







背景
企业级存储中,SSD+HDD的混合盘是一种典型应用场景,可以兼顾成本、性能与容量。
但网易数帆存储团队经过测试(4k随机写)发现,加了NVMe SSD做Ceph的WAL和DB后,性能提升不足一倍且NVMe盘性能余量较大。所以我们希望通过瓶颈分析,探讨能够进一步提升性能的优化方案。
测试环境
Ceph性能分析一般先用单OSD来分析,这样可以屏蔽很多方面的干扰。 我们的测试环境如下所示,1个OSD:
usrname@hostname:~/cluster$ sudo ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-5 1.09099 root single-wal-db
-6 1.09099 host single-wal-db-69
1 hdd 1.09099 osd.1 up 1.00000 1.00000
====== osd.1 =======
devices /dev/sdc
[ wal] /dev/sdv2
PARTUUID 6b3f8b48-99ad-4ede-a4ab-0c23d5b5e162
[ db] /dev/sdv1
PARTUUID b7debf8e-0907-4b80-90b9-04443a2e5c82
性能优化初览
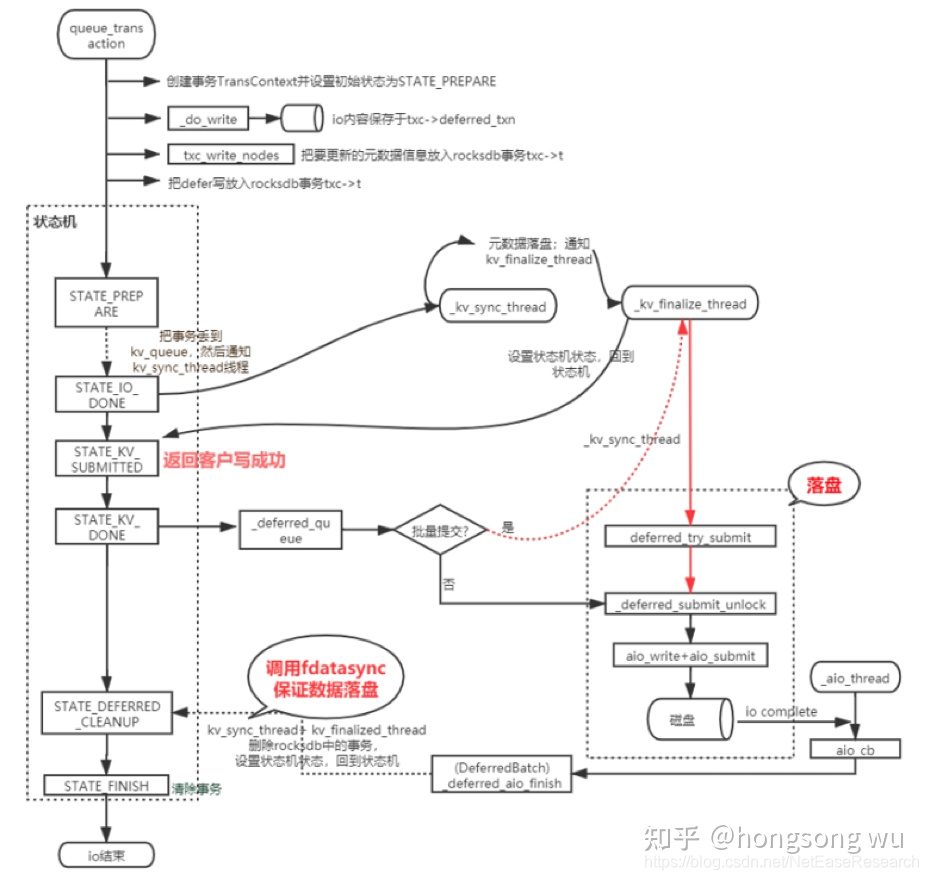
上图主要是BlueStore 对于defer write写的一个总体流程。可以看到这里的性能优化主要是两个点:
- 重耗时模块影响上下文
问题:返回客户端写成功函数+落盘在同一个线程(_kv_finalize_thread)
优化:返回写成功前保证元数据写成功即可,故可把这两个阶段拆分到不同的线程:
- 重耗时模块在IO核心路径
问题:刷盘函数fdatasync在IO关键路径上(kv_sync_thread)
优化:函数目的是确保数据落盘。故可把其移动到非IO核心路径(_deferred_aio_finish)
IO瓶颈分析
[global]
ioengine=rbd
pool=single_wal_db
rbdname=volume01(100g)
invalidate=0
rw=randwrite
bs=4k
runtime=180
[rbd_iodepth32]
iodepth=128
write: IOPS=1594, BW=6377KiB/s (6530kB/s)(374MiB/60106msec); 0 zone resets
slat (nsec): min=1249, max=721601, avg=5098.70, stdev=6069.83
clat (usec): min=1157, max=589139, avg=80279.11, stdev=77925.94
lat (usec): min=1166, max=589141, avg=80284.20, stdev=77926.06
# osd
"op_w_latency": {
"avgcount": 95824,
"sum": 7593.745711498,
"avgtime": 0.079246803
},
"op_w_process_latency": {
"avgcount": 95824,
"sum": 597.747938957,
"avgtime": 0.006237977
},
"op_before_queue_op_lat": {
"avgcount": 95887,
"sum": 3.172325348,
"avgtime": 0.000033083
},
"op_before_dequeue_op_lat": {
"avgcount": 95895,
"sum": 7001.039474373,
"avgtime": 0.073007346
},
# bluestore
"state_kv_queued_lat": {
"avgcount": 95858,
"sum": 103.287853014,
"avgtime": 0.001077508
},
"state_kv_commiting_lat": {
"avgcount": 95858,
"sum": 49.291618042,
"avgtime": 0.000514214
},
"throttle_lat": {
"avgcount": 95858,
"sum": 280.404541330,
"avgtime": 0.002925207
},
"commit_lat": {
"avgcount": 95858,
"sum": 436.058305735,
"avgtime": 0.004549002
},
代码深度分析与代码优化
从上面耗时分析可以看出,op_before_dequeue_op_lat这个阶段的耗时占了大头,从如下代码可以看出,该阶段是从收到op到op出队列的时间:
void OSD::dequeue_op()
{
utime_t now = ceph_clock_now();
utime_t latency = now - op->get_req()->get_recv_stamp();
logger->tinc(l_osd_op_before_dequeue_op_lat, latency);
pg->do_request(op, handle);
}
另外发现还有一个关键阶段的耗时统计,即op_before_queue_op_lat,如如下代码可以看出,该阶段是从收到op到op入队列之前的时间:
void OSD::enqueue_op(spg_t pg, OpRequestRef& op, epoch_t epoch)
{
utime_t latency = ceph_clock_now() - op->get_req()->get_recv_stamp();
ogger->tinc(l_osd_op_before_queue_op_lat, latency);
op_shardedwq.queue(make_pair(pg, PGQueueable(op, epoch)));
}
从OSD的时延统计可以看出,op_before_dequeue_op_lat耗时很长,但是op_before_queue_op_lat耗时很短,这可以说明耗时主要花费在工作线程入队到出队这块。
基于这个认识,所以首先考虑到的便是PG锁或者线程数太少处理不过来,第一步便是考虑调大Ceph逻辑pool的pg数,但是调大后,发现性能未有改变;所以进一步考虑调大线程数量,如下:
#osd_op_num_shards_hdd = 5(10)
#osd_op_num_threads_per_shard_hdd = 1(2)
write: IOPS=1571, BW=6286KiB/s (6437kB/s)(369MiB/60057msec); 0 zone resets
slat (nsec): min=1169, max=459761, avg=4347.07, stdev=5058.94
clat (usec): min=1903, max=8069.2k, avg=81438.80, stdev=294739.08
lat (usec): min=1919, max=8069.2k, avg=81443.15, stdev=294739.04
# osd
"op_w_latency": {
"avgcount": 94385,
"sum": 7544.120278825,
"avgtime": 0.079929228
},
"op_w_process_latency": {
" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3510
3510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











