







kaggle上的一个经典入门比赛:https://www.kaggle.com/c/titanic/overview
工具:kaggle kernel
数据处理
先导包:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
导入数据看看情况:
df_train=pd.read_csv("../input/train.csv")
print(df_train.info())
df_test=pd.read_csv("../input/test.csv")
print(df_test.info())
data=[df_train,df_test]
dataset=pd.concat(data)
print(dataset.info())
print(df_train.shape)
print(df_test.shape)
print(dataset.shape)



解释一下列的含义:
PassengerId: 乘客ID
Survived: 是否生存,0代表遇难,1代表还活着
Pclass: 船舱等级:1Upper,2Middle,3Lower
Name: 姓名
Sex: 性别
Age: 年龄
SibSp: 兄弟姐妹及配偶个数
Parch:父母或子女个数
Ticket: 乘客的船票号
Fare: 乘客的船票价
Cabin: 乘客所在的仓位(位置)
Embarked:乘客登船口岸
对数据缺失值进行填充,可以看出dataset数据中Age,Emnarked,Fare有缺失,对其进行填充
dataset['Age'].fillna(dataset['Age'].median(),inplace=True)
dataset['Fare'].fillna(dataset['Fare'].median(),inplace=True)
dataset['Embarked'].fillna(dataset['Embarked'].mode()[0],inplace=True)
Cabin与Survived关系
Cabin缺失值过多,有可能有缺失值的是乘客在甲板上(即不在船仓内),所以查看其有无缺失值与是否存活的情况
dataset.loc[dataset.Cabin.notnull(),'Cabin']=1
dataset.loc[dataset.Cabin.isnull(),'Cabin']=0
cabin = pd.crosstab(dataset.Cabin,dataset.Survived)
cabin.rename(index={0:'no cabin',1:'cabin'},columns={0.0:'Dead',1.0:'Survived'},inplace=True)
cabin
cabin.plot(kind='bar',figsize=(6,4))

显然cabin的有无可以作为一个特征来处理
接下来将名字分离,将性别和前缀(身份)做一个交叉表看看
dataset['Identify']=dataset['Name'].apply(lambda x: x.split(',')[1].split('.')[0].strip())
pd.crosstab(dataset.Identify,dataset.Sex)
从下图可以很明显的看出大部分的identify对应一种性别,除了Dr。八个人对应了7男1女,应该是标错了,找出这个数据并进行改正
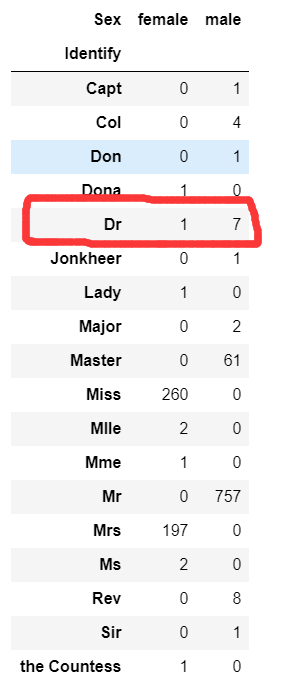

乘客的ID为797
建立映射关系,并改正797乘客的性别
m={'Capt':'man', 'Col':'man','Don':'man','Dona':'woman',
'Dr':'man','Jonkheer':'man','Lady':'woman','Major':'man',
'Master':'Master','Miss':'Miss','Mlle':'woman','Mme':'woman',
'Mr':'Mr','Mrs':'Mrs','Ms':'woman','Rev':'Mr','Sir':'man',
'the Countess':'woman'}
dataset.Identify=dataset.Identify.map(m)
dataset.loc[dataset.PassengerId==797,'Identify']=='woman'
dataset.Identify.value_counts()
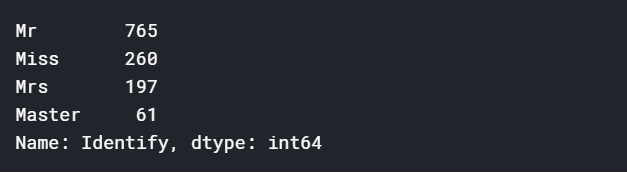
一般来说未婚的年纪较小,已婚的年纪较大,来看看Age和Identify之间的关系

Identify 与 Surived 关系
identify=dataset.groupby(['Identify'])[['Identify','Survived']]
identify.mean().plot(kind='bar',figsize=(10,8))
出乎意料的是,被标记为women的群体存活率为1!

Age 和Survived 关系
age=pd.crosstab(dataset.Age, dataset.Survived)
age.plot(kind='bar',figsize=(20,10))
plt.show()
从下图可以看出6岁之前的小孩存活率较高,64岁以后死亡率较高,其中28岁的死亡人数最多

Fare与Survived关系
fare=pd.concat([dataset[dataset.Survived==1]['Fare'],dataset[dataset.Survived==0]['Fare']],axis=1)
fare.columns=['Survived','Dead']
fare.plot(kind='hist',bins=30,figsize=(15,8),alpha=0.5,stacked=True)
明显可以看出,当票价高时存活率高

Sex和Survived 关系
sex=pd.crosstab(dataset.Sex,dataset.Survived)
sex.plot(kind='bar',figsize=(10,8))
显然女性的存活率高

Pclass 与 Survived 关系
pclass=pd.crosstab(dataset.Pclass,dataset.Survived)
pclass.plot(kind='bar',figsize=(10,8))
显然class1存活率高,class3存活率低

特征工程
看一下他们之间的关系
dataset.corr().plot(kind='bar',figsize=(15,10))


开始试着做特征:
dataset.Agecut=pd.cut(dataset.Age,5)
dataset.Agecut.value_counts().sort_index()

dataset.Farecut=pd.qcut(dataset.Fare,5)
dataset.Farecut.value_counts().sort_index()

根据以上信息将其标记为1,2,3,4,5,
dataset.loc[dataset.Age<=16.136,'Agecut']=1
dataset.loc[(dataset.Age>16.136)&(dataset.Age<=32.102),'Agecut']=2
dataset.loc[(dataset.Age>32.102)&(dataset.Age<=48.068),'Agecut']=3
dataset.loc[(dataset.Age>48.068)&(dataset.Age<=64.034),'Agecut']=4
dataset.loc[dataset.Age>64.034,'Agecut']=5
dataset.loc[dataset.Fare<=7.854,'Farecut']=1
dataset.loc[(dataset.Age>7.854)&(dataset.Age<=10.5),'Farecut']=2
dataset.loc[(dataset.Age>10.5)&(dataset.Age<=21.558),'Farecut']=3
dataset.loc[(dataset.Age>21.558)&(dataset.Age<=41.579),'Farecut']=4
dataset.loc[dataset.Age>41.579,'Farecut']=5
再来看一下关系

还剩下Parch,SibSp,Pclass以及Identify没有处理,来处理一下,做一个透视表看看
IPP=dataset[dataset.Survived.notnull()].pivot_table(index=['Identify','Pclass','Parch'],values=['Survived']).sort_values('Survived',ascending=False)
IPP

再做进一步处理
I=['Master','Mr','Miss','Mrs','man','woman']
for i in I:
for j in range(1,4):
for g in range(0,10):
if dataset.loc[(dataset.Identify==i)&(dataset.Pclass==j)&(dataset.Parch==g)&(dataset.Survived.notnull()),'Survived'].mean()>=0.8:
dataset.loc[(dataset.Identify==i)&(dataset.Pclass==j)&(dataset.Parch==g),'IPP']=1
elif dataset.loc[(dataset.Identify==i)&(dataset.Pclass==j)&(dataset.Parch==g)&(dataset.Survived.notnull()),'Survived'].mean()>=0.5:
dataset.loc[(dataset.Identify==i)&(dataset.Pclass==j)&(dataset.Parch==g),'IPP']=2
elif dataset.loc[(dataset.Identify==i)&(dataset.Pclass==j)&(dataset.Parch==g)&(dataset.Survived.notnull()),'Survived'].mean()>=0:
dataset.loc[(dataset.Identify==i)&(dataset.Pclass==j)&(dataset.Parch==g),'IPP']=3
else:
dataset.loc[(dataset.Identify==i)&(dataset.Pclass==j)&(dataset.Parch==g),'IPP']=4
当IPP=4时数据最少
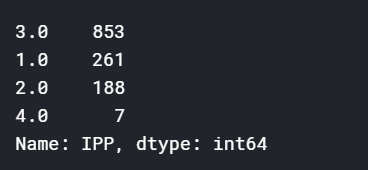
做一下处理将4分到其它类
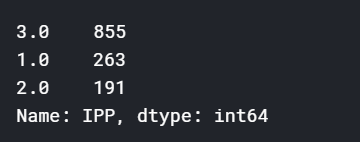
模型
我开始使用的是GBT,提交上去0.779
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import StandardScaler
features=['Cabin','Embarked','Parch','Pclass','Sex','SibSp','Identify','Agecut','Farecut','IPP','Age','Fare']
df=pd.get_dummies(dataset[features])
X=df[:891]
y=dataset.Survived[:891]
test_X=df[891:]
scaler=StandardScaler()
X_scaled=scaler.fit(X).transform(X)
test_X_scaled=scaler.fit(X).transform(test_X)
model=GradientBoostingClassifier()
model.fit(X,y)
param_grid={'n_estimators':[100,120,140,160],'learning_rate':[0.05,0.08,0.1,0.12,],'max_depth':[1,2,3,4]}
grid_search=GridSearchCV(GradientBoostingClassifier(),param_grid,cv=5)
grid_search.fit(X_scaled,y)
grid_search.best_params_,grid_search.best_score_
后来考虑了模型融合方面参考了其他人的方法
即逻辑回归、KNN、SVM、GBDT作为第一层模型,随机森林作为第二层模型,不过融合之后评分降了0.004,估计是过拟合了
融合方法采用oof 的 stacking
from sklearn.model_selection import StratifiedKFold
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import StandardScaler
features=['Cabin','Embarked','Parch','Pclass','Sex','SibSp','Identify','Agecut','Farecut','IPP','Age','Fare']
df=pd.get_dummies(dataset[features])
X=df[:891]
y=dataset.Survived[:891]
test_X=df[891:]
scaler=StandardScaler()
X_scaled=scaler.fit(X).transform(X)
test_X_scaled=scaler.fit(X).transform(test_X)
n_train=df_train.shape[0]
n_test=df_test.shape[0]
kf=StratifiedKFold(n_splits=5,random_state=1,shuffle=True)
def get_oof(clf,X,y,test_X):
oof_train=np.zeros((n_train,))
oof_test_mean=np.zeros((n_test,))
oof_test_single=np.empty((5,n_test))
for i, (train_index,val_index) in enumerate(kf.split(X,y)):
kf_X_train=X[train_index]
kf_y_train=y[train_index]
kf_X_val=X[val_index]
clf.fit(kf_X_train,kf_y_train)
oof_train[val_index]=clf.predict(kf_X_val)
oof_test_single[i,:]=clf.predict(test_X)
oof_test_mean=oof_test_single.mean(axis=0)
return oof_train.reshape(-1,1), oof_test_mean.reshape(-1,1)
LR_train,LR_test=get_oof(LogisticRegression(C=0.06),X_scaled,y,test_X_scaled)
KNN_train,KNN_test=get_oof(KNeighborsClassifier(n_neighbors=8),X_scaled,y,test_X_scaled)
SVM_train,SVM_test=get_oof(SVC(C=4,gamma=0.015),X_scaled,y,test_X_scaled)
GBDT_train,GBDT_test=get_oof(GradientBoostingClassifier(n_estimators=120,learning_rate=0.12,max_depth=4),X_scaled,y,test_X_scaled)
X_stack=np.concatenate((LR_train,KNN_train,SVM_train,GBDT_train),axis=1)
y_stack=y
X_test_stack=np.concatenate((LR_test,KNN_test,SVM_test,GBDT_test),axis=1)
stack_score=cross_val_score(RandomForestClassifier(n_estimators=1000),X_stack,y_stack,cv=5)
stack_score.mean(),stack_score















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









