







存储引擎
MySQL体系结构
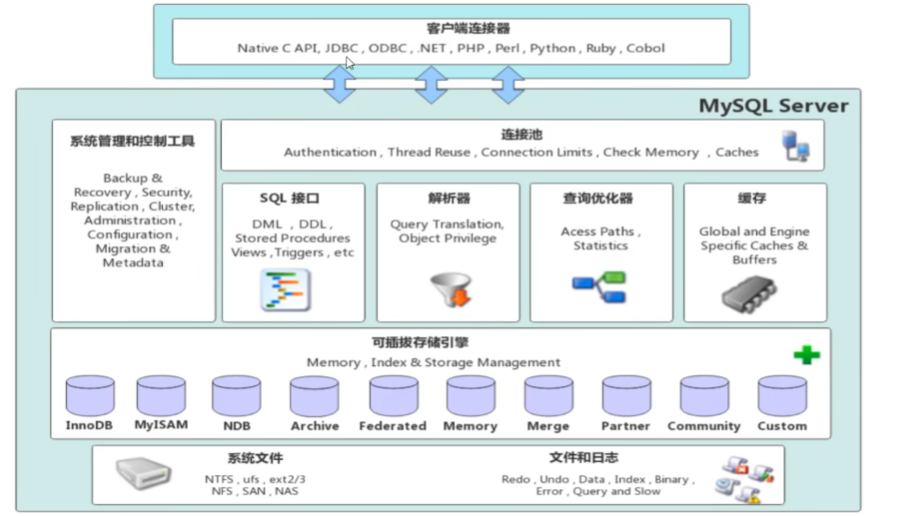
连接层
最上层是一些客户端和链接服务,主要完成一些类似于连接处理、授权认证、及相关的安全方案。
服务器也会为安全接入的每个客户端验证它所具有的操作权限。
服务层
第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化,
部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如过程、函数等。
引擎层
存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API和存储引擎进行通信。
不同的存储引擎具有不同的功能,这样我们可以根据自己的需要,来选取合适的存储引擎。
存储层
主要是将数据存储在文件系统之上,并完成与存储引擎的交互。
存储引擎简介
存储引擎就是存储数据建立索引,更新查询数据等技术的实现方式,存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型
MYSQL默认的存储引擎为InnoDB
创建表的时候,在最末端,表的注释前可插入语句来设置表的存储引擎
例如:engine=innodb
查看当前数据库支持的存储引擎
show engines
存储引擎特点
InnoDB
是一种兼顾高性能和高可靠性的通用存储引擎,在5.5版本后,作为了默认的存储引擎
特点
DML操作遵循ACID模型,支持事务;
行级锁,提高并发访问性能
支持外键Foreign Key约束,保证数据的完整性和正确性
文件
xxx.ibd
innoDB引擎每张表都会对应这样一个表空间文件,存储该表的=表结构(frm,sdi),数据和索引
参数innodb_file_per_table
innodb中的存储结构
表空间
段
区
页
行
MyISAM
最早作为MySQL的默认存储引擎
特点
不支持事务,不支持外键
支持表锁,不支持行锁
访问速度快
文件特点
xxx.MYD表结构信息
xxx.MYI数据
xxx.sdi索引
Memory
介绍
Memory引擎的表数据存储在内存中,由于收到硬件,断电或者断网等因素的影响,只能将这些数据作为临时表或者缓存使用
特点
内存存放(访问速度较快
hash索引
文件
xxx.sdi存储表结构信息

存储引擎选择
在选择存储引擎时,应该根据应用系统的特点选择合适的存储引擎。对于复杂的应用系统,还可以根据实际情况选择多种存储引擎进行组合。
InnoDB:是Mysql的默认存储引擎,支持事务、外键。如果应用对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,那么InnoDB存储引擎是比较合适的选择。
MyISAM:如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。
MEMORY:将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。MEMORY的缺陷就是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性。
索引
索引概述
索引是帮助MySQL高效获取数据的数据结构(有序),在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引
优缺点
优势 | 劣势 |
提高数据检索的效率,降低数据库的IO成本, | 索引列也是要占空间的 |
通过索引对数据进行排序,降低数据排序的成本,降低cpu的消耗 | 索引大大提高了查询效率,同时也降低了表的更新速度,如对表进行,insert,uodate,delete时,效率降低 |
索引结构
索引是在存储引擎层实现的,不同的存储引擎拥有不同的索引结构
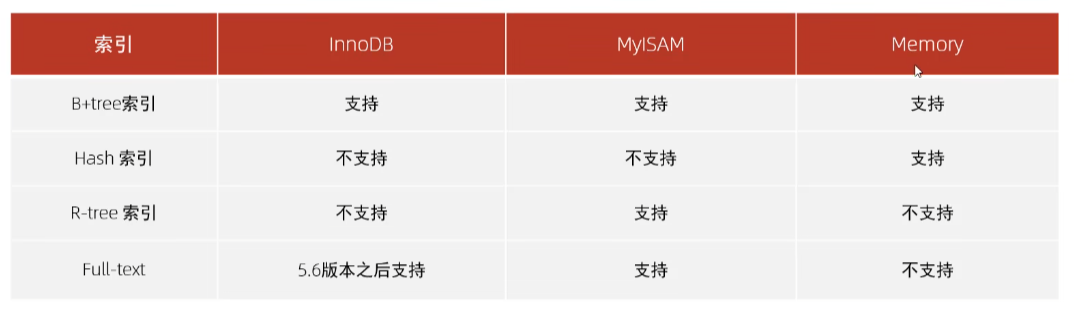
索引结构 | 描述 |
b+Tree索引 | 最常见的索引大部分引擎都支持b+树索引 |
Hash索引 | 底层数据结构时用哈希表实现的,只有精确匹配索引列的查询才有效,不支持范围查询 |
R-tree空间索引 | 空间索引时MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少 |
Full-text全文索引 | 一种通过建立倒排索引,快速匹配文档的方式 |
二叉树
二叉树缺点,顺序插入时,会形成一个链表,查询性能大大降低,大数据量情况下,层级较深,检索速度较慢
红黑树可以解决二叉树的无法自平衡问题
B-Tree(多路平衡查找树)
以一颗最大度数为5(5阶)的B-tree为例(每个节点最多存储4个Key,5个指针);

树的度数是一个节点的子节点个数
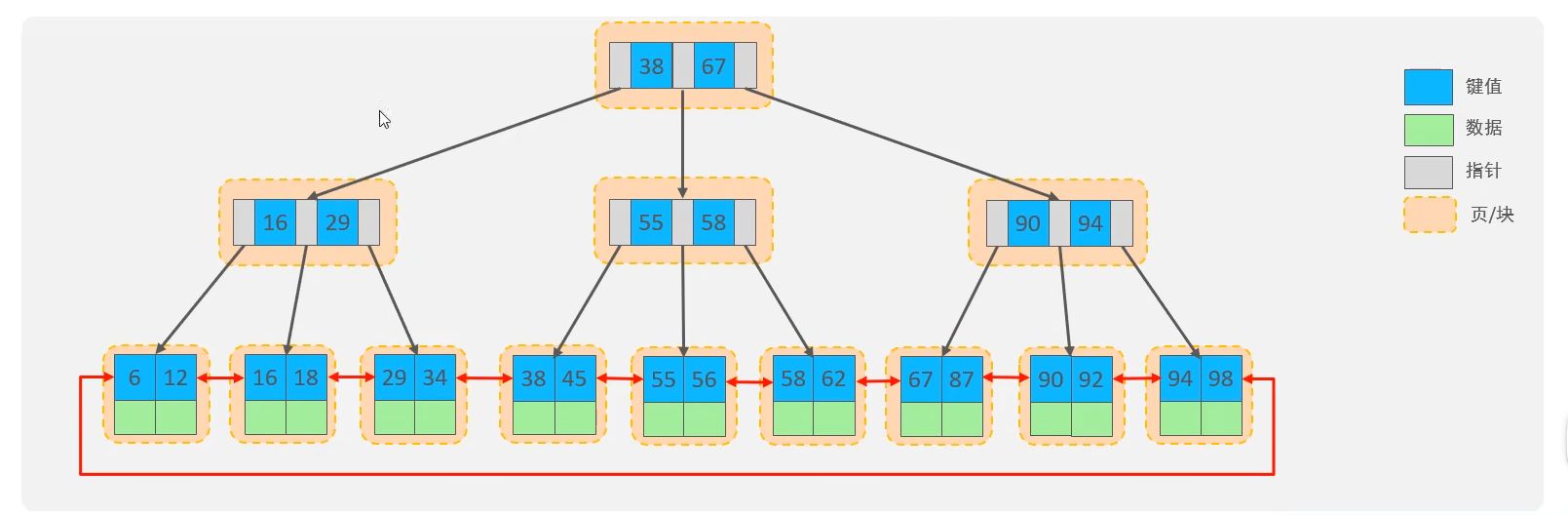
B+Tree树
也会像B-Tree一样向上分裂,但是会在子结点中保存分裂出去的部分
所有的数据都会出现在叶子节点
叶子节点形成一个单向链表
MySQL索引数据结构对经典的B+Tree进行了优化,在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能
Hash
哈希索引就是采用一定的hash算法,将键和值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中
Hash索引特点
Hash索引只能用于对等比较(=,in),不支持范围查找(between,>,<...)
无法利用索引完成排序操作
查询效率高,通常只需要一次检索就够了,效率通常高于B+Tree索引
存储引擎支持
在MySQL中,支持hash索引的是Memory引擎,而InnoDB中具有自适应hash功能,hash检索式存储引擎根据B+Tree索引在指定条件下自动构建的
为什么InnoDB存储引擎选择使用B+Tree索引结构
相对于二叉树,层级更少,搜索效率更高
相对于B-tree,无论是叶子节点,还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保留大量数据,只能增加树的高度,导致性能降低
索引分类
分类 | 含义 | 特点 | 关键字 |
主键索引 | 针对表中主键创建的索引 | 默认自动创建,只能有一个 | primary |
唯一索引 | 避免同一表中某数据列中的值重复 | 可以有多个 | unique |
常规索引 | 快速定位特定数据 | 可以有多个 | |
全文索引 | 全文索引查找的式文本中的关键词,而不是比较索引中的值 | 可以有多个 | fulltext |
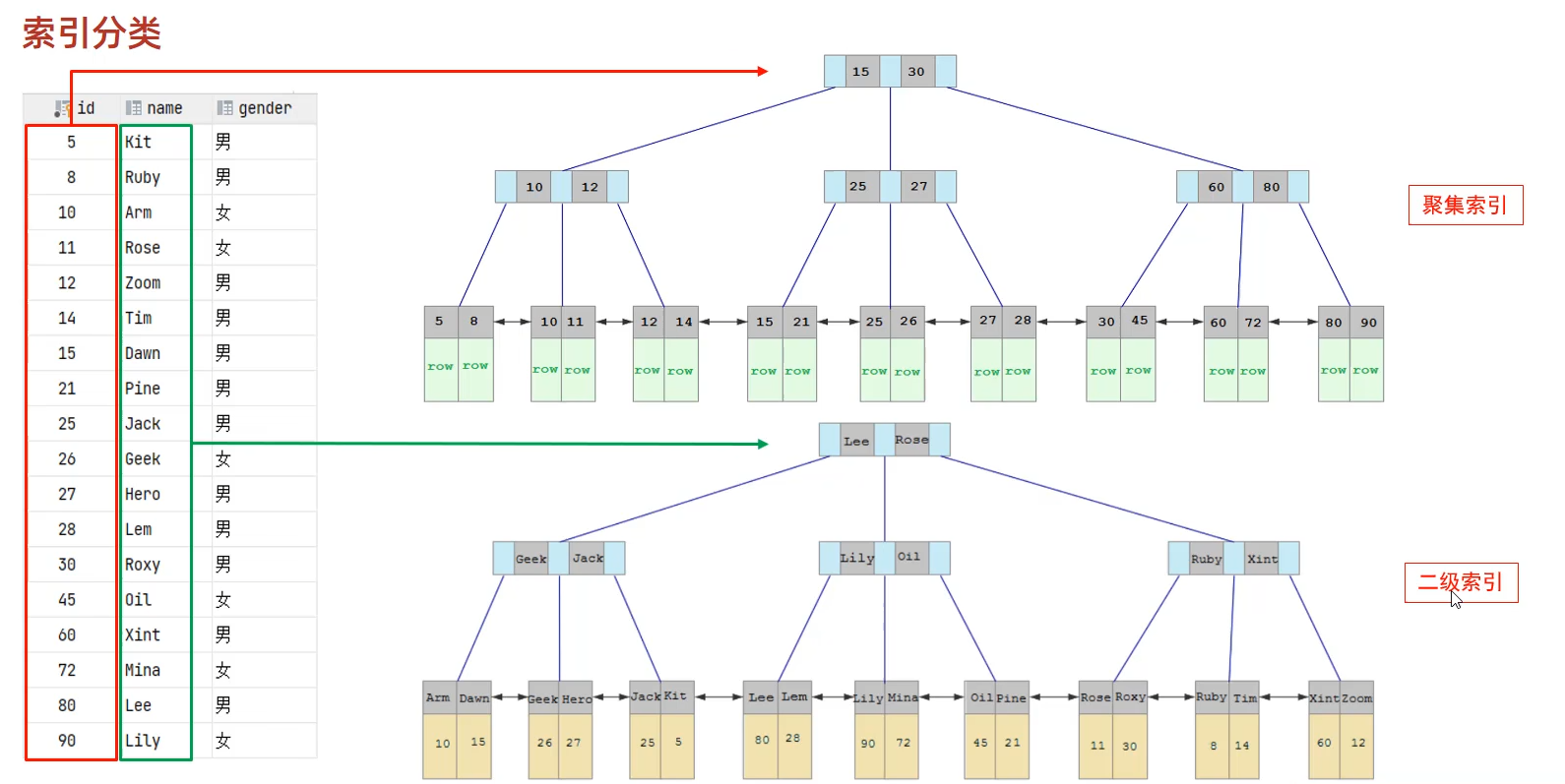
在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种
分类 | 含义 | 特点 |
聚集索引 | 将数据和索引放在了一起,索引结构的叶子节点保存了行数据 | 必须有,且只有一个 |
二级索引 | 将数据和索引分开存储,索引结构的叶子关联的是对应的主键 | 可以存在多个 |
聚集索引选取规则:
如果存在主键,主键索引就是聚集索引。
如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
索引语句
创建索引
create [unique | fulltext] index 索引名称 on 表名(字段名,可关联多个字段)
查看索引
show index from 表名
删除索引
drop index 索引名 on 表名
SQL性能分析
SQL执行频率
MySQL客户端连接成功后,通过show [session | globall status命令可以提供服务器状态信息。通过如下指令,可以查看当前数据库
的INSERT、UPDATE、DELETE、SELECT的访问频次:
show global status like '(模糊匹配内容)';
慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL语句的日志。
MySQL的慢查询日志默认没有开启,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:















 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









