






敬上,在接下来的篇幅中,我会和大家共享我在今日头条和新浪关于软件文章搜集方面的实战经验,内容包括但不限于操作方法和数据处理技术。
1.选择合适的采集工具
在收集新浪今日头条软件文章时,选择适当的收集工具至关重要哦!在此,我向您推荐选用专业的网络爬虫工具——比如Python的 BeautifulSoup 库或者 Scrapy框架。它们能助您迅速、高效地检索到所需信息。
2.确定采集目标
在采集前需明确所需信息,比如:每篇文章的标题、作者及发表日期等。确立目标后,您可依需求编写提取相关信息的代码。

3.设置合理的请求频率
在避免视听服务器压力巨大的情况下,我们需设定符合实际需求的数据收集请求次数。可通过设置相应请求间隔实现访问频率的调节,使得我们在操作过程中不会被站点封停或影响到其他用户的权益。
4.处理反爬机制
为避免被反爬限制识破和限制访问,建议大家采取以下策略进行应对:借助代理IP或设定随机 User-Agent头来降低被侦测的风险;同时,虚拟登录也是绕过验证码等安全认证措施的好方法哦。
5.数据清洗和处理
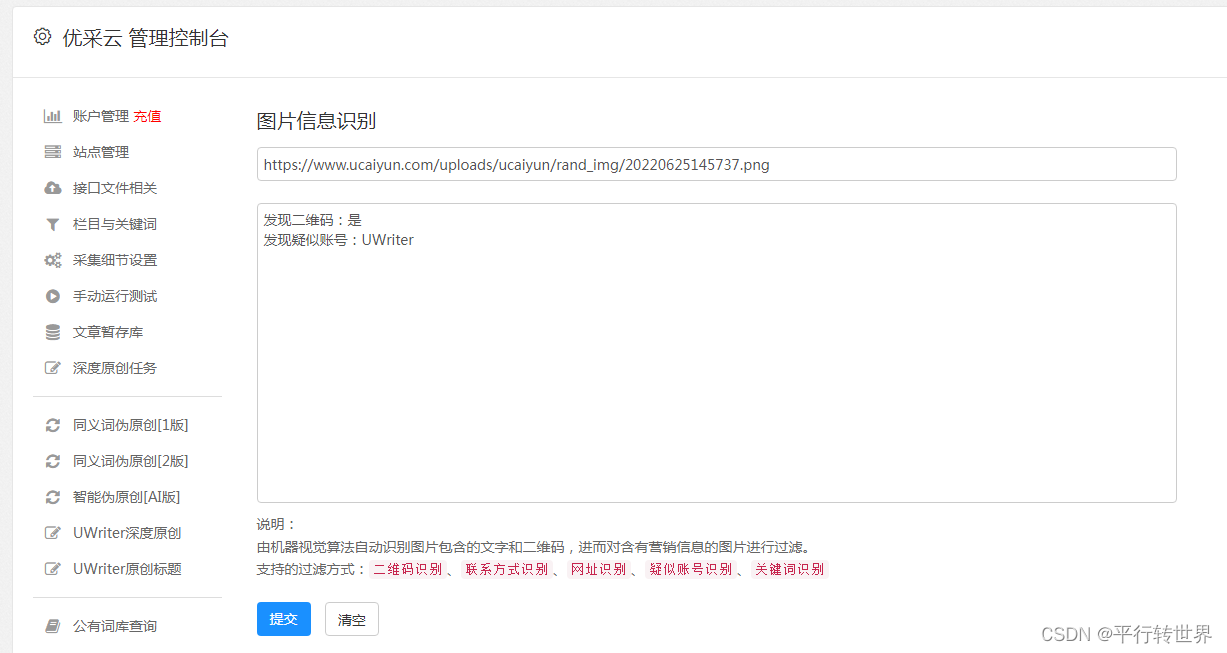
在完成数据采集后,为了能有效地进行分析和使用,常需对其进行清洗和处理。我们可借助正则表达式或字符串处理函数进行数据清洗与提取;同样,Python所配备的两个强大工具——pandas和numpy——也可以大大提升数据处理和分析的效率。
6.数据存储与备份
在收集今日头条与新浪文章的过程中,合理使用数据库来保存浩如烟海的信息是至关紧要的步骤。诸如MySQL、MongoDB等多元化的数据库都能胜任此任务。同样重要的是,为了应对突发情况导致信息丢失,我们应定期进行全面的数据备份工作。
7.数据分析与可视化
请放心,我们将您收集的宝贵数据进行深度剖析,赋予其更具洞察力的意义。Python的数据分析库,比如matplotlib与seaborn,让我们能从更深层次读取数据内在关系及其发展趋势。
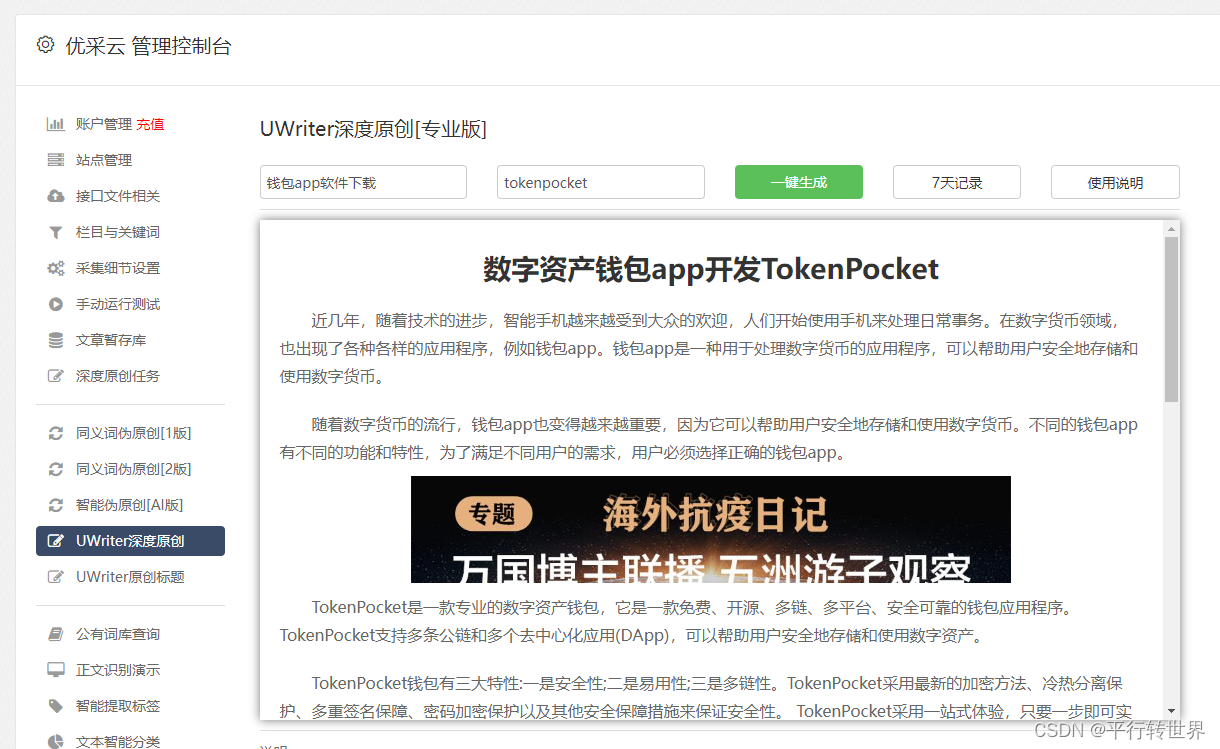
8.定期更新采集规则
为了应对网站架构可能的不断变更,推荐您定期更新抓取策略以适配网站的变动。请适时调校代码中如XPath或者CSS选择器之类的采集规定,并进行必要的测试与验证,确保其准确性。
9.遵守法律和道德规范
在进行数据采集过程中,敬请遵循相关法律法规及道德规范,不做违法、侵权或有损他人利益之事。同时,也需尊重并参照各大网站的使用规则,避免增加其负担。
愿这些宝贵的九个经验分享对您有所助益,祝您在采集今日头条与新浪新闻软件文章的过程中顺利前行,成就辉煌事业!














 79万+
79万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









