







 VulDeePecker是一个利用深度学习进行漏洞检测的系统,通过将程序代码转化为code gadget并转换为向量,采用BLSTM神经网络进行分类。该系统在Xen、Seamonkey和Libav中发现了未公开漏洞,但在假阳性率上仍有提升空间。研究发现,人工选择关键的library/API function calls能提升系统性能。
VulDeePecker是一个利用深度学习进行漏洞检测的系统,通过将程序代码转化为code gadget并转换为向量,采用BLSTM神经网络进行分类。该系统在Xen、Seamonkey和Libav中发现了未公开漏洞,但在假阳性率上仍有提升空间。研究发现,人工选择关键的library/API function calls能提升系统性能。
摘要
漏洞挖掘\探测往往要消耗大量的人力,繁琐而枯燥。漏洞的自动检测是一个很难的课题,常规的方法往往伴随很高的假阴和假阳。近年来深度学习得到充分发展,但是并未在漏洞探测方面取得很好的应用。
实际上,深度学习本身也不是为了探测漏洞而发明的,作者是第一个将深度学习有效利用于漏洞探测的学者,并为之提出了几条(建设性的)guiding principles。
INTRODUCTION
现存的自动化漏洞挖掘方法往往有两个大的弊端:需要密集的人力劳动、假阴率比较高。
(PS:阴或阳是指判断结果,真或假是指判断结果的对错,所以假阴、假阳这种都是判断错了,假X率自然都是越低越好,但假阴率和假阳率很难同时低,往往是要么错杀,要么漏过)
现存的自动化漏洞探测方法往往需要安全专家定义很多特征,定义的特征的质量直接影响漏洞探测的结果。最近的两款漏洞探测系统,VUDDY和VulPecker虽然没有让安全专家设置特征,但假阴率较高,并且往往只能针对特定的漏洞类型(如code clone)。
实际上,假阳率高的系统没法用,假阴率高的系统不好用,两者很难同时低,按惯例是在保证假阳率不太高的前提下,尽可能降低假阴率(宁错杀不放过,假阴的意思是:判定为阴,但是判断错了,就是说目标是阳,这就放过了,这是最不应该的)。
在本文,作者提出了一个特定情况下的解决方案:给定一个程序的源代码,探测出其中是否存在漏洞及漏洞类型。
作者的贡献:
1、此文可以说是深度学习在漏洞探测领域的开山之作,少有前人,故而作者对于深度学习在漏洞探测领域的应用提出了几点guiding priciples。(方法论)
2、设计并实现了一套系统Vulnerability Deep Pecker (VulDeePecker):此系统可同时处理两类漏洞(见下文),效率高,且能在人工辅助下提升性能。VulDeePecker在Xen, Seamonkey和Libav中发现了4个未公开漏洞。
3、深度学习需要大量的数据,然而此领域鲜有前人的工作,更无论数据集,作者使用 the NVD and the Software Assurance Reference Dataset (SARD) project合成了一个数据集。
GUIDING PRINCIPLES
深度学习要想在漏洞探测领域得到应用,需要解决以下几个大问题:
1、如何将程序转化为模型认的懂的单位?
2、转化的粒度?是program、function还是line?
3、选用何种深度学习模型?
GUIDING PRINCIPLES就是对这几个问题的解答:
1、深度学习算法往往接受vector作为输入,所以程序必须转为vector,且vector必须保存程序的原有语义。作者使用了code gadget(下文介绍)这个概念,即小数量的几行相关代码。
2、转化的粒度不能太大,否则无法定位漏洞位置;转化的粒度不能太小,否则必将失去原有代码逻辑。code gadget由小数量的几行相关代码(不一定连续)组成,可以避免粒度太大或太小。
3、神经网络在图像处理、语音识别、自然语言处理方面取得了成功,但这些领域和漏洞探测几乎不沾边。非要说沾边,那只有自然语言处理,且必须是兼顾上下文和语境的自然语言处理神经网络,作者选用了BLSTM(双向长短时记忆网络)。
DESIGN OF VULDEEPECKER
A、定义code gadget
先将程序转化为code gadget,再将code gadget转化为vector。
code gadget是程序中的若干行代码,这些代码在语义上相关联(有data依赖或控制依赖)。
作者的设计理念如下:
寻找关键点(key),漏洞的产生往往是由几行关键代码。由于不恰当使用library/API函数而产生的漏洞的key必然是library/API function calls;由于缓冲区溢出产生的漏洞,key必然是数组\指针之类。一种漏洞可能有多种key,一个key也可能对应多个漏洞。

此文中,作者只针对特定的两类key。找和这两类key相关联的代码组成code gadget也非易事,作者使用了商业软件checkMarx(可以分析数据流与控制流,但后面可以看到,本文仅仅涉及数据流)。
B、整体设计
VulDeePecker作为深度学习模型,有两个阶段:学习(或曰训练)阶段、探测(或曰测试)阶段。
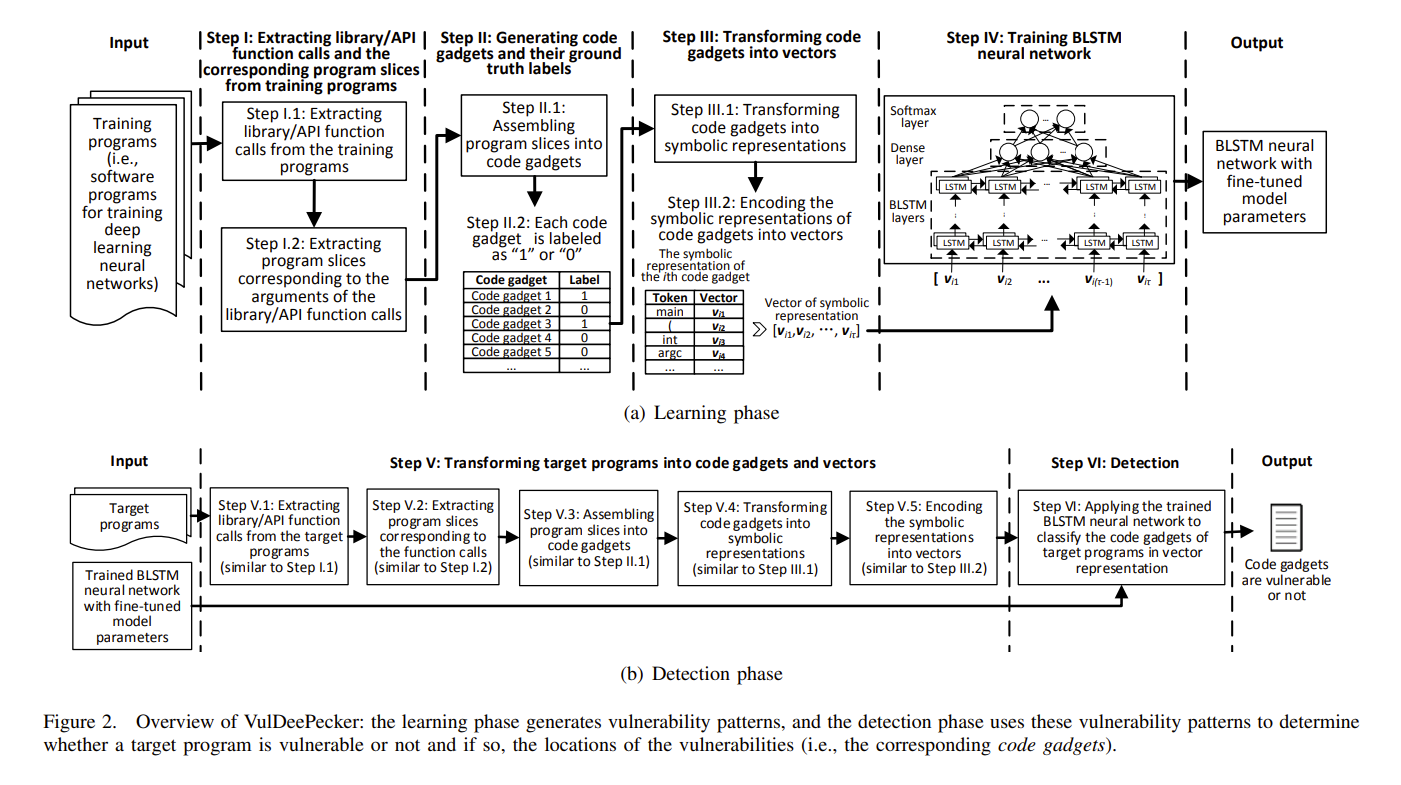
1)学习阶段
①提取library/API function calls 和相关程序切片。
②将程序切片组成code gadgets(一个library/API function call一个code gadget),并为 code gadgets打标签(有无漏洞及漏洞位置)。
③将code gadget转为symbolic representation,再将symbolic representation转为BLSTM可以接受的vector。
④训练BLSTM神经网络
2)detection阶段
⑤将target program转为code gadget和vector(与学习阶段类似,先提取library/API function calls 和相关程序切片,再将程序切片组成code gadgets,一个library/API function call一个code gadget,将code gadget转为symbolic representation,再将symbolic representation转为BLSTM可以接受的vector)
⑥使用BLSTM神经网络对code gadget对应的vector进行分类。
C、详述提取library/API function calls和program slices
1、提取library/API function calls和program slices
1)提取library/API function calls
将library/API function calls分为forward和backward。
前者直接从外部接收参数(如socket、command line);后者不直接从外部接收参数。
对于前者,重点关注接收外部参数的语句;对于后者重点关注影响其它参数的语句。
2)提取program slices
根据library/API function calls的参数,提取forward slices和backward slices,前者受这些参数影响,后者影响这些参数。
至于如何根据参数提取程序片段,作者使用了商业软件Checkmarx(尤其是其中的data dependency graph功能)。当和library/API function call参数相关的切片在该library/API function call处分支或位于其之后时,生成forward slices;当和library/API function call参数相关的切片在该library/API function call处合并或位于其之前时,生成backward slices。
slices在Checkmarx中被表示为chain,其实用tree也可。
D、详述提取code gadgets和打标签
1)将program slices转为code gadgets
首先,给定一个library/API function call和相应的程序slices,根据语句在用户定义函数中出现的顺序,将属于同一个用户定义函数的语句组合成一个片段(如果任何语句存在重复,则消除重复)。
其次,将属于不同用户定义函数的语句组装到单个code gadget中。这一步要保留原有代码片段顺序的,若本来就无有意义的顺序则使用随机顺序。
2)打标签
每个code gadget需要标记为“1”(有漏洞)和“0”(无漏洞)。如果code gadget对应于训练数据集中已知的漏洞,则将其标记为“1”;否则,它被标记为“0”。
E、详述将code gadgets 转为vectors
1)将code gadget转换为相应的符号表示(symbolic representation)
首先,删除非ascii字符和注释;其次,以一对一的方式将用户定义的变量映射到符号名(例如,“VAR1”,“VAR2”);第三,以一对一的方式将用户定义的函数映射到符号名称(例如,“FUN1”,“FUN2”)。
不过要注意,在第二步和第三步中,本来不同的名称可能会被转为相同的名称。
2)将符号表示(symbolic representation)编码为向量
每个code gadget需要通过其符号表示编码为向量。先通过词法分析将符号表示中的code gadget划分为一系列token,包括标识符、关键字、操作符和符号。
例如,“strcpy(VAR5, VAR2);“由7个符号组成的序列表示:” strcpy “, " (”, " VAR5 ", ", ", ", " VAR2 ", “) “和”;”。
接下来使用word2vec将这些token转换为vector。word2vec工具将一个token映射到一个整数,然后将其转换为一个固定长度的向量。但由于code gadget可能有不同数量的token,因此相应的向量可能具有不同的长度。
但是BLSTM采用等长向量作为输入,为此作者引入了一个参数τ作为与code gadget对应的vector的固定长度。
当vector长度小于τ时,分两种情况:如果code gadget是由一个或多个backward slices生成的,则在vector的开头加零,否则在末尾添加0。
当vector长度大于τ时,也分两种情况:如果code gadget是由一个或多个backward slices生成生成的,则删除向量的开头部分,否则删除向量的末尾部分。
这确保了从backward slice的每个code gadget的最后一个语句是library/API function call,而forward slice的每个code gadget的第一个语句也是library/API function call。至此,每个code gadget都表示为一个长度为τ的vector。
调参的结果如下,
code gadgets 的向量表示的tokens设置为50个,dropout设置为0.5,batch size设置为64,epochs设置为4,minibatch 随机梯度下降法,选择300个隐藏节点,采用默认的学习率1.0来进行训练。
EXPERIMENTS AND RESULTS
几个关键的问题:
1、VDP能否同时处理多类漏洞?
2、安全专家能否辅助提升VDP的性能?
3、与其它漏洞探测系统相比,VDP效率如何?
A、评估漏洞检测系统的指标
作为人工智能的模型,VDP采用了false positive rate (F P R), false negative rate (F NR), true positive rate or recall (T P R), precision §, and F1-measure (F1)来评估。
作为非人工智能专业出身的我,对于这些指标并不能很分的清,但是也找到了一点偷懒的方法:
阴或阳是指判断结果,真或假是指判断结果的对错,所以假阴、假阳这种都是判断错了,假X率自然都是越低越好,真X率越高越好。真X率就是评判为X且评判正确的数量与X总体数量的比值。
但实际上假阴率和假阳率很难同时低,往往是要么错杀,要么漏过。
B、准备VDP的输入
主要是NVD和SARD。
在此文中,作者专注于两类漏洞:buffer error (CWE-119) and resource management error (CWE-399)。这两类漏洞非常普遍,所以数据量是很可观的。
作者总共从NVD中收集到520个与buffer error 漏洞相关的开源程序和320个与resource management error漏洞相关的开源程序,从SARD中收集了8,122个与buffer error 漏洞相关的程序和1,729个与resource management error漏洞相关的程序。并随机选择了80%作为训练集,20%作为测试集。
C、训练BLSTM神经网络
使用了Python的Theano与Keras。
1、提取library/API function calls和相应的slices
总共提取了56,902 library/API function calls 其中有7,255 forward function calls和49,647 backward function calls。
同时作者人工选择了124个C/C++ library/API function calls。
2.1、生成code gadgets
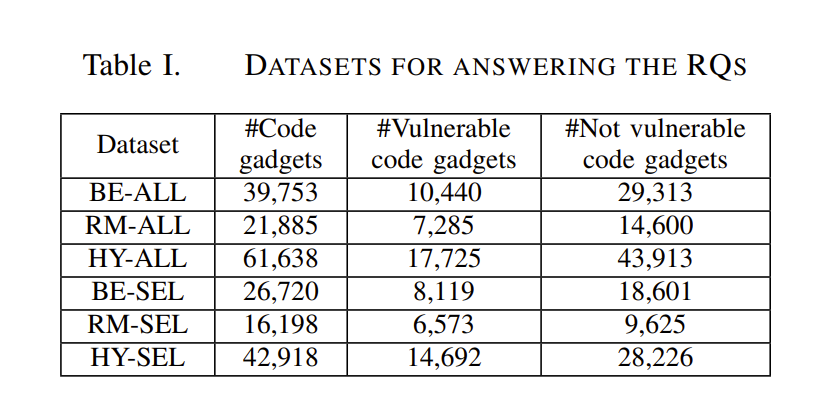
作者通过上述 function calls 和 slices生成了含有6w+code gadget的 Code Gadget Database,并衍生出6个子集。
BE-ALL:CGD中buffer error漏洞(CWE-119)和所有库/API函数调用(即在没有人工专家的情况下提取)的子集。
RM-ALL: CGD中对应于resource management error漏洞(CWE-399)和所有库/API函数调用的子集。
HY-ALL: CGD中对应于缓冲区错误漏洞(CWE-119)和resource management error漏洞(CWE-399)和所有库/API函数调用的混合(实际上与完整的CGD相同)。
BE-SEL: CGD中对应于缓冲区错误漏洞(CWE-119)和人工选择的函数调用(而不是所有函数调用)的子集。
RM-SEL: CGD中对应于resource management error漏洞(CWE-399)和手动选择的函数调用的子集。
HY-SEL: CGD中buffer error漏洞(CWE-119)和resource management error漏洞(CWE-399)的混合,以及手动选择的函数调用的子集。
2.2、打标签
具体步骤如下:
1)对于从NVD程序中提取的code gadget,重点关注那些补丁涉及行删除或修改的漏洞。
如果code gadget包含至少一条根据补丁删除或修改的语句,则自动标记为“1”,否则标记为“0”。当然这个方法并不一定完全准确。所以要人工检查标记为“1”的code gadget,纠正错误标签。
2)SARD中的每个程序已经被标记为Good(即没有安全缺陷)、Bad(即包含安全缺陷)或Mixed(即包含具有安全缺陷的函数及其修补版本)。对于从程序中提取的关于SARD的code gadget,从Good的程序中提取的code gadget标记为“0”,从Bad的或Mixed的程序中提取的code gadget中若包含至少一个脆弱语句则标记为“1”,否则标记为“0”。
作者人工筛查查看了1,000个随机code gadget的标签,发现其中只有6个(即0.6%)被错误标记,神经网络本身可以抵抗这种级别的噪声,所以无需人工去除。
除此以外,可能会遇到相同的代码小部件同时被标记为“1”和“0”的情况。造成这种现象的原因之一是数据流分析工具的不完善。在本文中作者选择删除这些代码小部件。
3、将code gadget转换为vector。
CGD总共包含6,166,401个tokens,其中23,464个是不同的。在将用户定义的变量名和函数名映射到一些符号名之后,不同令牌的数量进一步减少到10,480。这些符号表示被编码成向量,作为训练BLSTM神经网络的输入。
4、训练BLSTM神经网络。
对于表1所描述的每个数据集,作者采用10-fold cross来训练一个BLSTM神经网络,并选择与有效性相对应的最佳参数值进行漏洞检测。
D、实验结果与启示
1)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BfjybDvx-1683790197089)(null)]
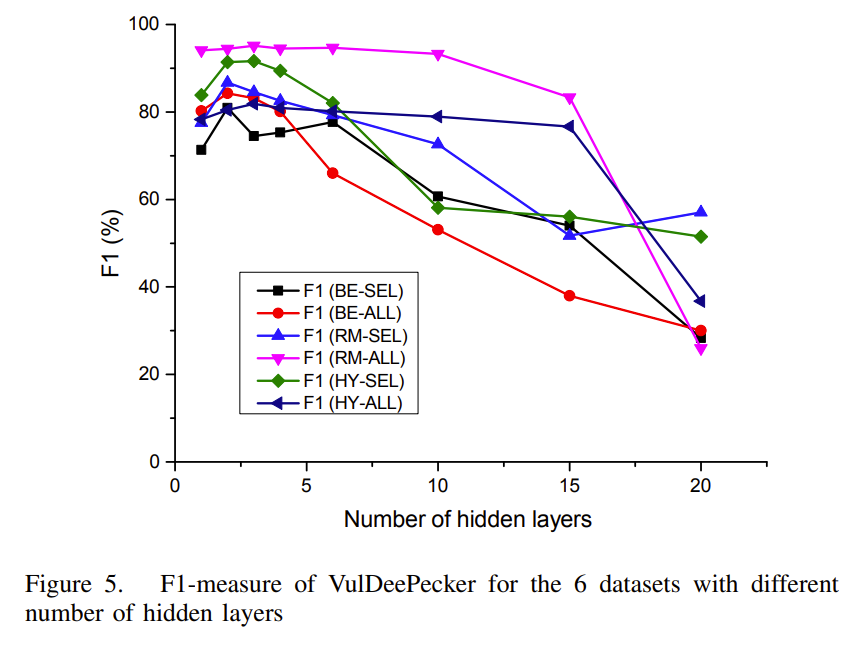
可以看出,探测出多种漏洞是没问题的,但是效果是受数据集的影响的。作者推测,HY-ALL数据集中 与漏洞相关的library/API function calls数量过大,反倒不利于提取出明确的特征,所以在一些指标上表现出的效果不如单独在BE-ALL或RM-ALL数据集上训练出的效果好,而且BE-ALL的相关的library/API function calls数量也是远远大于RM-ALL,所以二者都不如RM-ALL。
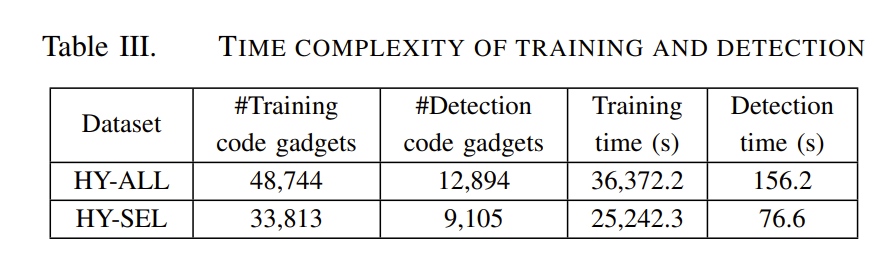
训练比较耗时间,但是detection耗时较短。
2)
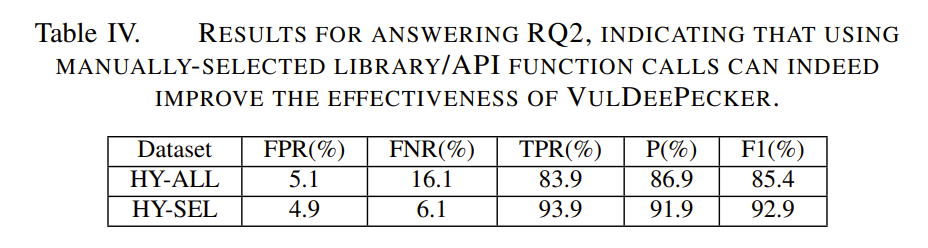
如表4所示,HY-SEL数据集训练的BLSTM网络比HY-ALL数据集训练的BLSTM网络更有效。FNR和TPR改善了10%,Precision改善5%,f1指标改善7.5%。1)中的表III显示,使用人工选择的library/API function calls的训练时间可能比使用所有library/API function calls的训练时间要短。因为需要处理的code gadget数量更少。所以人类专家的专业知识可以用来选择library/API function calls,以提高VulDeePecker的性能。
3)
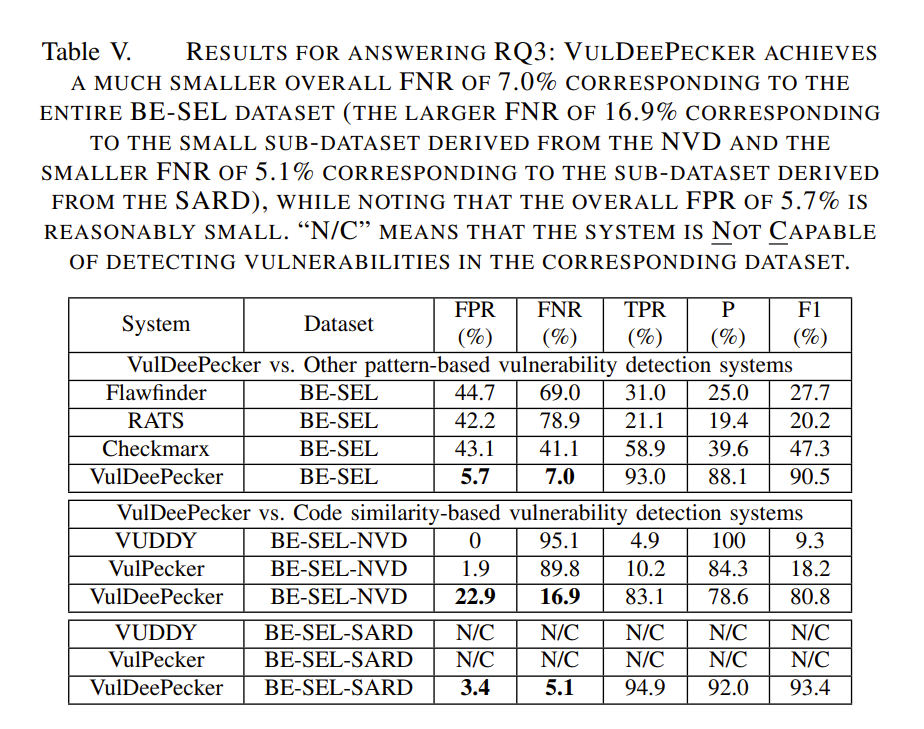
主要与两类工具做比较:
一是基于专家定义的规则的漏洞检测系统进行比较,选用Checkmarx、Flawfinder和RATS,这三款工具已经被广泛使用。
二是基于代码相似性的漏洞检测系统,这类系统主要针对clone漏洞,选用VUDDY和VulPecker(state-of-the-art级别)。需要注意一点,还需要将BE-SEL数据集分为两个子集,即BE-SEL-NVD(来自NVD的266个样本)和BE-SEL-SARD(来自SARD的样本)。因为VUDDY和VulPecker的设计目的主要是检测带有CVE id的漏洞或带有差异的漏洞,所以无法检测到BE-SEL-SARD中的漏洞。
从表中可以看出,VulDeePecker明显优于基于pattern的漏洞检测系统。Flawfinder和rat不使用数据流分析,因此错过了许多漏洞;Checkmarx使用了数据流分析,但其识别漏洞的规则是由专家定义的,实际效果并不好(这进一步强调了将专家从繁琐的诸如定义特征这类任务中解放出来的重要性)。通过利用数据流分析,基于深度学习的漏洞检测系统可以更有效。这也提示我们通过利用控制流,系统也可以更有效。(只是猜测,验证或否定这一推测是未来工作)
其次,对于BE-SEL-NVD子数据集,VUDDY和VulPecker的FNR极高,F1测量值极低。FNR高的原因在于:VUDDY只能检测到与训练程序中与 漏洞函数几乎相同的函数 相关的漏洞,VulPecker只能检测I型、II型和部分III型代码克隆(如语句的删除、插入和重排)造成的漏洞,这些系统无法检测到不是由代码克隆引起的漏洞,所以FNR很高。
相比之下,VulDeePecker具有更高的F1和更高的TPR,但它的FPR为22.9% (VUDDY为0%和VulPecker为1.9%)。作者猜测,BE-SEL-NVD数据集对应的22.9%的高FPR是由NVD的少量code gadget引起的,来自SARD的大量code gadget只产生了3.4%的FPR,这大约是来自NVD的训练code gadget数量的18倍。
虽然在BE-SEL-NVD子数据集上,VulDeePecker有高FPR和FNR,因为不应该被用作反对VulDeePecker的证据,因为在BE-SEL-SARD子数据集上,VulDeePecker的FPR为3.4%,FNR为5.1%,同时VUDDY和VulPecker根本无法检测该子数据集中的漏洞)。
此外,在整个BE-SEL数据集上,VulDeePecker的FPR为5.7%,FNR为7.0%,因为在实践中会使用所有可用的数据,所以这是更实际的情况。因此,可以说VulDeePecker大大优于两种最先进的基于代码相似性的漏洞检测系统。
然而,基于深度学习的漏洞检测在很大程度上依赖于数据量,这也是VulDeePecker的性能对数据量很敏感的原因,这是深度学习机制所固有的。
实践中使用
作者收集了3个软件产品的20个版本:Xen、Seamonkey和Libav,并使用VulDeePecker和其他漏洞检测系统来检测这些软件产品中的漏洞。
VulDeePecker检测到4个未在NVD中发布的漏洞,经过手工检查,这些漏洞漏洞得到确认,并且已经被产品供应商在后续版本中静默修补。相比之下,上述其他漏洞检测系统几乎都遗漏了这些漏洞,除了Flawfinder只检测到CVE-2015-4517对应的漏洞,而忽略了其他三个漏洞。
LIMITATIONS
虽然性能很好,但从整个过程中不难看出,VDP还是有一些限制的。
1、必须有源代码;
2、只能处理C/C++程序;
3、只能处理 library/API function calls相关漏洞,且当前只能处理buffer error和resource management error相关的 library/API function calls 产生的漏洞;
4、当前只用到了数据流分析,并没有用到控制流分析;
5、设计的将code gadget转为 symbolic representations、进而转为定长vector的算法是启发式的,暂无理论依据;
6、有无比BLSTM神经网络更适用的网络;
7、数据集只有buffer error和resource management error漏洞。
RELATED WORK
先前的相关工作主要包括漏洞探测和程序分析(以漏洞探测为目的)。漏洞探测主要包括基于pattern的和基于相似度的,VDP基于pattern。先前的将深度学习应用于程序分析工作可能是为了检测程序defect(算不上漏洞)及配置程序建模之类,但都需要解决将program以向量来表示的问题,方法有二:一是将程序拆解为token,并映射为向量(VulDeePecker选用这种);二是从程序中提取出抽象语法树并映射为向量。
CONCLUSION
关于深度学习在漏洞探测方面的应用,作者提出了几条指导性的原则,收集并制作了一个数据库,并实现了一个有效的漏洞挖掘系统,但未来还可以提升的方面还有很多。
自己的思考
斗胆评价一下,因为没有源码,所以难以得知具体细节。
对于作者列出的limitations,列一点自己的看法。
1、program转化为vector表示的过程缺少理论支撑,所以作者自己也说了是“启发式方法”,虽然效果很好,但是不像图像处理那样有理论支撑。
2、作者所说的专家提升模型表现的情况存疑,专家的作用主要是人工选择了 library/API function calls,并没有有效结合真正意义上的专业知识,参考VulDeePecker:基于深度学习的漏洞检测系统 - 知乎 (zhihu.com)可以结合专家的指导意见,比如可以通过在Bi-LSTM模型中加入attention机制予以解决。
3、若一段代码中存在多种漏洞,由于本文所用的BLSTM模型只能解决二分类问题(输出只有0、1),所以可能无法解决。
另外,D. Experimental results & implications中有这么一段:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5BCxXmRu-1683790197111)(null)]
大意是,VulDeePecker具有更高的F1和更高的TPR,但它的FPR为22.9% (VUDDY为0%和VulPecker为1.9%)。作者猜测,BE-SEL-NVD数据集对应的22.9%的高FPR是由NVD的少量code gadget引起的,来自SARD的大量code gadget只产生了3.4%的FPR,这大约是来自NVD的训练code gadget数量的18倍。但是,Moreover, the FPR of 5.7% corresponding to the entire BE-SEL dataset resides some where in between them. The high FNR of 16.9% can be explained similarly.,这句话有点奇怪,BE-SEL-NVD和BE-SEL-SARD都是BE-SEL的子集,那BE-SEL的code gadget的数目应该更多,按照作者所说,数目多了一些,FPR会下降,但为什么数目更多的BE-SEL的FPR反而比BE-SEL-SARD高?过拟合之类的?
同时D. Experimental results & implications这一章节还有一段话,

作者推测,library/API function calls的数目太多会导致vulnerability patterns提取的效果下降。这里看似和上面的“数目增多,性能上升”是矛盾的,但应该是对应的是下面这幅图,而不是具体的样本的数量。


















 1212
1212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









