







 本文介绍了MHA的工作原理,包括其角色和常用工具程序,并详细阐述了如何实现MySQL主从节点的自动在线切换步骤,以及切换后的注意事项。通过MHA,可以确保在主节点故障时无缝切换到从节点,保障数据库服务的高可用性。
本文介绍了MHA的工作原理,包括其角色和常用工具程序,并详细阐述了如何实现MySQL主从节点的自动在线切换步骤,以及切换后的注意事项。通过MHA,可以确保在主节点故障时无缝切换到从节点,保障数据库服务的高可用性。
一:MHA工作原理;
1
、保存宕机的
master
的二进制日志事件;
2
、找最新更新的
slave
;
3
、应用差异的中继日志到其他
slave
;
4
、应用从
master
保存二进制日志事件;
5
、提升一个
slave
为新的
master
;
6
、使用其他
slave指向
新的
master
进行复制;
MHA提供按需在线自动切换master/slave节点;能够在30秒内实现故障切换, 并能在故障切换中, 最大可能的保证数据一致性。
架构图如下所示:
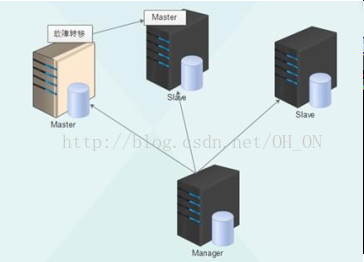
MHA的角色:
manager管理节点:
通常单独
部署在一台独立机器上管理多个
master/slave
集群
(
组
)
, 每个
master/slave
集群称作一个
application
, 用来管理统筹整个集群
;
node数据节点:
运行在每台
mysql
服务器上(
master|slave|manager
),接收
manager
发的指令,在每个节点上执行一系列操作;
常见工具程序:
manager
节点:
masterha_check_ssh
:MHA
依赖的
ssh
环境监测工具
masterha_check_repl
: MYSQL
复制环境检测工具;
masterga_manager
: MHA
服务主程序
masterha_check_status
: MHA
运行状态探测工具;
masterha_master_monitor
:MYSQL master
节点可用性监测工具;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3742
3742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









