







 本文深入探讨了MySQL如何进行基于成本的查询优化,包括IO和CPU成本的基本单位,以及优化步骤。主要内容涉及索引使用、全表扫描代价计算、不同索引查询代价分析,强调了成本计算在选择最优执行计划中的关键作用。文章还详细讲解了条件过滤、两表及多表连接成本分析,揭示了如何通过索引统计数据来估算查询成本。
本文深入探讨了MySQL如何进行基于成本的查询优化,包括IO和CPU成本的基本单位,以及优化步骤。主要内容涉及索引使用、全表扫描代价计算、不同索引查询代价分析,强调了成本计算在选择最优执行计划中的关键作用。文章还详细讲解了条件过滤、两表及多表连接成本分析,揭示了如何通过索引统计数据来估算查询成本。
这一章主要是讲基于成本的查询优化。核心方法有两种,一种是通过index dive这种方法去算io代价,另一种是根据记录数和势来估算。
12.1
成本分为两大类,即IO成本和CPU成本。
为了计算这两种成本,我们需要基本单位。基本单位主要有两个,一是从磁盘上读取一个页的时间开销,默认为1.0。二是读取以及检测一条记录是否符合搜索条件的开销,默认为0.2。
12.2
这次用到的还是以前那张表
CREATE TABLE single_table (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY uk_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1, key_part2, key_part3)
) Engine=InnoDB CHARSET=utf8;
这张表里有10000条记录,除id以外都是随机插入的值。
基于成本的优化步骤
在生成最终执行的物理执行计划前,优化器会找出所有可以用来执行该语句的方案,并估算这些方案的成本,从中选择一个最优的计划(方案)。
整体分四个步骤:
- 根据条件找出所有能用的索引
- 计算全表扫描的代价
- 计算使用不同索引执行查询的代价
- 选择代价最低的方案
下面举一个sql的例子:
select * from single_table where
key1 in ('a', 'b', 'c') and
key2 > 10 and key2 < 1000 and
key3 > key2 and
key_part1 like '%hello%' and
common_field = '123'
step1 找出能用的索引
对于 B+树索引来说, 只要索引列和常数使用=、<=>、 IN、 NOT IN、 IS NULL、
IS NOT NULL、>、<、>=、<=、 BETWEEN、!= (不等于也可以写成<>) 或者 LIKE 操作符连接起来, 就会产生一个扫描区间 (用LIKE匹配字符附缀时,也会产生一个扫描区间)。
也就是说,这些搜索条件都可能使用到索引,设计 MySQL 的大叔把一个查询中可能使用到的索引称之为 possible keys.
上面这个sql根据分析可知,能用的索引有idx_key1和uk_key2。
step2 计算全表扫描的代价
计算这部分只要知道表的信息就可以了。表的信息通过show table status这类sql来查看。
show table status like 'single_table';
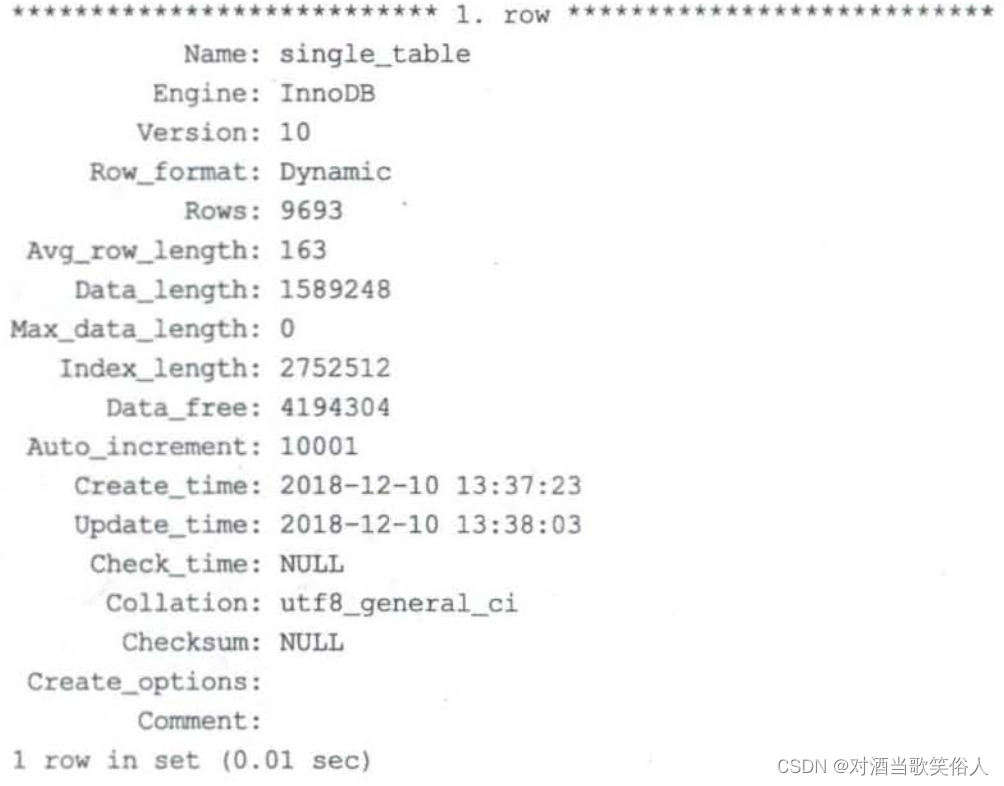
我们只关心两个选项。
一个是Rows,表示有多少条记录。对于用MyISAM引擎的表来说,这个记录数是固定的。对于使用InnoDB的表来说,这是个估值。
一个是Data_length,表示表占用的字节数。对于用MyISAM引擎的表来说,这个值是数据文件的大小。对于用InnoDB引擎的表来说,这个值是聚簇索引的大小。
用Data_length除以每个页面的大小,就可以知道有多少页面,进而算出IO成本。
(事实上,我们全表扫描的时候只需要扫描叶子节点所在的页面。但是在进行查询优化的估算时,我们简单认为所有页都是叶子节点,这样算比较方便。其实这也是可以接受的,对于一个大的表来说,最后一层的页数和上面几层相比不是一个数量级,所以问题不大)
再加上记录数*每条记录读取和检测的开销,就是总的开销成本了。对于这个例子来说:
- IO:97*1.0 + 1.1
- CPU 9693 * 0.2 + 1.0
最后的1.1和1.0都是微调值,固定常数,不要在意。
step3 计算使用不同索引执行查询的代价
其实就是依次分析使用不同索引的io成本和cpu成本。当然,还有可能发生索引合并。但是索引合并的规则是非常复杂的,我们基本不考虑索引合并相关的内容。
我们先来讨论使用key2列所对应的索引时的开销
对于使用二级索引+回表方式执行的查询,开销一方面来自于扫描,另一方面来自于回表。扫描的开销可以细分为扫描区间、页和记录。其中,页和记录是相互联系的。
扫描区间方面:按规定,每计算一个扫描区间,在io方面相当于从磁盘上读取了一个页
页和记录:因为使用二级索引需要回表,所以统计出有多少记录是必要的。每次回表的开销是1.0,也就相当于读取一个页。因此只需要知道有多少条记录,就能算出回表开销。那么如何统计出扫描区间内有多少个记录呢?难道要一个一个查找吗?
答案是否定的。那么具体该怎么做呢?
以我们的例子为例,我们要查找key2列的值在10和1000之间的记录。首先要找到key2>10的第一条记录和key2<1000的第一条记录,也就是最左记录和最右记录,查到它们所在的页。之后根据这两个页之间隔了多远来做判断
MySQL最多只会遍历10个页面。
遍历期间可以根据PageHeader中的PAGE_N_RECS这个属性来精确统计这10个页面各多少条记录。
因此,如果两个页面相隔不大于10页面,则获得的记录数是精确的,由遍历得出。
否则,会计算遍历的10个页面的记录数的平均值,然后乘以间隔,作为记录数的近似值。
这里有个问题是,如何计算两个页面相隔多远呢?
答案是依靠父页面。假设最左记录和最右记录有相同的父节点,由于每个B+树叶子节点都对应一个父节点中的值,因此只需要查一下父节点,看看对应的两个值之间隔着几个值即可。如下图所示:
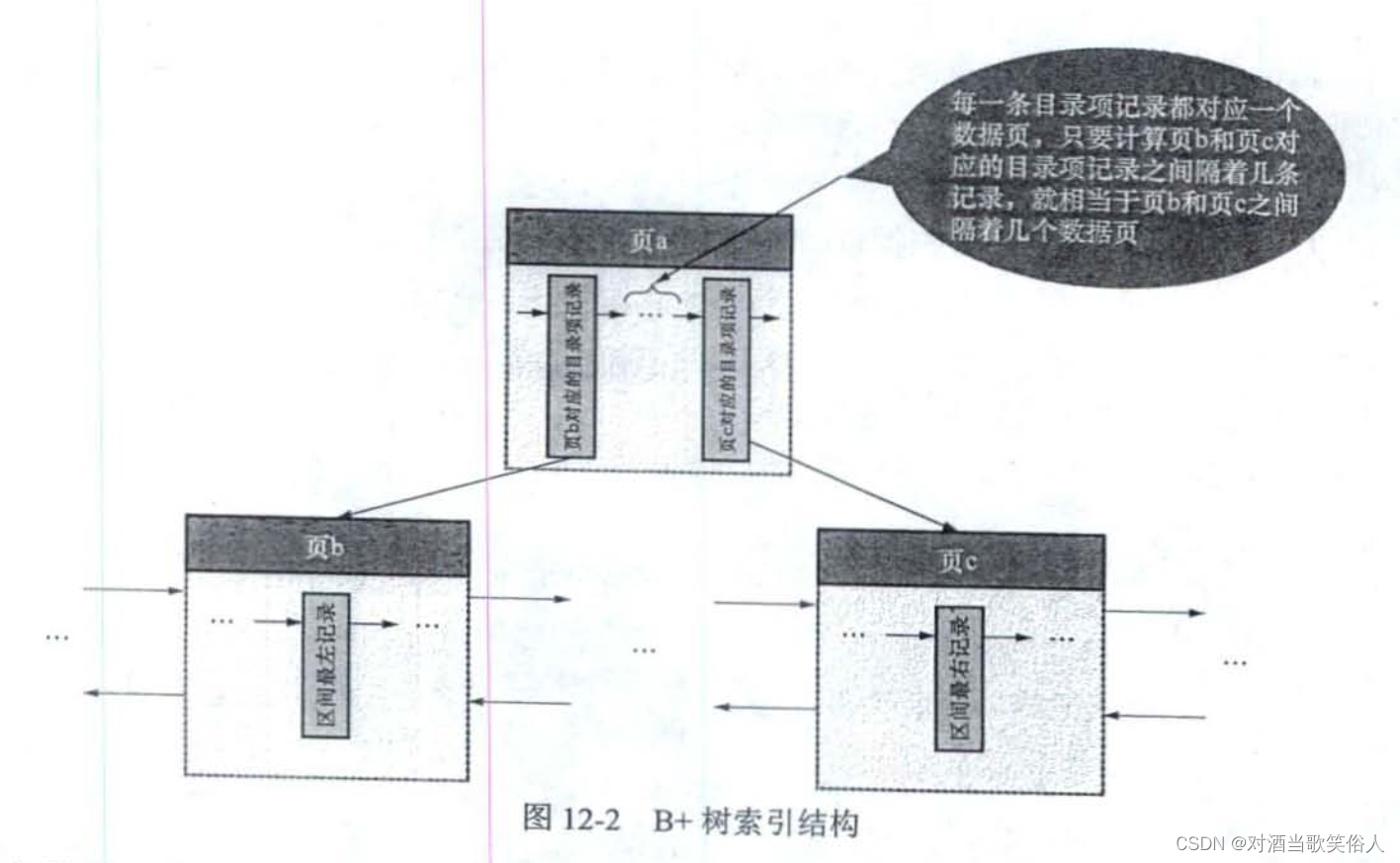
如果没有相同的父节点呢?答案是继续递归就可以了,总能算出来的。
得到所有记录后就是回表,回表的开销系数是1.0,前文提到过了,不再赘述。
回表后,还需要在聚簇索引中对完整的记录进行判断,这一步仍属于对记录的判断,开销是0.2
因此,总开销如下:(假设一共95条记录)
- io:1.0 + 95 * 1.0 扫描区间+回表,微调值没什么意义,没写
- cpu:95 * 0.2 + 0.01 + 95 * 0.2 = 38.01。0.01是微调,剩下的一个是二级索引里扫描记录的开销,另一个是聚簇索引里扫描记录的开销。
其实这里和真实情况有些区别。在比较使用二级索引和全表扫描谁的开销更大时,一开始不会考虑聚簇索引中扫描全部记录的开销(也就是最后的95 * 0.2)。如果不考虑的情况下比全表扫描开销小,则会把这个开销加上,再比较。当然这种细节其实意义不大,只是做个补充。
此外,还有一个值得补充的内容。我们说回表的开销是1.0.但对于ref访问方法来说,这个回表开销是有上限的,对ref而言回表的开销既不能超过访问总页面中1/10的页面的开销,也不能超过全表扫描的IO成本的三倍。这可能是因为使用ref方法触发回表时,那些记录对应的主键值是连续的,因此在回表过程中可以很好的利用IO预取技术,降低开销。当然具体的数值是不用背的,权作了解。
基于索引统计数据的成本计算
之前我们通过定位最左记录和最右记录在B+树的位置来判断扫描区间中一共有多少条记录的方法叫做index dive。
事实上还有更快但是精度更低的方法。
考虑一个这样的sql:
select * from single_table where key1 in ('aaa', 'bbb', .......);
如果这个in后面的大括号中,有10000个扫描区间,怎么统计呢?难道要做10000次index dive么?
答案显然是否定的,那样开销太大了。那么具体多少个扫描区间以上我们不做index dive呢?其实是有一个对应的变量的,变量叫做eq_range_index_dive_limit。默认是200。可以通过
show variables like '%dive%';
来查看。
对于扫描区间太多的情况,我们会计算key1列的cardinality。cardinality中文叫做势,也就是不重复的值的个数。
假设一共有10000个记录,key1列的势是1000,也就是说每个值会有10条记录。因此当扫描区间数为10000时,大概有10000 * 10 = 100000个记录。
这种算法非常快,但是准确性不高。
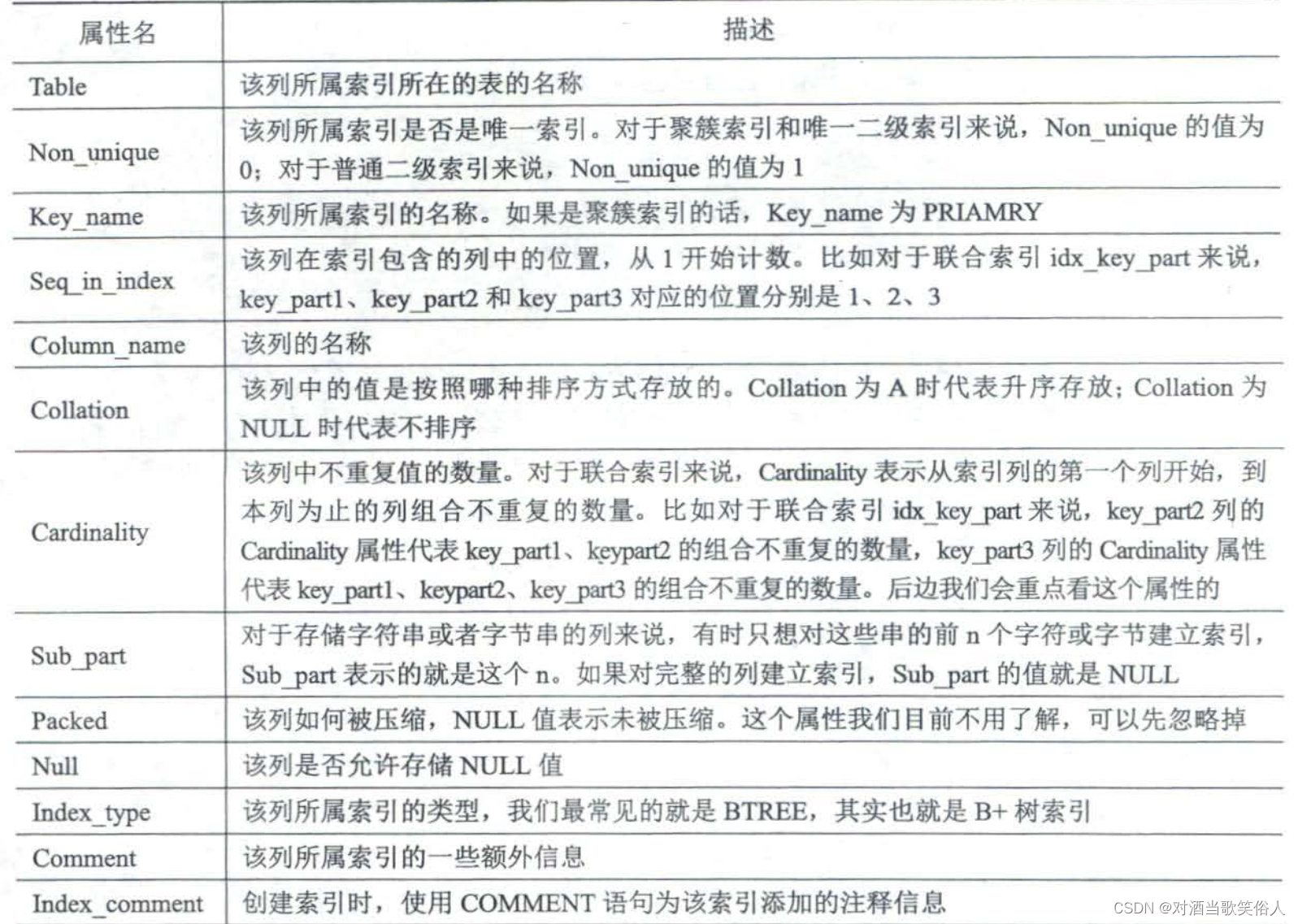
记录总数用show table status就能查看了,那如何查看势呢?语句是
show index from single_table;
查出来的结果有以下这些列
12.3
这一节主要是连接查询。为了描述方便,我们假设有个和single_table一模一样的表叫做single_table2,为了方便称呼,一个叫s1,一个叫s2。
条件过滤
连接查询的成本主要是驱动表访问成本+n次被驱动表访问成本。其中,n的学名叫扇出。
我们当然希望扇出越小越好,但很多时候分析扇出并非易事,如下:
select * from s1 inner join s2 where s1.common_field > 'xyz';
因为common_field列上没有索引,所以无法判断驱动表的扇出,只能靠猜测,或者叫经验值。
再看个例子
select * from s1 inner join s2 where
s1.key2 > 10 and s1.key2 < 1000 and
s1.common_field > 'xyz';
根据key2可以定位出95个记录(上一节的例子),因此只需要判断95个记录里有多少符合剩下的条件即可。
事实上,在5.7版本以前,我们直接把扫描区间中的记录数当作扇出,不会进一步判断。比如上面的例子,正常来说应该在95个记录里面继续估计扇出值,但在老版本我们不会估计,直接拿95当扇出值。
另一方面,所谓的估计是口语化的说法,实际是根据工程经验来确定的。“经验阈值”,dddd。
两表连接成本分析
连接查询总成本 =单次访问驱动表的成本+驱动表扇出值 ×单次访问被驱动表的成本
对于左外连接或右外连接来说,它们的驱动表是固定的。所以只需单独地计算每个表开销最低的方案即可。
但是对内连接来说,驱动表和被驱动表位置是可以互换的。
左外连接和右外连接有时可以优化成内连接。下一章会进行详细讨论。
以这个sql为例:
select * from s1 inner join s2
on s1.key1 = s2.common_field
where s1.key2 > 10 and s1.key2 < 1000
and s2.key2 > 1000 and s2.key2 < 2000
要么是s1驱动表,要么是s2驱动表。为了决定到底谁当驱动表,我们需要具体计算。
s1作为驱动表
首先根据
where s1.key2 > 10 and s1.key2 < 1000
这个与s1单表有关的条件,进行判断,看看是走表扫描,还是走key2所在的索引。前面分析过,正常来说应该走key2对应的索引。
然后考虑连接,这个过程相当于把
s1.key1 = s2.common_field 变成 s2.common_field = 常数
这个列上没有索引,所以这个条件没可能加速查找。
我们还是考虑对s2来说是走key2还是走全表扫描。根据前文分析可以得知,应该走key2上的索引。
所以,对这个查询来说,总的开销是s1(uk_key2) + s1扇出 * s2 (使用uk_key2)
使用s2做驱动表
对s2表自身来说,开销是不变的。
但在连接s1的时候,情况会发生变化,相当于我们有两个条件
s1.key1 = 常数
s1.key2 > 10 and s1.key2 < 1000
由于key1列上有索引,又是和常数做判断,很有可能是ref访问方法。
这样的话,就要多分析一下走key1列对应的索引是不是更快。开销的分析方法可以用基于成本的和基于统计数据的。
总之,最后开销会变成s2(uk_key2) + s2扇出 * s1(使用idx_key1)
总结
主要的优化方法是考虑减少扇出,以及尽可能的让连接列命中索引。
多表连接成本分析
其实多表连接可能性是非常多的。总的可能数是阶乘级别的。
如果都算一遍的话,开销可能很大。当然,也没有特别好的方法。数据量大了查询必然慢。
但是还是有一些小的优化可以用,类似于剪枝。
比如:
- 提前结束某种连接顺序的评估:如果这个方案没判断完的时候就比之前做的方案效果差,那肯定不用继续判断这个方案了。
- 系统变量optimizer_search_depth:表数小于这个值才穷举,否则不穷举。
- 根据工程经验,有些离谱的顺序直接不判断
等等…
12.4
除了读取一个页的成本是1.0,读取检测一行的成本是0.2以外,还有很多成本常数。它们存储在数据库的表中:
先来看看server_cost表
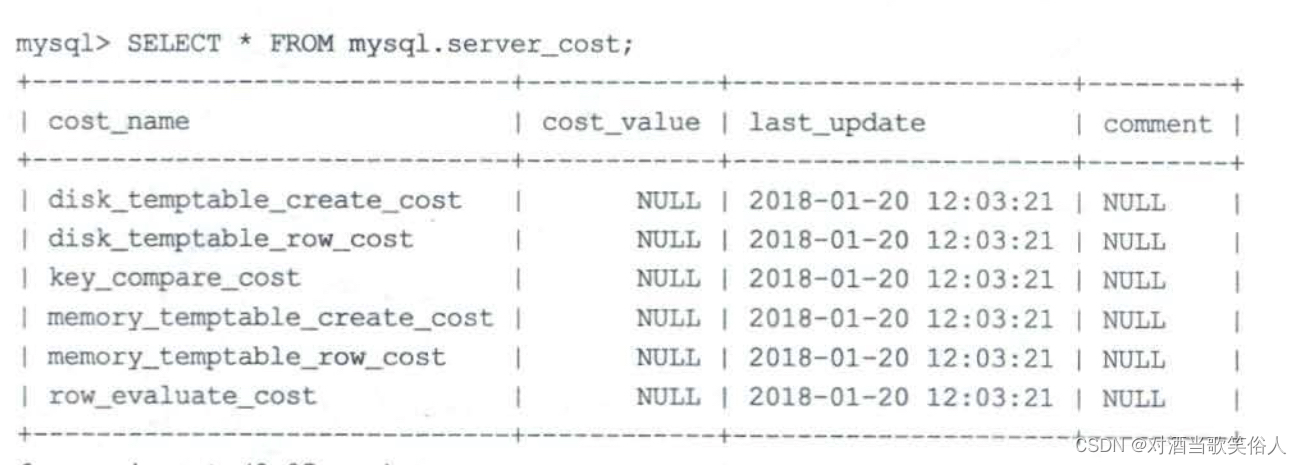
cost_value是变量的值,如果是null就用默认值。
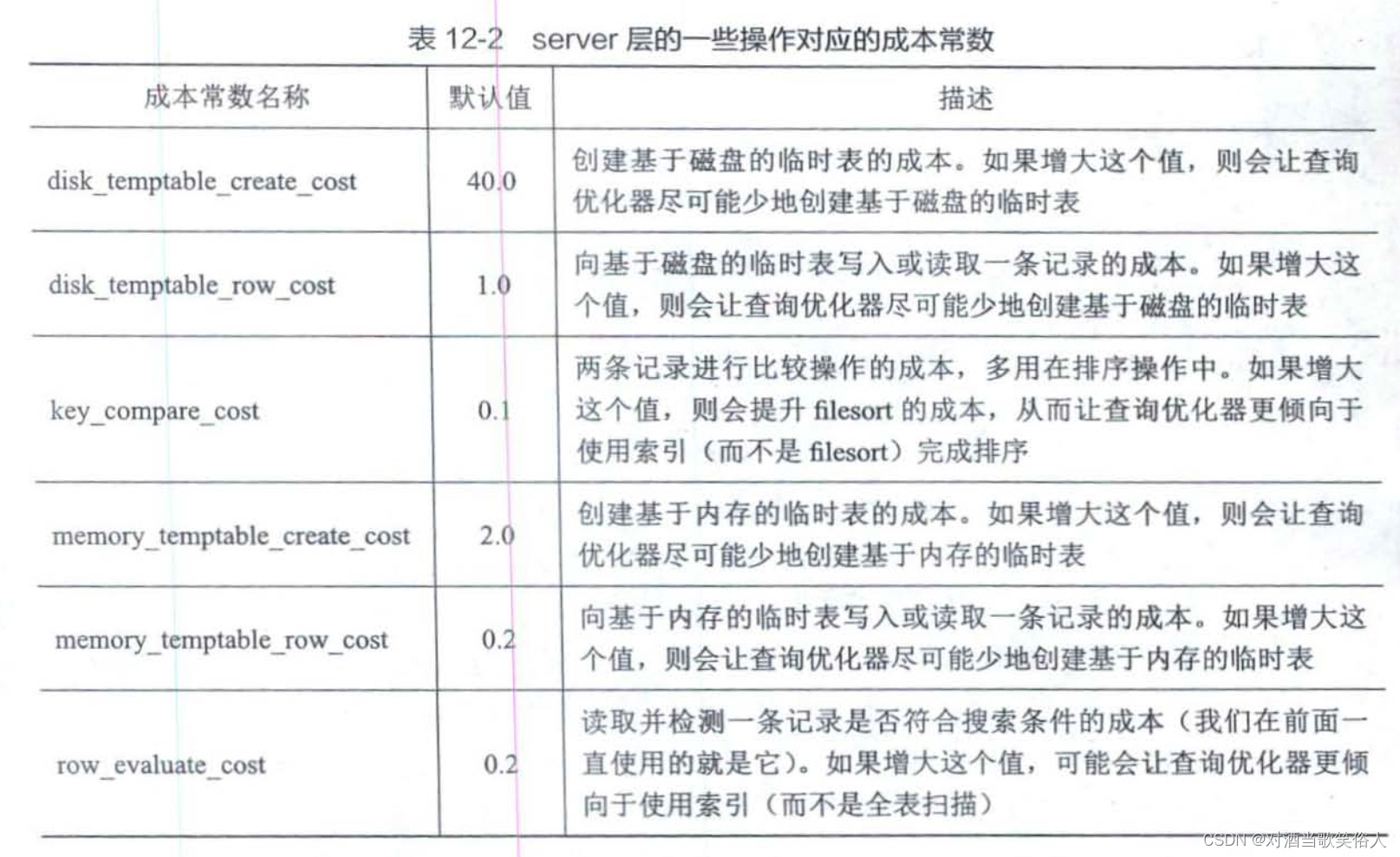
在我们执行distinct、group by、 union等子句的时候,可能会进行排序。排序可能会产生临时表。比如distinct,可以先建立内存临时表,把查到的数据写入到里面,在插入过程中实现去重,而在数据量大的时候可以建立磁盘临时表。
想更改值的话,直接update即可。当然更新完了要
flush optimizer_costs;
再看看engine_cost表

多了两个列,一个是engine_name,一个是device_type。
engine_name就是引擎名,默认是default,那就是所有引擎都会用。
device_type是硬件设备类型,比如固态/机械。5.7版本默认是0,也就意味着不区分。新的版本可能根据磁盘类型来修改这个值。
而默认值是这样的

这里,为什么读内存和读磁盘默认的开销都是1.0呢?这可能是因为mysql现在还不能很好的判断要访问的块有多少在磁盘里,有多少在内存里。未来也许会更新。
更新和刷新的方法和以前是一样的,不做赘述了。

















 1291
1291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









