






一、线性模型

f(x) 是线性模型的基本形式,数据集中有多少个属性(维度)就应该有几个自变量。当然,也可以存在一个自变量的有种次方形式,并将不同次方的自变量写成x1,x2,x3等。机器学习是通过数据集中的数据得到每个自变量前的参数。

二、损失函数
机器学习需要得到目标函数中的未知参数,那么我们就需要定义一个目标,使得机器学习算法在学习中逼近它并得到相应的参数。
这样的目标叫做损失函数,不同的学习算法拥有不同的损失函数。对于线性模型,损失函数是预测值与实际值之差的平方和。

f (xi)是预测值(某一组参数条件下),yi是实际值。我们需要找到当损失函数最小时对应的参数。根据式(3.4),可见参数w和b是损失函数的自变量。
三、寻找损失函数的最小值
1.最小二乘法
根据损失函数,最小二乘法最终的计算公式如下。
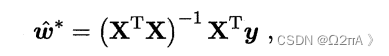
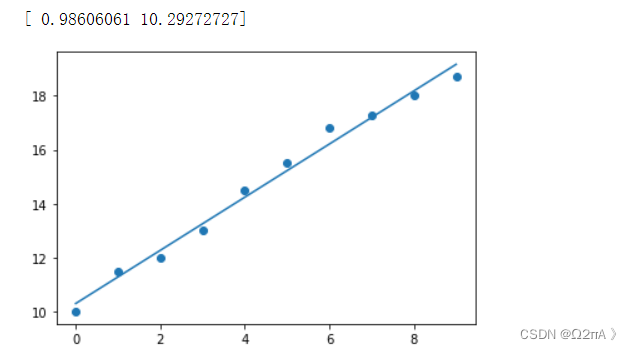
处理X数据集

import numpy as np
from matplotlib import pyplot as plt
x = np.array([[0,1],[1,1],[2,1],[3,1],[4,1],[5,1],[6,1],[7,1],[8,1],[9,1]])
y = np.array([10,11.5,12,13,14.5,15.5,16.8,17.3,18,18.7])
Xt = x.transpose()
Xs = np.matmul(Xt,x)
Xsi = np.linalg.inv(Xs)
Wstar = np.matmul(np.matmul(Xsi,Xt),y)
print(Wstar)
Xp = x[:,0]
Xhat = Wstar[0]*Xp + Wstar[1]
plt.scatter(Xp,y)
plt.plot(Xhat)
plt.show()
由于数据集只有一个维度,得到两个系数
也可以使用sklearn中的库
from sklearn.linear_model import LinearRegression
lm = LinearRegression()
lm.fit(x,y)
print(lm.coef_[0]) #系数
print(lm.intercept_) #截距
2.梯度下降法
我们有了损失函数就能获得关于损失函数的图像,我们的任务是找到这个图像中的最小值。不断改变参数,我们就能获得关于参数的损失函数的图像。梯度下降法,顾名思义需要计算每个维度方向的斜率(梯度)

由于损失函数是关于参数的函数,我们应该对每个参数求偏导。如果是只有一个参数的一维线性模型,假设他的损失函数如下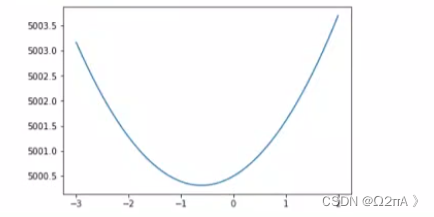
那么如何找到位于【-1,0】之间的最小点对应的横坐标就是我们需要解决的问题。

1.学习率
学习率代表每次迭代中横坐标移动的距离大小,太小的学习率会让迭代次数过多导致算法运行速度慢,过大的学习率可能导致找不到最小值的点,但也有可能跳出局部最小值而达到全局极小值,这样就可以得到更好的结果。选择合适的学习率或在程序运行过程中改变学习率就是调参的过程,目标是得到更好的拟合效果。
2.代码实现

如果是一维模型有两个参数θ0和θ1,那么损失函数必然包含两个自变量,我们需要计算两个方向中损失函数的偏导,如上图所示(J是损失函数,1/2m是自行添加的系数)。仍旧使用最小二乘法中的数据。
def diff1(x,y,theta0,theta1):
h = theta1*x + theta0
diff = (h - y)*x
partial = diff.sum() / x.shape[0]
return partial
这是计算θ1的偏导数。
def diff0(x,y,theta0,theta1):
h = theta1*x + theta0
diff = h - y
partial = diff.sum() / x.shape[0]
return partial
这是计算θ0的偏导数。
theta0 = 0
theta1 = 0
temp0 = 0
temp1 = 0
alpha = 0.01
for i in range(10000):
theta0 = theta0 - alpha * temp0
theta1 = theta1 - alpha * temp1
temp1 = diff1(x[:,0],y,theta0,theta1)
temp0 = diff0(x[:,0],y,theta0,theta1)
print(theta0)
print(theta1)
设学习率为0.01,迭代10000次,最终结果与最小二乘法几乎一样。如果只有100次迭代,结果会是两个2点几的数。若是迭代1000次,结果与最小二乘法差一点。改变学习率则会影响需要的迭代次数。
四、对数几率回归
对数几率回归也叫逻辑回归((logistic regression),它的作用是利用回归来解决二分类问题。
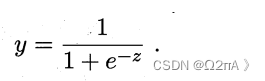
这是逻辑回归的函数。其中z是线性模型拟合的函数。也就是说,逻辑回归是线性回归套上了一个逻辑回归函数。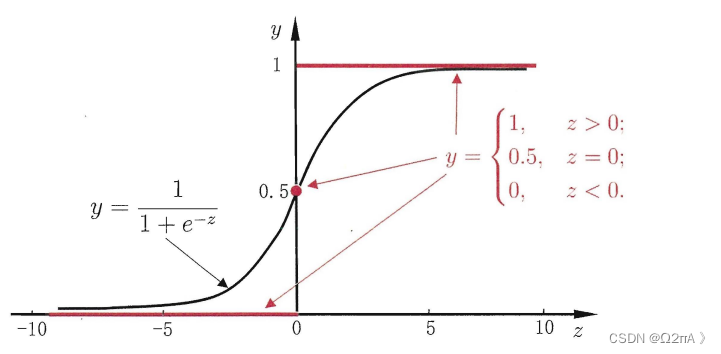
所谓的分类是根据数据先拟合一个线性模型,之后输入测试数据得到预测值,如果预测值大于某个值,如0.5,则为1类,小于则为0类,
这是简单的分类方法。实际上逻辑回归的输出是概率,表示的是某个对象是某一类的概率。
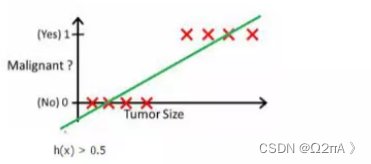
1、损失函数

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









