






6. 面向对象基础
1. 面向对象 vs 面向过程
-
面向过程把解决问题的过程拆成一个个方法,通过一个个方法的执行解决问题。
-
面向对象会先抽象出对象,然后用对象执行方法的方式解决问题。
2. 创建一个对象用什么运算符?对象实体与对象引用有何不同?
new 运算符,new 创建对象实例(对象实例 堆内存),对象引用指向对象实例(对象引用 栈内存)。
-
一个对象引用可以指向 0 个或 1 个对象(一根绳子可以不系气球,也可以系一个气球);
-
一个对象可以有 n 个引用指向它(可以用 n 条绳子系住一个气球)。
3. 对象相等 vs 引用相等
-
对象相等:内存中存放的内容是否相等。(
equals()) -
引用相等:指向的内存地址是否相等。(
==)
String str1 = "hello";
String str2 = new String("hello");
String str3 = "hello";
// == 引用相等
System.out.println(str1 == str2); // false
System.out.println(str1 == str3);
// equals 内容相等
System.out.println(str1.equals(str2));
System.out.println(str1.equals(str3));
4. 一个类没有声明构造方法,该程序能正确执行吗?
构造方法是为了完成对象的初始化工作。
会有默认的不带参数的构造方法。 如果我们自己添加了类的构造方法(无论是否有参),Java 就不会添加默认的无参数的构造方法了。
5. 构造方法的特点?是否可被override?
-
名字与类名相同。
-
没有返回值,但不能用 void 声明构造函数。
-
生成类的对象时自动执行,无需调用。
构造方法不能被 override(重写),但是可以 overload(重载),所以你可以看到一个类中有多个构造函数的情况。
6. 面向对象三大特征
封装、继承、多态。
7. 接口和抽象类有什么共同点和区别?
共同点:
-
都不能被实例化。
-
都可以包含抽象方法。
-
都可以有默认实现的方法(Java 8 可以用
default关键字在接口中定义默认方法)。
区别:
-
接口主要用于对类的行为进行约束,你实现了某个接口就具有了对应的行为。 抽象类主要用于代码复用,强调的是所属关系。
-
一个类只能继承一个类,但是可以实现多个接口。
-
接口中的成员变量只能是
public static final类型的,不能被修改且必须有初始值,而抽象类的成员变量默认 default,可在子类中被重新定义,也可被重新赋值。
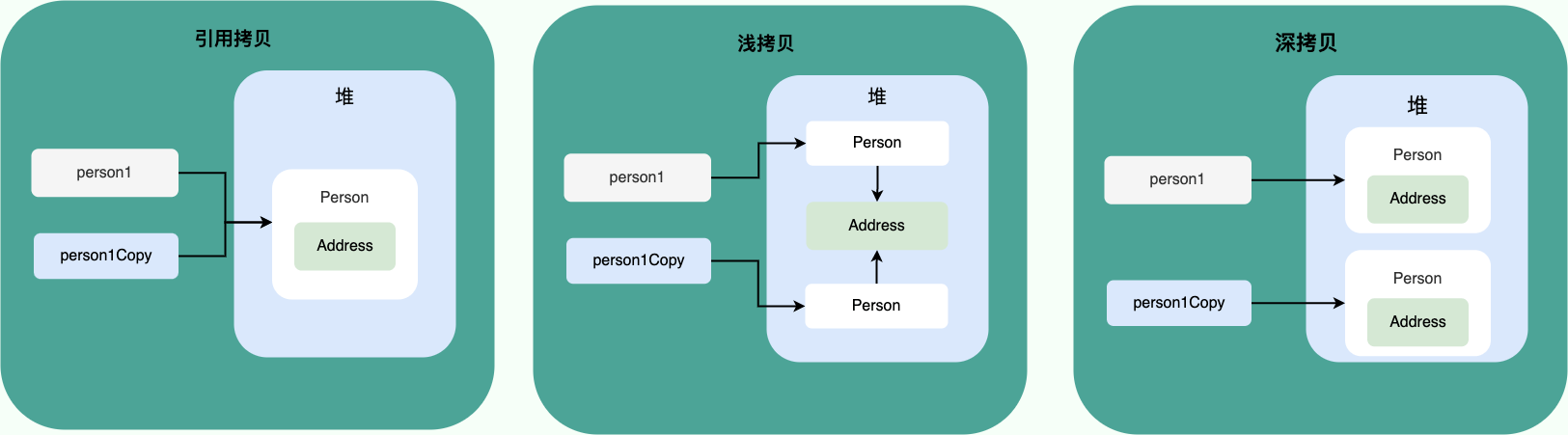
8. 深拷贝和浅拷贝区别了解吗?什么是引用拷贝?
浅拷贝:堆上创建一个新的对象。如果原对象内部的属性是引用类型,浅拷贝会直接复制内部对象的引用地址,也就是说拷贝对象和原对象共用 同一个内部对象。
深拷贝:深拷贝会完全复制(另一个 内容相同)整个对象,包括这个对象所包含的内部对象。
引用拷贝:两个不同的引用指向同一个对象。
7. Object类
1. 常见方法
作为所有类的父类,有11个方法。
getClass(), hashCode(), equals(), clone(), toString() notify(), notifyAll(), wait()*3 finalize()
/**
* native 方法,用于返回当前运行时对象的 Class 对象,使用了 final 关键字修饰,故不允许子类重写。
*/
public final native Class<?> getClass()
/**
* native 方法,用于返回对象的哈希码,主要使用在哈希表中,比如 JDK 中的HashMap。
*/
public native int hashCode()
/**
* 用于比较 2 个对象的内存地址是否相等,String 类对该方法进行了重写以用于比较字符串的值是否相等。
*/
public boolean equals(Object obj)
/**
* native 方法,用于创建并返回当前对象的一份拷贝。
*/
protected native Object clone() throws CloneNotSupportedException
/**
* 返回类的名字实例的哈希码的 16 进制的字符串。建议 Object 所有的子类都重写这个方法。
*/
public String toString()
/**
* native 方法,并且不能重写。唤醒一个在此对象监视器上等待的线程(监视器相当于就是锁的概念)。如果有多个线程在等待只会任意唤醒一个。
*/
public final native void notify()
/**
* native 方法,并且不能重写。跟 notify 一样,唯一的区别就是会唤醒在此对象监视器上等待的所有线程,而不是一个线程。
*/
public final native void notifyAll()
/**
* native方法,并且不能重写。暂停线程的执行。注意:sleep 方法没有释放锁,而 wait 方法释放了锁 ,timeout 是等待时间。
*/
public final native void wait(long timeout) throws InterruptedException
/**
* 多了 nanos 参数,这个参数表示额外时间(以纳秒为单位,范围是 0-999999)。 所以超时的时间还需要加上 nanos 纳秒。。
*/
public final void wait(long timeout, int nanos) throws InterruptedException
/**
* 跟之前的2个wait方法一样,只不过该方法一直等待,没有超时时间这个概念
*/
public final void wait() throws InterruptedException
/**
* 实例被垃圾回收器回收的时候触发的操作
*/
protected void finalize() throws Throwable { }
2. == 和 equals() 的区别
因为 Java 只有值传递,所以,对于 == 来说,不管是比较基本数据类型,还是引用数据类型的变量,其本质比较的都是值,只是引用类型变量存的值是对象的地址。
== 对于基本类型和引用类型的作用效果是不同的:
-
对于基本数据类型来说,
==比较的是值。 -
对于引用数据类型来说,
==比较的是对象的内存地址。
equals() 方法存在两种使用情况:
-
没有重写 :等价于通过“==”比较这两个对象,使用的默认是
Object类equals()方法。 -
重写了:比较两个对象中的属性是否相等;若它们的属性相等,则返回 true(即,认为这两个对象相等)。
String 中的 equals 方法是被重写过的,因为 Object 的 equals 方法是比较的对象的内存地址, 而 String 的 equals 方法比较的是对象的值。
3. hashCode() 作用?
获取哈希码(int 整数),也称为散列码。这个哈希码的作用是确定该对象在哈希表中的索引位置。

hashCode() 和 equals()都是用于比较两个对象是否相等。
因为在一些容器(比如 HashMap、HashSet)中,有了 hashCode() 之后,判断元素是否在对应容器中的效率会更高(参考添加元素进HashSet的过程)!
Q:为什么不只提供hashCode()比较对象呢?
使用的哈希算法也许刚好会让多个对象传回相同的哈希值 碰撞,无法确定。
hashCode(): 不等 -> 不等 相等: equals() 相等 -> 相等 不等 -> 不等
4. 为什么重写 equals() 时必须重写 hashCode() 方法?
两个相等的对象的 hashCode 值必须是相等,否则会导致 equals 方法判断是相等的两个对象,hashCode 值却不相等。
8. String类
1. String、StringBuffer、StringBuilder 的区别?
| 区别 | String | StringBuffer | StringBuilder |
|---|---|---|---|
| 可变性 | 不可变 | 可变 | 可变 |
| 线程安全性 | 线程安全 | 线程安全(方法加了同步锁) | 不安全(未加同步锁) |
| 性能 | 每次改变生成新对象 | 操作本身,不生成新对象,性能较 String 高 | 操作本身,不生成新对象,性能较 String 高 |
| 适用场景 | 操作少量数据 | 多线程 大量数据 | 单线程 大量数据 |
2. String 为什么是不可变的?
-
保存字符串的数组被
final修饰且为私有的,并且String类没有提供/暴露修改这个字符串的方法。 -
String类被final修饰导致其不能被继承,进而避免了子类破坏String不可变。
3. 字符串拼接用“+” 还是 StringBuilder?
Java 语言本身并不支持运算符重载,“+”和“+=”是专门为 String 类重载过的运算符,也是 Java 中仅有的两个重载过的运算符。
字符串对象通过“+”的字符串拼接方式,实际上是通过 StringBuilder 调用 append() 方法实现的,拼接完成之后调用 toString() 得到一个 String 对象 。 (+不要用在for循环内部,会创建多个StringBuilder对象)
4. 字符串常量池
JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。存储的是字符串字面量和通过某些方法生成的字符串对象的引用。
// 在堆中创建字符串对象”ab“ // 将字符串对象”ab“的引用保存在字符串常量池中 String aa = "ab"; // 直接返回字符串常量池中字符串对象”ab“的引用 String bb = "ab"; System.out.println(aa==bb);// true
5. String s1 = new String("abc"); 创建了几个字符串对象?
一个或者两个 字符串对象。
1、如果字符串常量池中不存在字符串对象“abc”的引用,那么它会在堆上创建两个字符串对象,字符串对象("abc")的引用会被保存在字符串常量池中。
2、如果字符串常量池中已存在字符串对象“abc”的引用,则只会在堆中创建 1 个字符串对象“abc”。
// 字符串常量池中
String s1 = "abc";
// 下面这段代码只会在堆中创建 1 个字符串对象“abc”
String s2 = new String("abc");
直接双引号声明出来的String对象会直接存储在常量池中。 new String()对象存储在堆里。
6. String#intern 方法有什么作用?
String.intern() 是一个 native(本地)方法,会从字符串常量池中查询当前字符串是否存在,其作用是将指定的字符串对象的引用保存在字符串常量池中,可以简单分为两种情况:
-
如果字符串常量池中保存了对应的字符串对象的引用,就直接返回该引用。
-
如果字符串常量池中没有保存了对应的字符串对象的引用,那就在常量池中创建一个指向该字符串对象的引用并返回。
// 在堆中创建字符串对象”Java“
// 将字符串对象”Java“的引用保存在字符串常量池中
String s1 = "Java";
// 直接返回字符串常量池中字符串对象”Java“对应的引用
String s2 = s1.intern();
// 会在堆中在单独创建一个字符串对象
String s3 = new String("Java");
// 直接返回字符串常量池中字符串对象”Java“对应的引用
String s4 = s3.intern();
// s1 和 s2 指向的是堆中的同一个对象
System.out.println(s1 == s2); // true
// s3 和 s4 指向的是堆中不同的对象
System.out.println(s3 == s4); // false
// s1 和 s4 指向的是堆中的同一个对象
System.out.println(s1 == s4); //true















 369
369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









