。具体公式为:
,其中median为特征中位数,IQR为特征的四分位距。
- Log Transform: 对特征取对数是一种常见的归一化方法,特别适用于右偏(正偏)分布的数据。取对数后,数据的分布将更加接近正态分布。
- 其他方法: 还有一些其他的归一化方法,例如范数归一化(Normalization),将特征向量的范数缩放到单位长度;均值移除(Mean Removal),将特征的均值移动到零;分位数归一化等。
实现归一化的方式有很多,这里不在罗列,我们选择一个比较简单的方式 Z-score 标准化 来处理图片的数值。
我们将向量化后的向量拿出来:【255,255,255,255,255,255,...,...,...,52,45,37,54,47,39】
为了更直观的体现计算过程,我们将上述向量中省略号去掉。【255,255,255,255,255,255,52,45,37,54,47,39】。请大家记住,这里只是为了直观的体现计算过程,其实当前向量中有360186个数字。我们只是吧第一个、第二个以及第360185个、第360186个像素拿出来举例!!!!。
Z-score标准化的具体公式为:,其中
为均值,
为标准差。
步骤 1:计算数据的均值和 标准差
。
说白了 就是将所有的数值加起来然后除以数值的总个数。
也就是将每个数减去平均值的平方加载一起后在取平均值。最后对平均值开个根号。
步骤 2:应用 Z-score 标准化公式
因此,经过 Z-score 标准化后的数据为:
[0.9937,0.9937,0.9937,0.9937,0.9937,0.9937,−1.0787,−1.1091,−1.1394,−1.0695,−1.0999,−1.1292]
至此我们得到了一张图片处理好的向量值。[0.9937,0.9937,0.9937,0.9937,0.9937,0.9937,−1.0787,−1.1091,−1.1394,...,...,...,−1.0695,−1.0999,−1.1292]
import numpy as np
# 给定数据
data = [255, 255, 255, 255, 255, 255, 52, 45, 37, 54, 47, 39]
# 计算均值
mean = np.mean(data)
print("均值:", mean)
# 计算标准差
std_dev = np.std(data)
print("标准差:", std_dev)
# Z-score 标准化
z_score_values = []
for index,value in enumerate(data):
z_score = (value - mean) / std_dev
z_score_values.append(z_score)















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









