







 新钛云服已为您服务1020天文档说明HDFS的缩放限制。我们描述Ceph及其元素,并提供安装可与Hadoop一起使用的演示系统的说明。Hadoop已经成为一个非常流行的大规模数据分析平台。...
新钛云服已为您服务1020天文档说明HDFS的缩放限制。我们描述Ceph及其元素,并提供安装可与Hadoop一起使用的演示系统的说明。Hadoop已经成为一个非常流行的大规模数据分析平台。...

新钛云服已为您服务1020天
文档说明
HDFS的缩放限制。我们描述Ceph及其元素,并提供安装可与Hadoop一起使用的演示系统的说明。
Hadoop已经成为一个非常流行的大规模数据分析平台。这种流行对Hadoop的可伸缩性和功能提出了更高的要求,并揭示了其底层文件系统的一个重要架构限制:HDFS只提供一个名称节点,该节点必须将整个文件系统名称空间存储在主内存中。这就对HDFS可以存储的元数据的数量,特别是文件的数量有了严格的限制。
在Hadoop用户和开发人员社区中,单名称节点的限制是公认的。大型集群经常在名称节点上耗尽容量来跟踪新文件,即使数据节点上有足够的存储容量。对于需要相对大量的元数据操作(如打开和关闭文件)的工作负载,单名称节点还会造成单点故障和潜在的性能瓶颈。
ceph特性
Ceph是一个基于对象的并行文件系统,具有许多特性,使其成为Hadoop的理想候选存储系统:
Ceph的可伸缩元数据服务器可以分布在数百个节点上,同时使用动态子树分区提供一致、可靠、高性能的元数据服务,具有近乎线性的可伸缩性。
每个文件都可以指定自己的条带化策略和对象大小。灵活的条带化策略和对象大小是Hadoop工作负载的重要调整参数
数据存储在多达10000个节点上,这些节点导出具有对象ID的平坦命名空间的单个可靠对象服务,这与亚马逊的简单存储服务不同。存储集群大小的变化导致数据的自动(快速)故障恢复和重新平衡,而不中断服务和最小数据移动,使Ceph适合于非常大的部署。
由于计算出的数据放置与分配表相反,ing数据放置、故障节点和恢复状态具有非常紧凑的表示形式,并且在Ceph的每个部分中都是已知的。与HDFS一样,Hadoop的调度器可以利用这些信息将映射放置在数据所在的位置附近。
Ceph是一个开源项目(ceph.newdream.net网站写在C++和C,作为一个博士研究项目在加州大学四年前开始,并一直处于严重发展至今。用于将Ceph集成到Hadoop中的Hadoop模块自0.12版以来一直在开发中,Hadoop还可以通过其POSIX I/O接口访问Ceph,使用ioctl调用获取数据位置信息。
由于Ceph被设计成一个通用文件系统(例如,它提供了一个Linux内核客户机,因此Ceph文件系统可以挂载),如果它能够很好地支持Hadoop工作负载,那么它也可以作为其他存储需求的通用解决方案。
Ceph
Ceph在2005年规定的以下目标:
一到数千个硬盘上的PB数据。
TB/秒一到数千个硬盘上的总吞吐量尽可能快地输出数据。
数十亿个文件组织在每个目录中的一到数千个文件中。
文件大小从字节到兆字节不等。
元数据访问时间(微秒)。
从数千个客户机到。
不同目录中的不同文件。
同一目录下的不同文件。
同一文件。
中等性能本地数据访问。
广域通用通道
这种文件系统面临的挑战是,它需要能够处理巨大的文件和目录,协调数千个磁盘的活动,提供大规模元数据的并行访问,处理科学和通用工作负载,在规模上进行身份验证和加密,以及因频繁使用而动态增长或收缩设备停用、设备故障和群集扩展。不能因为磁盘故障或空间不足就关闭系统。
Ceph是一个基于对象的并行文件系统,其设计基于两个关键思想。第一个关键思想是基于对象的存储,它将传统的文件系统体系结构分为客户机组件和存储组件。
存储组件在本地管理磁盘调度和布局,使客户机和服务器不再需要低级别的每磁盘详细信息,并提高了可扩展性。这种设计允许客户机通过高级接口与存储节点通信,并以对象的形式管理数据,对象是比512字节块大得多的数据块。
SCSI对象存储设备(OSD)命令集的T10标准是对象接口规范的一个示例。Ceph使用并显著扩展了osd的概念。出于所有实际目的,请将Ceph OSD视为在集群节点上运行并使用本地文件系统存储数据对象的进程。
Ceph设计的第二个关键思想是数据和元数据的分离。数据的管理与元数据的管理有着根本的区别:文件数据存储的并行性很低,主要受网络基础设施的限制。元数据管理要复杂得多,因为层次目录结构带来了相互依赖性(例如,POSIX访问权限依赖于父目录),元数据服务器必须保持文件系统的一致性。
元数据服务器必须承受繁重的工作负载:所有文件系统操作中有30–80%涉及元数据,因此在许多小型元数据项上有大量事务遵循各种使用模式。因此,良好的元数据性能对整个系统性能至关重要。流行的文件和目录是常见的,并发访问可以压倒许多方案。
Ceph设计的三个独特方面是:
在单独的元数据服务器(MDS)集群中进行分布式元数据管理,该集群使用动态子树分区来避免元数据访问热点,并对非拜占庭故障具有鲁棒性;
计算伪随机数据放置,允许在整个系统中轻松共享非常紧凑的状态(压缩)
分布式对象存储,使用智能OSD集群,形成可自主智能操作的可靠对象存储(RADOS)
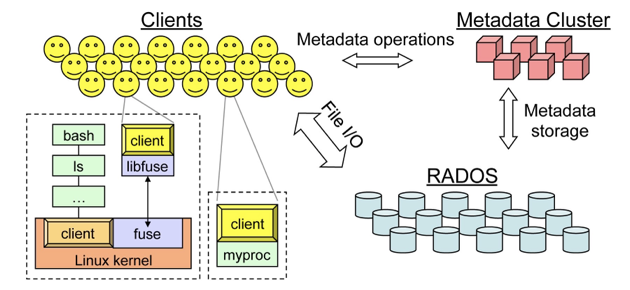
在单独的元数据服务器(MDS)集群中进行分布式元数据管理,该集群使用动态子树分区来避免元数据访问热点。
计算伪随机数据放置,允许在整个系统中轻松共享非常紧凑的状态(压缩)以及分布式对象存储,使用智能OSD集群,形成可自主智能操作的可靠对象存储(RADOS)。
Client
用户或应用程序通过客户端组件与Ceph交互。客户端公开了一个POSIX文件系统接口。该接口还支持用于高性能计算的POSIX I/O扩展的一个子集,包括POSIX open命令的Oïu LAZY标志,该标志允许注重性能的应用程序管理自己的一致性[15]。
Ceph有一个用户级客户端和一个内核客户端。用户级客户端要么直接链接到应用程序,要么通过FUSE使用。内核客户机现在可以在主线Linux内核中使用(从2.6.34开始),并允许装载Ceph文件系统。
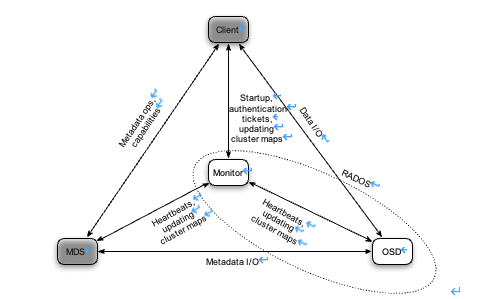
对于客户端如何与Ceph系统的其余部分交互的一个简单示例,请考虑客户端打开一个文件/foo/bar进行读取:客户端向MDS发送一条“openforread”消息
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 394
394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









