







网络通讯协议与爬虫浅谈
网络通信三要素
IP地址、端口号、协议
IP地址
IP地址的作用
用来在网络中标记一台电脑,比如192.168.1.1;在本地局域网上是唯一的。
IP地址查看
windows:
cmd->ipconfig
linux:
ifconfig
端口号
端口号:
用来唯一标识一个进程。每一个程序都要有一个端口号

端口号就是一个十进制的整数。
端口号的取值范围是:0到65535
0到1024以下的端口号是系统保留使用的,程序猿在实际开发不要使用1024以下的端口号
常见端口号
公有端口0-1023
HTTP:80
HTTPS:443
FTP:21
SSH:22
Telent:23
程序注册端口:1024-49151,分配用户或者程序
tomcat:8080
mysql:3306
oracle:1521
通讯协议
通信协议(communications protocol)官方给出的定义是指双方实体完成通信或服务所必须遵循的规则和约定。
协议定义了数据单元使用的格式,信息单元应该包含的信息与含义,连接方式,信息发送和接收的时序,从而确保网络中数据顺利地传送到确定的地方。
简单来说,通讯协议又是指通信双方对数据传送控制的一种约定。约定中包括对数据格式,同步方式,传送速度,传送步骤,检纠错方式以及控制字符定义等问题做出统一规定,通信双方必须共同遵守。

TCP协议
TCP是一种面向连接的、可靠的、基于字节流的传输层通信协议。即客户端和服务器之间在交换数据之前会先建立一个TCP连接,才能相互传输数据。并且提供超时重发,丢弃重复数据,检验数据,流量控制等功能,保证数据能从一端传到另一端。
tcp三次握手和四次挥手
相关原文链接:https://blog.csdn.net/qq_38950316/article/details/81087809
应用场景 :当对网络通讯质量有要求的时候,比如:整个数据要准确无误的传递给对方,这往往用于一些要求可靠的应用,比如HTTP、HTTPS、FTP等传输文件的协议,POP、SMTP等邮件传输的协议。在日常生活中,常见使用TCP协议的应用比如:浏览器使用HTTP,Outlook使用POP、SMTP,QQ文件传输等。HTTP 协议是基于应用层的协议,并且在传输层使用的 TCP 的可靠性通信协议。
HTTP协议
超文本传输协议(英文:HyperText Transfer Protocol,缩写:HTTP)是一种用于分布式、协作式和超媒体信息系统的应用层协议。HTTP是万维网的数据通信的基础。HTTP是一个客户端终端(用户)和服务器端(网站)请求和应答的标准(TCP)。
HTTP请求方法
HTTP/1.1协议中共定义了不同方式操作指定的资源:
GET
向指定的资源发出“显示”请求。使用GET方法应该只用在读取数据,而不应当被用于产生“副作用”的操作中,例如在Web Application中。其中一个原因是GET可能会被网络蜘蛛等随意访问。
HEAD
与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该资源的信息”(元信息或称元数据)。
POST
向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。
PUT
向指定资源位置上传其最新内容。
DELETE
请求服务器删除Request-URI所标识的资源。
TRACE
回显服务器收到的请求,主要用于测试或诊断。
OPTIONS
这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用’*'来代替资源名称,向Web服务器发送OPTIONS请求,可以测试服务器功能是否正常运作。
HTTP常用请求方式: get与post请求的区别
GET提交的数据会放在URL之后,也就是请求行里面,以?分割URL和传输数据,参数之间以&相连,如EditBook?name=test1&id=123456。
而POST方法是把提交的数据放在HTTP包的请求体中.
GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
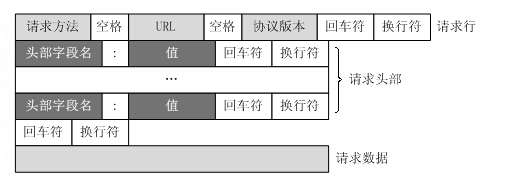
HTTP请求格式(请求协议)

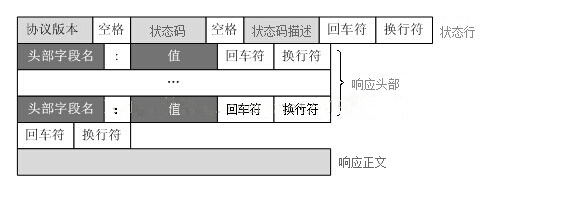
HTTP响应格式(响应协议)

HTTP常见的状态码
200 OK:表明该请求被成功地完成,所请求的资源发送回客户端;
302 Found:重定向,新的URL会在Response 中的Location中返回,浏览器将会自动使用新的URL发出新的Request;
304 Not Modified:代表上次的文档已经被缓存了, 还可以继续使用;
400 Bad Request:客户端请求与语法错误,不能被服务器所理解;
403 Forbidden:服务器收到请求,但是拒绝提供服务;
404 Not Found:请求资源不存在(输错了URL);
500 Internal Server Error:服务器发生了不可预期的错误;
503 Server Unavailable:服务器当前不能处理客户端的请求,一段时间后可能恢复正常;
HTTPS协议
https=http+ssl,顾名思义,https是在http的基础上加上了SSL保护壳,信息的加密过程就是在SSL中完成的https,是以安全为⽬标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加⼊SSL层,HTTPS的安全基础是SSL。
网络爬虫
网络爬虫的定义
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。对于我们来说,爬虫需要我们自己写,可以下载的我们眼里最有价值的数据。
爬虫的分类
通用网络爬虫
也称全网爬虫,顾名思义,就是爬取的目标是互联网中的所有数据资源,主要应用于大型搜索引擎中
通用型爬虫也是一个程序,可以从任何一个网友出发,用图的遍历算法,自动的访问每一个网友并存储在服务器里。
我们所熟悉的搜索引擎,如谷歌、百度、搜狗、必应、360,TA们的核心技术就是爬虫,属于通用型爬虫。
考虑的方面:
遍历算法的选择,如何在尽量短的时间下载所有网页 ?
如何高效 URL 去重 ?
如何避免漏掉网页呢 ?
JavaScript生成的网页,如何准确的提取出 URL 呢 ?
如何协调成千上万的服务器 ?
静态网页和动态网页需不需要分别处理 ?
聚焦网络爬虫
也称主题网络爬虫,按照预先定义好的主题有选择地进行网页爬取,爬取特定的资源。聚焦型爬虫与通用型爬虫的区别在于: 聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
通用型爬虫是搜索引擎的原身,也是一个程序;而聚焦型爬虫也是一个程序,主要是代替浏览器的程序根据我们设定的规则批量提取相关数据,而不需要我们去手动提取(通用型爬虫做不到这一点)。
增量式网络爬虫
指对下载⽹⻚采取增量式的更新和只爬⾏新产⽣的或者已经发⽣变化的⽹⻚爬⾍
深层网络爬
不需要登录就能获取的页面叫做表层页面,需要提交表单登录后才能获取的页面叫做深层页面,爬取深层页面需要想办法填写好表单
爬虫的基本步骤
获取数据:爬虫程序会根据提供的网址,向服务器发起请求,而后返回数据;
解析数据:爬虫程序把服务器返回的数据解析成我们能读懂的格式;
提取数据:爬虫程序再从中提取出需要的数据;
存储数据:爬虫程序把有用的数据保存起来,便于日后使用和分析
爬虫涉及的 Python 模块
request:获取网页信息,文本、音频、图片都可以的。
Json:解析 XHR 数据,也可以把字符串转为字典/列表
bs4:解析网页源代码,提取需要的数据
re:功能同 bs4,不过功能更强且大多数编程语言都支持
csv:存储数据(文件形式)
selenium:浏览器自动化
openpyxl:存储数据(excel文件形式)
gevent:异步爬虫,建立爬虫军队加速爬取数据
SMTP:电子邮件 发送
wxpy:微信消息 处理
pyautogui:鼠标键盘 自动化
MongoDB:数据库
Scrapy:爬虫框架
















 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











