







 本文详述了在一个5节点Ceph集群上进行CephFS性能基准测试的过程,包括硬件环境、软件配置、IO500基准测试、网络性能测试以及各种优化策略,如禁用C6、调整MDS、增加客户端和消除瓶颈等。通过测试,发现优化MDS缓存和客户端设置能显著提升性能,而某些调整如增大MTU反而导致性能下降。最终,测试表明Ceph的性能受限于多个因素,而最佳配置需谨慎调整。
本文详述了在一个5节点Ceph集群上进行CephFS性能基准测试的过程,包括硬件环境、软件配置、IO500基准测试、网络性能测试以及各种优化策略,如禁用C6、调整MDS、增加客户端和消除瓶颈等。通过测试,发现优化MDS缓存和客户端设置能显著提升性能,而某些调整如增大MTU反而导致性能下降。最终,测试表明Ceph的性能受限于多个因素,而最佳配置需谨慎调整。

新钛云服已为您服务1256天
本次测试的目的是通过使用 INTEL SSD PEYKX040T8 NVMe 驱动器从而在 Ceph 集群(特别是 CephFS)中实现最大的性能。同时为了保证本次测试的整体公平,故将会使用行业标准 IO500 基准测试来评估整个存储的性能。
备注:本次只使用了5节点的Ceph集群,因此无法正式提交结果到测试官网(至少需要10个节点),但是基准测试的分数已经足以进入最佳排名的前40名——2019 年的 10 节点存储系统。
硬件准备
本次提供了以下的实验环境,该实验环境由连接到 100Gbps 网络的七台 Supermicro 服务器组成。其中六台服务器具有以下规格:
型号:SSG-1029P-NES32R
主板:X11DSF-E
CPU:2x Intel(R) Xeon(R) Gold 6252 CPU @ 2.10GHz(Turbo 频率高达 3.70 GHz),总共 96 个虚拟内核
RAM:8x Micron Technology 36ASF4G72PZ-2G9E2 32GB DDR4 DIMM,即总共 256 GB,配置为 2400 MT/s 但能够达到 2933 MT/s
磁盘:8x INTEL SSDPEYKX040T8 NVMe 驱动器,每个 4TB
其他磁盘:64GB SATA SSD
板载网络:2x Intel Corporation Ethernet Controller 10G X550T [8086:1563]
PCIe 以太网卡:Mellanox Technologies MT27700 系列 [ConnectX-4] [15b3:1013] 带有两个 QSFP 端口,每个端口均能达到 100 Gbps
此外,还有一台配置与上面不同的服务器:
型号:SSG-1029P-NMR36L
主板:X11DSF-E
CPU:Intel(R) Xeon(R) Gold 6138 CPU @ 2.00GHz(Turbo 频率高达 3.70 GHz),总共 80 个虚拟内核
RAM:8x SK Hynix HMA84GR7CJR4N-WM 32GB DDR4 DIMM,即总共 256 GB,配置为 2666 MT/s 但能够达到 2933 MT/s
磁盘:32 个 SAMSUNG MZ4LB3T8HALS NVMe 驱动器,每个 3.84 TB(未使用)
其他磁盘:64GB SATA SSD
板载网络:2x Intel Corporation Ethernet Controller 10G X550T [8086:1563]
PCIe 以太网卡:Mellanox Technologies MT27700 系列 [ConnectX-4] [15b3:1013] 带有两个 QSFP 端口,每个端口均能达到 100 Gbps
在所有服务器上,板载网络仅用于 IPMI 和管理。在每个 Mellanox 网卡的两个 100Gbe 端口中,只有一个使用直连网线连接到运行 Cumulus Linux 4.2 的 SSE-C3632S 交换机。
测试软件
在测试期间,SSG-1029P-NMR36L 服务器用作测试的管理服务器的同时也用作运行基准测试的主机。由于单个 100Gbps 链路很可能不足以展示出集群的性能,因此其中一台 SSG-1029P-NES32R 服务器也将会只用于客户端。在这两台服务器上,都安装了 Debian 10.5。内核是从 Debian 的“backports”存储库安装的,以便获得 cephfs 客户端的最新安装版本。
剩下的五台 SSG-1029P-NES32R 服务器用于 Ceph 集群(使用 Ceph 14.2.9),通过从管理节点网络来管理它们。内核版本为 4.19。
CEPH 集群
五台服务器参与了 Ceph 集群。在三台服务器上,较小的 SATA SSD 用于 MON 磁盘。在每个 NVMe 驱动器上,创建一个 OSD。在每台服务器上,都配置了一个 MDS(负责 cephfs 元数据的Ceph核心组件)。
通过并行元数据操作从而获取最大的性能,五个节点中,四个 MDS 服务器将被标记为active的,剩下的一个作为standby。请注意:对于生产 Ceph 集群,多个active的 MDS 服务器仍然可能会存在一些问题,所以请慎用!!!
在客户端节点上,使用内核 cephfs 客户端,在 /etc/fstab 中添加如下的内容,保证开机即可挂载:
:/ /mnt/cephfs ceph name=admin,_netdev 0 0所有客户端和服务器都在一个二层的网络中,网络段为 10.10.49.0/24。同时每个节点都设置了ssh无密码登录,因为这是 OpenMPI 的要求,同时 IO500 基准测试使用 OpenMPI 以并行和分布式方式运行工作程序。
最初,我们打算将本次基准测试结果与另一个 Ceph 集群进行比较,后者每个节点有 6 个 OSD。因此,本次环境中,我们将每个主机上的两个 NVMe 分配到单独的设备类。然而,最终我们并没有这样做对比。尽管如此,大多数基准测试都是在每个节点只有 6 个 NVMe OSD 的情况下完成的。
Ceph存储被创建了三个存储池:cephfs_metadata(64 个 PG)、cephfs_data(512 个 PG)和 rbd_benchmark(也是 512 个 PG)。因此,虽然每个 OSD 的 PG 总数接近理想值,但 cephfs 在数据池中使用的 PG 比在这种情况下通常使用的 PG 少(即 1024)。理论上,太少的 PG 会导致数据不平衡(本次测试中,我们并不真正关心该问题),而太多的 PG 可能会造成性能问题。
IO500 基准测试
IO500 是 Virtual Institute for I/O 管理的存储基准测试软件。它测量不同场景下基于集群的文件系统的带宽和 IOPS 数据,并得出最终分数作为在所有测试阶段获得的性能指标的平均值。在每个阶段,执行“ior”工具(用于带宽测试)或“mdtest”工具(用于测试各种元数据操作的性能)的多个副本并将结果合并。还有一个基于并行“find”操作的阶段。作为实现细节,MPI 用于编排。
各个阶段的执行顺序是这样组织的,即基于 ior 和基于 mdtest 的阶段大多相互交错。
带宽测试阶段
带宽测试是使用“ior”工具完成的。有两个“difficulty”级别(easy 与 hard),对于每个级别,带宽分别针对写入和读取进行测量。基准测试结束时报告的带宽数字是所有四项测试的平均值。
默认情况下,两个difficulty级别的写入都需要 5 分钟,使用 POSIX 进行文件系统访问。在easy模式下,每个 ior 进程使用一个文件,并以 256 KiB 的传输大小顺序完成写入。在hard模式下,所有进程都写入同一文件的交错部分,使用47008 字节传输大小和“jumpy”线性访问(lseek() 对其他进程要写入的字节,写入 47008 字节,重复循环)。在这两种情况下,每个进程最后只执行一次 fsync() 调用,即基本上不受队列深度限制。
对于有多个客户端的 CephFS,hard I/O 模式确实很麻烦:每次写入都会导致一个RADOS对象的部分修改,该对象以前曾被另一个客户机修改,并且正在可能被另一个客户机同时修改,因此写入必须以原子方式执行。缺少fsync()调用(最后除外)也无济于事:fsync()保证数据访问稳定的存储,但此测试关心的是客户端之间的数据一致性,这是完全不同的事情,在兼容POSIX的文件系统中无法关闭。
因此,即使测试以GiB/s的速度显示结果,它也主要受到客户端和元数据服务器之间通信延迟的影响。
对于读取,easy和hard测试都使用与前面编写的相同的文件,以相同的方式访问它们,并验证文件中的数据是否与预期的签名匹配。
IOPS 测试阶段
几乎所有的 IOPS 测试都是使用“mdtest”工具完成的。与 ior 不同,mdtest 创建了大量文件并强调元数据操作。
就像带宽测试一样,测试有两个“difficulty”级别:easy和hard。对于每个difficulty,每个进程在“创建”阶段创建大量的测试文件(最多一百万个),然后在测试的“统计”阶段检查所有文件,然后在“删除”阶段删除所有文件. 在每个阶段结束时,都会执行“sync”命令并统计其运行时间。
hard测试与easy测试的不同之处在于以下几个方面:
easy测试中每个文件都是空的,在“创建”阶段写入 3901 个字节,然后在hard测试中读回;每个进程在简单的情况下获得一个唯一的工作目录,在
hard测试中使用一个共享目录。
原始存储性能
fio 是最常用的基准测试工具,用于评估数据库应用程序中磁盘驱动器的原始性能。在后台,选择针对并行具体作业数量(从 1 到 16)运行此命令:
fio --filename=/dev/XXX --direct=1 --fsync=1 --rw=write --bs=4k --numjobs=YYY --iodepth=1 --runtime=60 --time_based --group_reporting --name=4k-sync-write-YYY此基准测试作为 NVMe 驱动器的基础性能测试,并用于客观地比较它们在各种 BIOS 设置下的性能。
一个直接的发现是,不同的服务器拥有不同的性能,特别是在基准测试的单作业中,其IOPS介于78K和91K之间。16个作业的数据更加一致,仅显示548K(奇怪的是,在单作业基准测试中速度最快的服务器上)和566K IOPS之间的差异。
这种变化的原因最初被认为在于最初出现在服务器上的“CPU 配置”菜单中的 BIOS 设置不同。事实上,从高性能存储读取数据本身就是一个 CPU 密集型活动:在这种情况下,30% 的 CPU 被 fio 消耗,12% 被“ kworker/4:1H-kblockd”内核线程消耗。因此,让 CPU 达到尽可能高的时钟频率是合理的。
其实将 BIOS 的“高级电源管理配置”区域中的“电源技术”参数设置为“禁用”是错误的做法。它会将 CPU 频率锁定到最高非 Turbo 状态,即 2.10 GHz,并使 3.70 GHz 频率不可用。然后,fio 存储基准测试将只产生 66K IOPS,这太糟糕了。
此 BIOS 区域中的另一个选项决定是 BIOS 还是操作系统控制能效偏差。如果将控制权交给 BIOS,则有一个设置告诉它要做什么,而对于“Power Technology”参数的“Manual”设置,有很多选项可以微调 C-、P- 和T 状态。考虑到能效偏差控制以及对 C-、P-、和 CPU 的 T 状态,提供给操作系统。
在这两种情况下,NVMes 最初的基准测试为 89K-91K IOPS。不幸的是,后来的一些调优(不知道具体是什么)破坏了这一结果,最终结果再次是单线程的 84K 和 87K 写入 IOPS 之间的性能不一致。
好吧,至少从现在开始,所有服务器上的 BIOS 设置都变得一致 —— 请参见下表。这些设置背后的想法是尽可能多地控制操作系统而不是硬件或 BIOS 的 CPU 状态。我们还发现超线程、LLC Prefetch 和 Extended APIC 没有显着影响存储性能。因此,所有 CPU 功能都已启用。
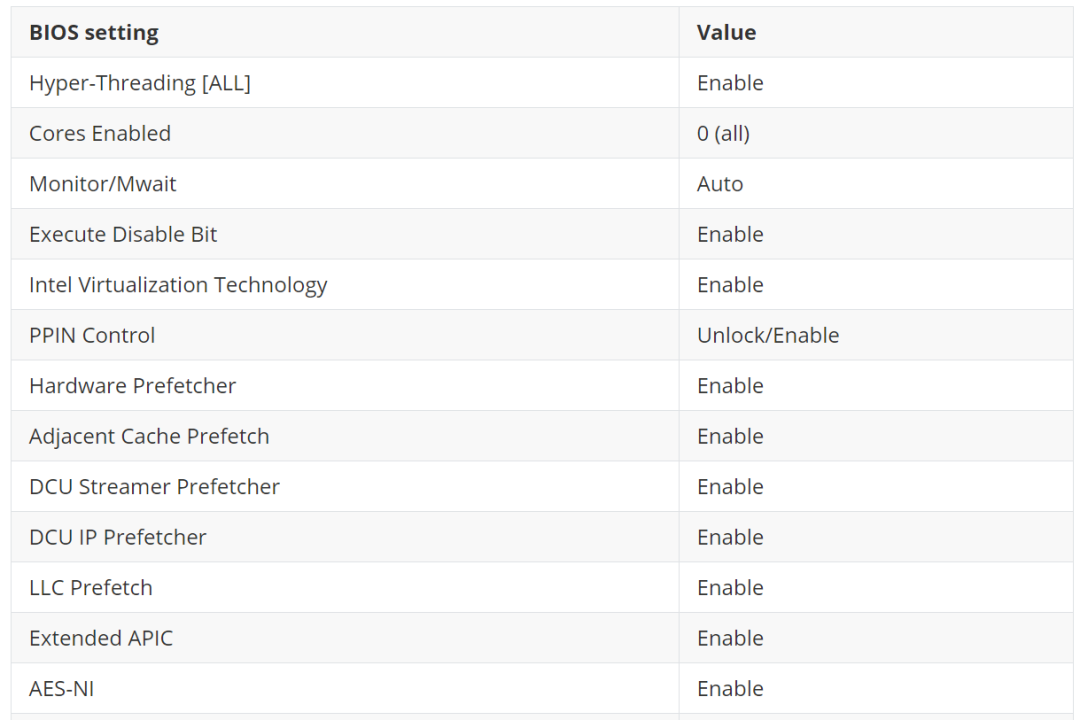
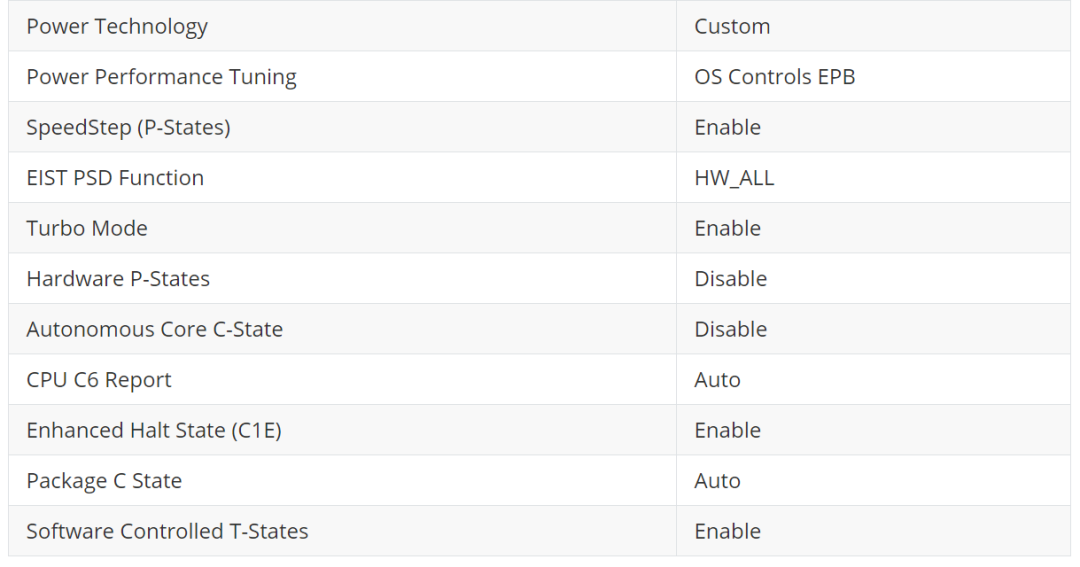
网络性能
Mellanox 适配器无需任何调整即可达到 85+ Gbps 的吞吐量,但为此需要多个 TCP 流。将 net.core.rmem_max sysctl 设置为一个较大的值会进一步将可实现的吞吐量提高到 94 Gbit/s,但不会提高基准分数,所以没有进行操作。
为了体现出最佳的吞吐量,我们在两台主机上运行了 iperf(版本 2.0.12),如下所示:
在“server”上:iperf -s -p 9999
在“client”上:iperf -c 10.10.49.33 -p 9999,其中 10.10.49.33 是服务器 IP
对于单个 TCP 流,iperf 表示吞吐量为 39.5 Gbit/s。为了同时使用四个流,在客户端添加了“-P 4”参数,使吞吐量达到了 87.8 Gbit/s。
吞吐量是好的,但请记住,IOR500 的一些测试实际上是针对延迟的,还需要对其进行优化。对于延迟测试,我们使用了两个客观基准:
在 RBD 设备上测量 4k 大小的写入 IOPS;
只是ping另一个主机。
RBD 基准命令(比 IOR500 更激进)是:
fio --ioengine=rbd --pool=rbd_benchmark --rbdname=rbd0 --direct=1 --fsync=1 --rw=write --bs=4k --numjobs=1 --iodepth=1 --runtime=60 --time_based --group_reporting --name=4k-sync-write-1没有任何调整,它仅达到 441 IOPS。是的,与原始存储相比减少了 200 多倍。
这里的限制因素之一是 CPU 时钟速度。Linux 内核中默认的“powersave”CPU 频率调节器将 CPU 时钟保持在较低水平,直到它发现工作负载太重。在这种情况下,它可能仍然“太低”(27%)并且不被视为提高频率的充分理由——这可以通过grep MHz /proc/cpuinfo | sort | tail -n 4在 fio 的命令来确认。
一旦在客户端和 Ceph OSD 节点 ( cpupower frequency-set -g performance)上将 CPU 频率调节器更改为“performance” ,情况就会改善:2369 IOPS。
优化网络延迟
正如已经提到的,IO500 基准测试对网络延迟很敏感。在没有任何调整的情况下,延迟(由“ping”命令报告)为 0.178 毫秒,这意味着在整个请求-响应周期中,仅浪费了 0.356 毫秒。ping 时间在这里加倍,因为有两个跃点延迟很重要:从客户端到主 OSD,以及从主 OSD 到辅助 OSD。上一节的 fio 基准测试中每秒有 2369 个这样的周期,因此每个周期平均持续 0.422 毫秒。因此,看起来减少延迟是非常重要的。
事实证明,CPU 负载足够低,其内核通过进入节能 C-states来降低使用。最深的这种状态是 C6,根据“ cpupower idle-info”,从它转换出来需要 0.133 毫秒。接下来的状态是 C1E、C1 和“CPUIDLE CORE POLL IDLE”(不节省任何电量),所有这些状态都需要不到 0.01 毫秒才能退出。
因此,下一个调整步骤是禁用 C6 状态。执行此操作的命令“ cpupower idle-set -D 11”实际上意味着“禁用所有需要超过 0.011 毫秒才能退出的空闲状态”。结果:ping 时间下降到 0.054 毫秒,但 fio 基准测试仅产生 2079 IOPS - 比以前更糟。这可能是因为不在 C6 中的内核会降低 CPU 可用的最大频率,而且,在这个“fio”基准测试中,达到可能的最高频率实际上更为重要。
尽管如此,正如我们稍后将看到的,禁用 C6 对整体 IO500 分数是有益的。
正式运行IO500基准测试
IO500 基准测试的源代码来自https://github.com/VI4IO/io500-app。本次使用的是“io500-isc20”分支(指向commit 46e0e53)的代码无法编译,因为“extern”变量使用不当。
幸运的是,该错误修复可从同一存储库的主分支中获得。因此,所有的基准测试都是通过 commit 20efd24 完成的。我们知道新的 IO500 版本已于 2020 年 10
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 60
60

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









