






目录
第 1 章 Zookeeper 入门
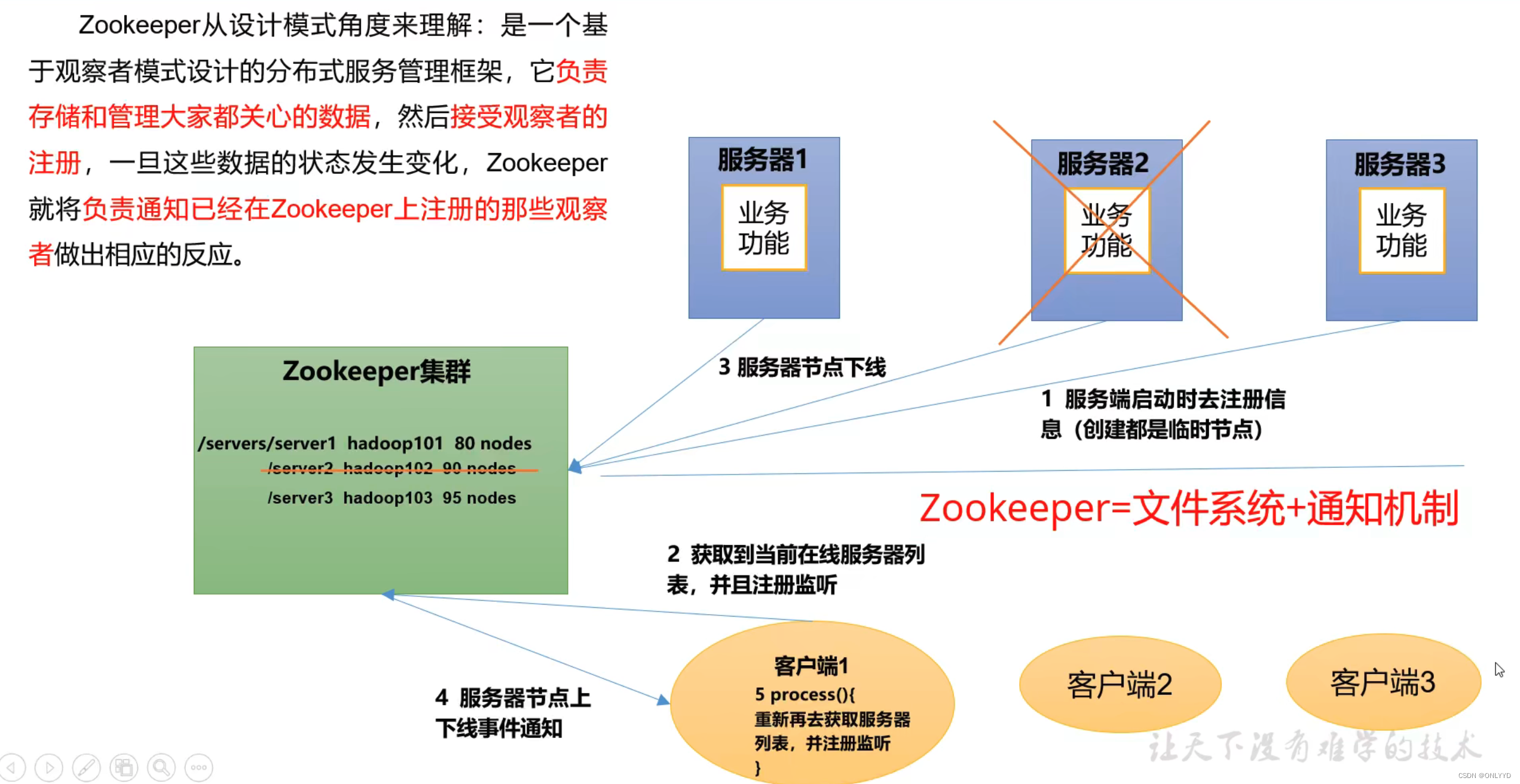
1.1 概述
1.2特点
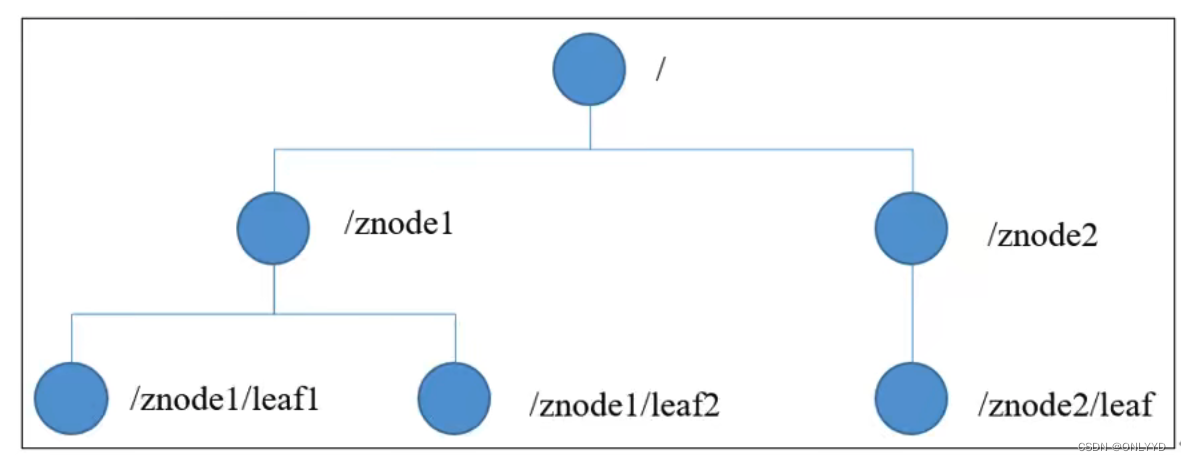
1.3 数据结构
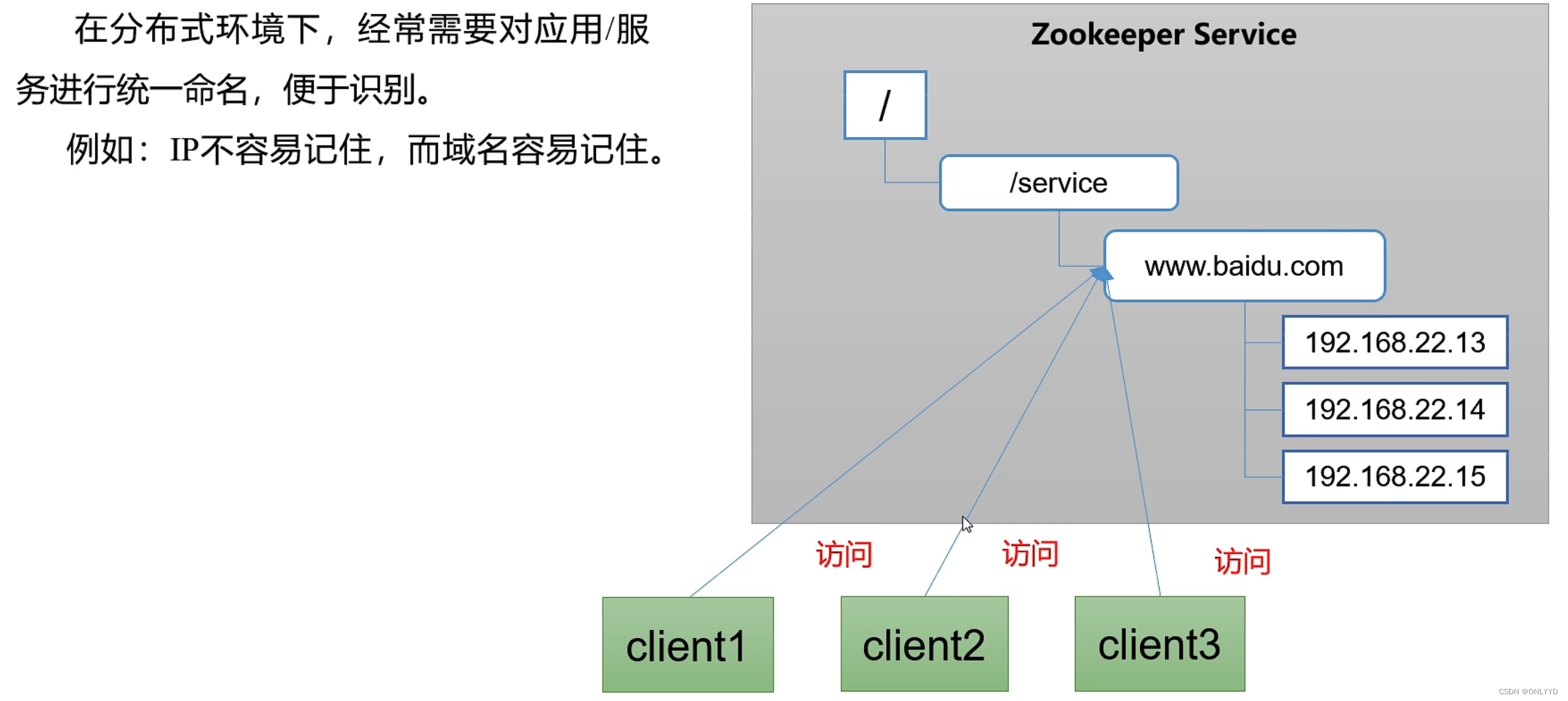
1.4 应用场景
Version:0.9 StartHTML:0000000105 EndHTML:0000002869 StartFragment:0000000141 EndFragment:0000002829
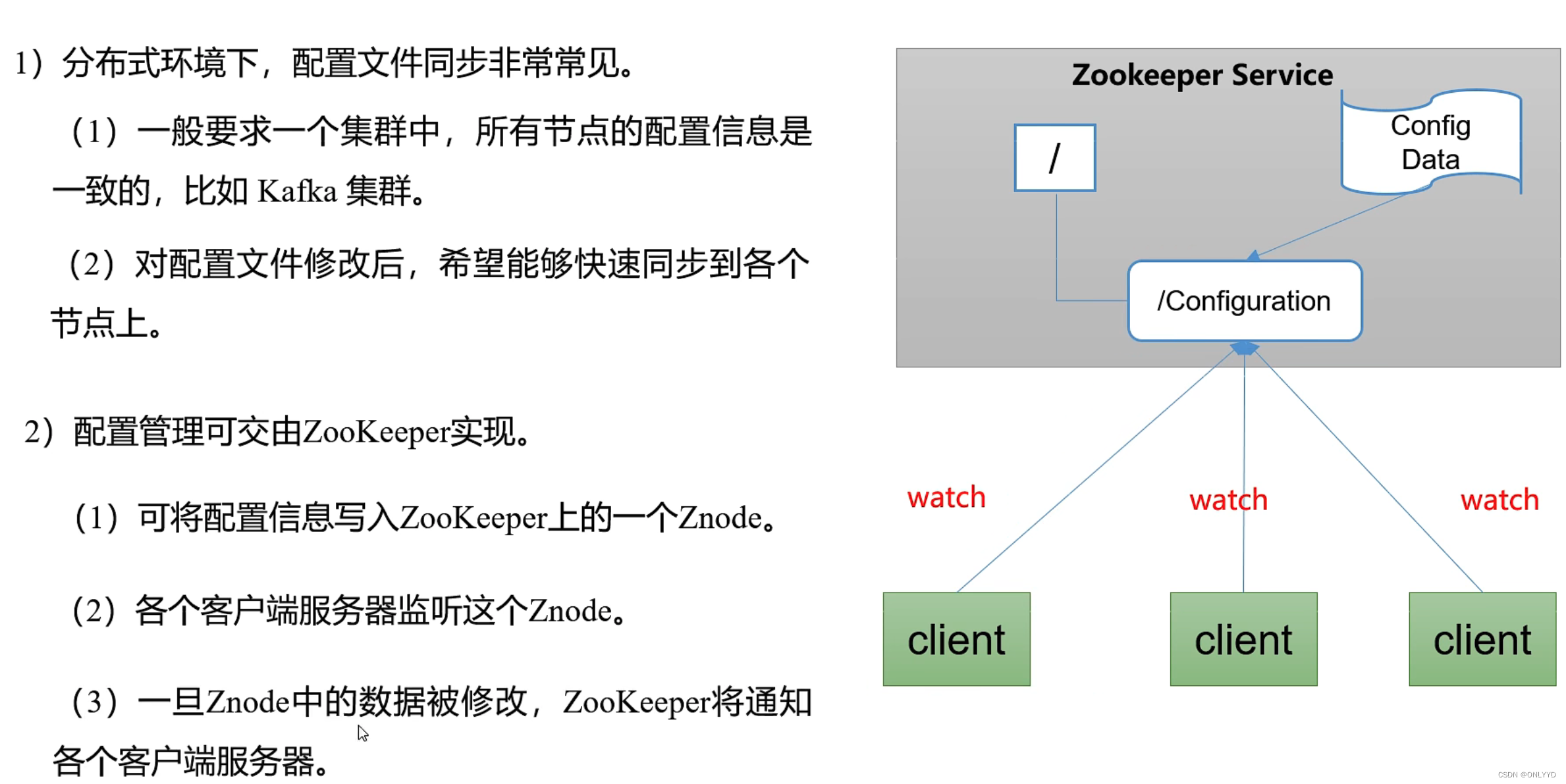
统一配置管理
Version:0.9 StartHTML:0000000105 EndHTML:0000000339 StartFragment:0000000141 EndFragment:0000000299
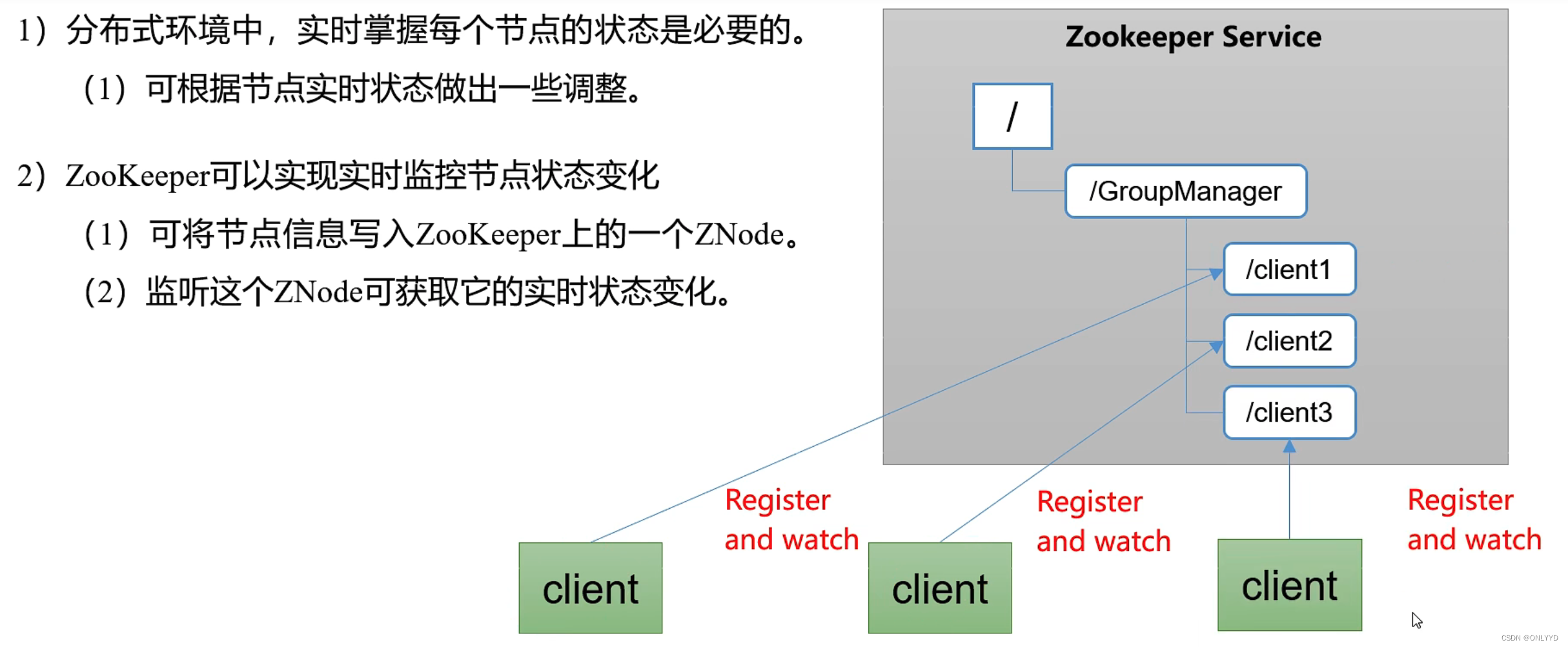
Version:0.9 StartHTML:0000000105 EndHTML:0000000345 StartFragment:0000000141 EndFragment:0000000305
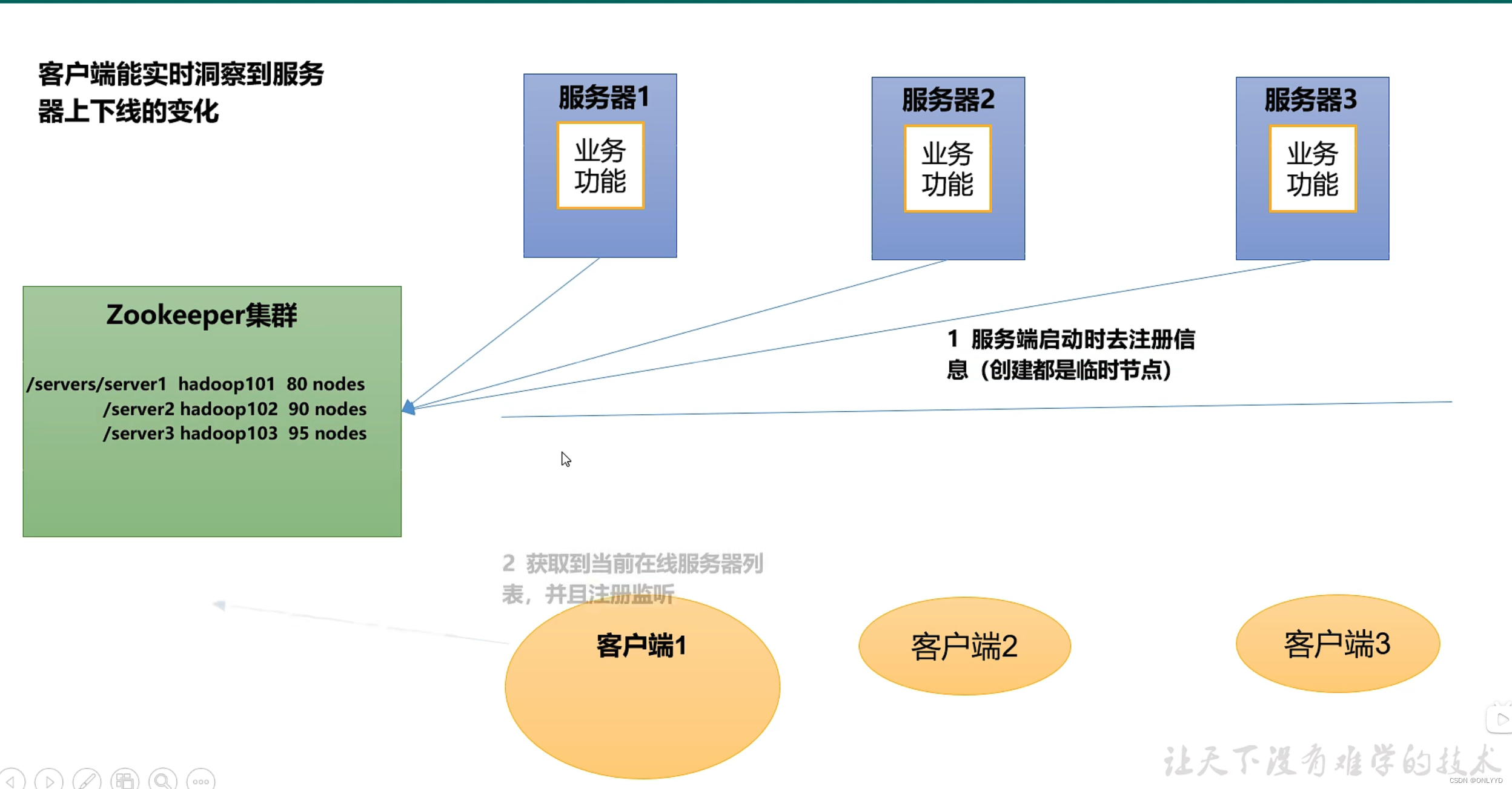
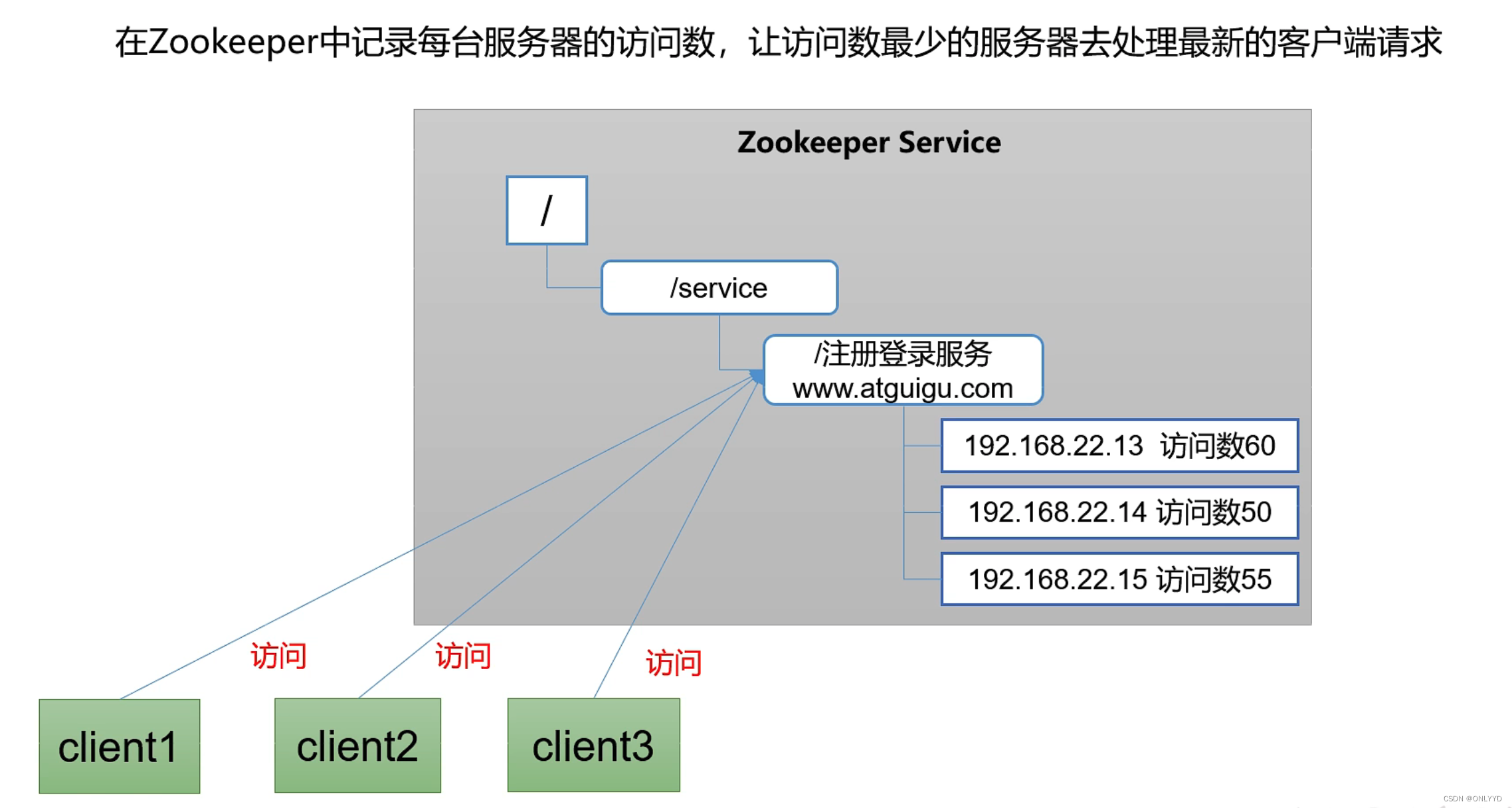
软负载均衡
第 2 章 Zookeeper 安装
2.1 本地模式安装
进入 https://archive.apache.org/dist/zookeeper/ 下载
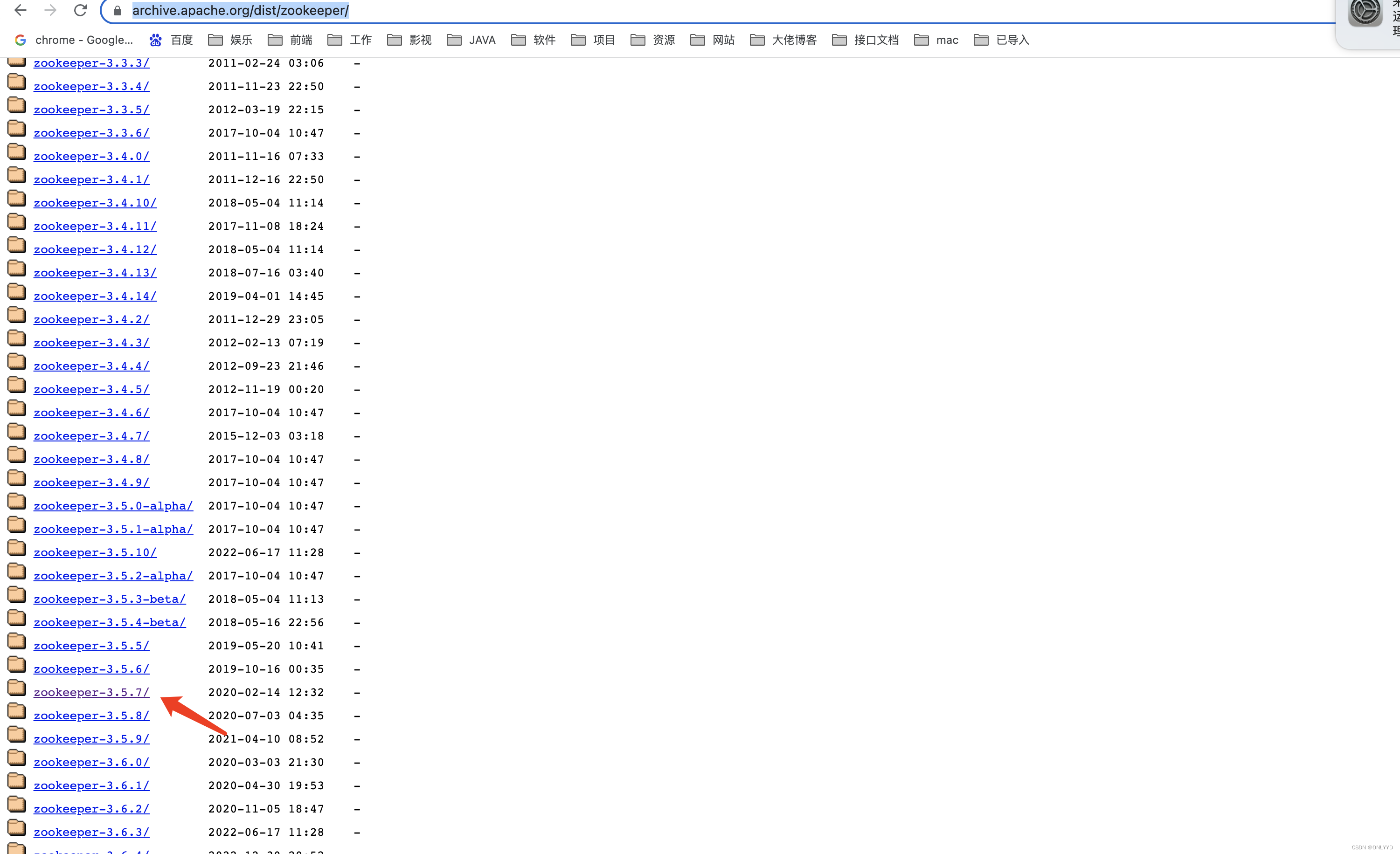
将安装包放在 /opt/software下,学习前部分配置在hadoop章节下
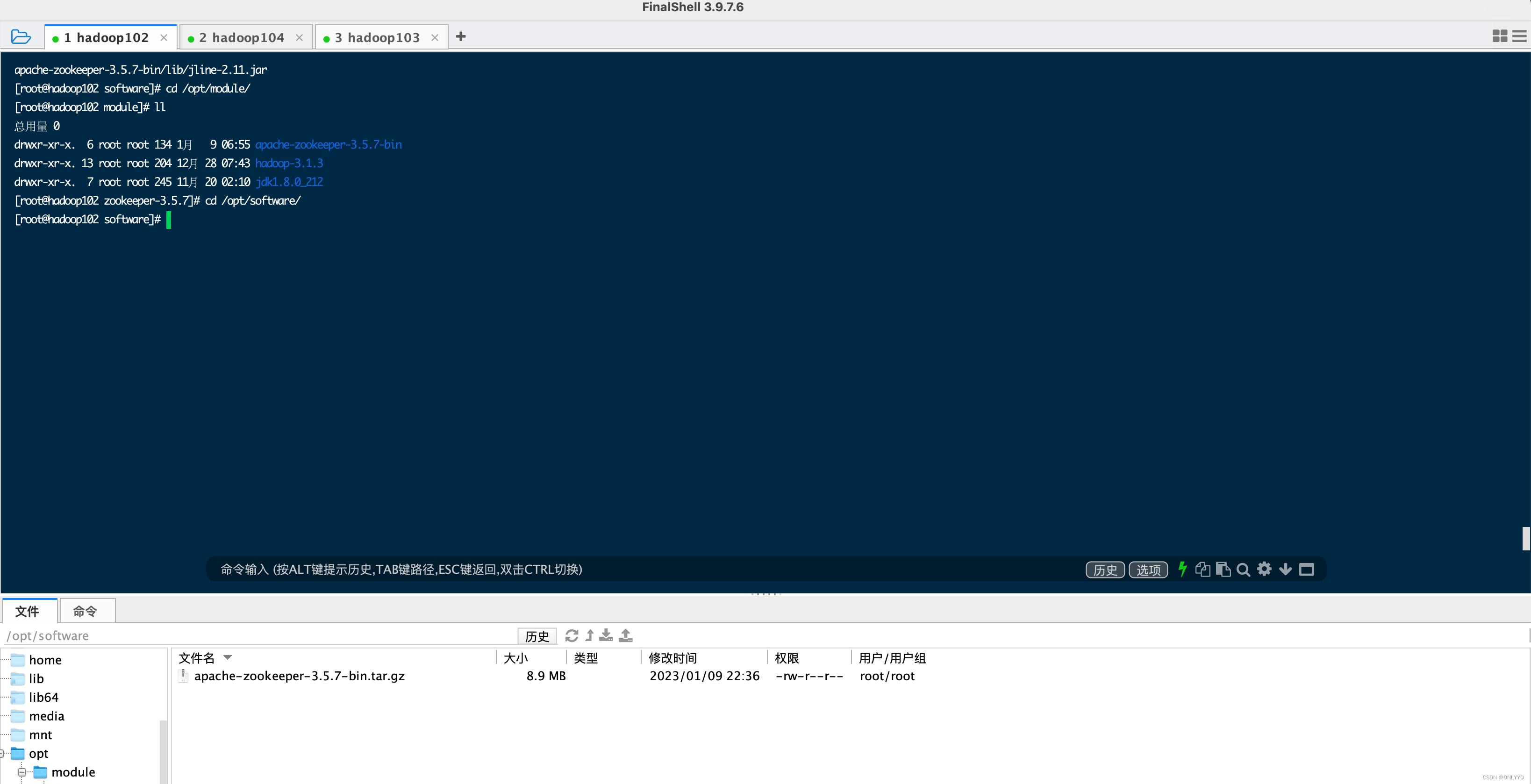
解压到制定目录
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7进入文件夹并创建数据文件夹
cd /opt/module/zookeeper-3.5.7/mkdir zkData修改配置文件名
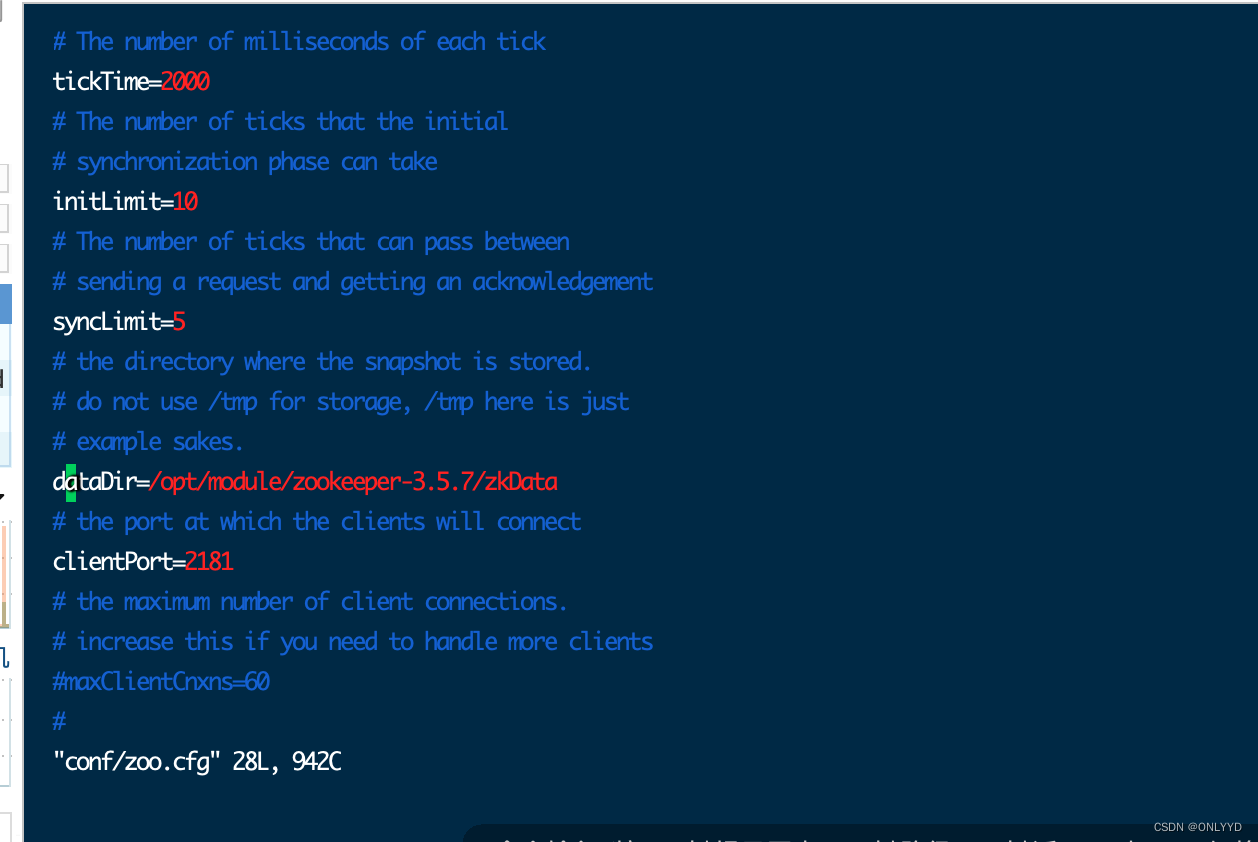
mv conf/zoo_sample.cfg zoo.cfg将文件夹路径配置到zoo.cfg中
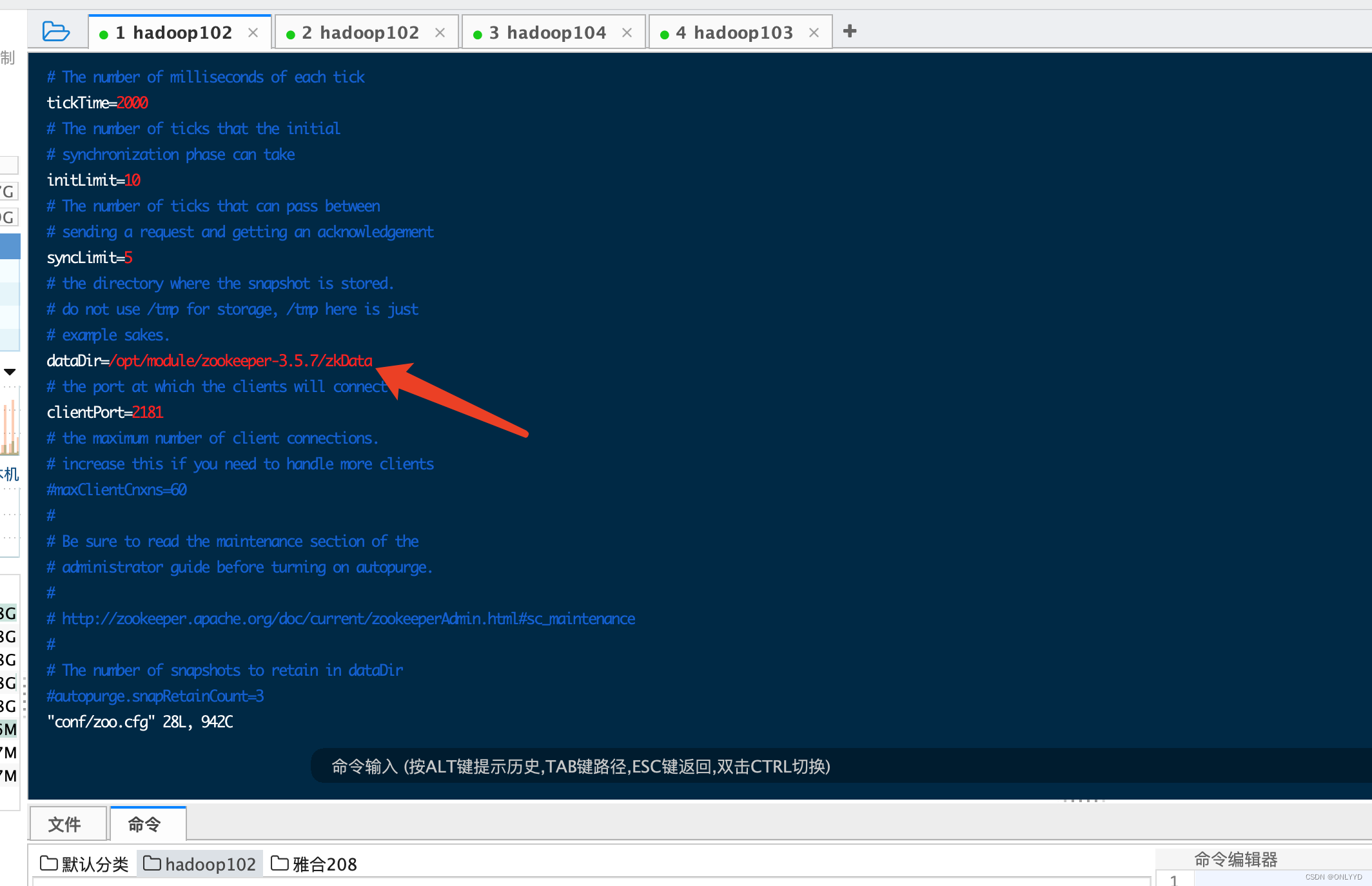
启动zookeeper
/opt/module/zookeeper-3.5.7/bin/zkServer.sh start
/opt/module/zookeeper-3.5.7/bin/zkCli.sh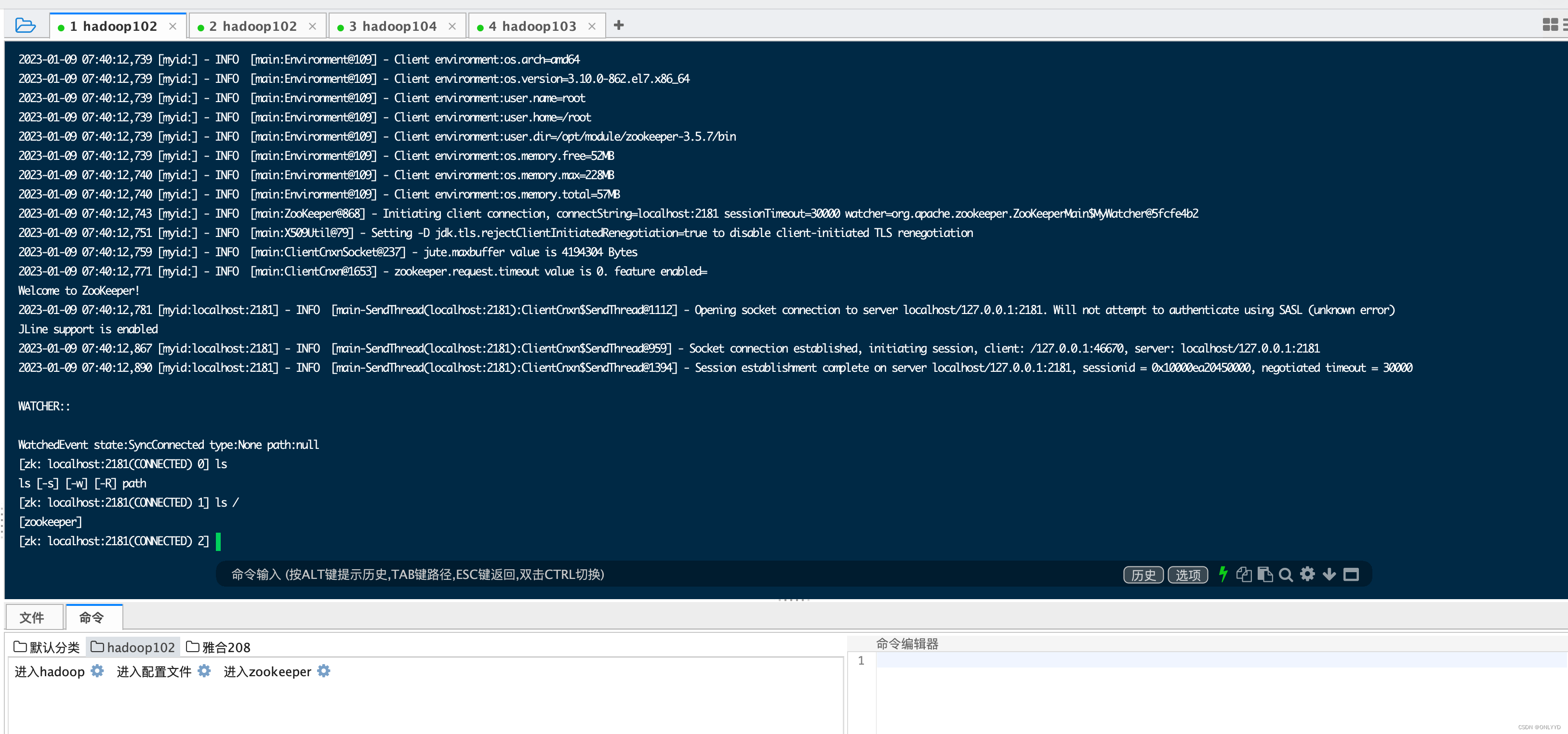
输入 quit便可退出,在bin目录下执行 ./zkServer.sh status可查看当前状态为本地模式
停止
/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop2.2配置解读
第 3 章 Zookeeper 集群操作
3.1.1 集群安装
1、在102服务器创建myid文件,并输入2
vim /opt/module/zookeeper-3.5.7/zkData/myid2、将zookeeper分发给103和104服务器,并编辑myid为3,4
cd /opt/module/
xsync zookeeper-3.5.7/3、将zoo.cfg增加配置,并分发给103、104
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888xsync zoo.cfg 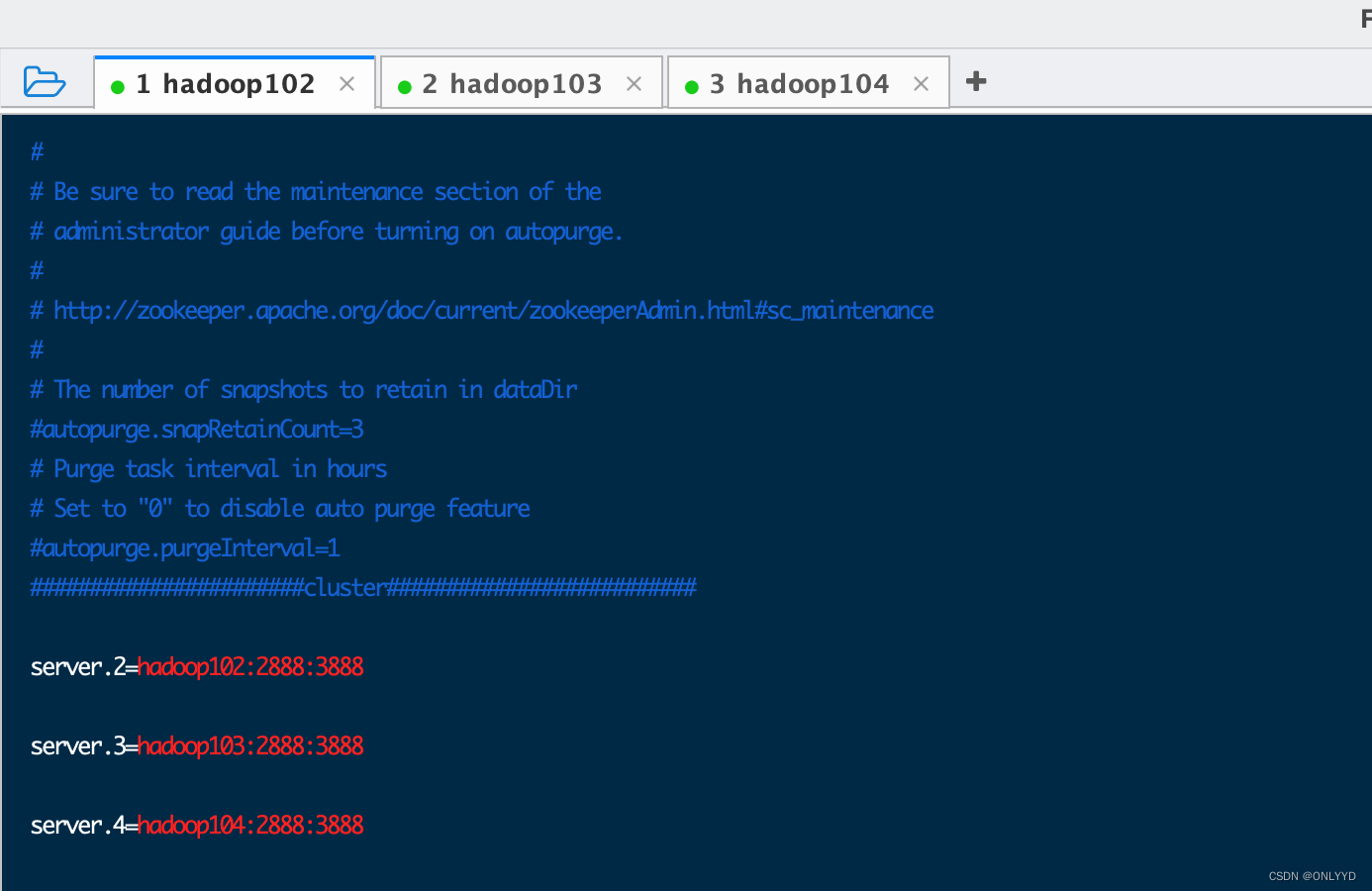
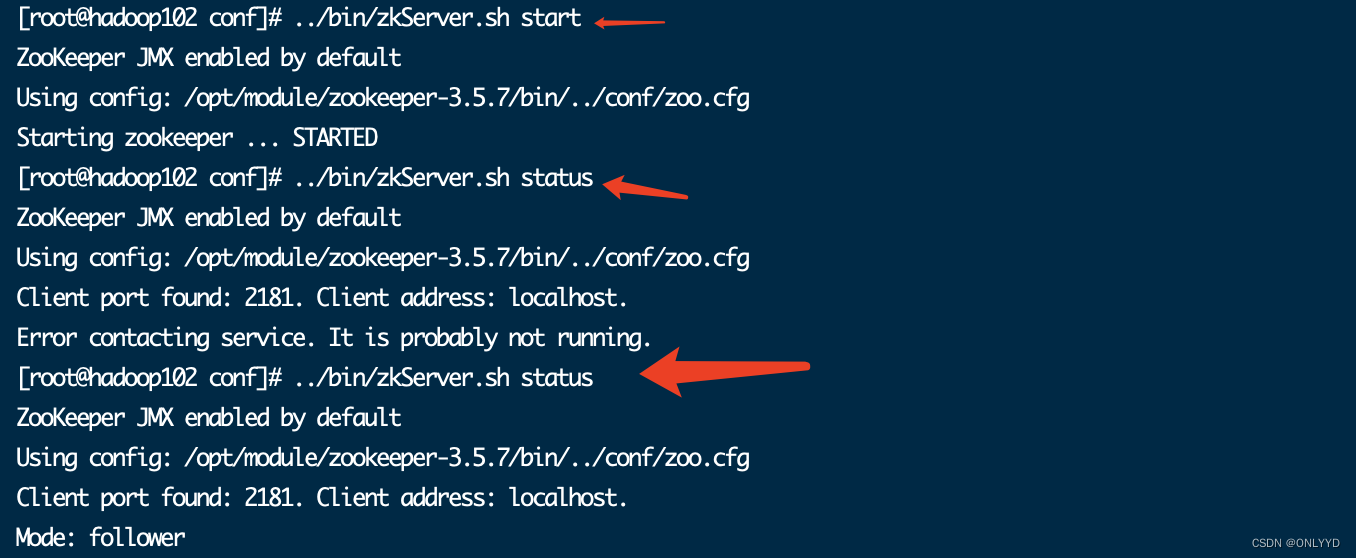
分别启动102、103、104服务器zookeeper,并查看102zookeeper状态
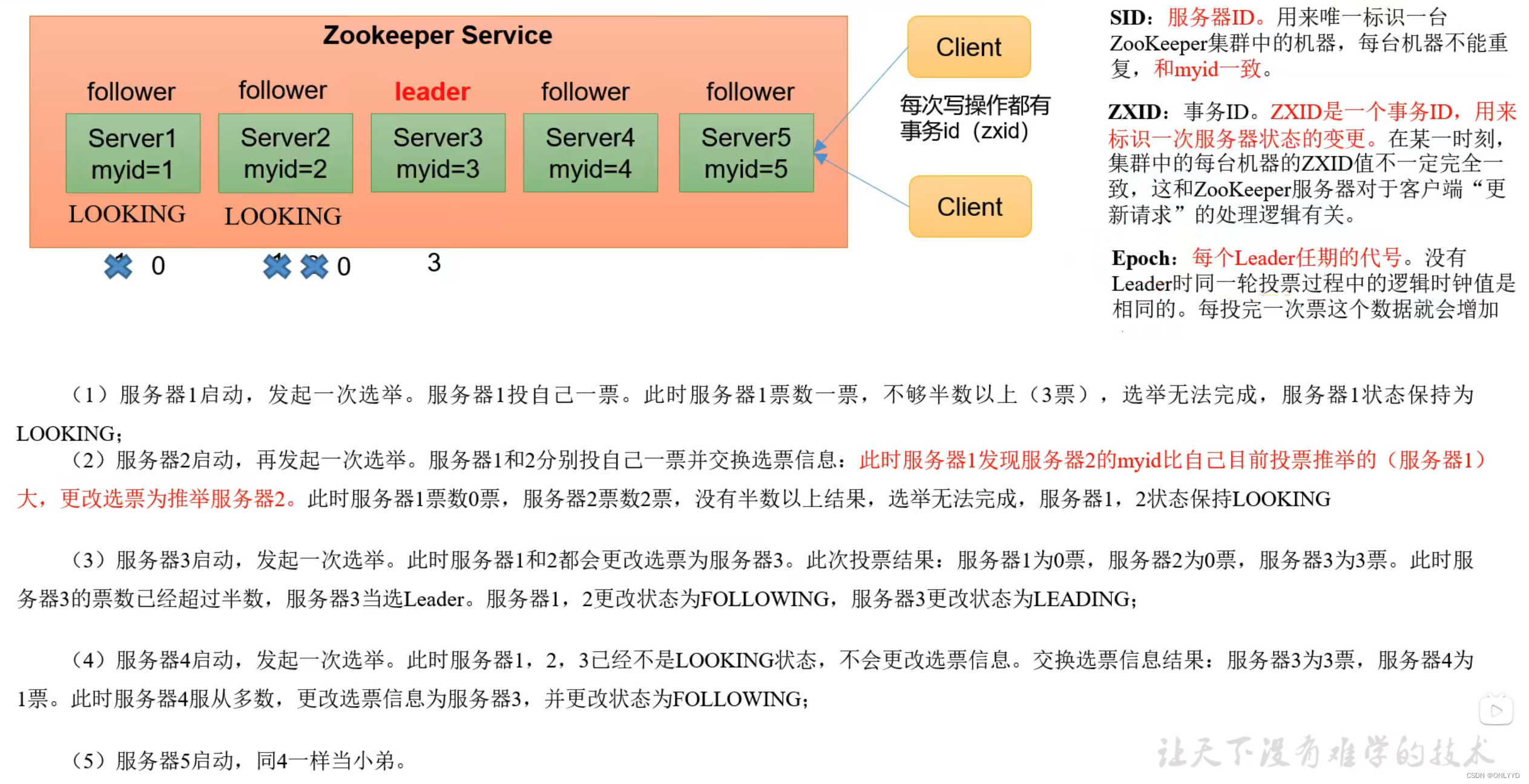
zookeeper选举机制------非第一次启动
3.2 客户端命令行操作
1)本地启动客户端
/opt/module/zookeeper-3.5.7/bin/zkCli.sh
服务启动
/opt/module/zookeeper-3.5.7/bin/zkCli.sh -server hadoop102:2181
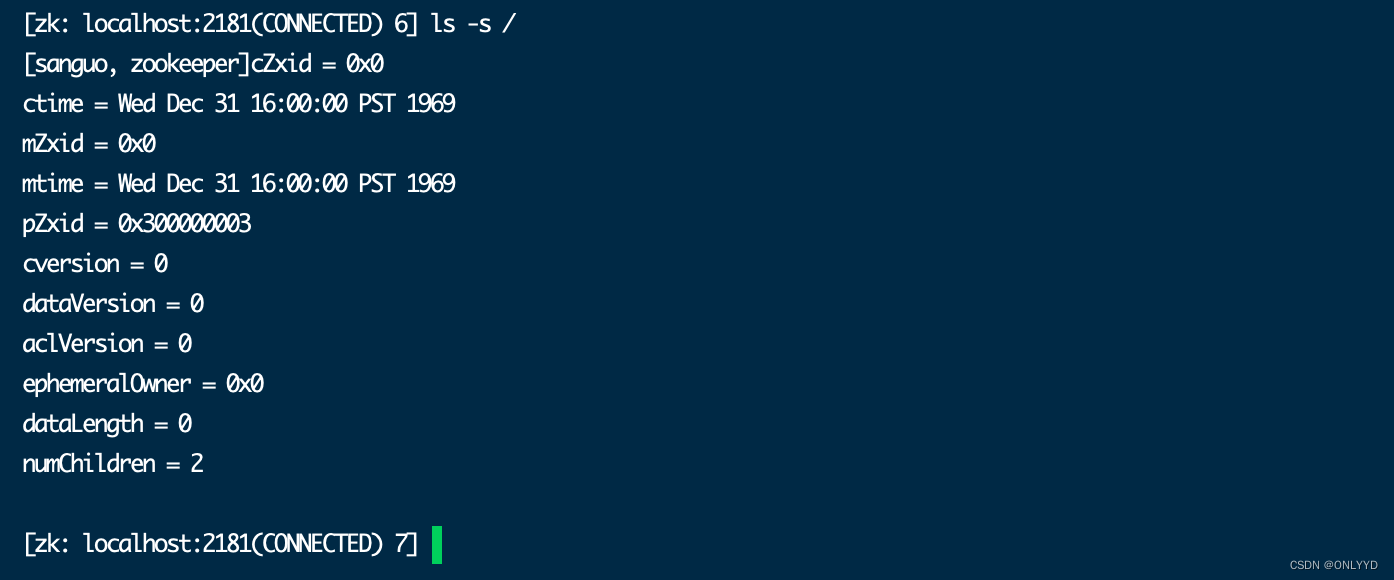
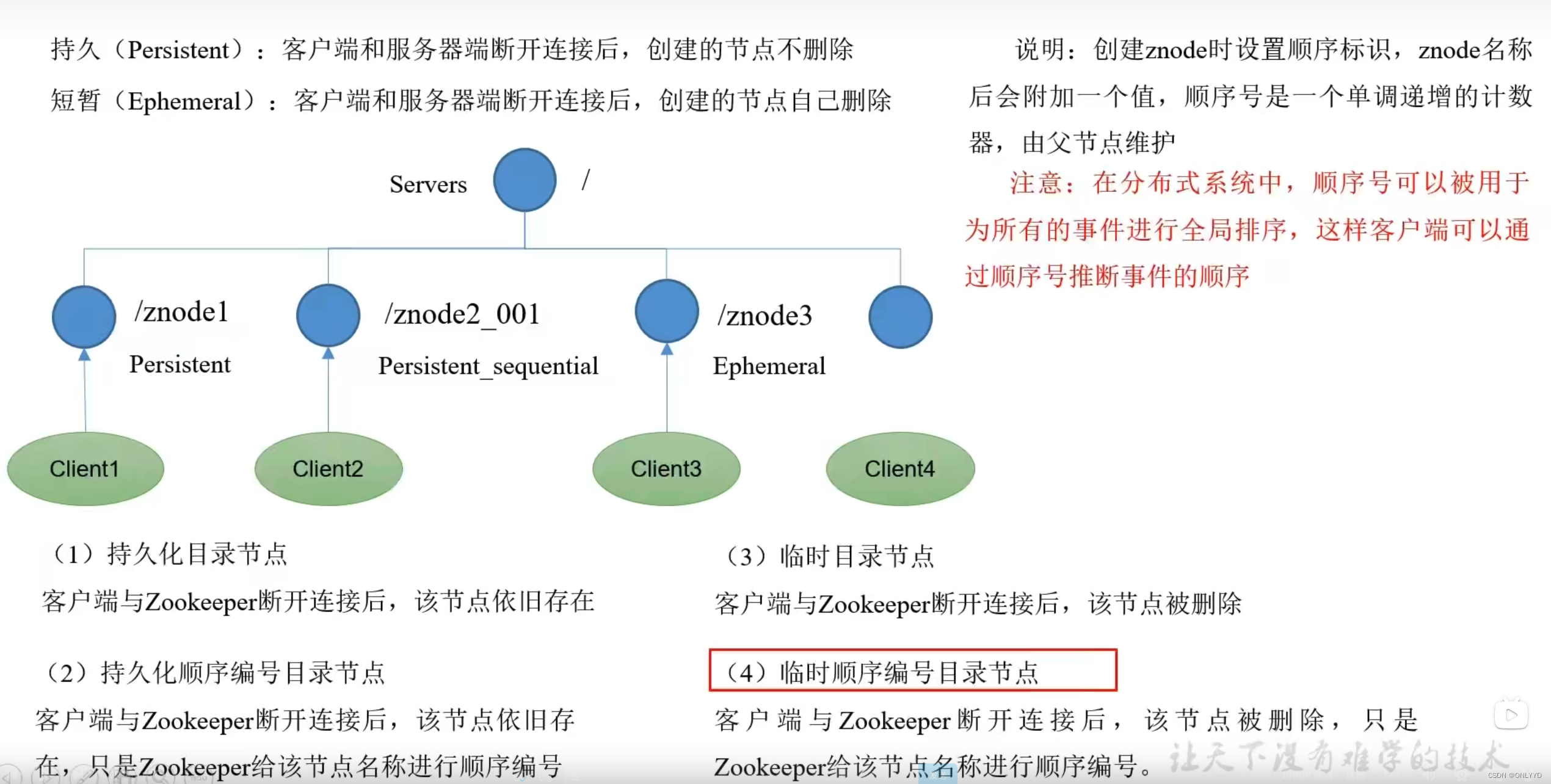
3.2.2 znode 节点数据信息

3.2.3 节点类型(持久/短暂/有序号/无序号)
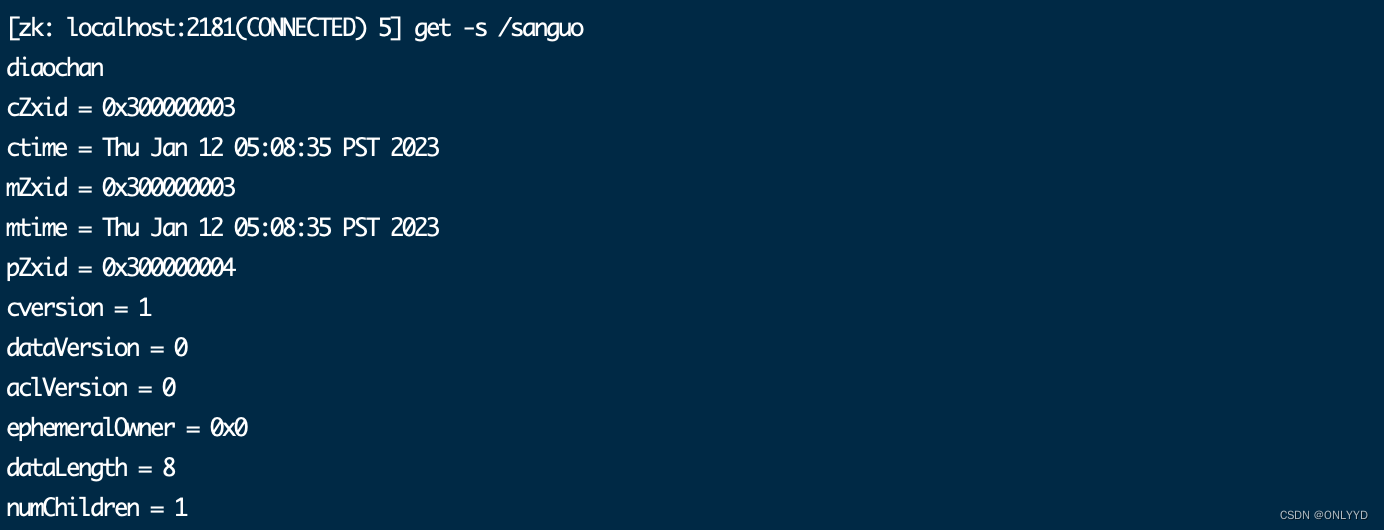
create /sanguo "diaochan"
create /sanguo/shuguo "liubei"2)获得节点的值

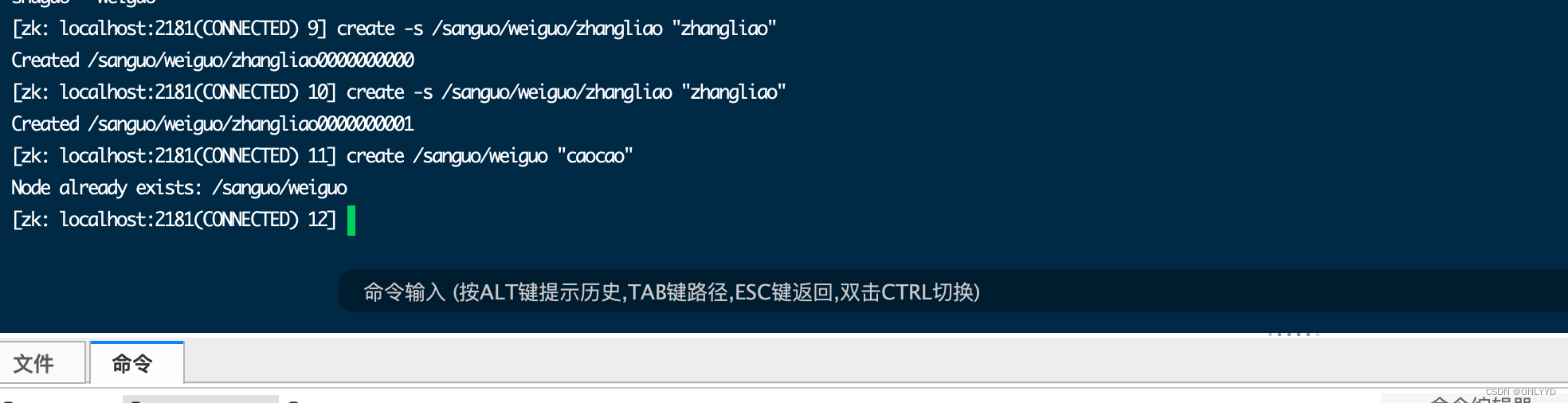
再次创建发现如果原来没有序号节点,序号从 0 开始依次递增。如果原节点下已有 2 个节点,则再排 序时从 2 开始,以此类推。
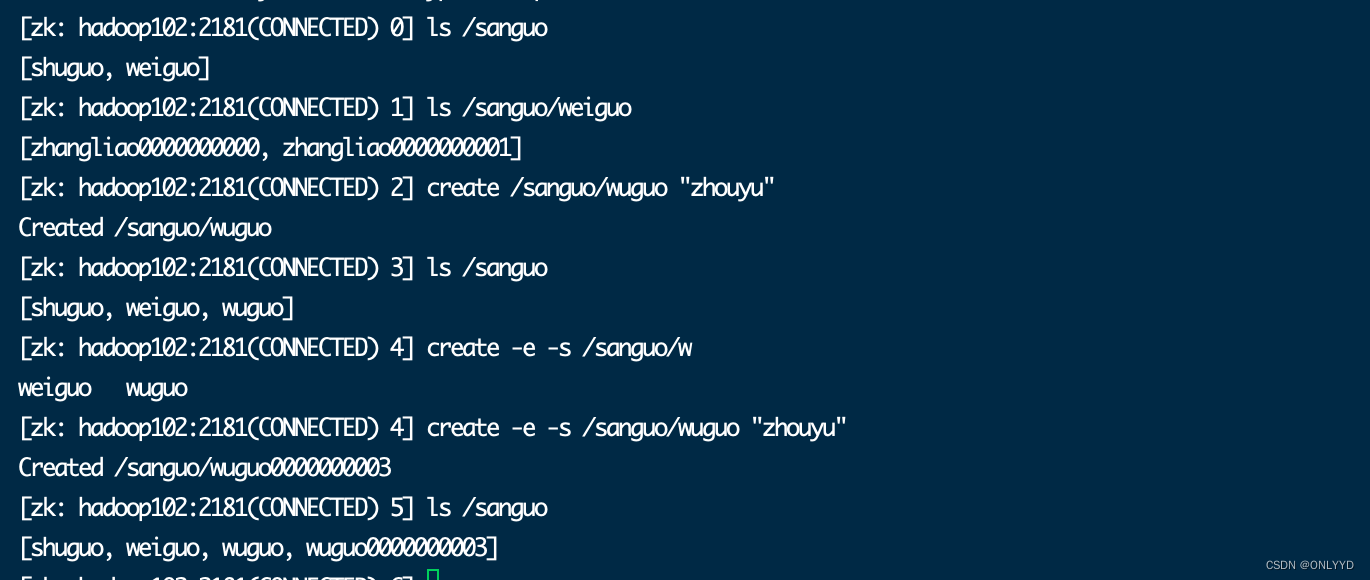
退出后进入,短暂节点被删除
 修改节点数据值
修改节点数据值
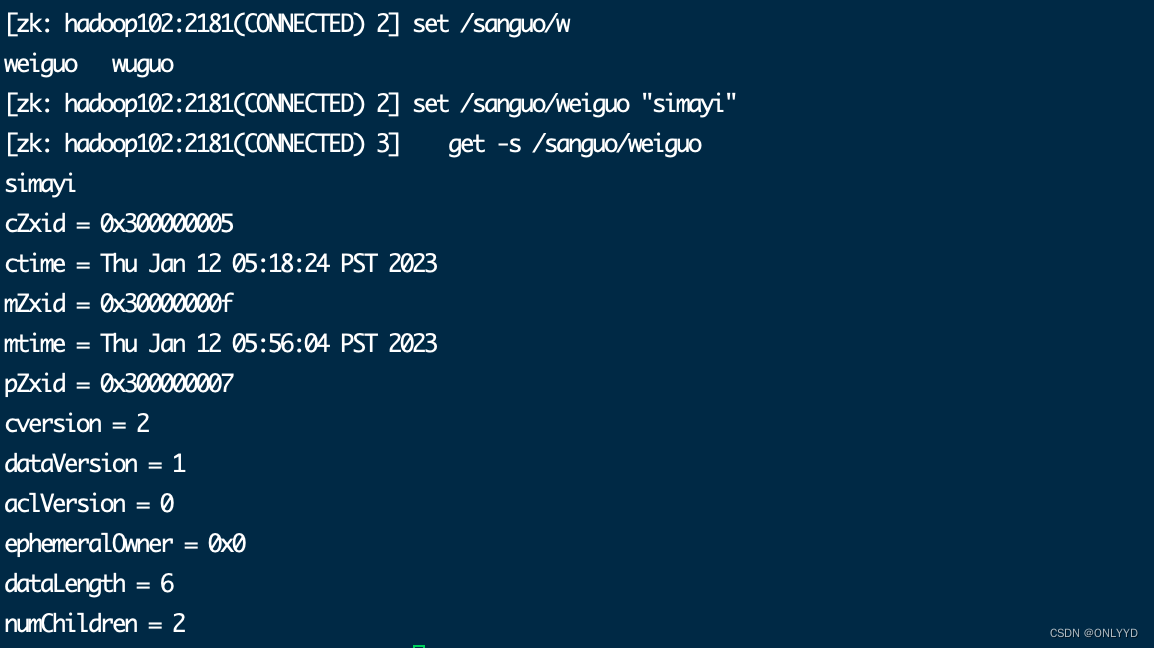
3.2.4 监听器原理
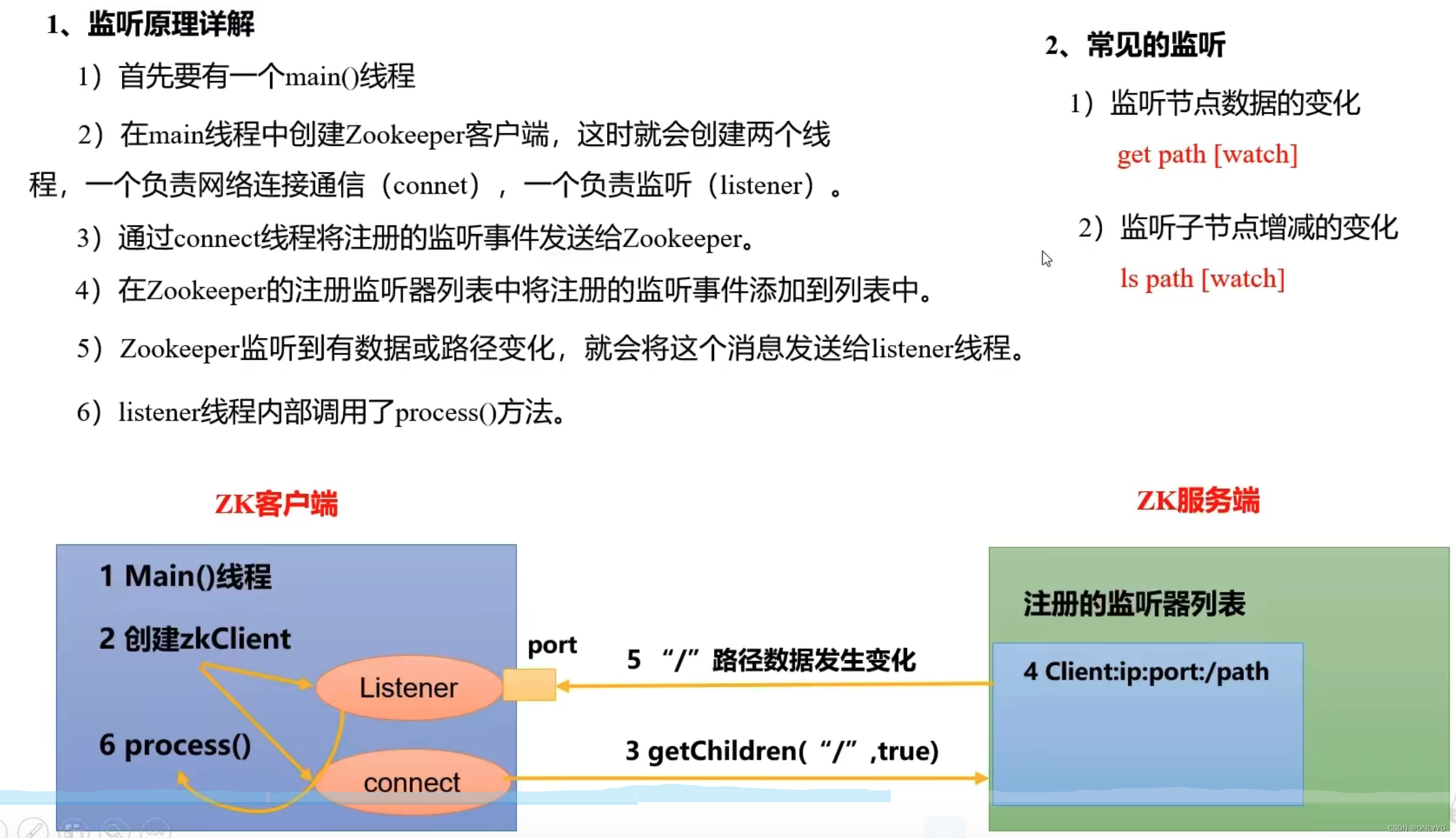

2)递归删除节点

3.3 客户端 API 操作
1) 在IDEA下创建maven项目,并添加pom依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.7</version>
</dependency>
</dependencies>log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c]- %m%n
3)创建 ZooKeeper 客户端
import org.apache.zookeeper.*;
import org.junit.Before;
import org.junit.Test;
import java.util.List;
/**
* @Author sxd
* @create 2023/1/22 10:29
*/
public class zkClient {
// 注意:逗号前后不能有空格
private static String connectString =
"hadoop102:2181,hadoop103:2181,hadoop104:2181";
private static int sessionTimeout = 2000;
private ZooKeeper zkClient = null;
@Before
public void init() throws Exception {
zkClient = new ZooKeeper(connectString, sessionTimeout, new
Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
// 收到事件通知后的回调函数(用户的业务逻辑)
System.out.println(watchedEvent.getType() + "--"
+ watchedEvent.getPath());
System.out.println("-----------");
List<String> children = null;
// 再次启动监听
try {
children = zkClient.getChildren("/",
true);
for (String child : children) {
System.out.println(child);
}
System.out.println("-----------");
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
// 创建节点
@Test
public void create() throws InterruptedException, KeeperException {
String nodeCreated = zkClient.create("/study", "tests".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
@Test
public void getChildren() throws InterruptedException, KeeperException {
List<String> children = zkClient.getChildren("/", true);
for (String child : children) {
System.out.println(child);
}
//延时
Thread.sleep(Long.MAX_VALUE);
}
}
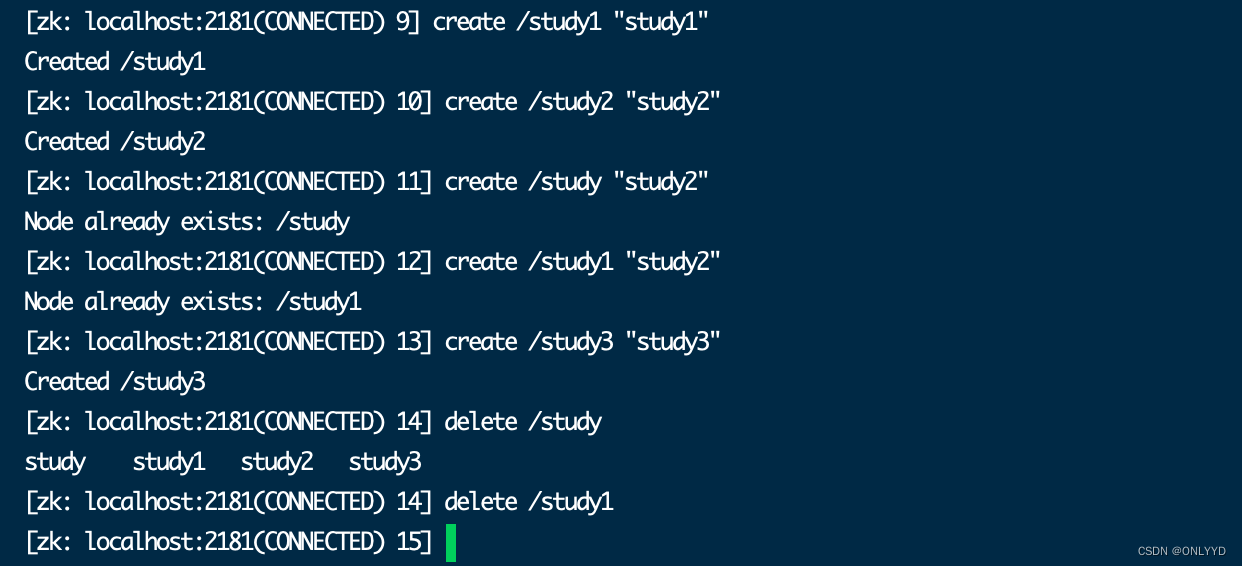
运行 create,节点被创建,并开启监听
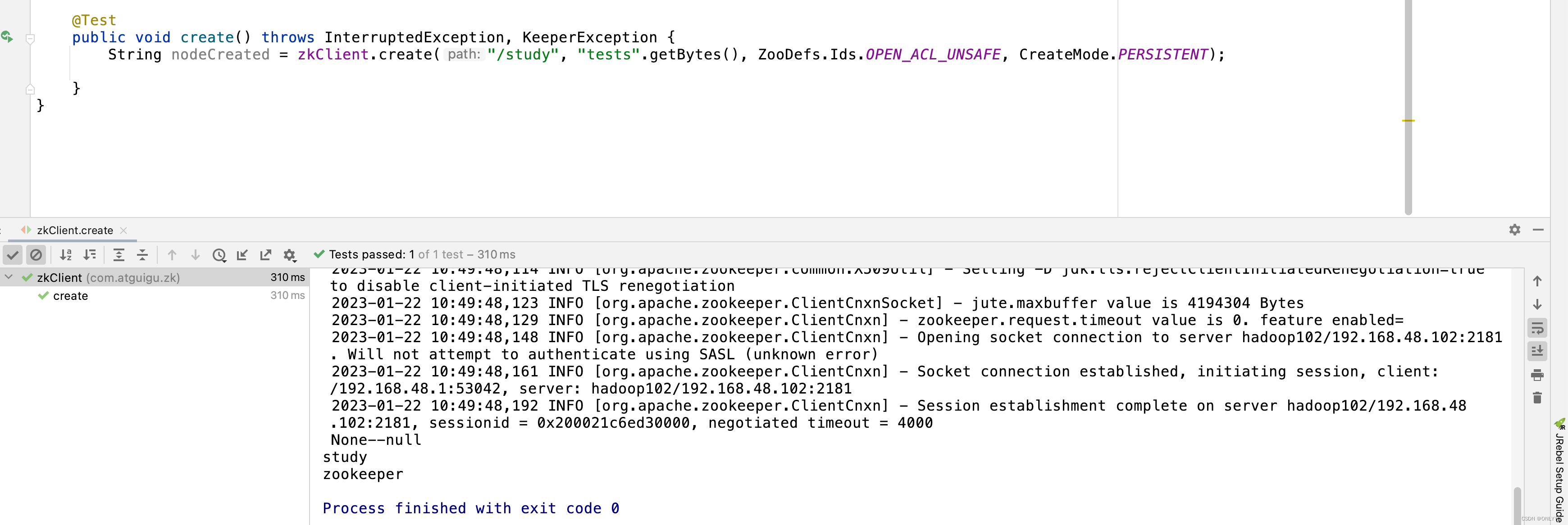

zookeeper创建节点和删除节点,控制台显示已有节点
















 245
245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











