 Glusterfs卷类型与常用命令详解
Glusterfs卷类型与常用命令详解







 本文详细介绍了Glusterfs分布式文件系统的volume类型,如分布式、复制、分散卷,以及其创建、操作和常用命令,包括peer管理、volume配额、快照和分层管理等,展示了其高可用性和灵活性。
本文详细介绍了Glusterfs分布式文件系统的volume类型,如分布式、复制、分散卷,以及其创建、操作和常用命令,包括peer管理、volume配额、快照和分层管理等,展示了其高可用性和灵活性。
Glusterfs 卷及常用命令总结
一、概述
开源的分布式文件系统
传统的分布式文件系统–> 有中心架构(元数据服务器),元数据服务器出现故障,整个存储系统崩溃
Glusterfs分布式文件系统–> 无中心架构(无元数据服务器),数据横向扩展能力强,具备较高的可靠性及存储效率。
1.1特点
Glusterfs采用集群式NAS存储系统:
传统的NAS系统–>独立的存储设备来提供文件共享服务,客户端通过网络连接到该存储设备来访问文件
Glusterfs–>每个存储服务器都可以安装 GlusterFS,并作为一个 Brick 加入到 GlusterFS 集群中,这些存储服务器之间通过网络互联,形成一个分布式的存储系统。通过将数据在不同的存储节点之间进行分布和复制,实现数据的冗余和负载均衡。
基于标准协议
客户端可以通过各种支持的文件访问协议(如NFS、CIFS、原生 GlusterFS 协议等)连接到 GlusterFS 集群,并像访问本地文件系统一样访问和操作文件
全局统一命名空间
通过将所有存储节点中的文件和目录合并成一个单一的文件系统视图,为客户端提供了一种透明的访问方式。在全局命名空间下,客户端可以像访问本地文件系统一样访问存储集群中的文件和目录,而不必关心它们实际上存储在哪个存储节点上。
弹性卷管理,高可用
根据业务需求实时地调整存储容量和性能,从而更好地满足不同的应用场景和工作负载,当存储节点发生故障时,数据可以自动转移到其他节点上,避免数据丢失。
1.2 术语解释
brick:存储节点上的数据单元,GlusterFS 存储卷的基本组成部分。
Volume:由一个或多个存储节点上的 brick 组成,提供了一个统一的命名空间,使客户端可以通过挂载 Volume 来访问其中的文件和目录。支持多种类型的 Volume,包括分布式卷、复制卷、条带化卷等
Replica:副本是存储卷中数据的复制品。GlusterFS 支持在不同的存储节点上创建文件的副本,以提供数据冗余和高可用性。
Stripe:条带是将文件数据分成固定大小块并分布在多个存储节点上的方式。条带化可以提高读写性能。
Vfs: 内核空间对用户空间提供的访问磁盘的接口
二、volume总结
创建卷
gluster volume create … server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4
GlusterFS 创建卷(Volume)时,需要确保所有参与卷的存储节点已经加入到同一个 GlusterFS 存储集群中,创建卷之前,需要先创建 GlusterFS 存储集群,并将各个存储节点添加到集群中
2.1 分布式卷
GlusterFS的默认卷;以文件为单位根据HASH算法散列到不同的Brick,其实只是扩大了磁盘空间,如果有一块磁盘损坏,数据也将丢失
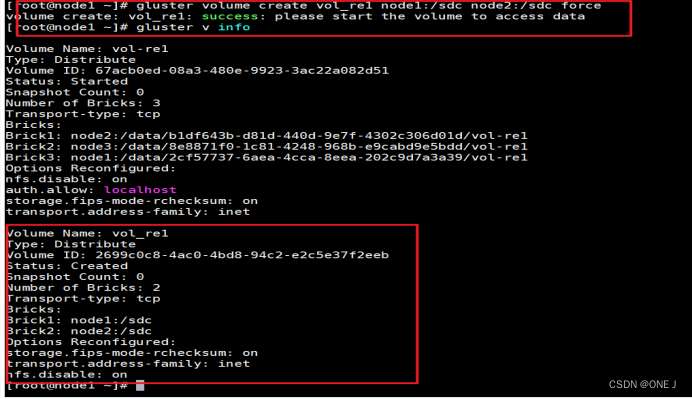
Volume Name: vol_re1 - 卷的名称。
Type: Distribute - 卷的类型, “Distribute”,表示该卷采用分布式模式。
Volume ID: 2699c0c8-4ac0-4bd8-94c2-e2c5e37f2eeb - 卷的唯一标识符,用于在 GlusterFS 中标识该卷。
Status: Created - 卷的状态
Snapshot Count: 0 - 快照的数量
Number of Bricks: 2 - 卷包含的存储节点数量
Transport-type: tcp - 传输类型,本例中为 “tcp”,表示使用 TCP/IP 进行通信。
Bricks: 存储节点和相应目录的列表。
Brick1: node1:/sdc - 存储节点1的名称和目录路径,本例中为 “node1:/sdc”。
Brick2: node2:/sdc - 存储节点2的名称和目录路径,本例中为 “node2:/sdc”。
Options Reconfigured: 已重新配置的选项列表。
storage.fips-mode-rchecksum: on - 已重新配置的选项,本例中为 “storage.fips-mode-rchecksum”,表示该选项已设置为 “on”。
transport.address-family: inet - 已重新配置的选项
nfs.disable: on - 已重新配置的选项 已设置为 “on”。
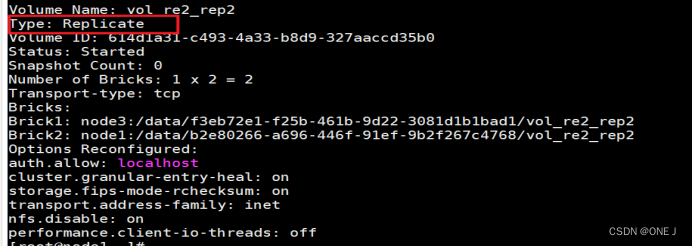
2.2 复制(副本)卷
文件同步到多个Brick上,使其具备多个文件副本 复制卷具备冗余性,即使一个节点损坏,也不影响数据的正常使用。
2.3 分布式复制(分布式副本)卷
文件同步到多个Brick上,使其具备多个文件副本,复制卷具备冗余性,即使一个节点损坏,也不影响数据的正常使用。但因为要保存副本,所以磁盘利用率较低。
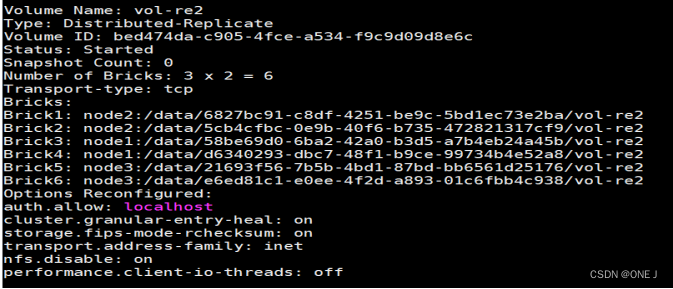
Number of Bricks: 3x2=6
数字 “3” 是分布因子(Distribute Factor),指有副本数为3
字母 “x” 表示乘号,将分布因子和复制因子分隔开。
数字 “2” 是复制因子(Replica Factor),表示每个数据块被复制到两个不同的存储节点上。
2.4 分散卷(纠删卷)
文件编码条带化后分散存储在卷的多个块中,提高磁盘利用率
分散卷的冗余值表示允许多少块失效而不中断对卷的读写操作
冗余值(redundancy)必须大于0,总块数大于2倍的冗余值---->分散卷至少3个块组成
可用存储空间计算公式:
=*(bricks-Redundancy)
创建命令:
#gluster volume create volume_name [disperse[<count>]] [disperse-data<count>] [redundancy<count>] [tcp|rdma] [new_brick]
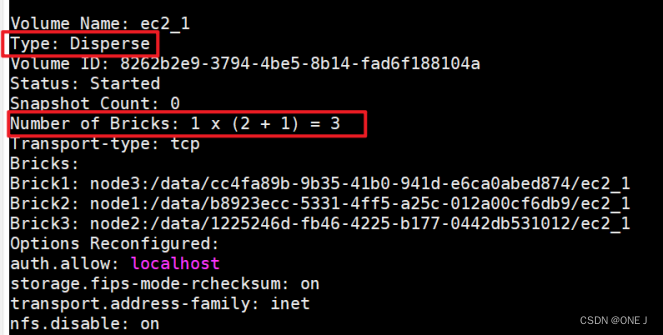
Disperse:纠删码的数据块数量
disperse-data:实际纠删码数量
Redundancy:冗余数据块数量
2.5分布式分散卷(分布式纠删卷)
与分布式复制卷的区别在于分布式分散卷通过分散卷将数据存储在数据块中
#gluster volume create volume_name [disperse[<count>]] [disperse-data<count>] [redundancy<count>] [tcp|rdma] [new_brick]
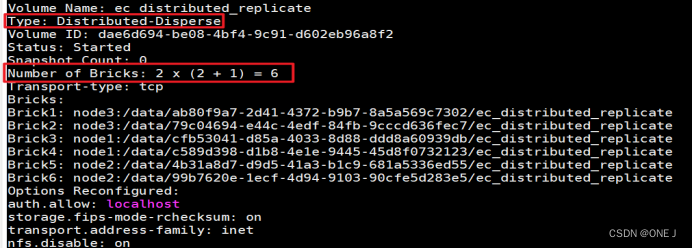
数字 “2” 表示卷的副本数(Replica Count),也就是每个数据片段在集群中的复制份数。
数字 “2 + 1” 表示卷的分散编码配置。其中,数字 “2” 表示数据片段的数量,而数字 “1” 表示冗余数据片段的数量。
2.6 分层卷
在存储设备之间创建多个层级,并使用这些层级来管理数据
层级管理,包括热数据的快速访问和冷数据的低成本存储
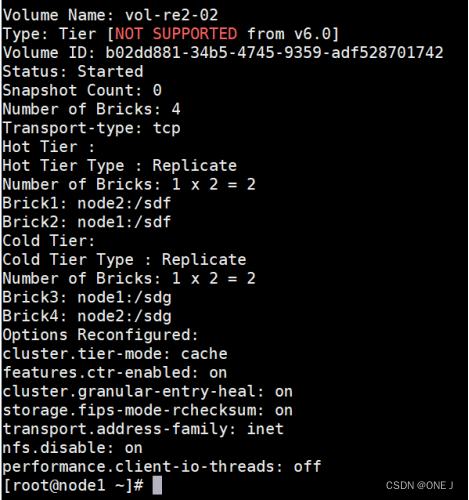
热层:node1:/sdf node2:/sdf
冷层:node2:/sdg node2:/sdg
三、volume其他操作
停止卷: gluster volume stop <VOLNAME>

启动卷:gluster volume start <VOLNAME>

删除卷:gluster volume delete <VOLNAME>
查看所有卷:gluster volume list
查看单个卷状态:gluster volume info <VOLNAME>

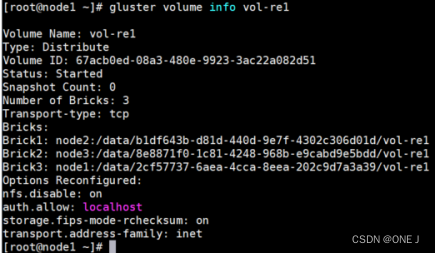
扩展卷:
gluster volume add-brick <VOLNAME> replica <N> <HOSTN>:<BRICKN>
移除卷上的brick:gluster volume remove-brick <VOLNAME> start <HOST>:<BRICK>
四、gluster常用命令
4.1 peer help
显示有关对等节点命令的帮助信息。
gluster peer detach { <主机名> | <IP地址> } [force]
此命令用于断开指定主机名或IP地址的对等节点的连接。如果提供了可选的 force 关键字,则会强制断开连接。
#peer detach peer1 force
gluster peer probe { <主机名> | <IP地址> }
此命令用于探测或连接到指定主机名或IP地址的对等节点。它建立与指定对等节点的连接,以启用通信和数据交换。
#peer probe peer2
glsuter peer status
运行此命令将列出所有已连接对等节点的状态信息
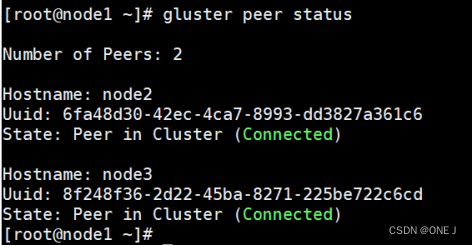
Uuid:节点唯一标识符
gluster pool list
列出池中的所有节点
4.2 volume help
显示有关卷命令的帮助信息。–>见二、volume总结
4.3 volume quota help
显示有关卷配额命令的帮助信息。
gluster volume quota\ enable
启用或禁用指定卷的配额功能

gluster volume inode-quota <VOLNAME> enable
启用或禁用指定卷的inode配额
Quota是指对文件系统中的存储空间设置限制。
inode quota 文件和目录的数量
#gluster volume quota vol-re2 alert-time 60
gluster volume quota <VOLNAME> limit-usage <path> <size>
设置指定卷路径中允许的最大条目数。
#gluster volume quota vol-re2 limit-objects /cifs1-1 100

gluster volume quota vol-re2 list
查看卷配额信息
#gluster volume quota vol-re2 list

4.4 volume tier help
gluster volume tier <VOLNAME> attach [<replica COUNT>] <NEW-BRICK>… [force]
将热层附加到指定的 <VOLNAME> 卷上,<replica COUNT> 来设置热层的副本数<NEW-BRICK> 参数来指定要添加到热层的新存储单元(brick)
#gluster volume tier vol-re2-02 attach replica 2 node1:/sdf node2:/sdf force

glsuter volume tier <VOLNAME> detach <start|stop|status|commit|[force]> - 从指定的 <VOLNAME> 卷中分离热层
执行分离热层之前,可能需要确认数据已经按照预期转移到冷层,以避免数据丢失,因为分离热层将从热层中删除所有数据。
使用 start 参数,可以分离热层并启动相应的冷层服务。

使用 status 参数,可以获取关于热层分离的状态信息。
文件迁移操作完成后,存储卷将处于无分层状态

使用 stop 参数,可以分离热层并停止冷层服务。
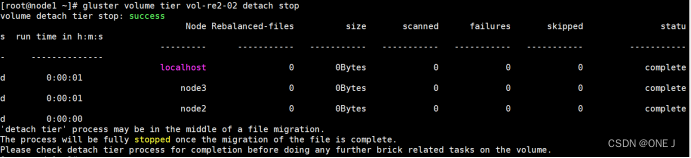
使用 commit 参数,可以提交热层分离的更改。

4.6 snapshot help
创建快照 snapshot create <snapname> <volname> [no-timestamp] [description <description>] [force]
#gluster snapshot create my_snap1 vol-lvm01 no-timestamp
查看快照列表 gluster snapshot list [volname]
#gluster snapshot list vol-lvm01

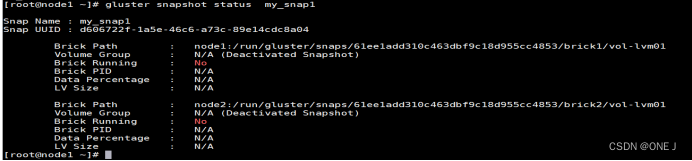
查看快照状态:gluster snapshot status [(snapname | volume <volname>)]
#gluster snapshot status my_snap1
删除快照:gluster snapshot delete (all | snapname | volume <volname>)
停用指定名称的快照卷:gluster snapshot deactivate <snapname>
激活指定名称的快照卷: gluster snapshot activate <snapname> [force]
快照回滚:gluster snapshot restore <snapname>
例:激活快照,然后在文件系统touch 100个txt文件

停止文件系统,回滚gluster snapshot restore my_snap1
开启文件系统,查看结果

4.6 global help
detail - 显示更详细的信息
#gluster volume status vol-re1 detail
long - 以长格式显示信息
bricks - 显示有关存储服务器节点的信息
clients - 显示连接到卷组的客户端信息
#gluster volume status vol-re2 clients
启用或禁用 NFS-Ganesha :gluster nfs-ganesha {enable|disable}

















 21
21

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









