







概论
- HashMap 是无论在工作还是面试中都非常常见常考的数据结构。比如 Leetcode 第一题 Two Sum 的某种变种的最优解就是需要用到 HashMap 的,高频考题 LRU Cache 是需要用到 LinkedHashMap 的。HashMap 用起来很简单,所以今天我们来从源码的角度梳理一下Hashmap
- 随着JDK(Java Developmet Kit)版本的更新,JDK1.8对HashMap底层的实现进行了优化,例如引入红黑树的数据结构和扩容的优化等。
- HashMap:它根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。
- HashMap最多只允许一条记录的键为null,允许多条记录的值为null。
- HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。
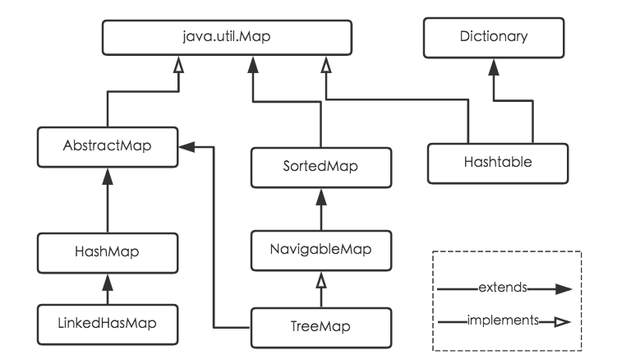
Hasmap 的继承关系
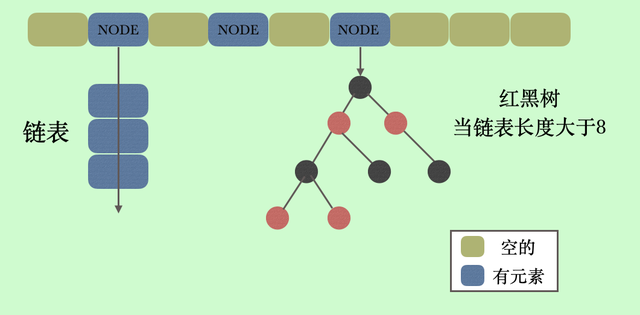
hashmap 的原理
- 对于 HashMap 中的每个 key,首先通过 hash function 计算出一个 hash 值,这个hash值经过取模运算就代表了在 buckets 里的编号 buckets 实际上是用数组来实现的,所以把这个hash值模上数组的长度得到它在数组的 index,就这样把它放在了数组里。
- 如果果不同的元素算出了相同的哈希值,那么这就是哈希碰撞,即多个 key 对应了同一个桶。这个时候就是解决hash冲突的时候了,展示真正技术的时候到了。
- 随着插入的元素越来越多,发生碰撞的概率就越大,某个桶中的链表就会越来越长,直到达到一个阈值,HashMap就受不了了,为了提升性能,会将超过阈值的链表转换形态,转换成红黑树的结构,这个阈值是 8 。也就是单个桶内的链表节点数大于 8 ,就会将链表有可能变身为红黑树。
解决Hash冲突的方法
开放定址法
这种方法也称再散列法,其基本思想是:当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi ,将相应元素存入其中。这种方法有一个通用的再散列函数形式:
Hi=(H(key)+di)% m i=1,2,…,n
其中H(key)为哈希函数,m 为表长,di称为增量序列。增量序列的取值方式不同,相应的再散列方式也不同。主要有三种 线性探测再散列,二次探测再散列,伪随机探测再散列
再哈希法
这种方法是同时构造多个不同的哈希函数
Hi=RH1(key) i=1,2,…,k
当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间
链地址法
这种方法的基本思想是将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。
链地址法适用于经常进行插入和删除的情况。
建立公共溢出区
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
hashmap 最终的形态
一顿操作猛如虎,搞得原本还是很单纯的hashmap 变得这么复杂,难倒了无数英雄好汉,由于链表长度过程,会导致查询变慢,所以链表慢慢最后演化出了红黑树的形态
HashMap主体上就是一个数组结构,每一个索引位置英文叫做一个 bin,我们这里先管它叫做桶,比如你定义一个长度为 8 的 HashMap,那就可以说这是一个由 8 个桶组成的数组。
当我们像数组中插入数据的时候,大多数时候存的都是一个一个 Node 类型的元素,Node 是 HashMap中定义的静态内部类
Hashmap 的返回值
很多人以为Hashmap 是没有返回值的,或者也没有关注过Hashmap 的返回值,其实在你调用Hashmap的put(key,value) 方法 的时候,它会将当前key 已经有的值返回,然后把你的新值放到对应key 的位置上
public class JavaHashMap { public static void main(String[] args) { HashMap<String, String> map = new HashMap<String, String>(); String oldValue = map.put("java大数据", "数据仓库"); System.out.println(oldValue); oldValue = map.put("java大数据", "实时数仓"); System.out.println(oldValue); }}
运行结果如下,因为一开始是没有值的,所以返回null,后面有值了,put 的时候就返回了旧的值

这里有一个问题需要注意一下,因为Map的Key,Value 的类型都是引用类型,所以在没有值的情况下一定返回的是null,而不是0 等初始值。
HashMap 的关键内部元素
存储容器 table;
因为HashMap内部是用一个数组来保存内容的, 它的定义 如下
transient Node<K,V>[] table
如果哈希桶数组很大,即使较差的Hash算法也会比较分散,如果哈希桶数组数组很小,即使好的Hash算法也会出现较多碰撞,所以就需要在空间成本和时间成本之间权衡,其实就是在根据实际情况确定哈希桶数组的大小,并在此基础上设计好的hash算法减少Hash碰撞。那么通过什么方式来控制map使得Hash碰撞的概率又小,哈希桶数组(Node[] table)占用空间又少呢?答案就是好的Hash算法和扩容机制。
在HashMap中,哈希桶数组table的长度length大小必须为2的n次方(一定是合数),这是一种非常规的设计,常规的设计是把桶的大小设计为素数。相对来说素数导致冲突的概率要小于合数
size 元素个数
size这个字段其实很好理解,就是HashMap中实际存在的键值对数量。注意和table的长度length、容纳最大键值对数量threshold的区别
Node
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; }}
- Node是HashMap的一个静态内部类。实现了Map.Entry接口,本质是就是一个映射(键值对),主要包括 hash、key、value 和 next 的属性。
- 我们使用 put 方法像其中加键值对的时候,就会转换成 Node 类型。其实就是newNode(hash, key, value, null);
TreeNode
当桶内链表到达 8 的时候,会将链表转换成红黑树,就是 TreeNode类型,它也是 HashMap中定义的静态内部类。
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { TreeNode<K,V> parent; // red-black tree links TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; // needed to unlink next upon deletion boolean red; TreeNode(int hash, K key, V val, Node<K,V> next) { super(hash, key, val, next);}
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









