






注:以下代码在MYSQL中运行完成
最近学习了窗口函数,统一书写形式为:
函数名(某字段)over(partition by 分区字段 order by 排序字段)
一共有两个括号,括号里面可以填参数,也可以不填,依据函数的不同而决定。下面将介绍7种窗口函数。使用价值体现在,无视select后字段的限制,自己玩自己。
一、汇总函数
1. 函数内容:
| 5种 | 函数特点 |
|---|---|
| 1.sum(字段) over (partition by 分区的字段 order by 排序的字段 desc/asc) | 第一行到当前行字段累计汇总值 |
| 2.avg(字段) over (partition by 分区的字段 order by 排序的字段 desc/asc) | 第一行到当前行字段累计平均值 |
| 3.count(字段) over (partition by 分区的字段 order by 排序的字段 desc/asc) | 第一行到当前行的累计计数 |
| 4.Max(字段) over (partition by 分区的字段 order by 排序的字段 desc/asc) | 第一行到当前行的最大值 |
| 5.min(字段) over (partition by 分区的字段 order by 排序的字段 desc/asc) | 第一行到当前行的最小值 |
2.运算逻辑:
第一行到当前行
3.运算举例
下面以sum()over()函数举例子
新建一个表test1
create table test1(organization varchar(20), ranking int, number_ int);
insert into test1 values(1,1,1),(1,1,2),(2,1,2),(3,1,3),(1,2,5), (1,3,4),(2,3,6),(2,3,6),(3,3,5),(1,2,3), (2,2,5),(3,4,4),(2,2,5),(3,2,3);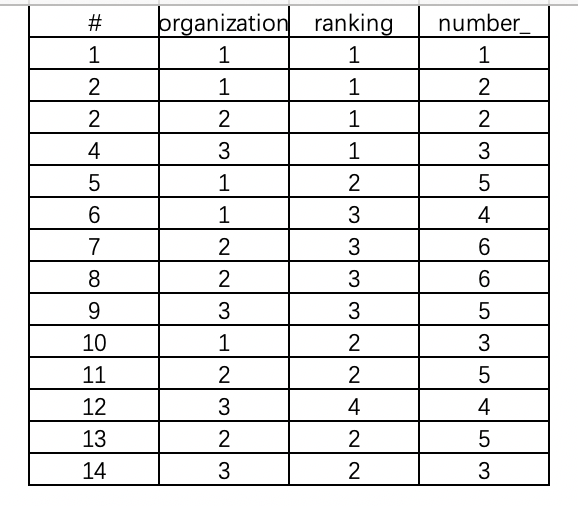
test1表中的数据
其中比较搞不清楚的是over后面两个参数的作用,通过实验,得出以下结论
| 函数 | 结果 | 特性 |
|---|---|---|
| 1.sum(字段)over() | 按照表整体,对字段进行汇总,表中每一行都填入最终汇总值 | 汇总 |
| 2.sum(字段)over(partition by 分区的字段) | 在分区字段内,对字段进行汇总,分区内的每一行都填入对应分区汇总的数值 | 汇总 |
| 3.sum(字段)over(order by 排序的字段 desc/asc) | 按照表整体,按照排序字段进行累计,排序字段如果出现相同值,则累计数值相同 | 累加 |
| 4.sum(字段)over(partition by 分区的字段 order by 排序的字段 desc/asc) | 在分区字段内,按照排序字段进行累计,排序字段如果出现相同值,则累计数值相同 | 累加 |
下面用实际的例子来演示一下
1.sum(字段)over()

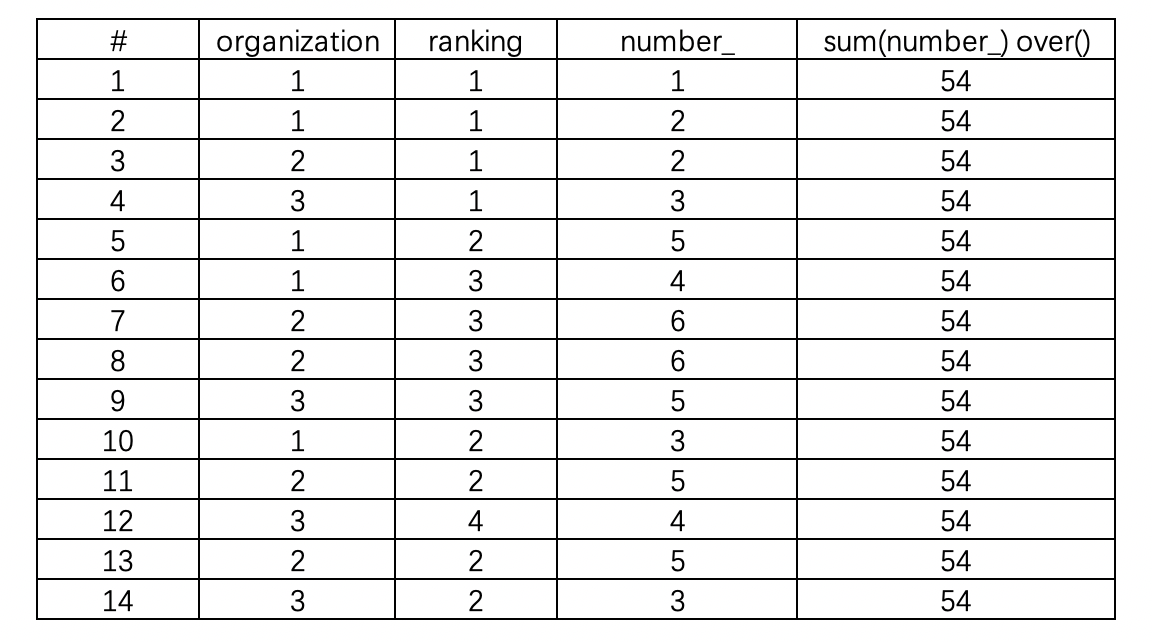
可以看到sum(number_) over()这一列,汇总了number_这一列,表中每一行都填入最终汇总值。
2.sum(字段)over(partition by 分区的字段)

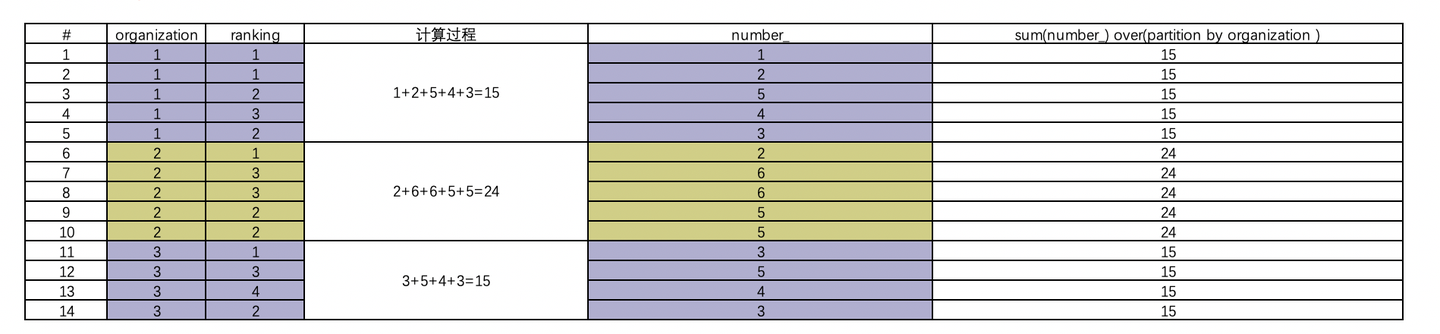
可以看到sum(number_) over(partition by organization)这一列,按照organization这一列将数据分区,并按照分区汇总了number_这一列,表中每一行都填入最终汇总值。
3.sum(字段)over(order by 排序的字段 desc/asc)

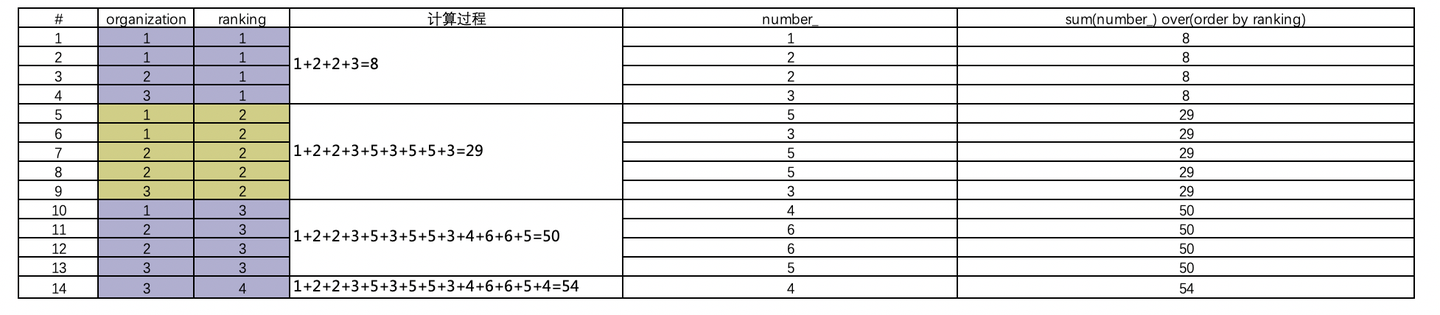
添加图片注释,不超过 140 字(可选)
4.sum(字段)over(partition by 分区的字段 order by 排序的字段 desc/asc)

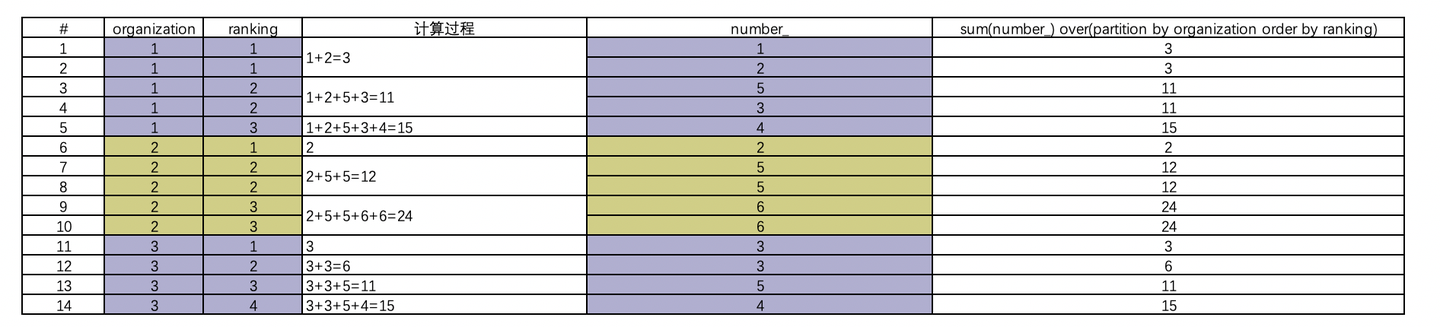
可以看到sum(number_) over(partition by organization order by ranking)这一列,按照organization这一列将数据分区,并按照ranking这一列排序,再去累计number_这一列,结果是每一行的值是第一行到当前行的累加值,如果按照排序的ranking字段有相同值,则累计数值相同。比如上图第1行与第2行,ranking的值都是1,最终值3,是二者累加值,并且最后一列第1行与第2行值相同。同理第3行与第4行;第7行与第8行;第9行与第10行。
总结:
不加order by,无论添加partition by与否,都是计算的汇总值,不是累计值。
二、排序函数
1.函数内容:
| 3种 | 函数特点 |
|---|---|
| row_number()over(partition by 分区的字段 order by 排序的字段 desc/asc) | 排名连续 |
| rank()over(partition by 分区的字段 order by 排序的字段 desc/asc) | 排名不连续,值相同时采用并列排名 |
| dense_rank()over(partition by 分区的字段 order by 排序的字段 desc/asc) | 排名连续,值相同时采用并列排名 |
2.运算逻辑:
第一行到最后一行
3.运算举例
新建表st_score
create table st_score(st_id int,name varchar(100),gender varchar(100),score int,lesson varchar(100)); insert into st_score values(20200001,'小明','男',85,'Math'), (20200001,'小明','男',90,'Chinese'), (20200001,'小明','男',89,'English'), (20200002,'小宁','男',92,'Math'), (20200002,'小宁','男',81,'Chinese'), (20200002,'小宁','男',83,'English'), (20200008,'杰伦','男',88,'Math'), (20200008,'杰伦','男',88,'Chinese'), (20200008,'杰伦','男',88,'English'), (20200009,'小娜','女',83,'Math'), (20200009,'小娜','女',87,'Chinese'), (20200009,'小娜','女',78,'English'), (20200009,'小娜','女',82,'Math'), (20200009,'小娜','男',85,'dama'), (20200008,'杰伦','男',87,'Math');现在按照每个学生来进行三科成绩的排名,看一下每个学生,分别是哪一门成绩最好,使用排序函数
SELECT * ,row_number()over(PARTITION by name order by score desc) as rn_rownum ,rank()over(PARTITION by name order by score desc) as rn_rank ,dense_rank()over(PARTITION by name order by score desc) as rn_dense FROM st_score ss ;结果如下:
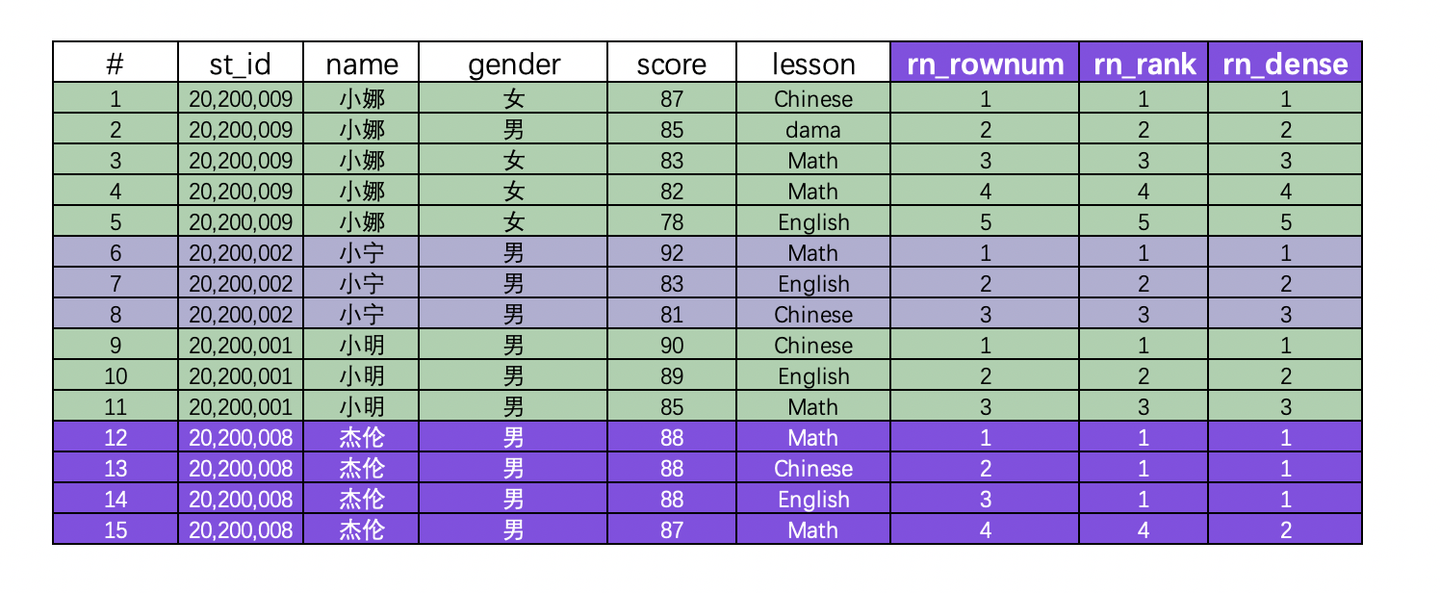
从结果可以看出,当成绩没有相同值时,三种排序函数的结果一致,比如:小娜,小宁,小明。但是当成绩出现重复值时,结果发生了变化,比如:杰伦同学有三个88的成绩,在row_number中,无视重复值,按照顺序直接排列下来;rank和dense_rank是重复值都按照相同的排名排序,但是rank的排序是断裂的,1,1,1,4,dense_rank排名是连续的1,1,1,2。
三、分布函数
四、前后函数
1.函数内容
| 2种 | 函数特点 |
|---|---|
| lead(字段,N ) over (partition by 分区的字段 order by 排序的字段 desc/asc) | 向前,求当前行的前第N行数据 |
| lag(字段,N ) over (partition by 分区的字段 order by 排序的字段 desc/asc) | 向后,求当前行的后第N行数据 |
2.运算逻辑
第一行到最后一行
3.运算逻辑
以lag函数举例子,lead函数逻辑同理。
原始数据
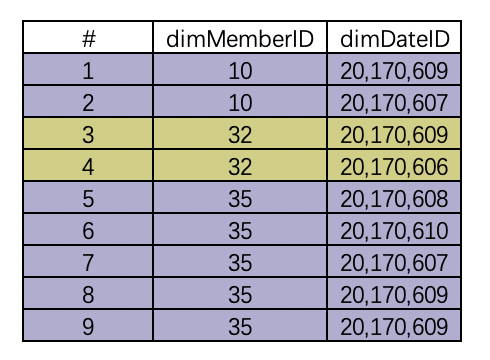
(1)lag(字段 ,N) over ( )
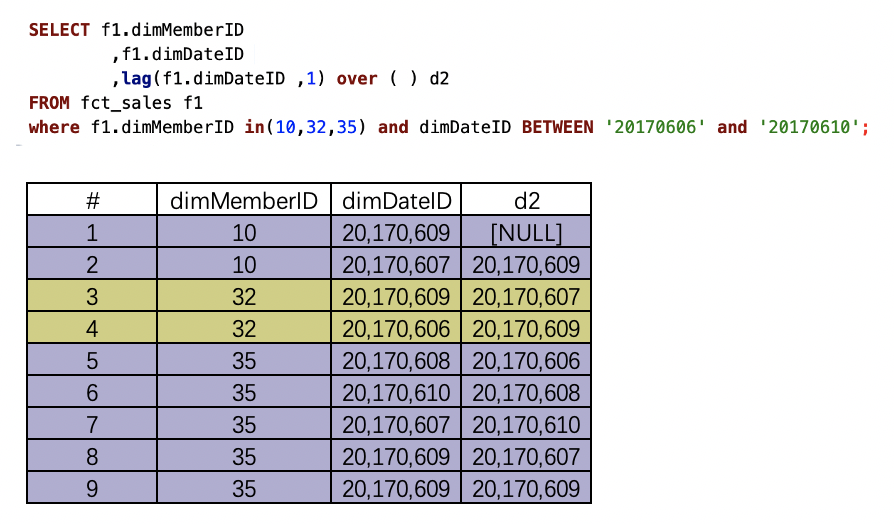
over()内没有指定分区字段和排序字段,按照全部数据,原始排序。结果求的是每一行数据的dimDateID字段的后一行数据。
(2)lag(字段 ,N) over (partition by分区字段)

over()内指定会员号dimMemberID分区内,排序不变。结果求的是不同会员号内,每一行数据的dimDateID字段的后一行数据,可以发现,与没有指定partition by分区字段相比,指定分区后,会员号32、35后一行数据,为null值。
(3)lag(字段 ,N) over (order by 排序字段)
全部数据排序
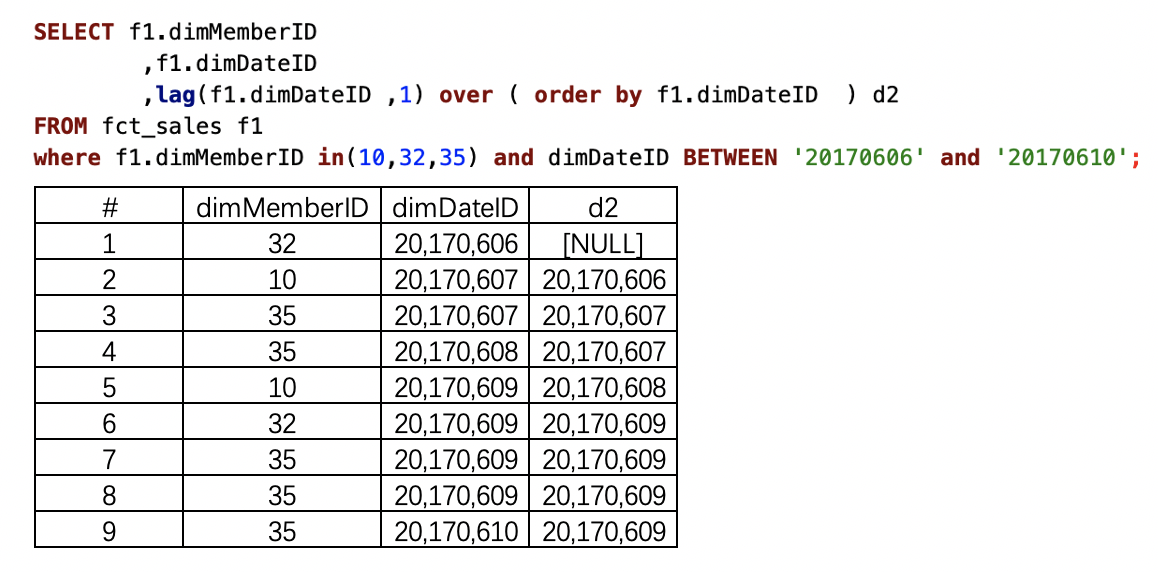
over()内全部数据,排序按照dimDateID字段生序。结果求的是每一行数据的dimDateID字段的后一行数据。
(4)lag(字段 ,N) over (partition by分区字段 order by 排序字段 asc/desc)
分区内排序
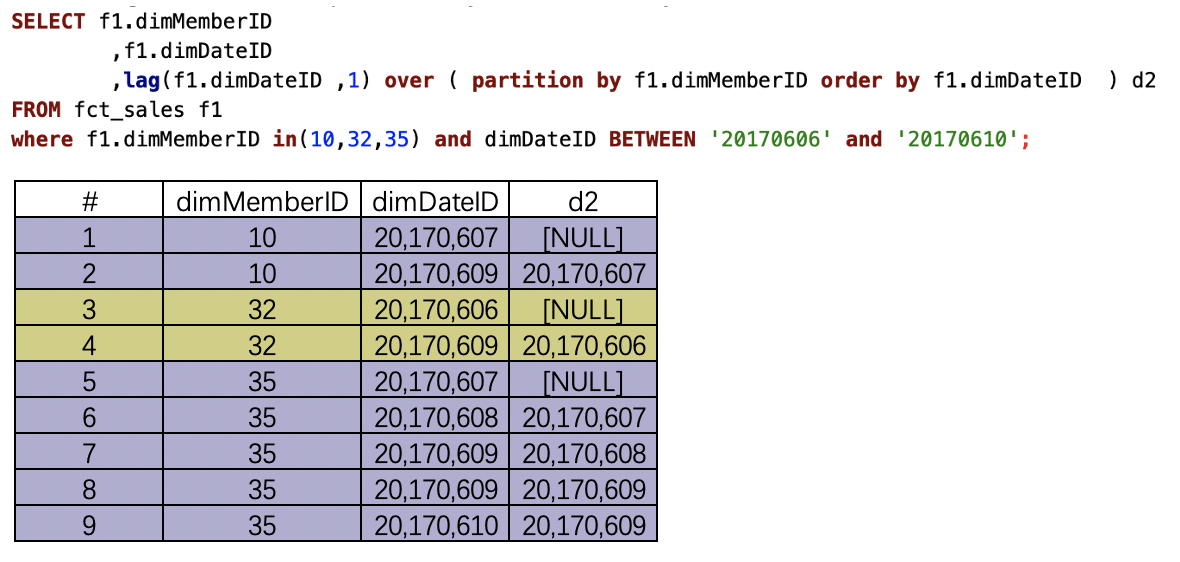
默认生序排列asc
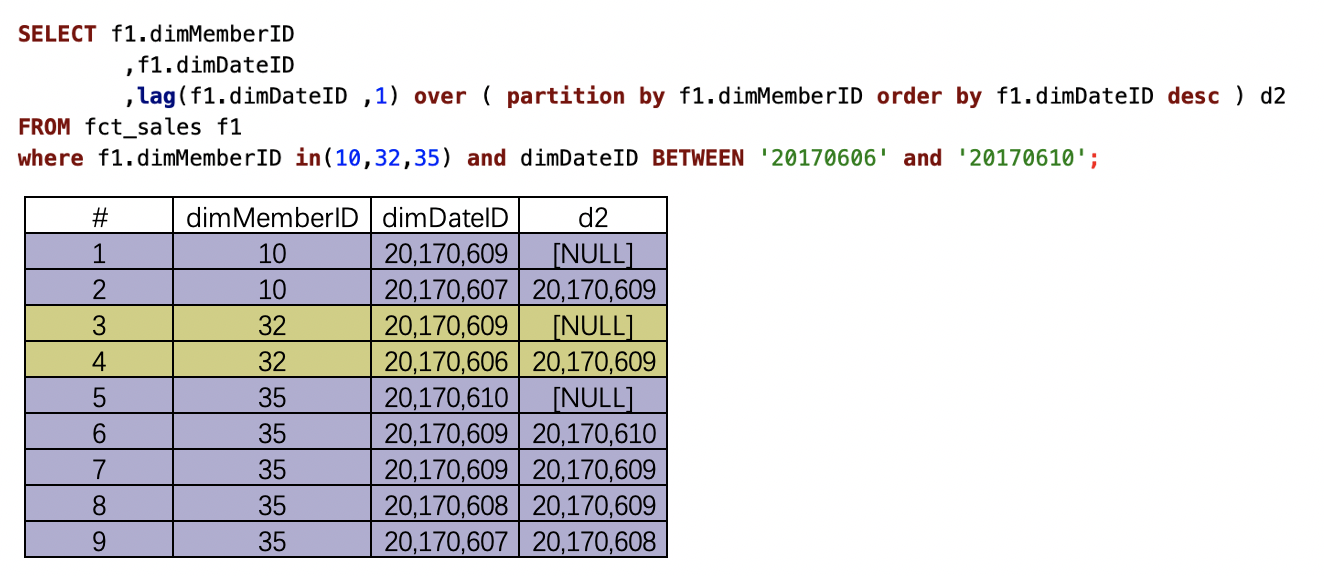
降序排列desc
over()内指定会员号dimMemberID分区内,按照dimDateID在分区内排序。结果求的是不同会员号内,按照指定字段排序后,每一行数据的dimDateID字段的后一行数据。
五、头尾函数
1.函数内容
2.运算逻辑
3.运算逻辑
六、ntile
1.函数内容
2.运算逻辑
3.运算逻辑
七、nthnth_value
1.函数内容
2.运算逻辑
3.运算逻辑


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









