







新钛云服已为您服务984天
Ceph 是一种广泛使用的分布式存储解决方案。在不同的配置环境中,Ceph的性能差异很大。生产环境中的群集都是部署在物理硬盘上。对于各种类型的工作负载,性能要求也不同。
我们基于Open-CAS缓存框架构建了一个Ceph集群。我们对特性进行了一些调整,以便系统可以处理大规模顺序读写的工作负载。这些调整为基于小块的随机读写的应用程序提供了更好的支持。
设想
HDD的随机访问受到磁头寻道时间的限制,与SSD相比,这导致随机访问的性能大大下降。对于10,000 RPM机械硬盘,随机读写的IOPS(每秒输入/输出操作)大约为350。
基于机械硬盘的Ceph集群成本较低,适合于大规模数据的顺序访问场景,但是不适用于OLTP(在线事务处理)工作负载中的小块数据访问。
如何以最优的成本提高小块数据的随机操作的访问性能?我们提出了Open-CAS缓存框架来加速Ceph OSD节点。
基线和优化解决方案如下图1所示。

图1:基于Open-CAS的Ceph集群性能优化框架
基准配置:HDD用作BlueStore的数据分区,而元数据(RocksDB和WAL)部署在Intel®Optane™SSD上。
优化配置:将HDD和NVMe * SSD通过Open-CAS软件组合为新的CAS设备,作为BlueStore的数据分区,并将元数据(RocksDB和WAL)部署在Intel Optane SSD上。
Open-CAS是由Intel发起的开源缓存加速解决方案。通过将模块加载到内核中,用作高速缓存的高速磁盘设备将慢速磁盘设备“合并”到新的CAS设备中,从而提高了系统的整体设备读写性能。
系统中的Open-CAS的层次结构如下图2所示。OCF(Open-CAS的核心,一个用C编写的高性能块存储缓存库)是文件系统层,如下所示。它是基于块设备层的IO请求处理。
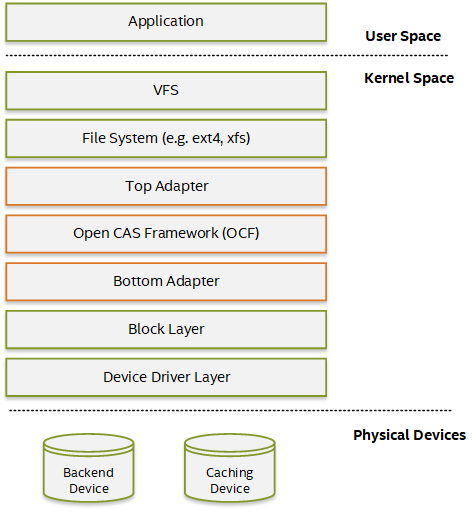
图2:Open-CAS框架
本文将重点介绍如何配置和优化Open-CAS并使用它构建Ceph集群。
性能评估
配置
我们基于Ceph构建了一个分布式存储集群。在服务器端,使用CeTune部署了Ceph集群以提供存储服务。在客户端,我们部署了Vdbench基准来验证我们的期望结果。
Vdbench是用Java编写的流行的IO基准测试工具,它以各种模式支持对块设备的多进程并发读写测试。
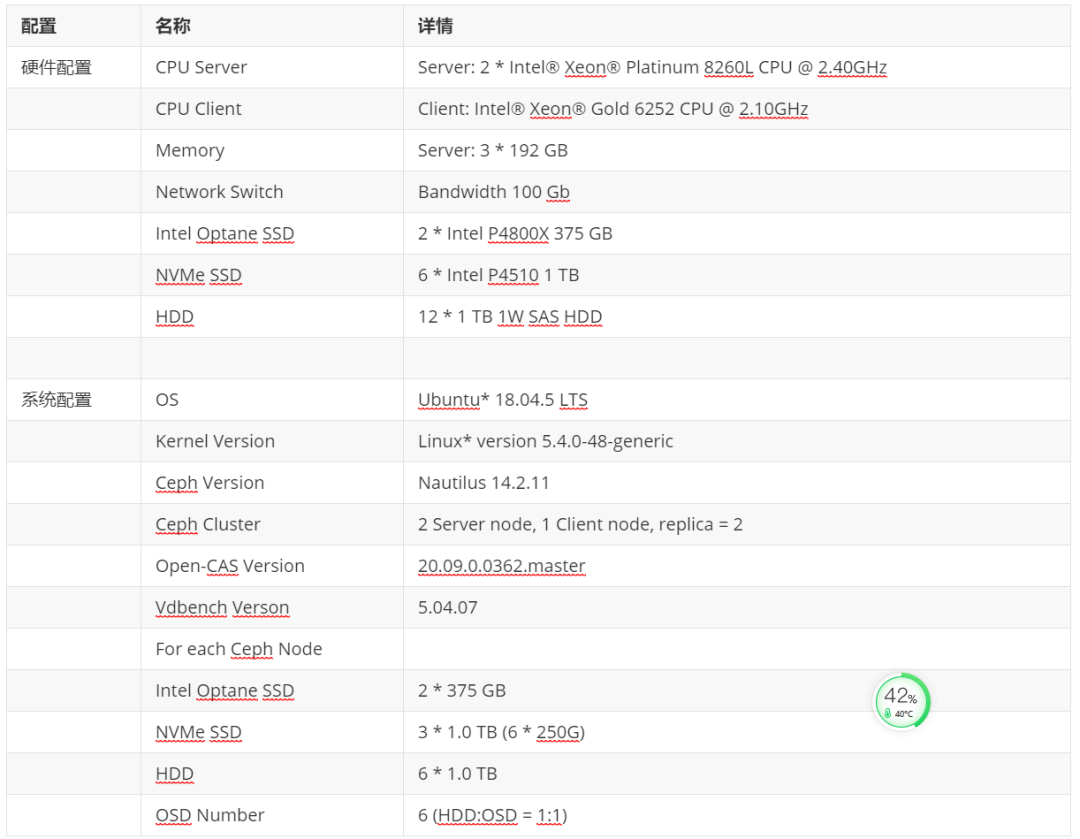
表1:Ceph集群配置
OPEN-CAS的优化配置
对于优化的解决方案,我们将Open-CAS用于数据分区。可以在编译和安装后使用Open-CAS:https://open-cas.github.io/guide_introduction.html
Open-CAS中的优化配置如下所示:
# casadm -S -d /dev/nvme2n1p1 -c wb --force // Create a new cache device, and return cache ID
# casadm -A -i -d /dev/sda // Add the backend device to the cache device and “merge” into a new CAS device
# casadm -L // View current Open-CAS configuration information
type id disk status write policy device
cache 1 /dev/nvme2n1p1 Running wb -
└core 1 /dev/sda Active - /dev/cas1-1
cache 2 /dev/nvme2n1p2 Running wb -
└core 1 /dev/sdb Active - /dev/cas2-1
cache 3 /dev/nvme3n1p1 Running wb -
└core 1 /dev/sdc Active - /dev/cas3-1
cache 4 /dev/nvme3n1p2 Running wb -
└core 1 /dev/sdd Active - /dev/cas4-1
cache 5 /dev/nvme4n1p1 Running wb -
└core 1 /dev/sde Active - /dev/cas5-1
cache 6 /dev/nvme4n1p2 Running wb -
└core 1 /dev/sdf Active - /dev/cas6-1
// The configuration for each cache ID
# casadm -X -n seq-cutoff -i 1 -j 1 -p always -t 16 // seq-cutoff always and threshold 16KB
# casadm --io-class --load-config --cache-id 1 -f ioclass-config.csv // only cache with request_size <=128K
# cat ioclass-config.csv
IO class id,IO class name,Eviction priority,Allocation
0,unclassified,22,0
1,request_size:le:131072,1,1
# casadm -X -n cleaning-alru -t 1000 -i 1 // clean policy alru with activity threashold to 1s
我们对上述配置进行了一些优化:
顺序读和写切断(cut-off):顺序读和写的IO流达到某个阈值时,将打开切断(cut-off)。所有后续的读写请求都直接进入后端存储,直到随机访问导致中断终止。
IO分类和优先级定义:我们希望按请求大小对随机访问进行分类,并且仅缓存块小于128K的数据。这需要添加基于request_size的类别,并将eviction优先级设置为高,同时避免过于容易从高速缓存中逐出。
清理策略参数调整:设置默认告警策略,缩短后台清理反应时间。清洁策略有两种类型:alru和acp。acp是一种比较活跃的策略,但是alru更适合于缓存中有可用空间的情况,它不会消耗太多带宽来进行后台清理。
CEPH集群设置和配置
我们通过CeTune工具部署了三个节点的Kubernetes集群;两个节点用于Ceph存储节点,一个节点用于客户端。
CeTune是用于部署,基准测试以及配置和调整Ceph集群性能的框架。它集成了一些基准测试工具,并为系统指标提供了各种参数数据。
您可以参考官方文档进行编译和安装。在部署之前,我们需要关注多个配置项:
根据以下格式在存储节点配置OSD:osd:data:db_wal。每个OSD需要三个磁盘,分别对应于OSD的数据分区和OSD的元数据分区。
网络配置。有一个公用网络,一个群集网络和一个单独的Ceph监视器网络。
配置文件在conf/all.conf中;主要内容如下:
head=CephCAS1 # Head node
list_server=CephCAS1,CephCAS2 # OSD nodes
list_client=CEPHCLIENT-01
list_mon=CephCAS1
disk_format=osd:data:db_wal
CephCAS1=/dev/cas1-1p1:/dev/cas1-1p2:/dev/nvme1n1p5,/dev/cas2-1p1:/dev/cas2-1p2:/dev/nvme1n1p6,/dev/cas3-1p1:/dev/cas3-1p2:/dev/nvme1n1p7,/dev/cas4-1p1:/dev/cas4-1p2:/dev/nvme1n1p8,/dev/cas5-1p1:/dev/cas5-1p2:/dev/nvme1n1p9,/dev/cas6-1p1:/dev/cas6-1p2:/dev/nvme1n1p10
CephCAS2=/dev/cas1-1p1:/dev/cas1-1p2:/dev/nvme1n1p5,/dev/cas2-1p1:/dev/cas2-1p2:/dev/nvme1n1p6,/dev/cas3-1p1:/dev/cas3-1p2:/dev/nvme1n1p7,/dev/cas4-1p1:/dev/cas4-1p2:/dev/nvme1n1p8,/dev/cas5-1p1:/dev/cas5-1p2:/dev/nvme1n1p9,/dev/cas6-1p1:/dev/cas6-1p2:/dev/nvme1n1p10
…
public_network=192.168.10.0/24 # Based on 100Gb NIC
monitor_network=192.168.10.0/24
cluster_network=192.168.11.0/24
然后,我们执行了部署脚本并创建了一个存储池。
# python run_deploy.py redeploy --gen_cephconf // Deploy Ceph cluster and wait for finish
…
# ceph osd pool create rbd 512 512 // 12 OSDs, Set PG num & PGP num to 512 is appropriate
# ceph osd pool set rbd size 2 // Set pool replicated = 2
# ceph osd pool application enable rbd rbd --yes-i-really-mean-it
# rbd create --thick-provision --size 65536 rbd/rbd1 --image-format 2 // Create rbd and fill in content atumaticaly, it will take more time
…
# rbd map rbd/rbd1 // Map rbd block device on the client side
性能比较与分析
VDBENCH基准分析
测试环境和报告
下面列出了Ceph RBD块设备上Vdbench的测试配置。
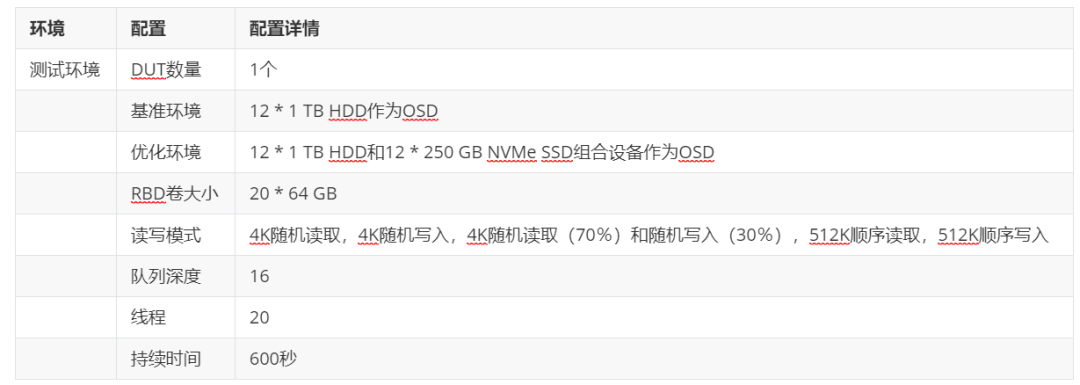
测试报告如下图所示。
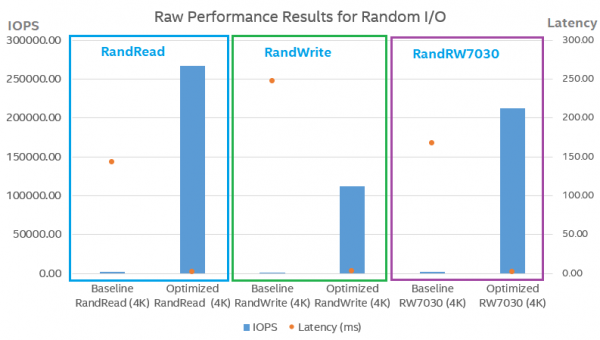
图3:随机I/O的原始性能结果
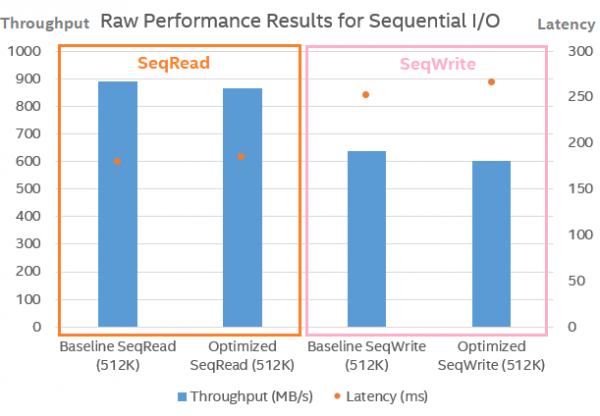
图4:顺序I/O的原始性能结果

图5:Open-CAS配置比较
从上图可以看出,在Open-CAS优化配置中,随机读取(100%缓存命中)和随机写入的IOPS分别提高了119.54倍和86.761倍。平均延迟分别降低到0.8%和1.2%。
对于顺序读取和写入,我们将较大的顺序写入块直接传递到后端,并在CAS层评估顺序读取和写入的性能损失。顺序读取的带宽损耗为2.8%,而顺序写入的带宽损耗为5.6%。
OPEN-CAS的配置策略
随机访问性能的提高主要来自NVMe SSD随机访问的特性。Open-CAS相当于glue,它结合了NVMe SSD随机访问的优势和HDD大容量的优势。
对于顺序访问,可以使用多个HDD来提高生产环境中的并行性。节点中的HDD越多,顺序访问的性能越好。这种并行性可以抵消单个HDD性能受限的影响。
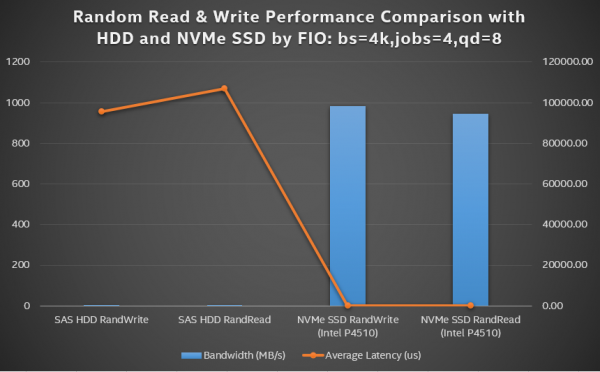
图6:R/W性能比较
Open-CAS用于加速写入过程的机制主要取决于缓存池中是否有可用或干净的缓存空间。当高速缓存池完全被脏数据“污染”时,高速缓存池对于写入无效,这也是高速缓存系统的共同特征。
下图显示了随机写入期间“脏”缓存的百分比。随着时间的流逝,越来越多的数据被写入缓存。当缓冲区完全为“脏”时,出于数据一致性考虑,必须将其刷新回后端存储以释放缓存空间。
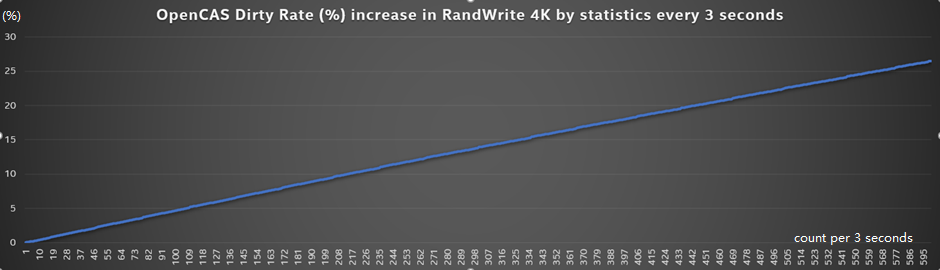 图7:CAS的增长的dirty rate%
图7:CAS的增长的dirty rate%
有两种解决方案:增加“income”和减少“expenditure”。
增加“income”意味着改善缓存刷新策略。如果您更快地将缓存数据刷新到后端存储,则可以更快地释放“受污染的”缓存空间。但由于瓶颈是刷新时随机写入HDD的性能较低,因此改进并不明显。
减少“expenditure”可以优化缓存资源的使用。此处可以考虑几种配置,例如cache-line设置,顺序访问cut-off和IO分类。配置:seq cutoff绕过缓存,在检测到顺序IO时直接写入后端存储。这样,只缓存随机访问的数据
随机读取的性能提高主要取决于读取命中率(read_hit_rate = read_cache_hit_number/total_read_access_number)。我们验证了100%的hit rate是提高性能的上限。
在实际环境中,读取命中率取决于很多因素,例如缓存容量和数据访问模式。要提高读取命中率,需要从应用程序到缓存层的全面设计。
以下是有不同访问模式的Ceph OSD设备(Open-CAS设备与缓存设备和后端设备组合)中的读写条件,这些结果由dstat工具收集:
由于设置了顺序cut-off,大块的顺序访问将直接存储到后端存储。
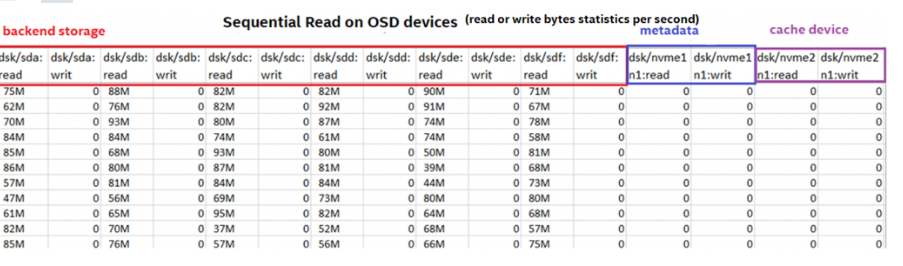 图8:在OSD上顺序读取
图8:在OSD上顺序读取

图9:在OSD上顺序写入
对于随机写入,如果写入命中或存在空闲或干净的缓存块,则可以缓存数据。下图显示了要缓存所有写操作的理想情况。
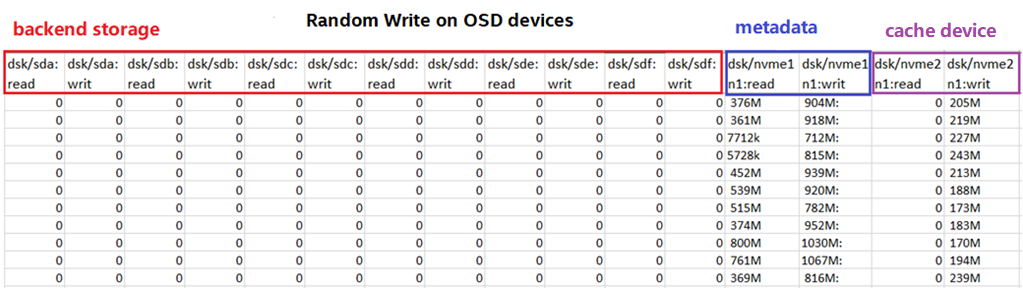
图10:在OSD上随机写入
在随机读取(命中率100%)的情况下,所有数据均从缓存中读取并使用完整的缓存功能。
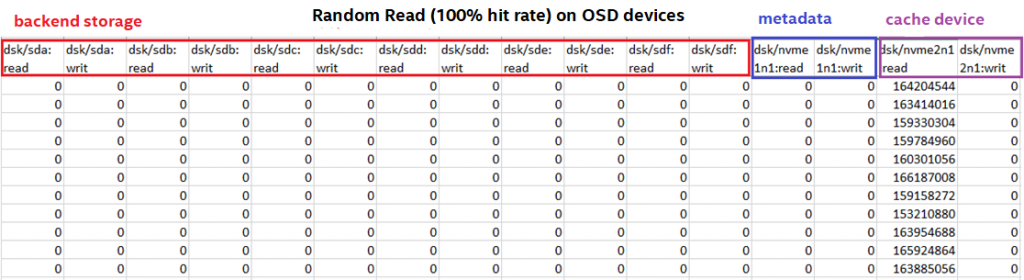
图11:在OSD上随机读取
结论与建议
本文中描述的配置适用于一般方案。它适用于具有大规模顺序访问和对Ceph集群的集中随机访问的工作场景。
对于顺序访问模式,SSD与HDD的性能对比,优势并不明显。我们将Open-CAS设置为顺序访问 cut-off并直接访问后端存储,这样可以节省宝贵的缓存池资源,并最大程度地利用其容量来处理小的随机访问数据。
当然,某些方案需要短期的高性能和低延迟。对于这些情况,请尝试完全读取和写入缓存。具体配置取决于HDD和SSD(缓存)设备的数量和并发性。
对于具有小块大小的随机写访问,性能取决于写命中率以及高速缓存池中干净或空闲高速缓存块的容量。在理想条件下(例如干净且可用的缓存块或非常高的写入命中率),在回写模式下,写入请求将直接从缓存返回到应用程序。
当缓存池中充满了脏缓存块并且写入命中率非常低时,写入性能将急剧下降,因为需要将新的写入访问数据提升为缓存块,并且必须等待旧的脏块被刷新到后端存储。
对于具有小块大小的随机读取访问,性能取决于读取命中率。如果发生读取未命中,则高速缓存需要访问后端存储以获取数据并将其提升到高速缓存。在极端情况下,需要额外刷新数据到后端存储。
以下是几种提高缓存一侧的读取命中率的方法:
使用不同的缓存模式,例如write around模式,write invalid模式等。
可以根据应用程序访问模式设置升级策略
使用应用程序预热数据
优化应用程序访问数据模型
对于一般情况,Open-CAS参考配置为write-back模式,cache-line为4KB,顺序cut-off始终处于打开状态,设置IO分类并且仅高速缓存小的随机块(请求大小<= 128KB),并使用clean具有默认警报的策略,同时调整了更多活动参数。
在理想情况下,随机读取IOPS增加119.54倍,随机写入IOPS增加86.761倍,访问延迟分别降低到0.8%和1.2%。
总结与展望
在基于HDD的存储环境中,以NVMe SSD上的Open-CAS为存储节点的Ceph集群,缓存显着提高了Ceph客户端块存储的性能,适用于小块随机读写。Ceph存储节点中的复制机制确保了缓存数据的可靠性,并且write-back模式适用于Ceph存储集群。
Open-CAS支持多种缓存模式,并具有只读,只写和读写模式的相应首选配置。使用Open-CAS缓存框架可以兼并具有NVMe SSD的高速随机读取与写入特性以及HDD的大容量特效。
以下是几种具有参考价值的业务场景:
具有低延迟要求的小型数据块的随机读取和写入方案,例如在线交易系统和银行服务,可以利用NVMe SSD的高速随机读取和写入功能。
具有大量数据的大吞吐量方案,例如视频点播,大数据分析和处理等。多个并发HDD直通模式可以确保稳定的带宽和顺序的读写功能。
参考
Open-CAS:(https://open-cas.github.io/
CeTune和github:https://github.com/intel/CeTune
附录
OPEN-CAS参数说明
Open CAS有很多参数。根据我们的经验和测试环境,我们评估并验证了影响性能的几个关键参数。
缓存模式
Open-CAS支持多种缓存模式。我们希望找出混合读/写操作的模式,主要是以较小的块大小来改善随机访问。最终,我们选择write-back模式。
在客户端,仅在本地磁盘上保留一个副本。如果磁盘物理损坏,数据将永久丢失。我们将缓存解决方案部署在Ceph存储集群上,并确保副本,避免单点故障。
下图显示了write-back模式的读/写流程。除读写过程外,Open-CAS根据清理策略将脏数据(缓存的数据与后端存储数据不一致)刷新到后端存储。
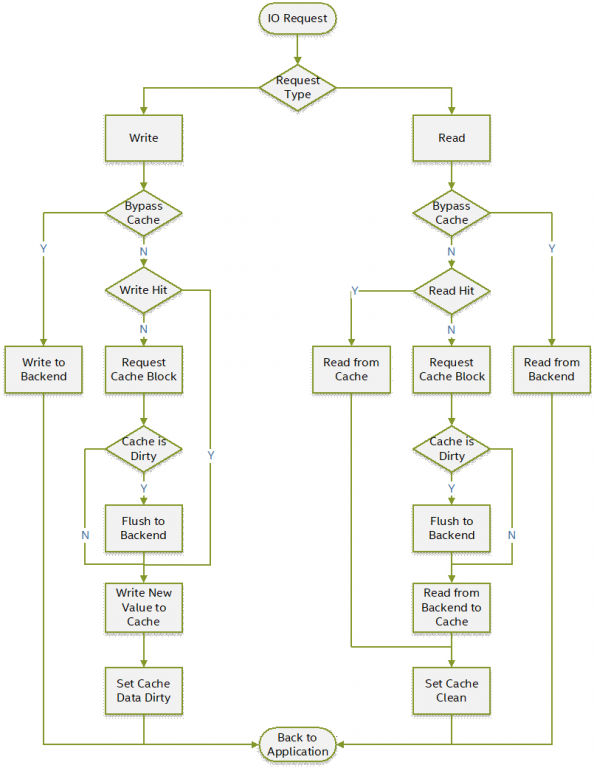
图12:IO请求流程
CACHE-LINE大小
高速缓存CACHE-LINE是可以映射到高速缓存中的数据的最小部分。每条映射的CACHE-LINE都与一条核心线关联,该核心线是后端存储上的相应区域。下图说明了缓存线和核心线之间的关系。
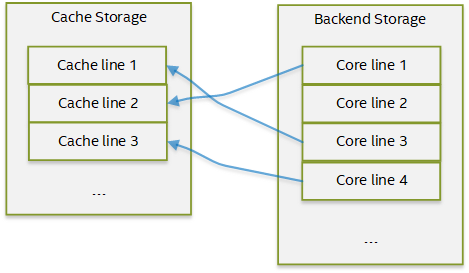
图13:缓存映射
当前系统支持的Open-CAS cache-line的默认大小范围是4K到64K。该设置在创建缓存设备时指定,并且无法在运行时修改。
对于具有NVMe SSD的缓存设备,使用HDD不会对寻道时间造成影响。读取小块与大块的带宽差异不大。cache-line设置越大,读/写请求占用的缓存空间越大;对于具有较小块大小的访问,这也浪费了缓存空间。在某些高吞吐量的情况下,例如使用Intel® Optane™ 持久 Memory,您可能需要增加cache-line以增加带宽。
顺序访问CUT-OFF
当顺序IO流达到某个阈值时,cut-off将打开。所有后续的顺序读取和写入请求都直接发送到后端存储,直到cut-off终止。
对于小的随机块,SSD的IOPS优于HDD。但是,对于大块顺序读取和写入,SSD作为缓存的优势并不明显,尤其是当一个SSD充当多个HDD的缓存时。因此,很多缓存解决方案选择绕过顺序大块的读/写,并将其直接发送到后端HDD设备。它可以节省缓存空间,并以较小的块大小容纳更多的随机访问数据。
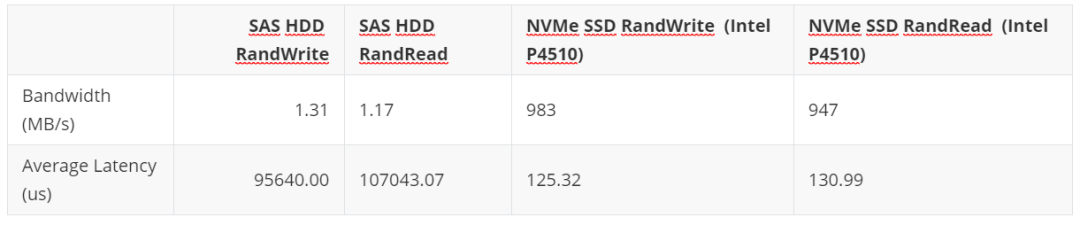
我们使用FIO(jobs = 4,queue_depth = 8)基准评估了不同模式和块大小下SAS HDD磁盘的性能。我们发现随机读取和写入性能带宽随块大小而增加(IOPS并没有太大变化),而顺序读取和写入性能受块大小的影响较小。
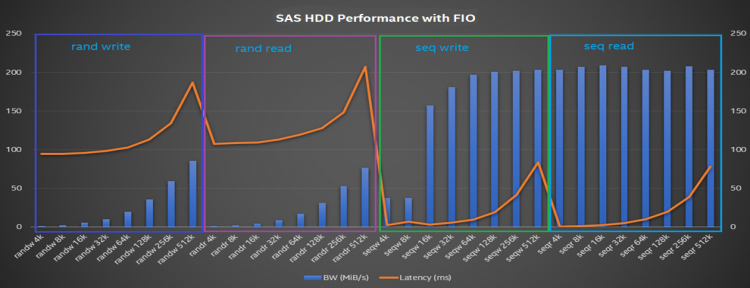 图14:带有FIO的SAS硬盘性能
图14:带有FIO的SAS硬盘性能
清理策略
在缓存系统中,Open-CAS提供刷新策略并根据参数将数据从缓存刷新到后端存储。
默认策略alru定期刷新脏数据。使用修改过的least-recently-used的算法,刷新优先级相对较低。另一种清理策略acp则是尽快清除脏的缓存行,以保持后端存储的最大带宽。
ACP策略旨在稳定write-back模式的数据刷新时间,并保持更一致的缓存性能。
我们发现acp策略的效果并不令人满意。在前台执行常规IO操作时,ACP模式会更活跃,并且刷新将无限期继续。
结果,严重影响前台的读写操作的性能。我们将刷新策略设置为alru,并调整了参数以使刷新操作更加活跃。当系统具有可用或干净的缓存空间时,alru策略会更好。

其他
Open-CAS还支持多对一模式,在该模式下,一个缓存设备可以缓存多个后端存储设备,并且这些后端存储设备的数据共享一个缓存池。
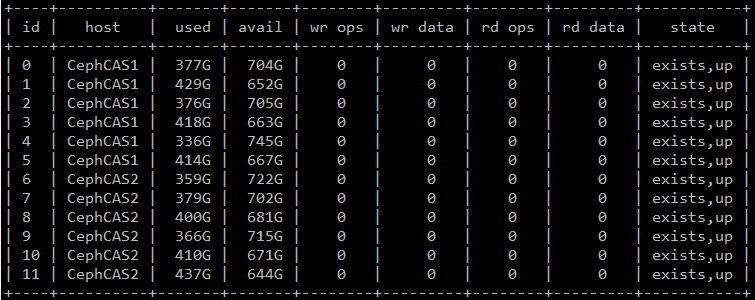
优点是可以平衡数据访问。在Ceph中,每个OSD的数据分布不一定完全平衡。共享缓存池可抵消由于数据不平衡而导致的缓存空间浪费(下面显示了典型的OSD数据分布)。
但是write-back高速缓存模式的缺点是无法避免单点故障。如果多个OSD共享一个存储池中的数据,并且该存储池包含此数据的所有副本,则情况将变得复杂。
因此,我们使用一对一模型,其中一个缓存设备对应一个后端存储设备。
除了这些参数之外,Open-CAS还提供了一些与硬盘介质相关的配置,例如对trim和atomic写入的支持,但这需要特定的缓存介质和内核版本。
*本文翻译自https://01.org/blogs/tingjie/2020/research-performance-tuning-hdd-based-ceph-cluster-using-open-cas,如有侵权请联系删除
了解新钛云服
当IPFS遇见云服务|新钛云服与冰河分布式实验室达成战略协议
新钛云服正式获批工信部ISP/IDC(含互联网资源协作)牌照
新钛云服,打造最专业的Cloud MSP+,做企业业务和云之间的桥梁
往期技术干货
刚刚,OpenStack 第 19 个版本来了,附28项特性详细解读!
OpenStack与ZStack深度对比:架构、部署、计算存储与网络、运维监控等
















 889
889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









