






任务类型:
1、Speech Recognition
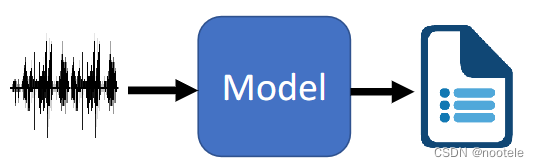
2、Text-to-Speech Synthesis
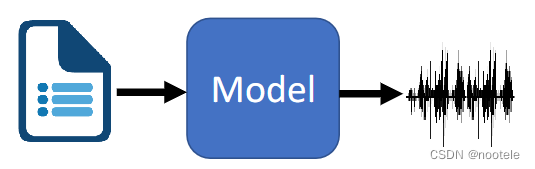
3、Speech Separation
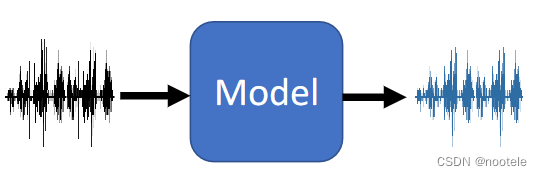
4、Speaker Recognition
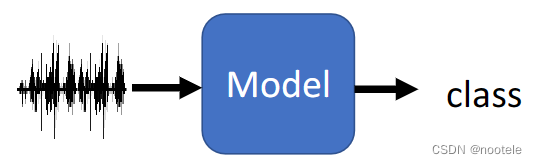
5、多种任务类型情况(NLP Tasks):
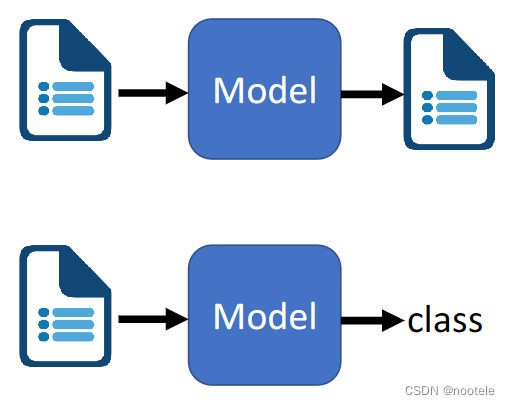
1、语音识别(Speech Recognition)
token
token是在模型输出时选择的如何处理文本或语言的最小单位
1、Phoneme:
发音的基本单位,和语音关系较大(eg音标,需要语音学家进行提取和转换)
之后将Phoneme再转成对应的文字(eg )

2、Grapheme:
书写的基本单位,比较容易
英文:26个英文字母+空格+标点符号
中文:大约4000个字

3、Word token:
对于某些语言来说,其词汇数量巨大,且没有空格区分
4、Morpheme:
最小的意思单元,长度小于word,大于grapheme。由语言学家提取or统计大量重复出现部分
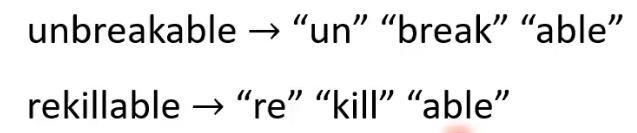
5、Bytes:
输出编码,例如 UTF-8
声学特征(Acoustic Feature):
1、帧向量
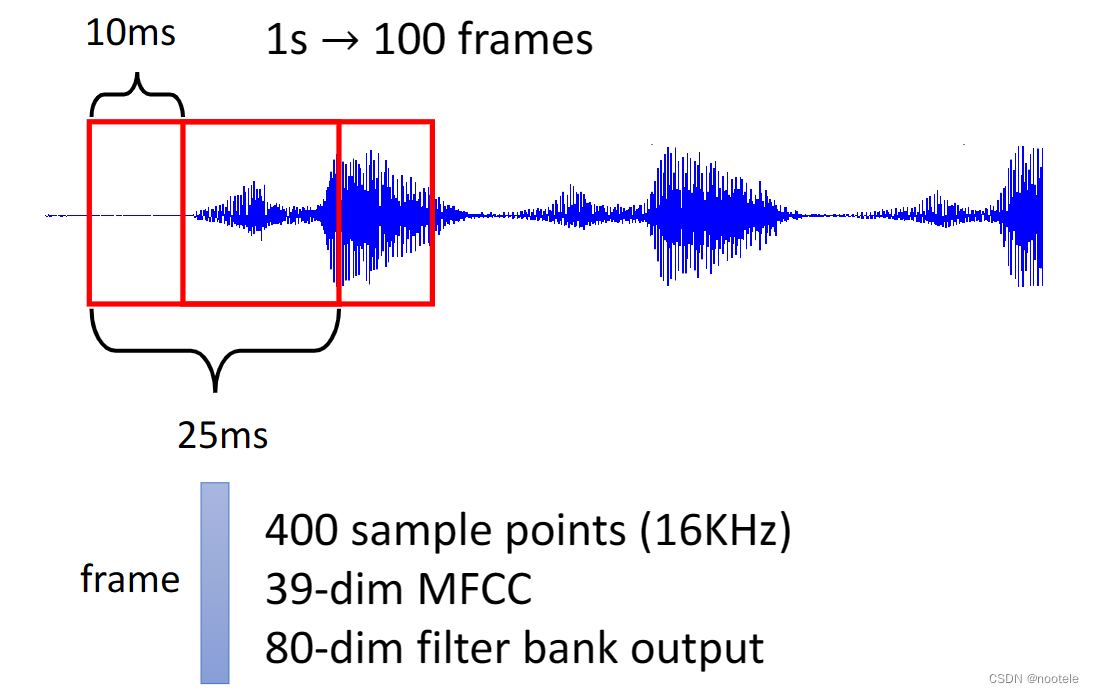
分帧:
每25ms作为一帧(frame),要是频率为16KHz的话,有400个采样点,即400维的向量。
转换:
使用滤波器(filter bank)转换为80维,使用MFCC转换为39维。
加窗:
右移10ms,获得下一个窗口,抽出下一帧,即1s声音讯号可以获得100帧,即100个400/39/80维的向量。
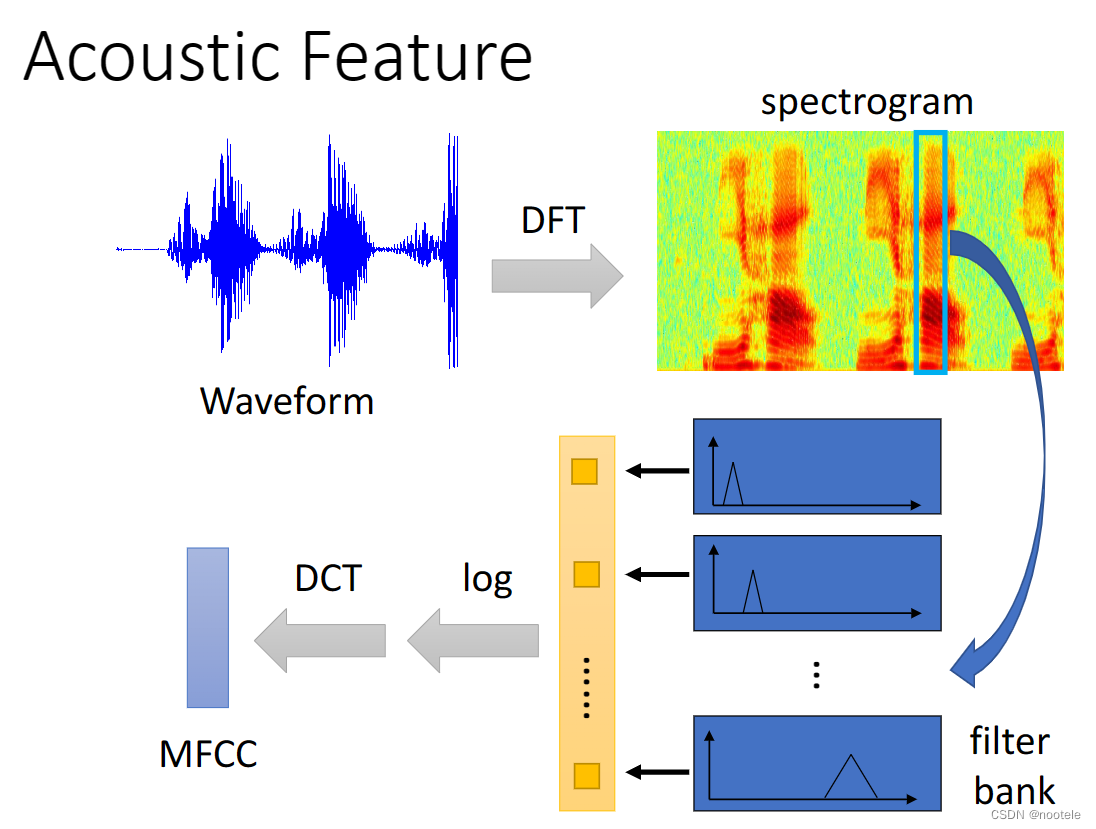
声波经过 离散傅立叶变换 得到 声谱图 经过 滤波器组 取对数经过 离散余弦变换 获得 Mel频率倒谱系数。
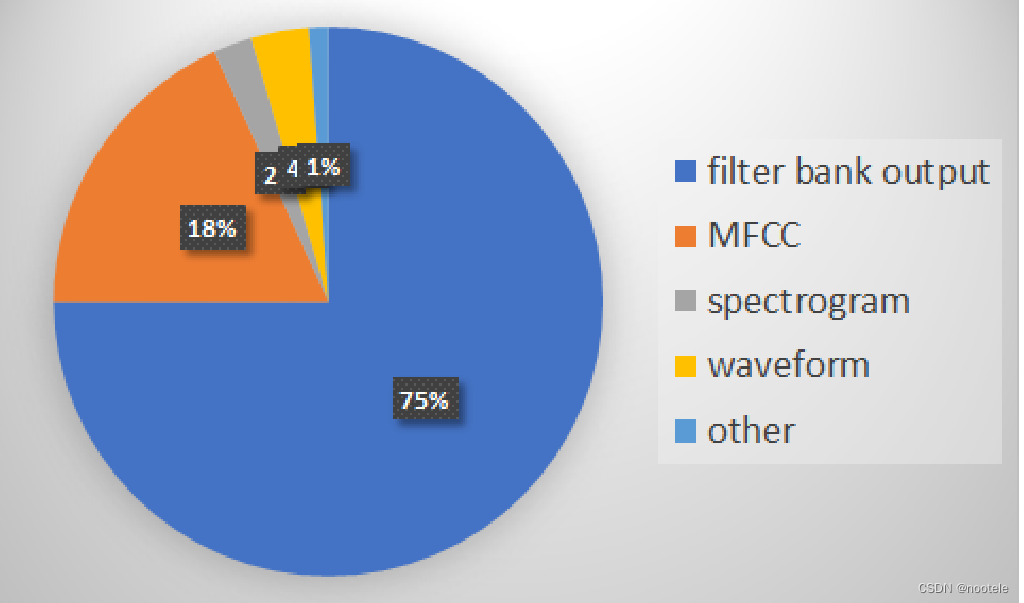
不同音频处理方式在论文中的使用占比:
重要论文(seq-seq)
• Listen, Attend, and Spell (LAS)
• Connectionist Temporal Classification (CTC)
• RNN Transducer (RNN-T)
• Neural Transducer
• Monotonic Chunkwise Attention (MoChA)
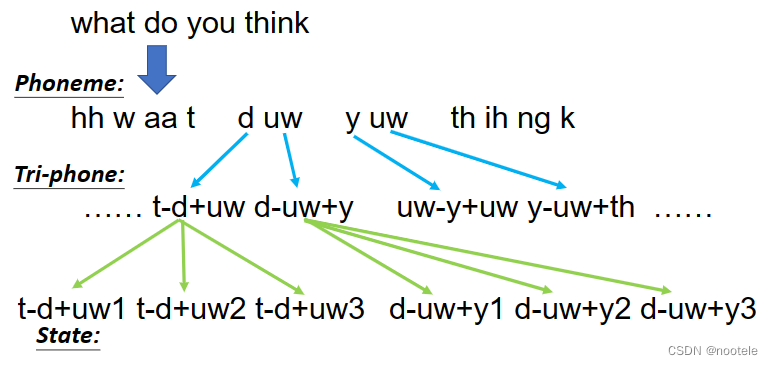
Hidden Markov Model(HMM):
概念:输入通过一个隐藏的马尔科夫链随机生成不可观测的状态随机序列,再由一个状态生成一个观测,从而产生观测随机序列的过程,在这个过程中,需要一个状态转移概率矩阵A,一个观测概率矩阵B,一个初始状态概率向量α。
States s:比phoneme还小的发音单位
将根据sequence Y产生X的概率计算转化为根据States产生X的概率
![]()
Transition Probability:从一个state转到另一个state的概率
Emission Probability:给一个state,产生vector的概率
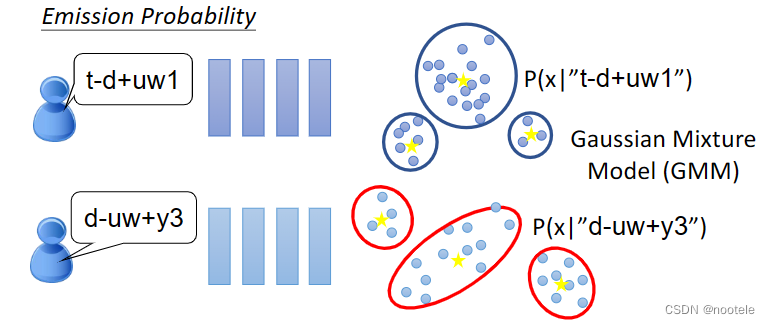
Subspace GMM:所有的state共用同一个GMM
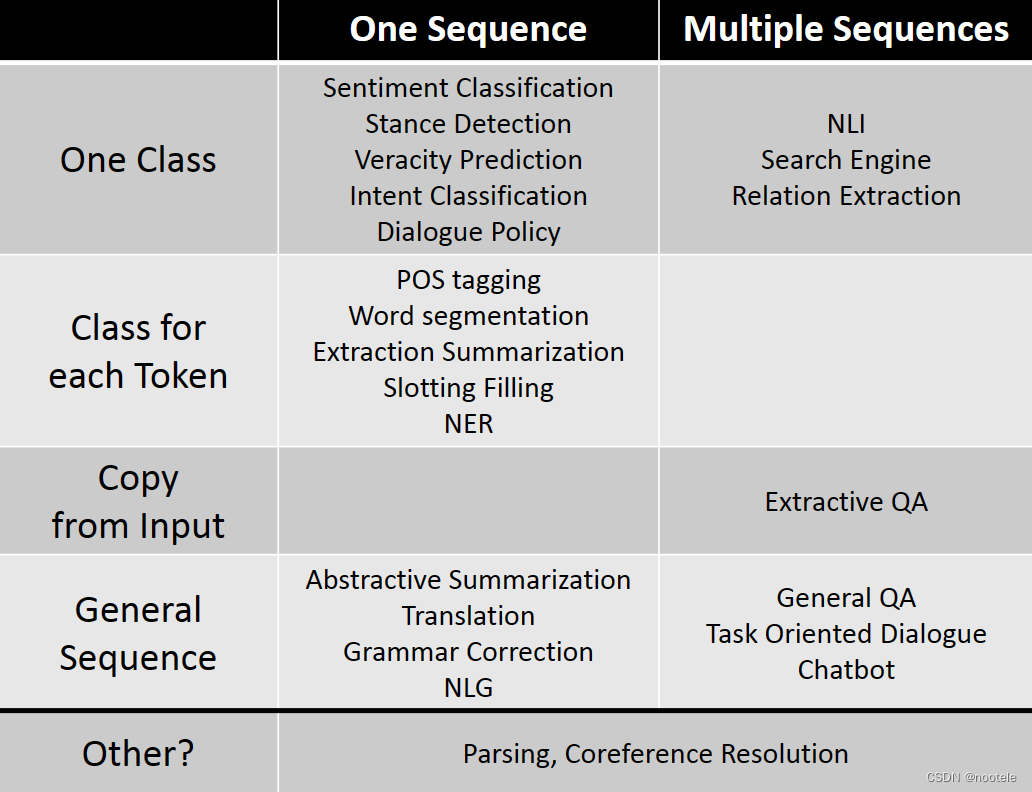
5、NLP Tasks
前处理方法:
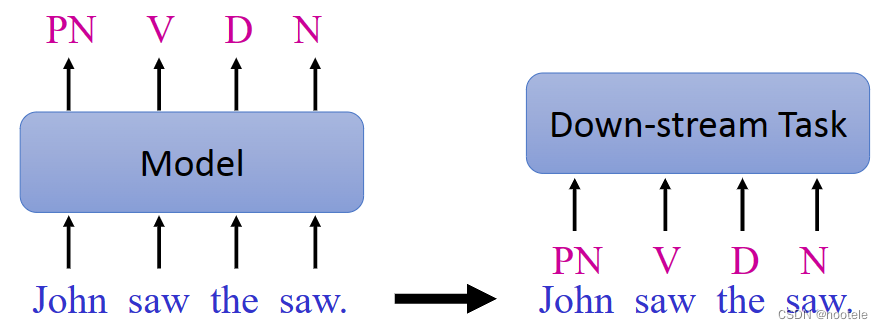
1、Part-of-Speech (POS) Tagging
用词性注释句子中的每个单词(例如动词、形容词、名词)
2、Word Segmentation
分割单词
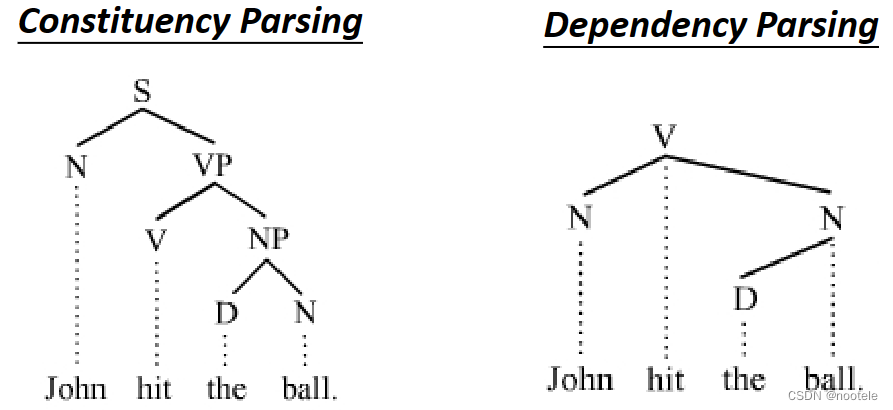
3、Parsing
4、Coreference Resolution(指代消除)
输入一段文本,让模型判断文中意思相同的内容

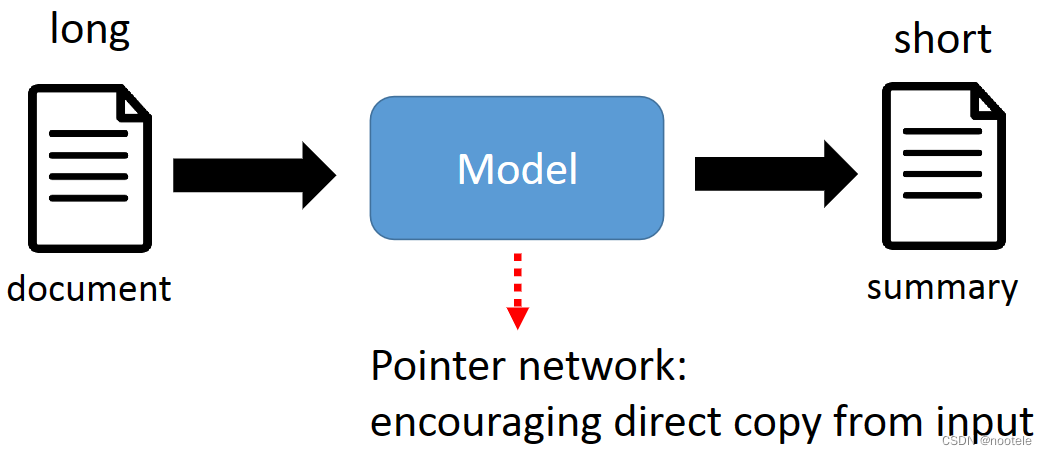
5、Summarization
Extractive summarization
输入一些句子,让model选择其中的一些作为摘要

Abstractive summarization
输入一段文本,让model自己概括一段简短的文字作为摘要
具体应用:
1、Machine Translation
翻译任务
2、Grammar Error Correction
文法识别
3、Sentiment Classification
情感判断/正向负向判断
4、Stance Detection
输入文本,从Support, Denying, Querying, Commenting (SDQC)四类中给出判断
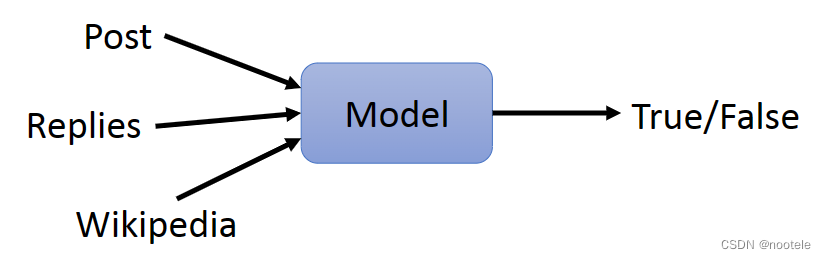
5、Veracity Prediction
文本内容真实性判断
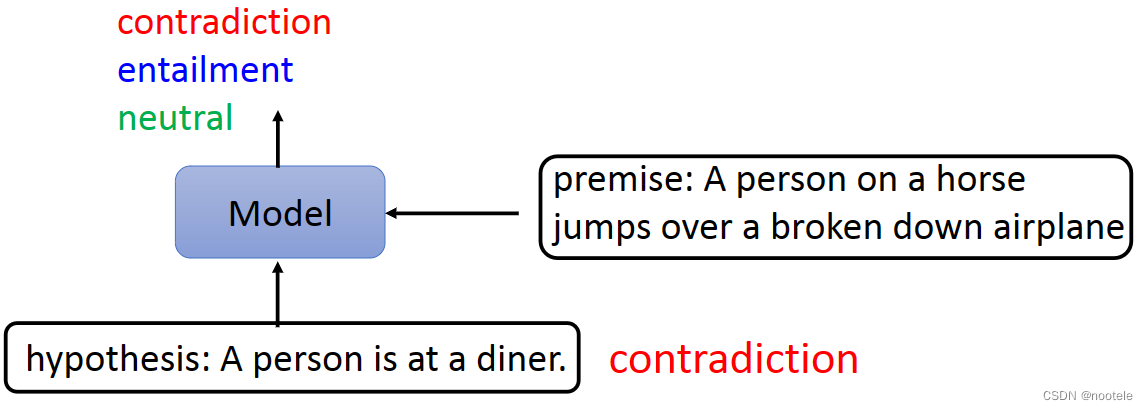
6、Natural Language Inference (NLI)
通过输入的premise,推断hypothesis
7、Search Engine
搜索引擎
8、Question Answering (QA)
问答机器人
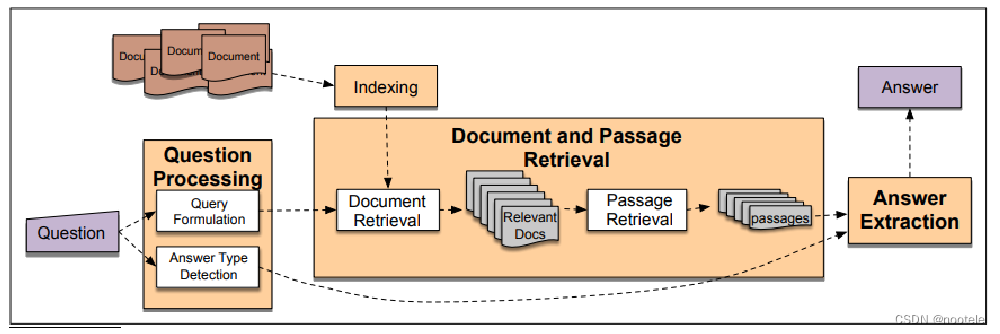
传统问答系统:
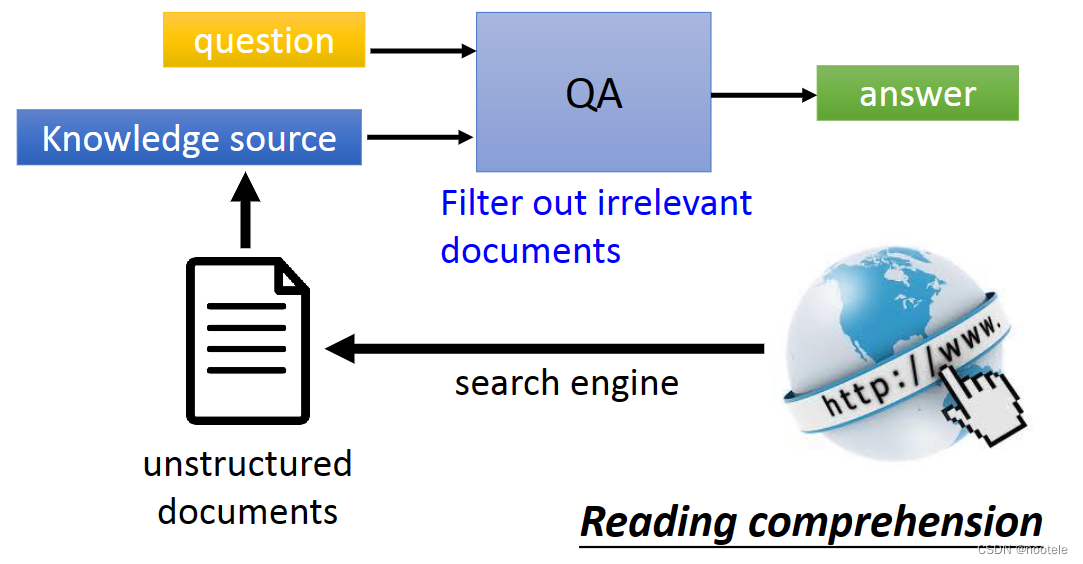
基于深度学习的问答系统:
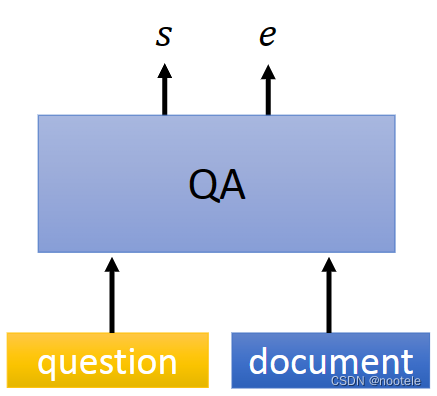
简洁版:(Extractive QA)将概括后的答案作为回答输入,而不是在大量文本中自己识别有用的回答
9、Chattin
聊天机器人
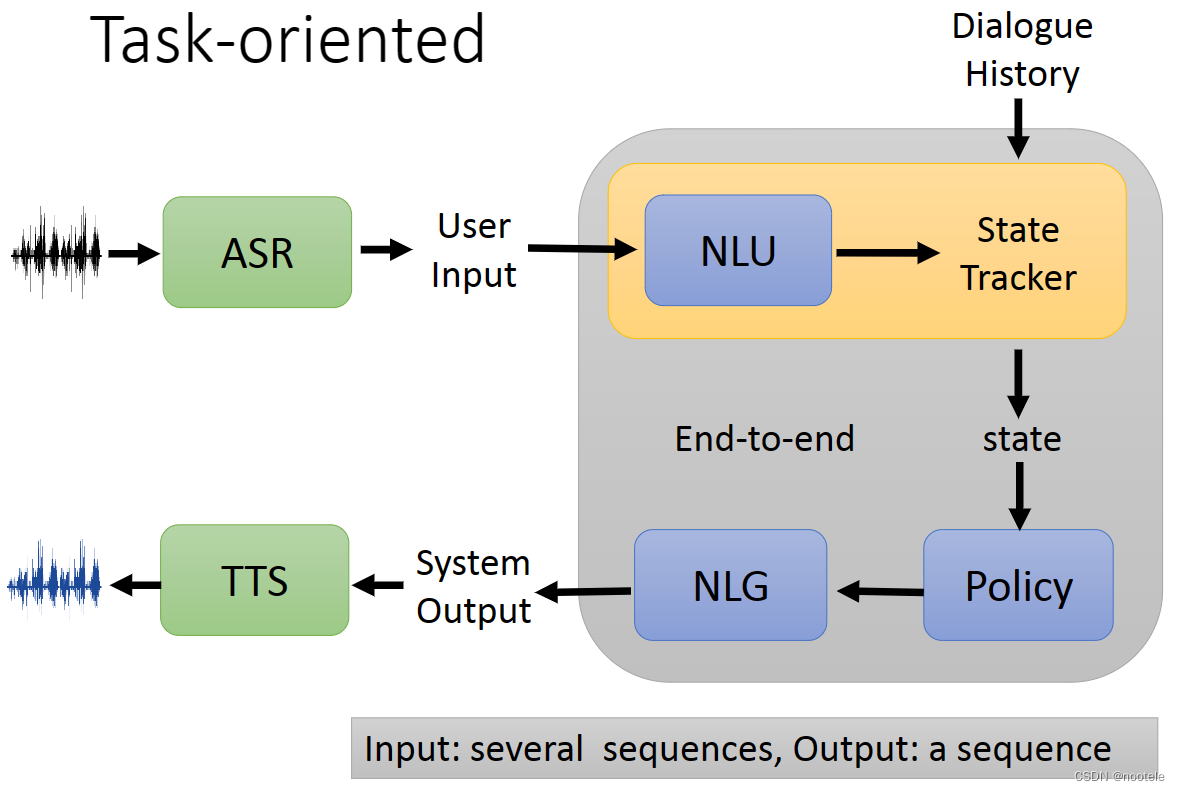
10、Task-oriented
任务导向的对话机器人
分模块实现:
Natural Language Understanding(NLU) --> State Tracker --> Policy --> Natural Language Generation (NLG)
State Tracker:摘要,将不重要的内容过滤掉,只保留重要信息得到一个State
Policy:根据输入的State来决定action
11、Knowledge Graph
Model读入文本后,理解出Entity之间的Graph,简单理解的话,可以分为下面两步
1、Name Entity Recognition (NER):抽取出entity
2、Relation Extraction:得到entity的graph
6、Non-Autoregressive Sequence Generation
传统自回归模型会有多个stage,通过上一个timestep输入生成下一步隐向量。实现的模型主要为RNN,transformer的Decoder。这样的模型存在的问题是速度很慢。非自回归模型则是直接生成输出。但是这样有两个问题:1、output没有相互依赖的structure。2、没有latent variable。
在input有多种output情况中的multi-modality problem
在图像生成中,可以通过添加GAN学习整体输入的structure dependen解决,但由于文本是离散结构,用GAN没有较好的效果。
Vanilla NAT(Non-Autoregressive Translation):
翻译任务中第一篇使用非自回归的model
Fertility
添加一个额外的aligner,给出两种语言中词汇的映射。

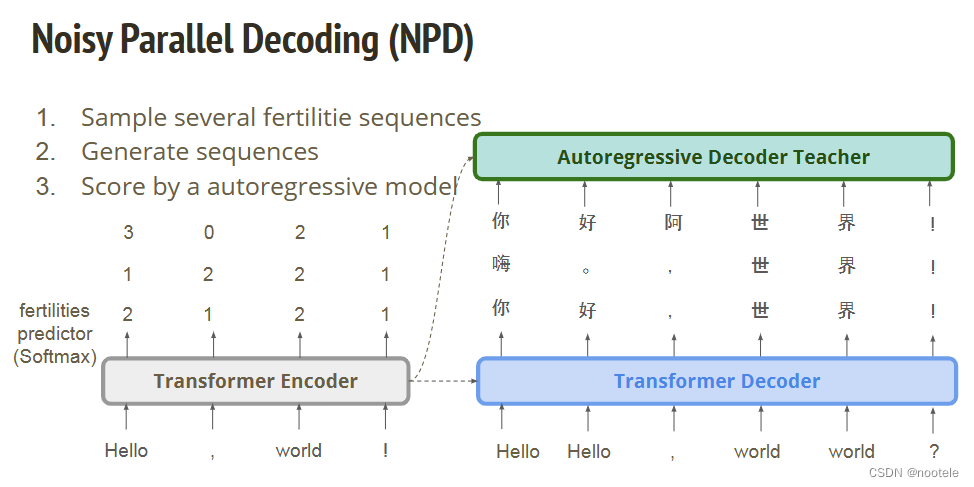
Sequence-level knowledge distillation
设计一个teacher-student net,Teacher: Autoregressive model, Student: Non-autoregressive model
teacher net 负责对输入进行筛选,
7、Bert
Contextualized Word Embedding:
让模型看到一段文本后再给出每个token的embedding
让模型变小的技术:
• Network Pruning 网络剪枝
• Knowledge Distillation 知识蒸馏
• Parameter Quantization 参数量化
• Architecture Design 结构设计
Fine tune
How to Pre-train















 1039
1039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









