






urllib库是Python的一个内置HTTP请求库,无需安装即可直接使用。它主要用于发送HTTP/FTP请求,可以看作处理URL的组件集合。urllib库具有简单易用、支持多种协议(如HTTP、HTTPS、FTP等)的特点。
urllib库主要包含四个模块:
urllib.request:这是请求模块,用于打开和读取URLs。其主要方法包括urlopen(),用于打开URL并返回响应对象。响应对象包含了服务器返回的内容、状态码、头部信息等。此外,urllib.request还提供了Request类,允许用户为请求的网址添加头部信息。
urllib.parse:这个模块主要用于解析URLs,将URLs分解为组成部分,或将查询参数转换为字符串等。
urllib.error:这个模块提供了处理请求过程中可能发生的各种异常的类。
urllib.robotparser:这个模块用于解析robots.txt文件,该文件通常用于告知爬虫哪些页面可以访问,哪些不可以。Robots-(Robots Exclusion Protocol)
urllib库的主要作用是设定相关的头部信息并与网站建立请求连接,一旦连接建立完成,就可以获取到网页的整体数据。这也是Python爬虫脚本实现的核心功能。此外,urllib库还可以访问到网页的robots.txt文件,从而了解网页的访问规则,并在抓取数据返回之后对数据进行相关的解析。
在使用urllib库时,通常首先通过urllib.request.urlopen()方法打开一个URL,然后获取响应对象。通过响应对象的read()方法,可以读取响应的网页内容。此外,还可以使用响应对象的status、getheaders()等方法获取状态码和头部信息。urlopen 函数返回的是一个响应对象,该对象不是上下文管理器,因此不能直接使用 with 语句。
urllib.request是Python中的一个模块,主要用于发送HTTP或HTTPS请求。它提供了一组功能强大的方法和类,使得在Python中进行网络请求变得简单。
主要功能
urlopen()函数:此函数用于打开一个URL,并返回一个响应对象。通过这个响应对象,你可以获取到服务器的响应内容、状态码、头部信息等。
Request类:当你需要为请求添加更多的控制时,可以使用Request类。你可以通过Request类来设置请求的URL、方法(如GET、POST等)、头部信息(如User-Agent、Cookie等),甚至可以添加请求体数据。
示例
以下是一个使用urllib.request发送GET请求的简单示例:
import urllib.request
url = 'Example Domain'
response = urllib.request.urlopen(url)
# 读取响应内容
content = response.read().decode('utf-8')
print(content)
# 获取状态码
status_code = response.getcode()
print(status_code)
# 获取头部信息
headers = response.getheaders()
print(headers)
请求头设置
如果需要设置请求头,可以使用urllib.request.Request类。例如,为了伪装浏览器访问,可以设置User-Agent头部:
import urllib.request
url = 'Example Domain'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
content = response.read().decode('utf-8')
print(content)
异常处理
在发送网络请求时,可能会遇到各种异常,如连接错误、超时等。urllib.request模块提供了urllib.error模块来处理这些异常。你可以使用try-except语句来捕获和处理这些异常。
import urllib.request
import urllib.error
url = 'Example Domain'
try:
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
print(content)
except urllib.error.URLError as e:
print(e.reason)
总结
urllib.request是Python中用于发送HTTP/HTTPS请求的强大工具,它提供了简单且灵活的方式来执行网络请求,并获取服务器的响应。无论是进行简单的网络爬虫,还是构建复杂的Web服务,urllib.request都能提供有力的支
持。
关于什么时候使用urlopen和Request
当需要进行防伪的时候要用到请求的时候可以使用request:
import urllib.request
url = 'Example Domain'
response = urllib.request.urlopen(url)
# 读取响应内容
content = response.read()
# 获取状态码
status_code = response.getcode()
# 获取响应头
headers = response.getheaders()
# 关闭响应
response.close()
urllib.request.urlopen() 是 Python 中用于打开一个 URL 并读取其内容的函数。这个函数提供了多个参数和方法,以支持不同的请求方式和处理各种网络请求场景。下面是对 urlopen() 中的参数以及返回对象的主要方法和属性的详细解释:
urlopen() 参数
url:
类型:字符串
描述:要打开的 URL。
data(可选):
类型:字节序列
描述:如果提供此参数,则会发送 POST 请求,并且 data 会作为请求体发送。通常,你需要先将数据编码为字节串(例如,使用 str.encode())。
timeout(可选):
类型:浮点数或元组
描述:设置网络操作的超时时间。可以是单个浮点数,表示连接和读取的总超时时间;也可以是一个包含两个浮点数的元组,分别表示连接超时和读取超时。
urlopen() 返回对象的主要方法和属性
返回的 http.client.HTTPResponse 对象(或其他类型的响应对象,取决于 URL 的协议)具有以下方法和属性:
read():
描述:读取响应体的内容,并返回字节串。
readinto(b):
描述:读取响应体的内容,并将数据写入提供的字节数组中。
readline():
描述:读取响应体的一行内容,并返回字节串。
readlines():
描述:读取响应体的所有行,并返回行组成的列表。
getcode() 或 status:
描述:返回 HTTP 响应的状态码(如 200 表示成功)。
getheaders():
描述:返回响应头的列表,其中每个元素是一个包含头名和头值的元组。
getheader(name, default=None):
描述:返回指定头名的头值。如果头不存在,则返回 default(默认为 None)。
msg:
描述:返回响应头的 email.message.Message 对象,允许你像处理邮件头一样处理响应头。
version:
描述:返回 HTTP 协议的版本(如 11 表示 HTTP/1.1)。
reason:
描述:返回响应的简短原因短语(如 "OK")。
close():
描述:关闭响应并释放相关资源。
示例
python
import urllib.request
# 打开 URL 并读取内容
response = urllib.request.urlopen('http://www.example.com')
content = response.read().decode('utf-8')
print(content)
# 读取状态码和响应头
status_code = response.getcode()
headers = response.getheaders()
print(f'Status code: {status_code}')
print(f'Headers: {headers}')
# 关闭响应
response.close()
注意:在实际使用中,通常建议使用 with 语句来自动处理资源的关闭,如上面提到的示例。这样可以确保即使在处理响应时发生异常,资源也能被正确释放。
另外,由于 urllib.request 模块的功能相对基础,对于更复杂的网络请求和更高级的 HTTP 功能(如 cookies、会话、重定向处理等),你可能会发现 requests 库更为方便和强大。
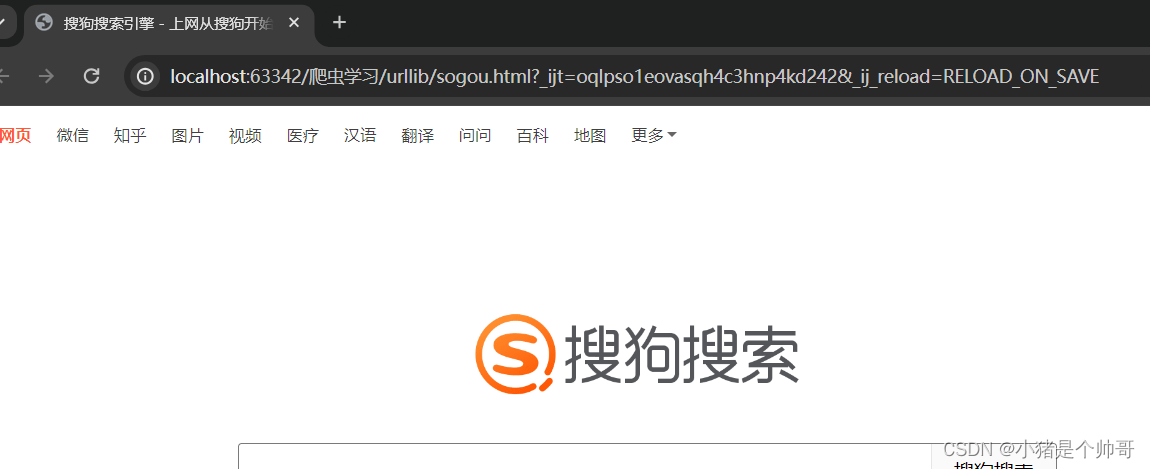
案例:让我们用urllib的urlopen读取一下搜狗的网页:
importurllib.request#导入urllib.request模块
#定义要爬取的URL
url="https://www.sogou.com/"
#使用urlopen方法发起请求
response=urllib.request.urlopen(url)
#读取响应内容
html_content=response.read()
#获取响应状态码
status_code=response.getcode()
print(f"响应的状态码:{status_code}")
#将响应内容保存到文件
withopen('sogou.html','wb')asfile:#使用二进制写入模式
file.write(html_content)
print("网页保存成功")
在上述代码中我们使用urllib的urlopen来爬取一个网页的html。注意在上述代码中我并没有进行encoding编码
这是应为,在二进制模式中使用encoding会出现报错
ValueError: binary mode doesn't take an encoding argument
'wb':以二进制格式打开一个文件只用于写入。如果该文件不存在,将创建新文件。在这种模式下,数据将以原始的字节序列形式写入文件,而不是经过编码的文本。
'rb':以二进制格式打开一个文件用于只读。这种模式常用于读取二进制文件,如图像、音频或视频文件。
'rb+':以二进制格式打开一个文件用于读写。这种模式允许你既读取文件的内容,也可以向文件中写入数据。
'ab':以二进制格式打开一个文件用于追加。如果该文件已存在,新的内容将会被写入到已有内容之后;如果该文件不存在,将创建新文件进行写入。
'ab+':以二进制格式打开一个文件用于追加和读取。与'ab'类似,但如果需要读取之前写入的内容,可以使用此模式。
'xb':以二进制格式打开一个文件,如果文件已存在则产生异常。这通常用于确保文件不会被意外覆盖。
如果你要使用encoding进行编码的话。需要使用decode函数
importurllib.request#导入urllib.request模块
#定义要爬取的URL
url="https://www.sogou.com/"
#使用urlopen方法发起请求
response=urllib.request.urlopen(url)
#读取响应内容
html_content=response.read()
#获取响应状态码
status_code=response.getcode()
print(f"响应的状态码:{status_code}")
html_content_str=html_content.decode('utf-8')
#将响应内容保存到文件
withopen('sogou.html','w',encoding="utf-8")asfile:#使用二进制写入模式
file.write(html_content_str)
print("网页保存成功")
这个效果和上述效果是一样的:
- 关于发起请求的一些事项:
- 在爬虫无论是post请求还是get请求。最终都是获取服务器的响应。
- 在使用get请求的时候。通常我们会得到一个响应对象,我们可以从这个响应对象中读取数据
- 比如:
importurllib.request
url='https://www.baidu.com'
response=urllib.request.urlopen(url=url)
response_container=response.read()
print(type(response))
print(f"响应的内容{response_container}")
- 输入的内容:
<class 'http.client.HTTPResponse'>
响应的内容b'<html>\r\n<head>\r\n\t<script>\r\n\t\tlocation.replace(location.href.replace("https://","http://"));\r\n\t</script>\r\n</head>\r\n<body>\r\n\t<noscript><meta http-equiv="refresh" content="0;url=http://www.baidu.com/"></noscript>\r\n</body>\r\n</html>'
- 这个响应的内容是一个HTML文档的字节串表示形式,以b'开头表示它是一个字节串(bytes)。当你打印这个变量时,Python会显示它的原始字节表示,包括所有的转义字符和不可见字符。
- 如你想显示HTML标准的可以这样写;加上:
html_content_str=html_content.decode('utf-8')
print(html_content_str)
- 现在我来展示一下:
importurllib.request
url="https://www.baidu.com"
withurllib.request.urlopen(url=url)asf:
html_content=f.read()
html_content_str=html_content.decode('utf-8')
print(html_content_str)
#with语句结束时,response对象会自动关闭
- 输出结果:在上述代码中with无论代码是否正常执行,都会在with语句结束的时候,终止
E:\python\python.exe E:\python_project\爬虫学习\urllib\response.py
<html>
<head>
<script>
location.replace(location.href.replace("https://","http://"));
</script>
</head>
<body>
<noscript><meta http-equiv="refresh" content="0;url=http://www.baidu.com/"></noscript>
</body>
</html>
- 对于post请求:主要用途是提交表单数据到服务器,当我们使用post请求的时候,我们通常会构建一个请求对象,这个对象包含了你提交的数据(表单字段和值),并从服务器获取响应。
服务器的响应主要是包含了对请求的处理结果,比如一个HTML页面、JSON数据、或者仅仅是一个状态码来表示请求的处理情况。
响应的内容取决于服务器如何处理你的POST请求。例如,如果你提交了一个表单来创建一个新用户账户,服务器的响应可能是一个包含新用户信息的JSON对象,或者是一个表示操作成功的状态码和消息。
响应中可能会包含一些与请求相关的元数据,比如响应头(Headers),这些元数据提供了关于响应的一些额外信息,比如内容类型、响应长度、服务器信息等。但是,这些信息并不是你原始请求中的数据,而是服务器在生成响应时添加的。
如果你想要检查服务器响应中是否包含请求信息,你需要查看响应的具体内容。这通常可以通过读取响应体(Body)来实现,这取决于你使用的编程语言和库。
在Python的urllib或requests库中,你可以通过访问响应对象的属性来获取这些信息。例如,使用requests库时,你可以这样做:
import requests
# 发送POST请求
response = requests.post('http://www.example.com/post', data={'key': 'value'})
# 获取响应状态码
status_code = response.status_code
# 获取响应头
headers = response.headers
# 获取响应内容
content = response.content # 原始字节数据
text = response.text # 解码后的文本内容
json_data = response.json() # 如果响应是JSON格式,可以直接解析为Python对象
# 检查响应内容是否包含请求信息(通常不会)
# 你需要具体查看content或text中的内容来判断
如果你发现响应中似乎包含了请求信息,那很可能是服务器特意在响应中返回了这些信息,或者是因为某种特殊的原因(比如调试或日志记录)导致的。在正常情况下,服务器响应不应该包含原始的请求数据。
关于——bytes
关于课本中的bytes使用:您询问了课本中是否为了强调而使用了bytes()函数来创建bytes对象,以及在实际编程中是否需要这样做。我解释了课本中可能为了教学目的而展示了不同的方法,但在实际编程中,通常使用字符串的.encode('utf-8')方法来得到bytes对象,这是一种更简洁和常见的做法。
关于bytes对象的创建:您询问了如何将包含数据的字典转换为URL编码的字符串,并进一步转换为bytes对象。我给出了一个完整的代码示例,演示了如何使用urllib.parse.urlencode方法将字典转换为URL编码的字符串,并调用.encode('utf-8')方法将其转换为bytes对象。
案例:urllib中相关参数的使用:
- data参数:
- 当您想要向服务器发送POST请求并附带数据时,可以使用data参数。这个参数通常是一个字节串(bytes),表示要发送的数据。如果数据是字符串,您需要使用.encode()方法将其编码为字节串。
- 如果你确实需要向某个网站发送POST请求,你应该首先确定该网站是否支持这样的请求,并查找正确的URL端点以及可能需要的任何其他信息(如身份验证凭据、CSRF令牌等)
开始一直对着书敲,没有明白urlopen中的data的含义
出了问题才发现,data值并不是我想的固定的,它来自于你所需要打开的地址
![]()

而且这个data是和同为参数的url是对应的,不能张冠李戴了
找url的时候要争对需要的结果去找,而不是找触发结果的事件
importurllib.request
importurllib.parse
url='https://httpbin.org/post'
#创造一个字典
new_data={"name":"value"}
#对字典进行编码,并转换为字节串
encoded_data=urllib.parse.urlencode(new_data).encode('utf-8')
#现在encoded_data是一个字节串,可以用于POST请求
#发起请求
response=urllib.request.urlopen(url=url,data=encoded_data)
#读取请求后的响应内容
read_response=response.read()
print(read_response.decode('utf-8'))
输出结果是:
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "value"
},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "10",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.12",
"X-Amzn-Trace-Id": "Root=1-65fe47ab-636168e62c9d3ed84441be4d"
},
"json": null,
"origin": "39.144.168.8",
"url": "https://httpbin.org/post"
}
对输出结果的解读:
您给出的JSON数据看起来像是从httpbin.org网站上的/post端点获取的一个响应。httpbin.org是一个在线HTTP请求/响应服务,它允许开发者测试他们的HTTP客户端库。
以下是该JSON响应的简要解释:
args: 一个空字典,表示URL中没有查询参数。
data: 一个空字符串,表示POST请求的正文为空。
files: 一个空字典,表示没有上传任何文件。
form: 一个包含name键和germey值的字典,表示这是POST请求中发送的表单数据。
headers: 一个字典,列出了请求的各种头部信息,包括:Accept-Encoding: 表示客户端接受的编码类型。
Content-Length: 请求体的长度。
Content-Type: 请求体的媒体类型,这里是application/x-www-form-urlencoded,表示数据是以URL编码的键值对形式发送的。
Host: 请求的目标主机。
User-Agent: 发送请求的客户端信息。
X-Amzn-Trace-Id: AWS的X-Ray跟踪ID,用于跟踪和调试分布式应用。
json: 为null,表示请求中没有包含JSON数据。
origin: 发起请求的IP地址。
url: 请求的完整URL。
从这个响应可以看出,您或其他人使用了一个HTTP客户端(可能是Python的urllib库)向https://httpbin.org/post发送了一个POST请求,其中包含了名为name的表单字段,其值为germey。该请求没有包含其他数据、文件或JSON负载,并且请求头中提供了关于客户端和请求的各种信息。
- 时间参数:timeout
- 参数用于设置超时时间,单位是秒。如果请求超出了这个设置的时间,还没有响应就会抛出异常
- 案例:
importurllib.request
importurllib.error
try:
response=urllib.request.urlopen("https://www.moooyu.com/",timeout=0.05)
read_response=response.read()
print(read_response)
excepturllib.error.URLErrorase:
print("抱歉请求超出设置时间")
#在这里不需要显式关闭response,因为urlopen的响应对象会在使用完毕后自动关闭
注意爬虫的速度是非常快的。Timeout=0.1都可能是爬取成功的。
- 关于with:with 语句通常用于管理资源,确保这些资源在使用完毕后能够被正确地关闭或释放。对于爬虫来说,这些资源可能包括网络连接、文件句柄、数据库连接等。
- urllib.request.urlopen 函数返回的是一个 HTTPResponse 对象,这个对象包含了服务器的响应。你可以从这个对象中获取状态码、响应头、响应体等信息
- 在 Python 的 urllib 库中,urlopen 函数返回的是一个响应对象,该对象不是上下文管理器,因此不能直接使用 with 语句。但是,从 Python 3.4 开始,urllib.request 提供了一个 urlopen 的上下文管理器版本,即 urllib.request.Request 和 urllib.request.urlopen 的组合使用。
importurllib.request
url="https://www.example.com"
req=urllib.request.Request(url)
withurllib.request.urlopen(req)asresponse:
content=response.read().decode('utf-8')
print(content)
#在这里,当with块执行完毕时,response对象会被自动关闭,
#无需显式调用response.close()
结合使用
urlopen对象通常会在使用完毕后自动关闭。在大多数情况下,你不需要显式地关闭通过urllib.request.urlopen()获取的响应对象。Python的垃圾回收机制会在对象不再被引用时自动关闭和释放相关资源。
然而,为了确保代码的健壮性和资源的正确管理,有些开发者可能会选择使用with语句来管理urlopen的上下文。这样,即使发生异常,也能确保资源被正确释放。但是,需要注意的是,urlopen返回的对象本身并不是上下文管理器,因此不能直接使用with语句。
如果你需要更细粒度的控制,比如设置请求头、处理重定向等,你可以使用urllib.request.Request对象和urlopen函数结合的方式,并通过with语句来管理这个请求的上下文。但即使在这种情况下,你也通常不需要显式关闭响应对象,因为with语句会在退出时自动处理。
总的来说,虽然urlopen对象通常会自动关闭,但使用with语句或确保在不再需要对象时释放其占用的资源仍然是一个好的编程习惯。
但是reques可以直接使用with
- requests 库在发送请求后返回的是一个 Response 对象。这个对象提供了比 urllib.request 更丰富和友好的 API 来处理 HTTP 响应。你可以直接访问状态码、响应头、cookies、JSON 数据等,而无需像 urllib.request 那样调用额外的方法
- 两个案例结合:
importurllib.request
importurllib.error
url="https://www.httpbin.org/post"#设置url
creator_data={"message":"value"}#创建字典
#对字典进行编码格式
encode_data=urllib.parse.urlencode(creator_data).encode("utf-8")
try:
#发起请求
response=urllib.request.urlopen(url=url,data=encode_data,timeout=5)
#获取响应
obtain_response=response.read().decode("utf-8")
print(obtain_response)
excepturllib.error.URLErrorasf:
print("请求时间超过设置时间")
#使用read可以获取响应的网页内容
importurllib.request
#要爬取的url
url='https://www.yuznu.edu.cn/html/'
#发送请求
response=urllib.request.urlopen(url=url)
#读取响应内容
yuzhang=response.read()
#调用decode函数。用于将Python的Unicode字符串(str类型)转换成UTF-8编码的字节串(bytes类型)
decode_yuzhang=yuzhang.decode('utf-8')
withopen("豫章.html","w",encoding="utf-8")asfile:
file.write(decode_yuzhang)
print("爬取成功")
在urllib库中有4个模板:
request——error——parse——robotparser
- urllib.request:用于打开和读取URLs。
- urllib.error:包含由
urllib.request产生的异常。 - urllib.parse:用于解析URLs,将URL各部分分割、合并或转码。
- urllib.robotparser:用于解析robots.txt文件,判断爬虫是否可以爬取某个网页。
在request中又有一个urlopen的类
这个函数中又有几个参数:url——必备参数——data可选参数(提供这个参数的时候表明请求方式现在时POST)——timeout(可选参数)urllib对于一些特殊需求或者需要更底层控制的情况更合适
更强大的库---requests
然后使用:
1——指定URL
2——发起请求
3——获取响应式
4——持久化存储
案例:
import requests
if __name__ == '__main__':
# 指定URL
url = "https://www.sogou.com/"
# 发起请求 发起一个get请求
# get方法会返回一个响应对象
response = requests.get(url=url)
# 获取响应数据 text返回的字符串形式地响应数据
page_text = response.text
# 持久化存储
with open("./sogou.html","w",encoding="utf-8") as fp:
fp.write(page_text)
print("爬取数据结束")with 语句用于简化异常处理,特别是当需要确保一些清理操作(如关闭文件或网络连接)总是被执行时。with 语句通过上下文管理协议(context management protocol)来实现这一点,它要求对象实现 __enter__ 和 __exit__ 方法。
当你使用 with 语句打开一个文件时,Python会在代码块执行完毕后自动关闭文件,即使发生了异常也是如此。这避免了因为忘记关闭文件而导致的资源泄露或其他问题。
open函数被调用,并返回一个文件对象。__enter__方法被调用(隐式地),通常返回文件对象本身,这个对象被赋值给fp。- 在
with语句的代码块内部,你可以使用fp来操作文件。 - 当代码块执行完毕后(无论是否发生异常),
__exit__方法被调用(隐式地),负责清理资源,比如关闭文件。
当然也可以不用with,可以使用try和finally来执行
import requests
if __name__ == '__main__':
url = "https://www.apple.com.cn/"
response = requests.get(url=url)
iphone = response.text
fp = open('iphone_01.html', 'w', encoding='utf-8')
try:
fp.write(iphone)
finally:
print("爬取数据完成")
fp.close()
finally:不管发送了什么,我都要执行:
关于为什么要在这里写if __name__=="__main__"
if __name__ == '__main__': 确保了只有在直接运行这个脚本时,才会发起网络请求并保存网页内容。如果其他脚本导入了这个模块,则不会执行这些操作,这有助于避免不必要的副作用和潜在的错误。
关于
# script.py
def some_function():
print("This is a function in the module.")
if __name__ == '__main__':
print("This script is being run directly.")
some_function()如果该程序是在本地执行的话。先运行 print("This script is being run directly."),其次在是去运行函数:print("This is a function in the module.") 。如果该程序导入到其他程序中 import script。这个程序就只会运行函数下面的print("This is a function in the module.")
下面是爬取的数据
案例:网页爬取
# 网页采集器
import requests
# UA防伪:门户网站的服务器会检测对应请求的载体身份标识。如果检测到请求的载体标识为某一款浏览器,说明是正常的请求,如果检测到载体不是一个
# 不是一个浏览器,网站就会拒绝这个请求
# UA:User-Agent(请求载体的身份标识)
# 如何进行UA伪装:让爬虫对应的请求载体身份标识伪装成某一款浏览器
if __name__ == "__main__":
# url = "https://www.sogou.com/web?query=%小朱是个帅哥" # 这个参数是一个静态的词条,只可以搜索这一个词条
# 进行伪装:将对应的User-Agent封装到一个字典中其他浏览器也可以
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/122.0.0.0 Mobile Safari/537.36 Edg/122.0.0.0"
}
url = "https://www.sogou.com/web"
# 处理URL携带的参数 :声明一个字典
kw = input("输入你要搜索的词条") # 现在就变了一个动态的参数
param = {
"query":kw
}
# 对指定的URL发起的请求对应的URL是携带参数的,并且请求过程中已经处理了参数
response = requests.get(url=url, params=param, headers=headers) # 在这个我们使用的get方法发送的请求,那么当前请求就是我们的爬虫浏览器
# 当我们用浏览器对应网址发请求的话,当前User-Agent的请求载体是浏览器
page_text = response.text
fileName = kw + ".html"
with open(fileName, "w", encoding="utf-8") as f:
f.write(page_text)
print(fileName, "保存成功")
注意事项:
一般在爬取网页的时候,要设置动态的参数,给浏览器搜索。
在上述代码中
requests.get() 接收了以下参数:
-
url:这是您想要请求的网络地址的字符串。例如,对于搜索引擎,它可能是https://www.sogou.com/s?或https://www.baidu.com/s?。确保 URL 是正确的,并且它指向您想要获取内容的页面。 -
params:这是一个字典,包含了要添加到 URL 中的查询参数。这些参数通常用于过滤结果、指定搜索关键词等,param(或之前定义的 kw)是一个字典,其中包含了搜索关键词。当您传递params给requests.get()时,requests库会自动将这些参数编码到 URL 的查询字符串中。 -
headers:这是一个字典,包含了您想要发送给服务器的 HTTP 头部。HTTP 头部是 HTTP 请求和响应中的元数据,包含了关于请求或响应的信息,如 User-Agent(表示发出请求的客户端类型)、Accept(表示客户端可以处理的响应类型)等。在爬虫中,设置 User-Agent 头部常常用于伪装成常见的浏览器,以避免被目标网站拒绝或限制 -
User-Agent在开发者工具中查看按F12便可以查看了
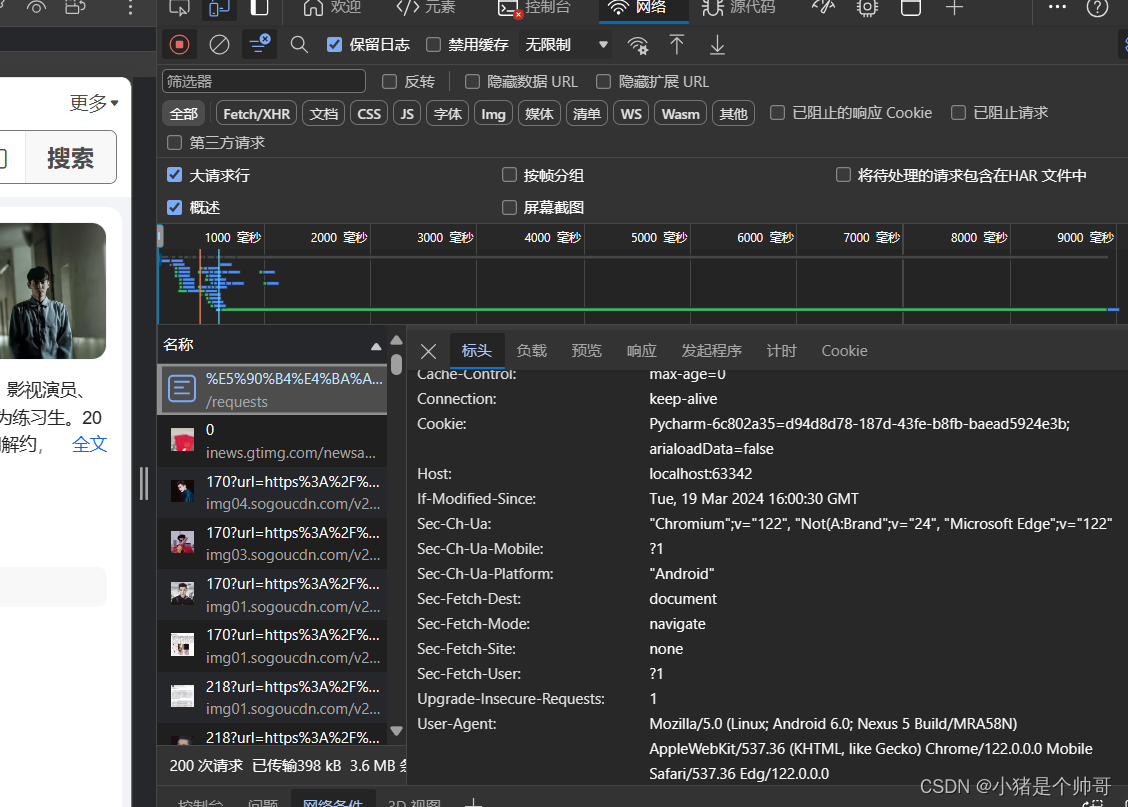
在其中找到User-Agent
输入到headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/122.0.0.0 Mobile Safari/537.36 Edg/122.0.0.0"就可以了
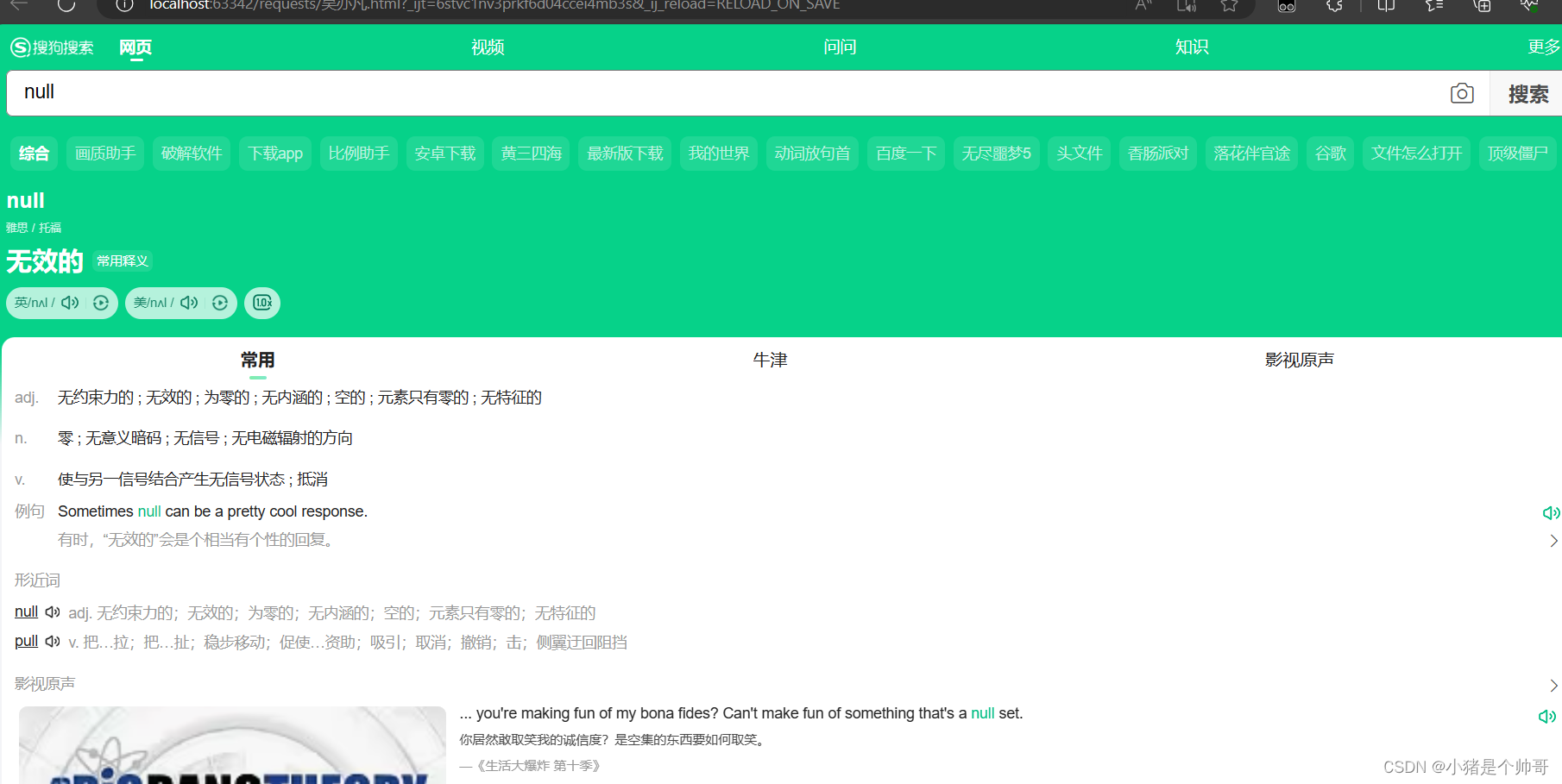
注意一点:在构造请求参数时,最重要的是确保使用的参数键(key)与目标网站期望接收的参数键相匹配。对于大多数搜索引擎,常见的参数键包括 "query"、"keyword"、"s" 等,但具体使用哪个键取决于搜索引擎的实现。在搜索引擎中都会体现出来参数名称,比如百度就是wd 如果不匹配的话,打开爬取的html文件会显示null无效的
如果不匹配的话,打开爬取的html文件会显示null无效的















 565
565











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









