







EMNLP 2020 | 开放域对话系统的属性一致性识别
论文:Profile Consistency Identification for Open-domain Dialogue Agents
作者:宋皓宇,王琰,张伟男,赵正宇,刘挺,刘晓江
论文链接:https://www.aclweb.org/anthology/2020.emnlp-main.539.pdf
资源地址:https://github.com/songhaoyu/KvPI
前言
提示:最近一次学位论文工作中所研读的论文,NLP有时间还是随机更一下吧。
也参考了网上一些资料(但忘了出处了,如果相关内容原创作者看到的话还请谅解哈嘿嘿。我再改正,谢谢!),仅作为个人学习记录。
一、论文研究目的
1、一致性问题是当前开放域对话面临的主要问题之一。已有的研究工作主要探索了如何将属性信息融合到对话回复中,但是很少有人研究如何理解、识别对话系统的回复与其预设属性之间的一致性关系。
2、构建了一个大规模的人工标注数据集KvPI(Key-value Profile consistency Identification)。该数据集包含了超过11万组的单轮对话及其键值对属性信息,并且对回复和属性信息之间的一致性关系进行了人工标注。
3、在此基础上,提出了一个键值对结构信息增强的BERT模型来识别回复的属性一致性。该模型的准确率相较于强基线模型获得了显著的提高。同时在两个下游任务上验证了属性一致性识别模型的效果。实验结果表明,属性一致性识别模型有助于提高开放域对话回复的一致性。
4、开放域对话生成任务旨在根据根据对话历史生成连贯、合理、有趣的对话回复。由于传统的对话生成往往缺乏一致的角色特征,近几年的工作开始在对话生成中明确引入纯文本的人设描述或者结构化的角色信息,希望提高对话回复的一致性。
5、虽然现有的角色化对话生成模型已经能够很好地融合给定的人设、角色信息,但是这些生成模型仍然无法有效地理解对话回复的一致性关系。
6、主要涉及对话生成与对话理解。
7、下图中,左边部分是对话系统预设的角色信息,该信息是以结构化键值对(key-value
pairs)的形式给出的;右边部分是一个对话片段,包括一句对话输入和若干对话回复。
在这些对话回复中,虽然R1和R2都包含了给定的地点词“北京”,但是这两个回复关于位置信息的含义却完全不同:
(1)R1表达了欢迎其他人来到自己所在地的含义,暗示了说话人现在正位于北京;
(2)而R2表达出了希望能够去一次北京的含义,因此可以推断出说话人不可能在北京。
对于机器而言,现阶段它们仍然难以理解这些关系。现有的角色化对话生成模型已经能够结合给定的人设、角色信息较好地生成类似R1 和R2的回复。

二、KvPI数据集
1、针对上述问题,这篇论文构建了一个大规模的中文人工标注数据集KvPI。
上表是KvPI数据集给出的一些例子。这里的一致性关系包括三类:
lable:一致(Entailed),矛盾(Contradicted)和无关(Irrelevant)。
其中,一致和矛盾都是针对说话者自身的属性而言的;如果包含属性信息但是非说话人的属性,则会被标注为无关。KvPI数据集的构建使得有效训练对话一致性识别模型成为可能。KvPI数据集以及模型、代码等资源已经全部开源在GitHub项目中。

2、该数据集的一条基本数据元组包含了键值对角色信息,单轮对话输入-回复对,领域信息,人工抽取的对话回复角色信息以及人工标注的角色一致性标签。
3、在角色信息中引入了性别、地点和星座三种常见的基本属性。同时,为了在有限的三种属性内获得尽可能丰富的表达方式,还从新浪微博收集了原始的待标注数据。
4、人工标注过程由一组全职的标注人员进行,标注过程持续了约4个月时间。在最终的KvPI数据集中,总共收集到了118540条数据。(Ps:大佬的团队就是不一般)
三、KvBERT模型
1、虽然BERT模型在自然语言理解任务上表现突出,然而,结构化的角色信息却几乎不会出现在普通BERT模型的预训练语料中。因此,如果使用BERT模型直接线性表示键值对结构信息会难以避免地导致信息损失。
2、结构化的角色信息有着固定的层次化依赖关系。比如:女性会定义性别的含义,北京会定义地点的含义,狮子座会定义星座的含义;而性别,地点,星座又会进一步定义角色信息的含义。
3、用于一致性识别的结构信息增强BERT模型 = BERT语义表示 + TreeLSTM结构表示
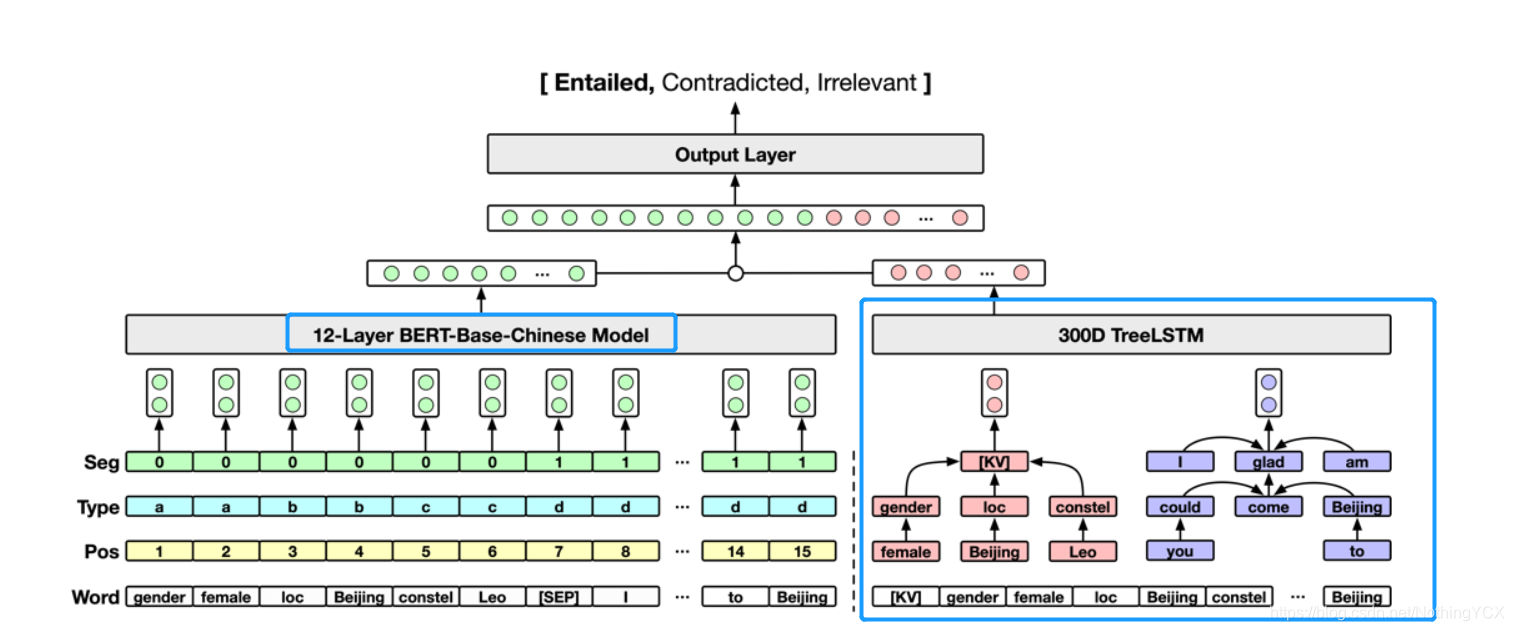
4、这里具体计算细节细节还是建议看论文吧,其实也很容易理解的,这里时间原因不再详述了。
5、为了有效建模这种结构信息,文章使用了treeLSTM来学习这种结构表示。最终,来自BERT模型的语义表示和来自TreeLSTM的结构表示会进行拼接并送入输出层,以预测最后的一致性关系。
6、在KvPI数据集以及其中的各个子属性上进行了大量的实验,使用准确率(accuracy)作为主要评价指标。同时,也计算了每一个一致性类别下的f1-score作为模型能力的细致化度量。基线模型方面,我们选取了从统计方法、循环神经网络方法到最新的预训练模型中具有代表性的若干模型。
四、下游任务验证
1、为了进一步验证一致性识别模型的效果,作者还在两个下游任务上进行了实验:
I.
对检索结果进行重排序,观察重排序前后对话回复的一致性是否提高;
II.
对生成结果进行一致性评估,并与人工评价进行对比,观察一致性识别模型的预测结果与人工评价的相似度。
2、最终的实验结果表明,一致性识别模型通过重排序能够有效降低矛盾回复的比例,并在可能的情况下提高一致回复的比例,从而提高了对话一致性;同时,即使是在生成的对话回复上,一致性识别模型仍然与人工评价的结果保持了较高的相似度。
五、补充:TreeLSTM的计算
1、基础的LSTM知识略过,普通的LSTM都是解决线性问题的。例如常用的应用之句子分类:每个词在随着时间序列的增加而不断地依次进入LSTM网络。这种方法有明显的局限性:当前词的输入需要依赖前一步词的输入。但是如果当前词要进行运算,而此时前一步词还没有进行计算怎么办?比如下面的基于依存树的情感分类。
2、依存树示例:
其中:
空白方框就LSTM的一个单元,文本序列为x1,x2,x4,x5,x6,x是输入的序列,y是每个x输入后经过LSTM一个时间片段的预测输出。
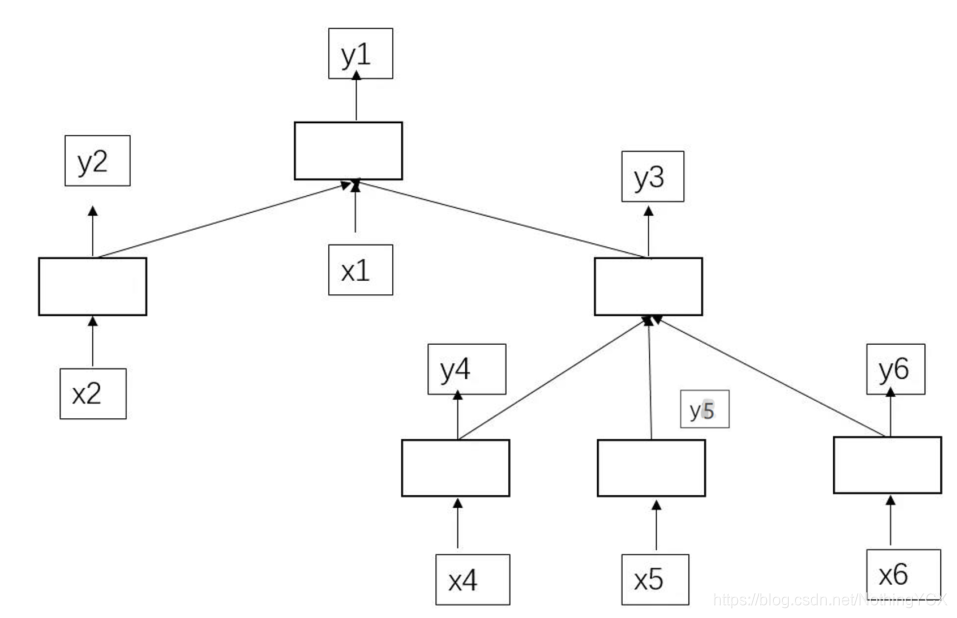
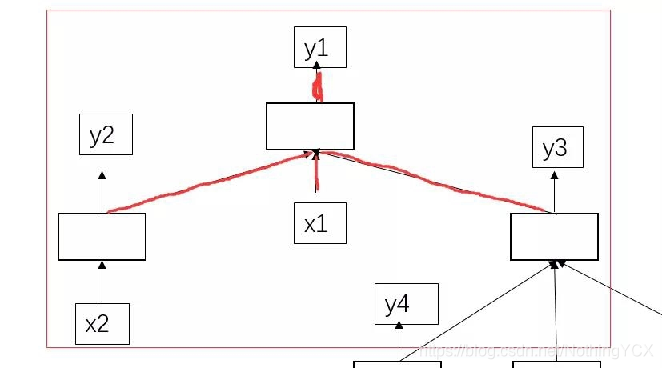
计算过程: 先找y2,y4,y5,y6的产生依赖于的x2,x4,x5,x6都已经存在,那么我们就能通过x2,x4,x5,x6分别过自己的隐层,得到对应的y2,y4,y5,y6;类似的,y2,y3也能相继产生;接着最终的y1也产生了。
具体计算: 如计算y1:y1的产生依靠于y2,x1,y3的输入。
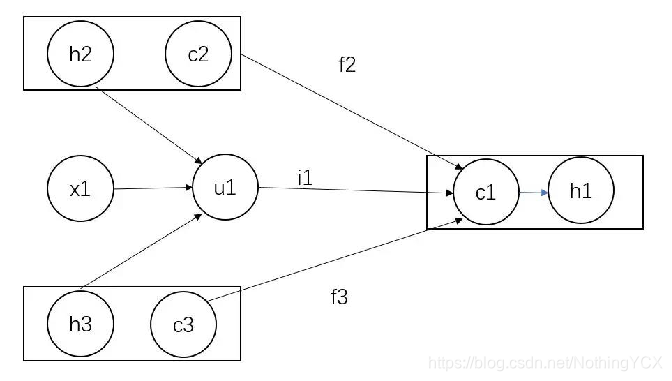
具体计算如下图:h为LSTM的隐层,c为LSTM的记忆单元
类似于LSTM的公式:
h2,h3求和再与x1进行如下计算:
得到u1;
c2,f2与c3,f3分别按位相乘再求和,再加上u1,i1按位相乘,最后两个和相加即可,得到c1。(i1怎么算,公式里有。)最后通过该公式:
得到隐层h1。
计算loss:
每个隐层y都要经过一个线性层,映射到具体的类别上,就是每个x对应一个类别,公式为:
最终的损失函数为:其实这个损失函数用的就是交叉熵,最后添加一个正则化。
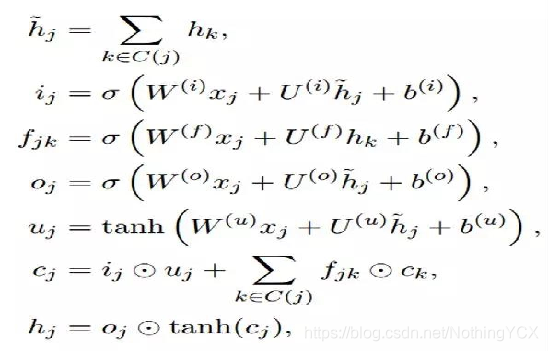
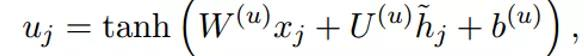
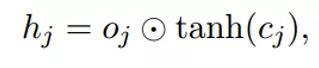
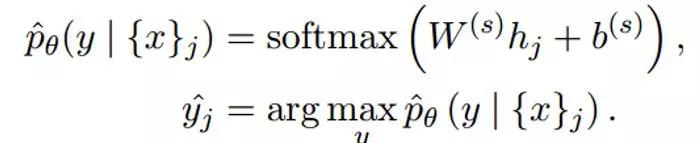
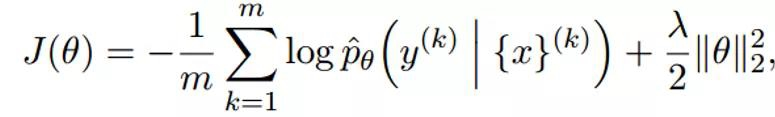
提示:这里我忘了之前是在哪里看的资料了,找不到原创地址了,作者看到勿怪哈,看到之后我再修正转载地址。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









