







DFA简介
在实现文字过滤的算法中,DFA是唯一比较好的实现算法。DFA即Deterministic Finite Automaton,也就是确定有穷自动机,它是是通过event和当前的state得到下一个state,即event+state=nextstate。下图展示了其状态的转换
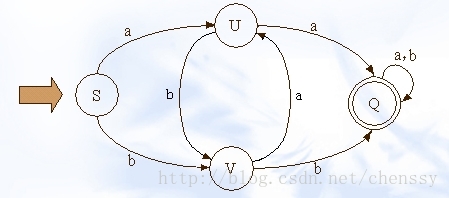
在这幅图中大写字母(S、U、V、Q)都是状态,小写字母a、b为动作。通过上图我们可以看到如下关系
a b b
S -----> U S -----> V U -----> V
在实现敏感词过滤的算法中,我们必须要减少运算,而DFA在DFA算法中几乎没有什么计算,有的只是状态的转换。
参考文献:http://www.iteye.com/topic/336577
Java实现DFA算法实现敏感词过滤
在Java中实现敏感词过滤的关键就是DFA算法的实现。首先我们对上图进行剖析。在这过程中我们认为下面这种结构会更加清晰明了。
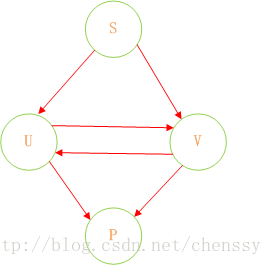
同时这里没有状态转换,没有动作,有的只是Query(查找)。我们可以认为,通过S query U、V,通过U query V、P,通过V query U P。通过这样的转变我们可以将状态的转换转变为使用Java集合的查找。
诚然,加入在我们的敏感词库中存在如下几个敏感词:日本人、日本鬼子、毛.泽.东。那么我需要构建成一个什么样的结构呢?
首先:query 日 ---> {本}、query 本 --->{人、鬼子}、query 人 --->{null}、query 鬼 ---> {子}。形如下结构:
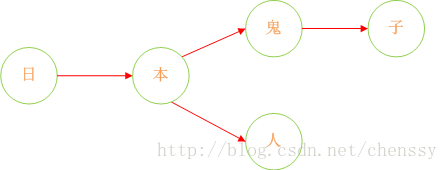
下面我们在对这图进行扩展:
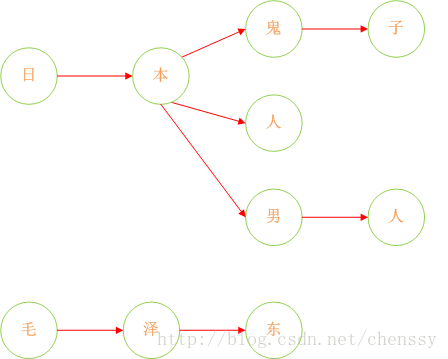
这样我们就将我们的敏感词库构建成了一个类似与一颗一颗的树,这样我们判断一个词是否为敏感词时就大大减少了检索的匹配范围。比如我们要判断日本人,根据第一个字我们就可以确认需要检索的是那棵树,然后再在这棵树中进行检索。
但是如何来判断一个敏感词已经结束了呢?利用标识位来判断。
所以对于这个关键是如何来构建一棵棵这样的敏感词树。下面我已Java中的HashMap为例来实现DFA算法。具体过程如下:
日本人,日本鬼子为例
1、在hashMap中查询“日”看其是否在hashMap中存在,如果不存在,则证明已“日”开头的敏感词还不存在,则我们直接构建这样的一棵树。跳至3。
2、如果在hashMap中查找到了,表明存在以“日”开头的敏感词,设置hashMap = hashMap.get("日"),跳至1,依次匹配“本”、“人”。
3、判断该字是否为该词中的最后一个字。若是表示敏感词结束,设置标志位isEnd = 1,否则设置标志位isEnd = 0;
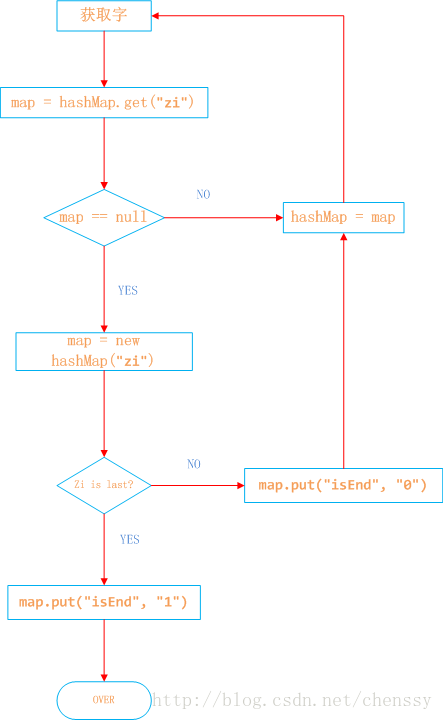
程序如下:
public class BanWordUtil {
private final static Logger logger = LoggerFactory.getLogger(BanWordUtil.class);
/**
* 敏感词库
*/
public static Map sensitiveWordMap = null;
/**
* 只过滤最小敏感词
*/
public static int minMatchTYpe = 1;
/**
* 过滤所有敏感词
*/
public static int maxMatchType = 2;
/**
* 敏感词库敏感词数量
*
* @return
*/
public int getWordSize()
{
if (BanWordUtil.sensitiveWordMap == null)
{
return 0;
}
return BanWordUtil.sensitiveWordMap.size();
}
/**
* 是否包含敏感词
*
* @param txt
* @param matchType
* @return
*/
public boolean isContaintSensitiveWord(String txt, int matchType)
{
boolean flag = false;
for (int i = 0; i < txt.length(); i++)
{
int matchFlag = checkSensitiveWord(txt, i, matchType);
if (matchFlag > 0)
{
flag = true;
}
}
return flag;
}
/**
* 获取敏感词内容
*
* @param txt
* @param matchType
* @return 敏感词内容
*/
public Set<String> getSensitiveWord(String txt, int matchType)
{
Set<String> sensitiveWordList = new HashSet<String>();
for (int i = 0; i < txt.length(); i++)
{
int length = checkSensitiveWord(txt, i, matchType);
if (length > 0)
{
// 将检测出的敏感词保存到集合中
sensitiveWordList.add(txt.substring(i, i + length));
i = i + length - 1;
}
}
return sensitiveWordList;
}
/**
* 替换敏感词
*
* @param txt
* @param matchType
* @param replaceChar
* @return
*/
public String replaceSensitiveWord(String txt, int matchType, String replaceChar)
{
String resultTxt = txt;
Set<String> set = getSensitiveWord(txt, matchType);
Iterator<String> iterator = set.iterator();
String word = null;
String replaceString = null;
while (iterator.hasNext())
{
word = iterator.next();
replaceString = getReplaceChars(replaceChar, word.length());
resultTxt = resultTxt.replaceAll(word, replaceString);
}
return resultTxt;
}
/**
* 替换敏感词内容
*
* @param replaceChar
* @param length
* @return
*/
private String getReplaceChars(String replaceChar, int length)
{
String resultReplace = replaceChar;
for (int i = 1; i < length; i++)
{
resultReplace += replaceChar;
}
return resultReplace;
}
/**
* 检查敏感词数量
*
* @param txt
* @param beginIndex
* @param matchType
* @return
*/
public int checkSensitiveWord(String txt, int beginIndex, int matchType)
{
boolean flag = false;
// 记录敏感词数量
int matchFlag = 0;
char word = 0;
Map nowMap = sensitiveWordMap;
for (int i = beginIndex; i < txt.length(); i++)
{
word = txt.charAt(i);
// 判断该字是否存在于敏感词库中
nowMap = (Map) nowMap.get(word);
if (nowMap != null)
{
matchFlag++;
// 判断是否是敏感词的结尾字,如果是结尾字则判断是否继续检测
if ("1".equals(nowMap.get("isEnd")))
{
flag = true;
// 判断过滤类型,如果是小过滤则跳出循环,否则继续循环
if (BanWordUtil.minMatchTYpe == matchType)
{
break;
}
}
}
else
{
break;
}
}
if (!flag)
{
matchFlag = 0;
}
return matchFlag;
}
/**
* 初始化敏感词
* @return
*/
public Map initKeyWord(String[] sensitiveWords)
{
try
{
// 从敏感词集合对象中取出敏感词并封装到Set集合中
Set<String> keyWordSet = new HashSet<String>();
for (String s : sensitiveWords)
{
keyWordSet.add(s.trim());
}
// 将敏感词库加入到HashMap中
addSensitiveWordToHashMap(keyWordSet);
}
catch (Exception e)
{
e.printStackTrace();
}
return sensitiveWordMap;
}
/**
* 封装敏感词库
* @param keyWordSet
*/
private void addSensitiveWordToHashMap(Set<String> keyWordSet)
{
// 初始化HashMap对象并控制容器的大小
sensitiveWordMap = new HashMap(keyWordSet.size());
// 敏感词
String key = null;
// 用来按照相应的格式保存敏感词库数据
Map nowMap = null;
// 用来辅助构建敏感词库
Map<String, String> newWorMap = null;
// 使用一个迭代器来循环敏感词集合
Iterator<String> iterator = keyWordSet.iterator();
while (iterator.hasNext())
{
key = iterator.next();
// 等于敏感词库,HashMap对象在内存中占用的是同一个地址,所以此nowMap对象的变化,sensitiveWordMap对象也会跟着改变
nowMap = sensitiveWordMap;
for (int i = 0; i < key.length(); i++)
{
// 截取敏感词当中的字,在敏感词库中字为HashMap对象的Key键值
char keyChar = key.charAt(i);
// 判断这个字是否存在于敏感词库中
Object wordMap = nowMap.get(keyChar);
if (wordMap != null)
{
nowMap = (Map) wordMap;
}
else
{
newWorMap = new HashMap<String, String>();
newWorMap.put("isEnd", "0");
nowMap.put(keyChar, newWorMap);
nowMap = newWorMap;
}
// 如果该字是当前敏感词的最后一个字,则标识为结尾字
if (i == key.length() - 1)
{
nowMap.put("isEnd", "1");
}
}
}
}
}















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









