







一、获取淘宝天猫商品销量数据的方法
(一)爬虫技术
通过编写网络爬虫程序,模拟用户在浏览器中的操作行为,抓取淘宝或天猫的商品页面,进而从页面源代码中解析出销量数据。不过,淘宝和天猫平台针对爬虫行为设有诸多限制和防范手段,如验证码识别、IP 访问频率限制、User - Agent 检测等。在运用爬虫技术时,务必严格遵守平台规则,防止对平台服务器造成过大压力或引发反爬虫机制导致 IP 被封禁等风险。例如,控制请求频率,避免短时间内大量发送请求;随机更换 User - Agent,模拟不同的浏览器或设备访问;采用代理 IP 池,分散请求源 IP,降低被封禁的概率。
(二)第三方数据服务
部分第三方数据服务提供商凭借合法合规的方式,获取了淘宝或天猫的商品销量数据,并向开发者开放相应的 API 接口。与这些第三方服务合作,能够相对便捷地获取所需的销量数据。在选择第三方服务提供商时,需谨慎评估其可靠性、数据准确性以及合法性。例如,查看其是否具备相关的数据授权资质,了解其数据采集和更新机制,参考其他用户的使用评价等,确保所获取的数据真实有效且来源合法。
(三)与淘宝 / 天猫合作
若您是大型商家或具有特殊需求的合作伙伴,可以尝试与淘宝或天猫平台开展深度合作,通过官方正规渠道获取商品销量数据。这通常需要与平台建立合作关系,遵循平台的一系列规定和要求,可能涉及签署合作协议、满足特定的业务条件等。例如,大型品牌商可能通过与平台的战略合作,获得定制化的数据服务权限,以满足其精准的市场分析和业务决策需求。
二、使用爬虫技术获取淘宝天猫商品销量数据的实战步骤
(一)环境搭建
- 安装 Python:Python 是编写爬虫程序的常用语言,其丰富的库和简洁的语法能大大提高开发效率。从 Python 官方网站(https://www.python.org/downloads/)下载并安装最新版本的 Python。
- 安装必要的库:
-
- requests 库:用于发送 HTTP 请求,获取网页内容。在命令行中执行pip install requests进行安装。
-
- BeautifulSoup 库:用于解析 HTML 和 XML 文档,方便从网页源代码中提取数据。通过pip install beautifulsoup4安装。
-
- lxml 库:配合 BeautifulSoup 使用,提升解析速度。使用pip install lxml进行安装。
(二)分析商品页面结构
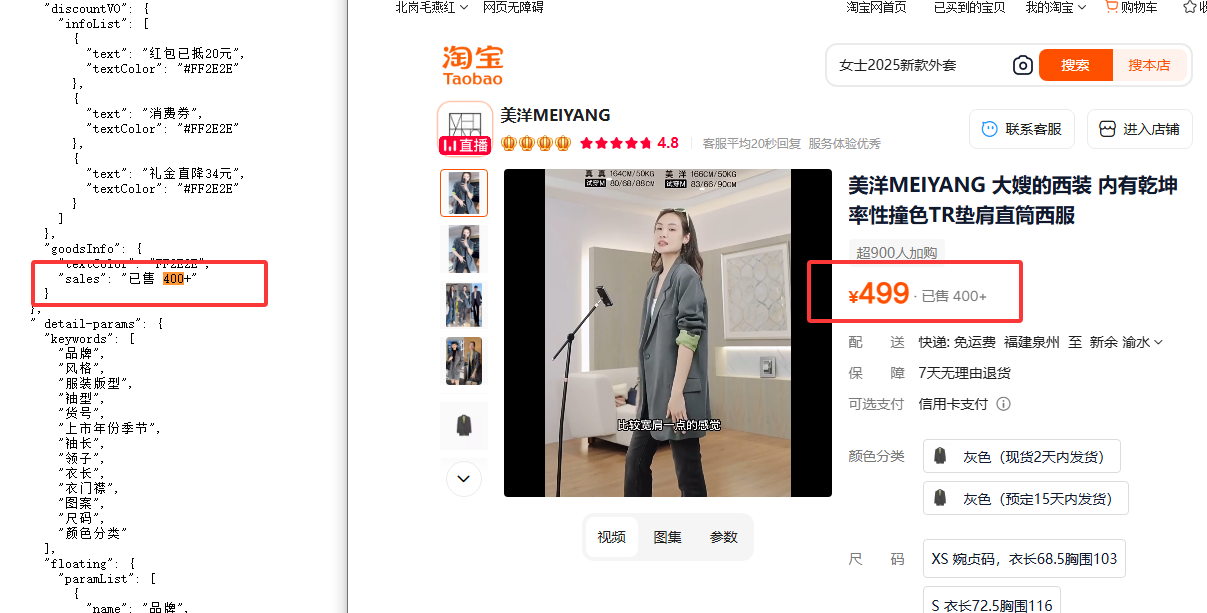
以淘宝商品页面为例,打开淘宝网站,搜索目标商品,进入商品详情页。右键点击页面,选择 “查看网页源代码”,在源代码中查找与商品销量相关的 HTML 标签和属性。一般来说,商品销量信息可能包含在<span>标签内,且具有特定的 class 属性,如 “tm - count” 等(不同页面结构可能有所差异)。通过分析页面结构,确定销量数据在 HTML 文档中的具体位置,以便后续编写代码进行解析。
(三)编写爬虫代码
以下是一个简单的 Python 爬虫示例代码,用于获取淘宝商品的销量数据:
import requests
from bs4 import BeautifulSoup
def get_taobao_sales(url):
headers = {
"User - Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
response = requests.get(url, headers = headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'lxml')
sales_span = soup.find('span', class_='tm - count')
if sales_span:
sales = sales_span.text.strip()
return sales
else:
return "未找到销量数据"
else:
return "请求失败,状态码:" + str(response.status_code)
# 示例商品链接
product_url = "https://detail.tmall.com/item.htm?id=654321"
sales_data = get_taobao_sales(product_url)
print("商品销量:", sales_data)
在上述代码中:
- 设置请求头:通过headers字典设置 User - Agent,模拟真实浏览器访问,避免被反爬虫机制识别。
- 发送 HTTP 请求:使用requests.get()方法发送 GET 请求,获取商品页面的 HTML 内容。
- 解析页面:利用BeautifulSoup库将获取到的 HTML 文本解析为可操作的对象,通过find()方法查找包含销量数据的<span>标签。
- 提取销量数据:若找到对应的标签,则提取其中的文本内容,并去除首尾空格,得到商品销量数据。
(四)应对反爬虫措施
- 设置请求频率:在代码中添加延迟,避免短时间内大量发送请求。例如,使用time.sleep()函数,在每次请求后暂停一定时间,如time.sleep(2)表示暂停 2 秒。
- 使用代理 IP:从免费或付费的代理 IP 服务提供商处获取代理 IP 列表,在每次请求时随机选择一个代理 IP 进行访问。可以使用requests库的proxies参数来设置代理,如下所示:
proxies = {
"http": "http://123.456.789.10:8080",
"https": "https://123.456.789.10:8080"
}
response = requests.get(url, headers = headers, proxies = proxies)
- 验证码处理:当遇到验证码时,可采用 OCR 识别技术(如使用pytesseract库)对验证码图片进行识别,或调用第三方验证码识别服务(如超级鹰等)来自动识别验证码。不过,验证码识别的准确性可能受到图片质量、验证码类型等因素影响,需要根据实际情况进行优化。
三、使用第三方数据服务获取商品销量数据的流程
(一)选择可靠的第三方数据服务提供商
在众多第三方数据服务提供商中进行筛选,考虑因素包括数据覆盖范围、数据更新频率、数据准确性、价格、服务稳定性等。可以通过网络搜索、行业论坛、用户评价等途径了解不同提供商的口碑和服务质量。例如,一些知名的数据服务提供商如艾瑞咨询、QuestMobile 等,在电商数据领域具有较高的知名度和可靠性,但价格可能相对较高;也有一些专注于电商数据服务的新兴平台,可能提供更具性价比的解决方案,需要根据自身需求和预算进行综合评估。
(二)注册并申请 API 访问权限
一旦选定第三方数据服务提供商,通常需要在其平台上注册账号,并按照要求提交相关信息进行身份验证和资质审核。审核通过后,在平台上创建应用,获取 API 访问密钥(如 App Key、App Secret 等)。不同的提供商可能在申请流程和所需资料上有所差异,需严格按照其指引完成申请步骤。例如,某些提供商可能要求提供企业营业执照、应用使用场景说明等资料,以确保数据使用的合法性和合规性。
(三)了解 API 接口文档
仔细研读第三方数据服务提供商提供的 API 接口文档,明确接口的功能、请求参数、返回数据格式等关键信息。例如,接口可能支持通过商品 ID、关键词等参数查询商品销量数据,返回的数据格式可能为 JSON 或 XML。了解这些细节对于正确调用 API 接口、准确获取所需数据至关重要。在接口文档中,还会包含关于请求频率限制、错误码说明等内容,需要一并关注,以便在开发过程中做好相应的处理。
(四)调用 API 接口获取数据
以 Python 为例,使用requests库发送 HTTP 请求调用第三方 API 接口,示例代码如下:
import requests
import json
# 第三方API接口地址
api_url = "https://api.thirdparty.com/taobao/sales"
# 你的API访问密钥
app_key = "your_app_key"
app_secret = "your_app_secret"
# 商品ID
product_id = "654321"
params = {
"app_key": app_key,
"product_id": product_id,
"sign": generate_sign(app_key, app_secret, product_id) # 假设需要签名,需按照提供商要求生成签名
}
response = requests.get(api_url, params = params)
if response.status_code == 200:
data = json.loads(response.text)
sales = data.get('sales', "未找到销量数据")
print("商品销量:", sales)
else:
print("请求失败,状态码:" + str(response.status_code))
def generate_sign(app_key, app_secret, product_id):
# 按照第三方提供商规定的签名算法生成签名
# 例如,可能是将app_key、app_secret、product_id等参数拼接后进行MD5加密
sign_str = app_key + app_secret + product_id
import hashlib
sign = hashlib.md5(sign_str.encode('utf - 8')).hexdigest()
return sign
在上述代码中:
- 构建请求参数:根据 API 接口文档要求,将必要的参数(如 API 密钥、商品 ID 等)组装成params字典。若接口需要签名认证,还需按照特定算法生成签名并添加到参数中。
- 发送请求并处理响应:使用requests.get()方法发送 GET 请求到 API 接口地址,将返回的 JSON 格式数据解析为 Python 字典,从中提取商品销量数据并进行输出。若请求失败,则打印错误状态码,以便排查问题。
四、与淘宝 / 天猫合作获取商品销量数据的要点
(一)确定合作需求和目标
在寻求与淘宝 / 天猫合作之前,明确自身的数据需求和合作目标。例如,是为了进行深度的市场分析以优化产品策略,还是为了实现精准的营销推广等。清晰的需求和目标有助于在与平台沟通合作时,准确表达自身诉求,提高合作的针对性和成功率。同时,也便于评估合作方案是否符合自身业务发展的需要。
(二)联系平台商务团队
通过淘宝 / 天猫开放平台的官方渠道,查找并联系其商务合作团队。一般在平台的官方网站上会有关于商务合作的联系方式或指引。在与商务团队沟通时,详细介绍自己的企业背景、业务规模、合作意向以及能为平台带来的价值等信息。展示自身的实力和诚意,增加平台对合作的兴趣和认可度。例如,作为大型品牌商,可以强调自身的品牌影响力、市场份额以及在电商领域的创新实践等优势。
(三)商讨合作方案和数据权限
与平台商务团队就合作细节进行深入商讨,包括合作模式(如数据购买、联合项目等)、数据使用范围、数据安全保障措施、费用等方面。对于商品销量数据的获取权限,明确可获取的数据字段(如总销量、月销量、不同时间段销量等)、数据更新频率、数据使用期限等关键内容。在商讨过程中,充分考虑自身业务需求和平台的规定,寻求双方都能接受的平衡点。例如,若业务对实时销量数据有较高要求,可与平台协商提高数据更新频率,但同时可能需要支付更高的费用或满足更严格的数据安全要求。
(四)签订合作协议并遵守规定
在达成合作意向后,与平台签订正式的合作协议。协议中会明确双方的权利和义务、数据使用规则、违约责任等重要条款。务必仔细阅读协议内容,确保自身权益得到保障的同时,严格遵守协议规定。例如,按照协议要求对获取到的数据进行妥善存储和使用,防止数据泄露或滥用;在数据使用期限到期后,及时停止使用相关数据等。违反合作协议可能导致合作终止,并面临法律风险。
通过以上对获取淘宝天猫商品销量数据的多种方法及相关技术细节的介绍,希望能帮助开发者和数据分析师在电商数据领域更好地开展工作,为业务决策提供有力的数据支持。在实际操作过程中,需根据自身情况选择合适的方法,并严格遵守法律法规和平台规则,确保数据获取和使用的合法性与合规性。
如果你在实践过程中遇到具体问题,或者希望我针对某一种方法展开更深入的讲解,欢迎随时跟我说。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









