







 本文介绍了使用Python进行新浪微博爬虫的步骤,无需模拟登录。通过Chrome浏览器的开发者模式观察网络请求,找到XHR请求,解析JSON数据获取微博内容和图片URL,从而实现微博的抓取和下载。
本文介绍了使用Python进行新浪微博爬虫的步骤,无需模拟登录。通过Chrome浏览器的开发者模式观察网络请求,找到XHR请求,解析JSON数据获取微博内容和图片URL,从而实现微博的抓取和下载。
环境:
浏览器: chrome 64
python 3.6
ps:python新手,写得不好求轻喷
ps:这是更加纯净的微博内容页面
思路步骤:
- 打开微博移动端网址并登录,
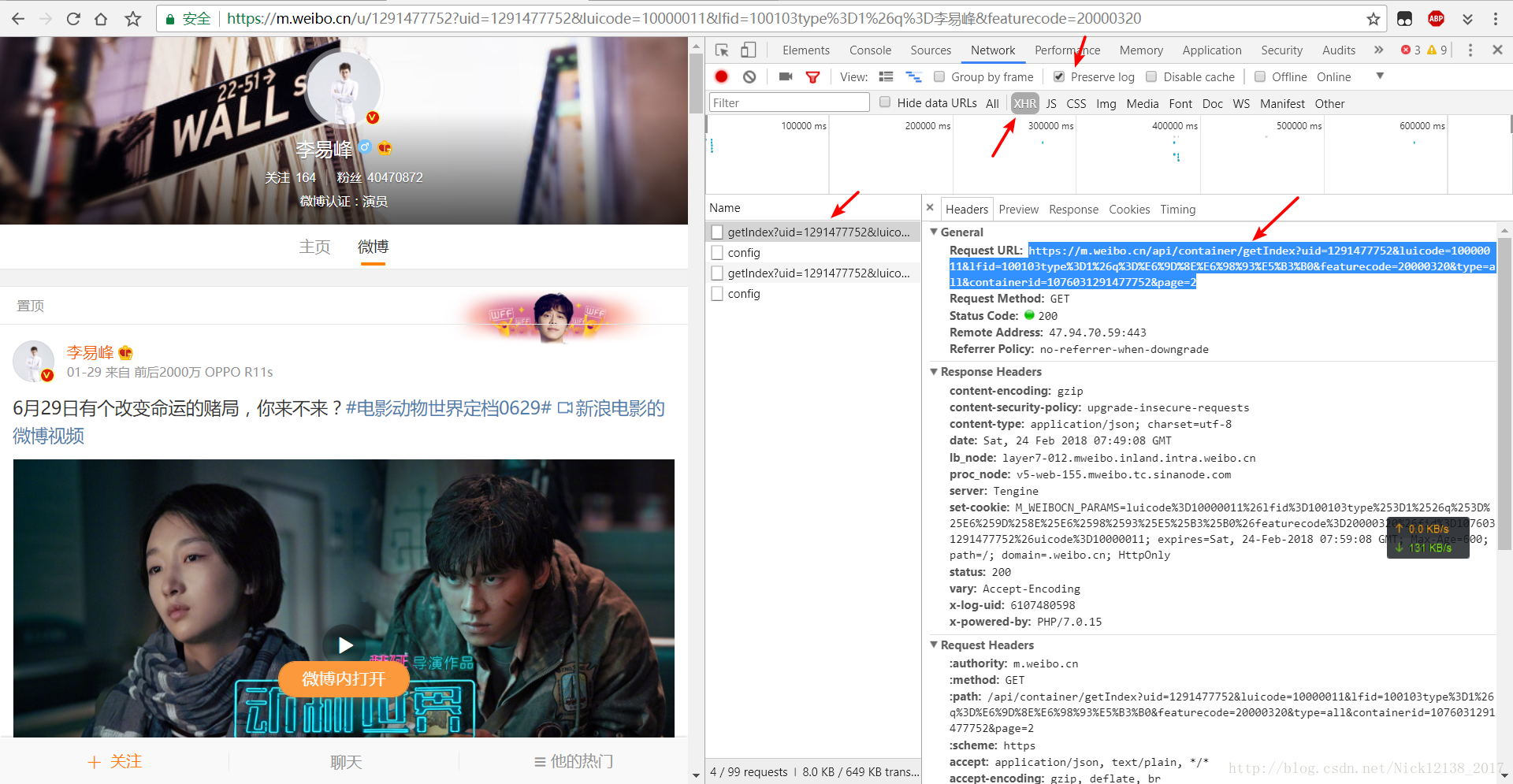
如 - 找到目标人物的微博,并按F12打开开发者模式,找到Network选项卡,勾选preserve log,类型选择XHR,下拉页面直至加载下一页,发现XHR中多了几项文件,打开图中的URL,如图
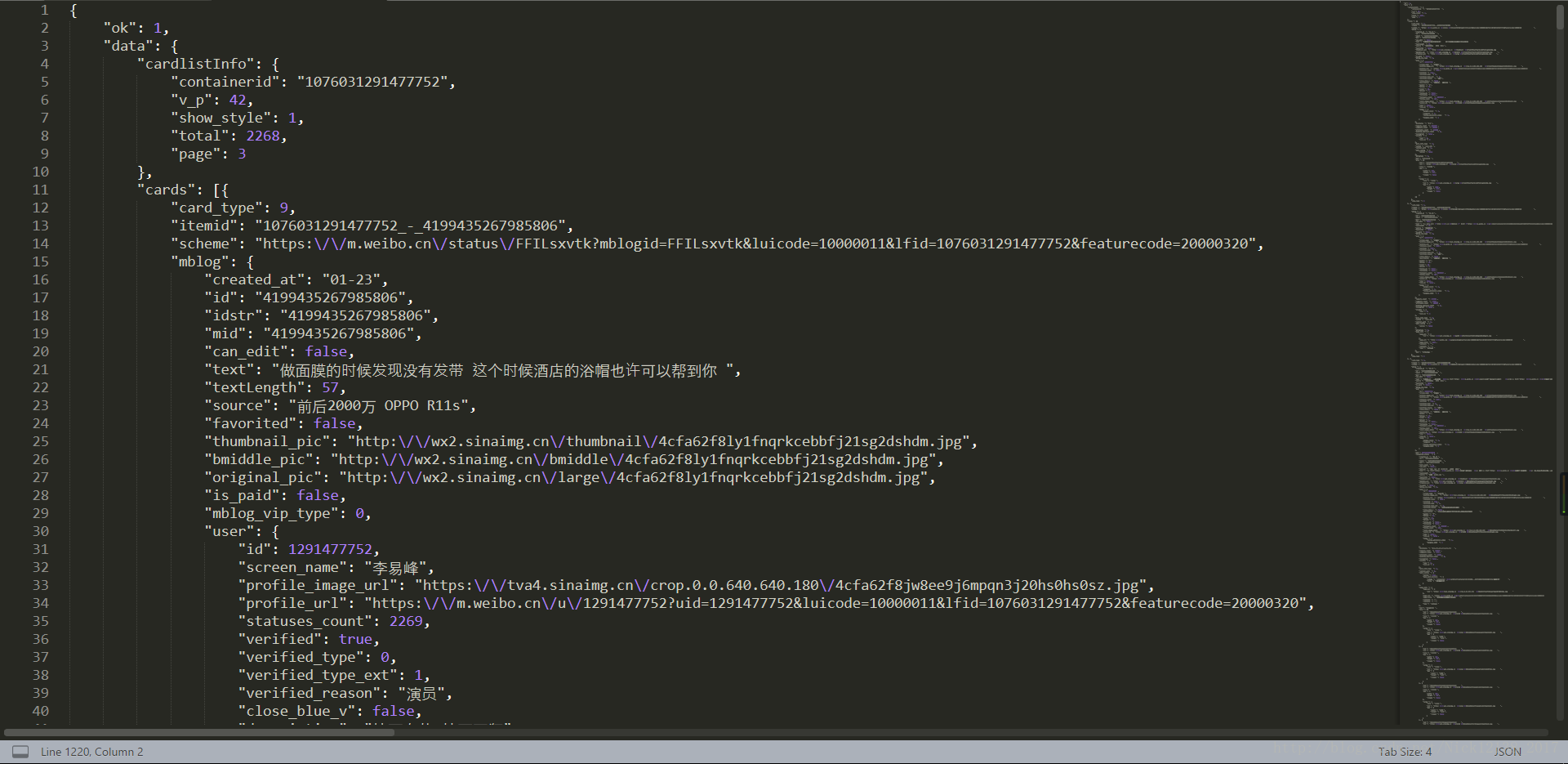
- 复制响应页面的内容,并用在线json工具解析可得
设该json为r,cards=r[‘data’][‘cards’]为微博列表,对cards中的每一个card,图片信息pics_info在card[‘mblog’][‘pics’],以此类推,获取到图片的URL之后就可以下载了

附上代码:
from 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8053
8053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









