







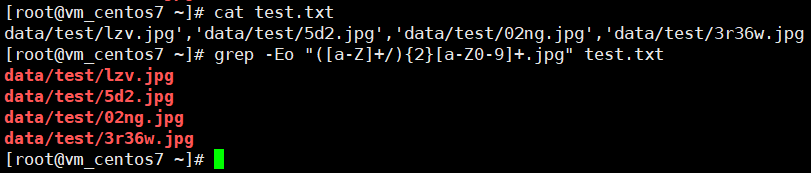
1、截取list中的xxxxx.jpg
下面是数据,只有1行
['data/zxcv/hello/20te11st/77/144149lho1h9m2g13ja2ot.jpg','data/zxcv/hello/20te11st/77/144156wbylbasy0hnsbvbc.jpg','data/zxcv/hello/20te11st/77/144156v868o0981wesl8eo.jpg','data/zxcv/hello/20te11st/77/144156ih2yrqjdrhhjtwfl.jpg','data/zxcv/hello/20te11st/77/144157bp31np2eakkfaw1u.jpg','data/zxcv/hello/20te11st/77/144157r199m4d8o2071998.jpg','data/zxcv/hello/20te11st/77/144157ktlvet0ziieidq2v.jpg','data/zxcv/hello/20te11st/77/144157nrrzw77j2wqww78r.jpg','data/zxcv/hello/20te11st/77/144157gweppip9dvneezve.jpg','data/zxcv/hello/20te11st/77/144158obwwzer8g7wwa7rg.jpg','data/zxcv/hello/20te11st/77/144158pvz252taoc2fxxcw.jpg','data/zxcv/hello/20te11st/77/144158btcuwbqg5yb2zj2z.jpg','data/zxcv/hello/20te11st/77/144158g6zg151v944x5svx.jpg','data/zxcv/hello/20te11st/77/144158e7bbedge7d76wzad.jpg','data/zxcv/hello/20te11st/77/144158igc4f9zm2ff4f24f.jpg','data/zxcv/hello/20te11st/77/144159bqisipsa1kie1d1i.jpg','data/zxcv/hello/20te11st/77/144159bldcie9o2ltc3k55.jpg','data/zxcv/hello/20te11st/77/144159f7bo4noeddoccgjg.jpg']方法1:
awk -F"[ ',']+" '{$1=$1;for(i=1;i<=NF;i++) {print $i}}' 1.txt
方法2:
grep -oP '[^',']+' 1.txt 但是没单引号' 没识别出来,加了转义符号也不对头。但是在regexBuddy是有效的
=====2020年10月5日18:23:23==== 时隔2个月吧,看了龙帅的视频,悟道了,理应这样写才能达到效果。
grep -oP "[^',\[\]]+" 1.txt
方法3:
awk '{split($0,var,"''\'','\''")} END{for(i in var)print var[i]}' test.txt
方法4:
grep -oP "[^\']+(?=',)|(?<=,')[^\']+" 1.txt
解释说明
[^\']+ 取反,除了' 单引号都能匹配上。
(?=',) 切右边数据, ',左边的数据都匹配上。
单独写 [^\']+(?=',) 但此时最后(最右边)一段没匹配上。所以要写个| 或
(?<=,') 切左边的数据, ',右边数据都匹配上
单独写 (?<=,')[^\']+ 则是最开头(最左边)一段没匹配上。
其实还是有点不解,就算在regexBuddy上运行了。 这个零宽断言的使用方式 -.-
方法5:
grep -Eo "([a-Z]+/){2}[a-Z0-9]+.jpg" 1.txt
grep -Eo "([a-zA-Z0-9]+/)+[a-zA-Z0-9]+.jpg" 1.txt方法2的正则


再做调整:

其他:

2、sed修改jdbc.mysql.password的值
jdbc.mysql.password=abc123
jdbc.mysql.driver=yyyyy
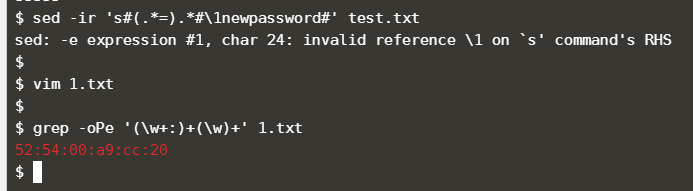
jdbc.mysql.url=xxxxxx#sed -r 's#(.*=).*#\1newpassword#' 1.txt
sed -r -i 's#(.*password=).*#\1newpassword#' 1.txt
匹配后, 利用分组、后向引用来修改值
(注意-r -i要分开写,如果写成 -ri 会报错)


修改结果:

参考:解决sed -i报错sed: -e expression #1, char 44: invalid reference \1 on `s' command's RHS_听涯love的博客-CSDN博客
3、将目录中所有的文件 重命名加上 主机名
ls | xargs -i mv {} `hostname`{}
4、截取日志不需要红框这部分,只需要后面实际内容,前面的时间 日志等级 还是要的
[spring-b0002-server:19010::] 2020-07-05 11:09:34.815[ INFO] 32509 [] [main:4688] [o.springframework.boot.actuate.endpoint.EndpointId.?:?] Endpoint ID 'service-registry' contains invalid characters, please migrate to a valid format.
[spring-b0002-server:19010::] 2020-07-05 11:09:34.815[ INFO] 111 [] [main:4688] [threeNum.springframework.boot.actuate.endpoint.EndpointId.?:?] Endpoint ID 'service-registry' contains invalid characters, please migrate to a valid format.
[spring-b0002-server:19010::] 2020-07-05 11:09:34.815[ INFO] 2222 [] [main:4688] [fourNum.springframework.boot.actuate.endpoint.EndpointId.?:?] Endpoint ID 'service-registry' contains invalid characters, please migrate to a valid format.

grep -oP '.*(?= [0-9]{3,5})|(?<=\?]).*' test3.txt
由本章的第一节的 方法4: grep -oP "[^\']+(?=',)|(?<=,')[^\']+" 1.txt 得到启发。
利用零宽断言加上 “或|表达式” 达成效果


5、获取wb 9宫格的图
数据weibo.txt:
<ul class=\"WB_media_a WB_media_a_mn WB_media_a_m9 clearfix\" node-type=\"fl_pic_list\" action-data=\"isPrivate=0&relation=0&clear_picSrc=%2F%2Fwx3.sinaimg.cn%2Fmw690%2Fa1fd3eedly1gi6duitrskj20u0140gqc.jpg,%2F%2Fwx3.sinaimg.cn%2Fmw690%2Fa1fd3eedly1gi6dul9axbj21ha0u0guj.jpg,%2F%2Fwx3.sinaimg.cn%2Fmw690%2Fa1fd3eedly1gi6dumms6zj20u0140qaw.jpg,%2F%2Fwx4.sinaimg.cn%2Fmw690%2Fa1fd3eedly1gi6duornvlj20u015vwne.jpg,%2F%2Fwx3.sinaimg.cn%2Fmw690%2Fa1fd3eedly1gi6duq6x09j20u00zn0xc.jpg,%2F%2Fwx4.sinaimg.cn%2Fmw690%2Fa1fd3eedly1gi6durtoztj20u012egrm.jpg,%2F%2Fwx4.sinaimg.cn%2Fmw690%2Fa1fd3eedly1gi6dutthynj20u00v3tdx.jpg,%2F%2Fwx4.sinaimg.cn%2Fmw690%2Fa1fd3eedly1gi6duwc05uj20u00uzjwe.jpg,%2F%2Fwx2.sinaimg.cn%2Fmw690%2Fa1fd3eedly1gi6dvcapzfj20u0140q9m.jpg&thumb_picSrc=%2F%2Fwx3.sinaimg.cn%2Forj360%2Fa1fd3eedly1gi6duitrskj20u0140gqc.jpg,%2F%2Fwx3.sinaimg.cn%2Fthumb150%2Fa1fd3eedly1gi6dul9axbj21ha0u0guj.jpg,%2F%2Fwx3.sinaimg.cn%2Forj360%2Fa1fd3eedly1gi6dumms6zj20u0140qaw.jpg,%2F%2Fwx4.sinaimg.cn%2Forj360%2Fa1fd3eedly1gi6duornvlj20u015vwne.jpg,%2F%2Fwx3.sinaimg.cn%2Forj360%2Fa1fd3eedly1gi6duq6x09j20u00zn0xc.jpg,%2F%2Fwx4.sinaimg.cn%2Fthumb150%2Fa1fd3eedly1gi6durtoztj20u012egrm.jpg,%2F%2Fwx4.sinaimg.cn%2Forj360%2Fa1fd3eedly1gi6dutthynj20u00v3tdx.jpg,%2F%2Fwx4.sinaimg.cn%2Fthumb150%2Fa1fd3eedly1gi6duwc05uj20u00uzjwe.jpg,%2F%2Fwx2.sinaimg.cn%2Fthumb150%2Fa1fd3eedly1gi6dvcapzfj20u0140q9m.jpg&uid=2717728493&pic_ids=a1fd3eedly1gi6duitrskj20u0140gqc,a1fd3eedly1gi6dul9axbj21ha0u0guj,a1fd3eedly1gi6dumms6zj20u0140qaw,a1fd3eedly1gi6duornvlj20u015vwne,a1fd3eedly1gi6duq6x09j20u00zn0xc,a1fd3eedly1gi6durtoztj20u012egrm,a1fd3eedly1gi6dutthynj20u00v3tdx,a1fd3eedly1gi6duwc05uj20u00uzjwe,a1fd3eedly1gi6dvcapzfj20u0140q9m&mid=4542864304120465&pic_objects=&object_ids=1042018%3A557365b2211e0fd6021b42d92e5ecdbf%2C1042018%3Af8453ef1f78738a51b4413886c877760%2C1042018%3A0736d7658d48f81c4cd8a821fc9b40e1%2C1042018%3A51f8ef0bf21a503f57e83b4f2e585cda%2C1042018%3A2984c3cf581fce508f3efef8921eef52%2C1042018%3A75c99c8d2df413f3c2cd33b6e3701224%2C1042018%3A8a741c5ab2e074f9ac83a337206263a7%2C1042018%3Ac415816be37f6715accd20d9fffa82a9%2C1042018%3Aa78da968c3d10b7af84f66710d02d33e&photo_tag_pids=\">\n
#!/bin/bash
grep -oP '%2F%2F(.*?\.jpg)' weibo.txt > metaJpg.txt
sed -r 's#(%2F%2F)#https:\/\/#;s#(%2F)#\/#g' metaJpg.txt > downloadJpg.txt
wget --no-check-certificate -i downloadJpg.txt
==========================================
经过观察
https://wx3.sinaimg.cn/mw690/a1fd3eedly1gi6dul9axbj21ha0u0guj.jpg
%2F%2Fwx3.sinaimg.cn%2Fmw690%2Fa1fd3eedly1gi6dul9axbj21ha0u0guj.jpg
将 %2F%2F --> https://
%2F --> /6、关于转义 ' 带单引号的内容。
需求 echo "fhfhhjgh':" , 去除行末的':
![]()

方法1:
sed "s/"\'"://"
sed s/\'://
方法2:
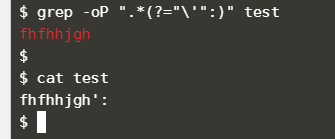
grep -oP ".*(?="\'":)" test
方法3:
sed -r 's#(.*)(.:)#\1#' test
巧妙的一种方法
方法4:匹配16进制的
[root@web01 mvFile]# echo "fhfhfhfhfhjjsa':" | grep -oP '.*(?=(\x27))'
fhfhfhfhfhjjsa
[root@web01 mvFile]# echo "fhfhfhfhfhjjsa':" | grep -oP '.*(?=(\x27):)'
fhfhfhfhfhjjsa
下面是群大佬的总结:
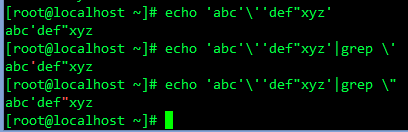
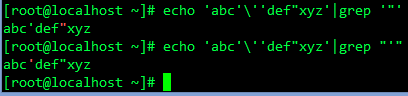
echo 'abc'\''def"xyz'
echo 'abc'\''def"xyz' | grep \'
echo 'abc'\''def"xyz' | grep \"
echo 'abc'\''def"xyz' | grep "'"
echo 'abc'\''def"xyz' | grep '"'
echo 'abc'\''def"xyz' | grep ''"'"''
echo 'abc'\''def"xyz' | grep -P '\x22'
echo 'abc'\''def"xyz' | grep -P '\x27'
echo 'abc'\''def"xyz' | grep -P '[\x22\x27]'单双引号匹配(和替换)问题总结一下,以后不要纠结,以grep为例,Perl,sed都差不多:
1.在匹配不复杂的字符,不写Meta符,可以不要单引号或双引号来把“代码”部分包围
2.匹配双引号的时候用单引号包围,匹配单引号的时候用双引号包围,减少转义的难度,其实跟“1”基本上一样的思路。
3.单引号包围的代码中匹配单引号,用两组引号来包围
![]()
4.不管是匹配单引号还是双引号,还是两种引号再加各种复杂匹配,代码部分根据实际需要用单引号和双引号都可以,使用16进制编码,复杂情况我是必定使用这种。


可总结为一句话:引号必须配对,左引号必须匹配右引号才算一对,任何不被引号包围的孤儿引号必须转义。
====分割线 2022年4月3日11:02:17========
题目:
文本样式:"abc","ab(a,b)c",'aba,ec+c()',"aabcd"
转换后的结果需求:"abc"|"ab(a,b)c"|'aba,ec+c()'|"aabcd"

sed -r "s#\x22,\x22#\x22|\x22#g" 1.txt | sed -r "s#\x22,\x27#\x22|\x27#g" | sed -r "s#\x27,\x22#\x27|\x22#g"
#Steven:
perl -pe's#["\x22][^"\x22]+["\x22](*SKIP)尻|,#|#g' 1.txt
=============分割线 2020年10月5日11:47:06=======
看了龙帅的视频,这一块再做些笔记。
首先进行引号的配对。shell解析匹配的引号, 里面的就被当成了普通的字符
1.双引号中的单引号,以及单引号中的双引号都会被保留,不被shell解析
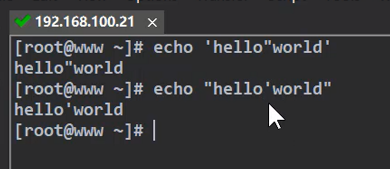
2. 双引号弱引用,单引号强引用 。
双引号能直接解析出变量的值,而单引号在这不进行解析。

3.引号配对,从左至右进行配对
4.反斜线转义 , 只有在双引号中能转义,单引号中被当作普通反斜线字符
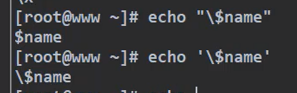
5.可以将一个参数通过引号配对的方式,分隔开,只要分割的时候不要使用空白符号断开


6 、 sed的示例

用单引号的写法是不可行的,这样他不认识${line}的内容
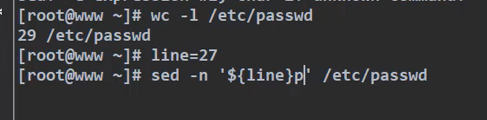
要换成双引号或者一个引号都不用,才能达到输出倒数第三行的效果。
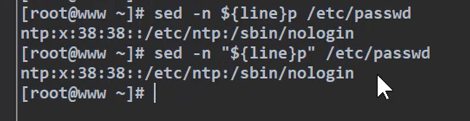
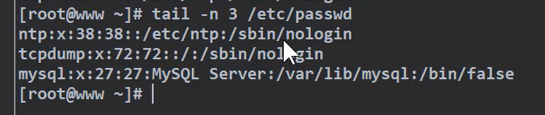
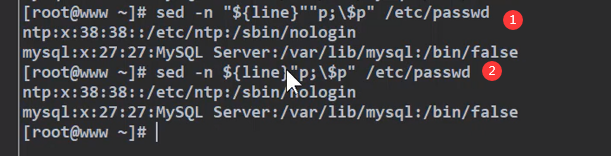
此时有另一个需求,输出倒数第三行和倒数第一行, 在sed中 $为最后一行,所以用单引号,直接暴露扔给sed解析,而不是用双引号“包裹”。
或者双引号里面用转义符号进行操作。

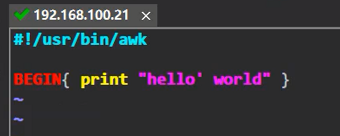
7、awk 示例

引号匹配 、转义 、 八进制

使用-v变量

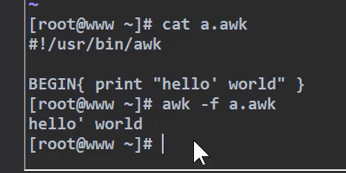
使用程序文件, 比如进到 a.awk
















 3678
3678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









