









摘要:
数据挖掘、机器学习和推荐系统中的评测指标—准确率(Precision)、召回率(Recall)、F值(F-Measure)简介。
引言:
在机器学习、数据挖掘、推荐系统完成建模之后,需要对模型的效果做评价。
业内目前常常采用的评价指标有准确率(Precision)、召回率(Recall)、F值(F-Measure)等,下图是不同机器学习算法的评价指标。下文讲对其中某些指标做简要介绍。

本文针对二元分类器!
本文针对二元分类器!!
本文针对二元分类器!!!
对分类的分类器的评价指标将在以后文章中介绍。
在介绍指标前必须先了解“混淆矩阵”:
混淆矩阵
True Positive(真正,TP):将正类预测为正类数
True Negative(真负,TN):将负类预测为负类数
False Positive(假正,FP):将负类预测为正类数误报 (Type I error)
False Negative(假负,FN):将正类预测为负类数→漏报 (Type II error)


1、准确率(Accuracy)
准确率(accuracy)计算公式为:
注:准确率是我们最常见的评价指标,而且很容易理解,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。
准确率确实是一个很好很直观的评价指标,但是有时候准确率高并不能代表一个算法就好。比如某个地区某天地震的预测,假设我们有一堆的特征作为地震分类的属性,类别只有两个:0:不发生地震、1:发生地震。一个不加思考的分类器,对每一个测试用例都将类别划分为0,那那么它就可能达到99%的准确率,但真的地震来临时,这个分类器毫无察觉,这个分类带来的损失是巨大的。为什么99%的准确率的分类器却不是我们想要的,因为这里数据分布不均衡,类别1的数据太少,完全错分类别1依然可以达到很高的准确率却忽视了我们关注的东西。再举个例子说明下。在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。比如在互联网广告里面,点击的数量是很少的,一般只有千分之几,如果用acc,即使全部预测成负类(不点击)acc也有 99% 以上,没有意义。因此,单纯靠准确率来评价一个算法模型是远远不够科学全面的。
2、错误率(Error rate)
错误率则与准确率相反,描述被分类器错分的比例,error rate = (FP+FN)/(TP+TN+FP+FN),对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate。
3、灵敏度(sensitive)
sensitive = TP/P,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力。
4、特效度(sensitive)
specificity = TN/N,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力。
5、精确率、精度(Precision)
精确率(precision)定义为:
表示被分为正例的示例中实际为正例的比例。
6、召回率(recall)
召回率是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitive,可以看到召回率与灵敏度是一样的。
7、综合评价指标(F-Measure)
P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。
F-Measure是Precision和Recall加权调和平均:
当参数α=1时,就是最常见的F1,也即
可知F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。
8、其他评价指标
计算速度:分类器训练和预测需要的时间;
鲁棒性:处理缺失值和异常值的能力;
可扩展性:处理大数据集的能力;
可解释性:分类器的预测标准的可理解性,像决策树产生的规则就是很容易理解的,而神经网络的一堆参数就不好理解,我们只好把它看成一个黑盒子。
下面来看一下ROC和PR曲线(以下内容为自己总结):
1、ROC曲线:
ROC(Receiver Operating Characteristic)曲线是以假正率(FP_rate)和真正率(TP_rate)为轴的曲线,ROC曲线下面的面积我们叫做AUC,如下图所示:
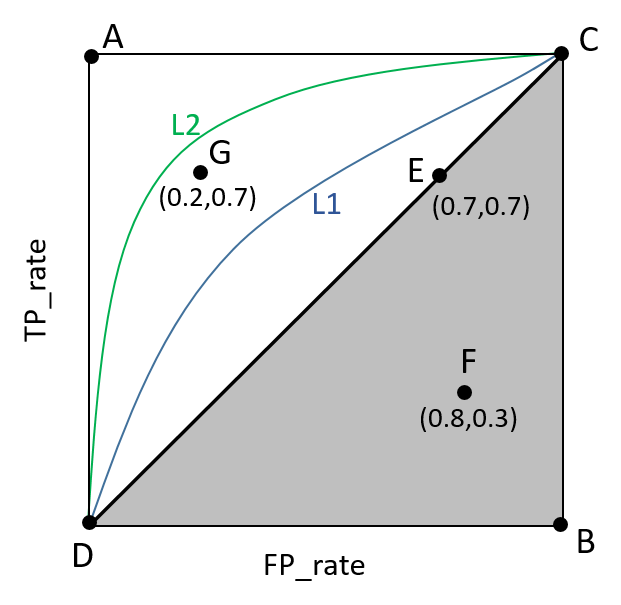
图片根据Paper:Learning from eImbalanced Data画出
其中: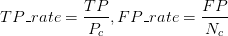 (1)曲线与FP_rate轴围成的面积(记作AUC)越大,说明性能越好,即图上L2曲线对应的性能优于曲线L1对应的性能。即:曲线越靠近A点(左上方)性能越好,曲线越靠近B点(右下方)曲线性能越差。 (2)A点是最完美的performance点,B处是性能最差点。 (3)位于C-D线上的点说明算法性能和random猜测是一样的--如C、D、E点。位于C-D之上(即曲线位于白色的三角形内)说明算法性能优于随机猜测--如G点,位于C-D之下(即曲线位于灰色的三角形内)说明算法性能差于随机猜测--如F点。 (4)虽然ROC曲线相比较于Precision和Recall等衡量指标更加合理,但是其在高不平衡数据条件下的的表现仍然过于理想,不能够很好的展示实际情况。
2、PR曲线:
即,PR(Precision-Recall)曲线。
举个例子(例子来自Paper:Learning from eImbalanced Data):
假设N_c>>P_c(即Negative的数量远远大于Positive的数量),若FP很大,即有很多N的sample被预测为P,因为 ,因此FP_rate的值仍然很小(如果利用ROC曲线则会判断其性能很好,但是实际上其性能并不好),但是如果利用PR,因为Precision综合考虑了TP和FP的值,因此在极度不平衡的数据下(Positive的样本较少),PR曲线可能比ROC曲线更实用。
,因此FP_rate的值仍然很小(如果利用ROC曲线则会判断其性能很好,但是实际上其性能并不好),但是如果利用PR,因为Precision综合考虑了TP和FP的值,因此在极度不平衡的数据下(Positive的样本较少),PR曲线可能比ROC曲线更实用。
当然
1、两个最常见的衡量指标是“准确率(precision)”(你给出的结果有多少是正确的)和“召回率(recall)”(正确的结果有多少被你给出了) 这两个通常是此消彼长的(trade off),很难兼得。很多时候用参数来控制,通过修改参数则能得出一个准确率和召回率的曲线(ROC),这条曲线与x和y轴围成的面积就是AUC(ROC Area)。AUC可以综合衡量一个预测模型的好坏,这一个指标综合了precision和recall两个指标。 但AUC计算很麻烦,有人用简单的F-score来代替。F-score计算方法很简单: F-score=(2*precision*recall)/(precision+recall) 即使不是算数平均,也不是几何平均。可以理解为几何平均的平方除以算术平均。
不妨举这样一个例子:某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
不妨看看如果把池子里的所有的鲤鱼、虾和鳖都一网打尽,这些指标又有何变化:
正确率 = 1400 / (1400 + 300 + 300) = 70%
召回率 = 1400 / 1400 = 100%
F值 = 70% * 100% * 2 / (70% + 100%) = 82.35%
由此可见,正确率是评估捕获的成果中目标成果所占得比例;召回率,顾名思义,就是从关注领域中,召回目标类别的比例;而F值,则是综合这二者指标的评估指标,用于综合反映整体的指标。
当然希望检索结果Precision越高越好,同时Recall也越高越好,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是准确的,那么Precision就是100%,但是Recall就很低;而如果我们把所有结果都返回,那么比如Recall是100%,但是Precision就会很低。因此在不同的场合中需要自己判断希望Precision比较高或是Recall比较高。如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。
2、综合评价指标(F-Measure)
P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。
F-Measure是Precision和Recall加权调和平均:
当参数α=1时,就是最常见的F1,也即
可知F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。


3、E值
E值表示查准率P和查全率R的加权平均值,当其中一个为0时,E值为1,其计算公式:

b越大,表示查准率的权重越大。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









