






向量化执行技术因其高效的批处理数据的能力,在分析型查询中能显著提升执行性能。OceanBase 3.2版本虽已引入向量化执行引擎,但默认状态下并未启用。自OceanBase 4.0版本起,该引擎已默认开启。在最新的OceanBase 4.3版本中,推出了向量化引擎2.0,通过对数据格式、 算子、表达式以及计算下压存储引擎进行优化,进一步明显提升了其执行性能。
向量化引擎2.0实现
数据格式优化
向量化数据格式优化是向量化引擎2.0核心改进点, 向量化引擎1.0实现中,存储层数据投影后, 某列表达式一批数据在内存中的组织格式, 是由多个连续数据描述单元及实际数据组成, 每个数据描述单元中, 均包含null描述, 数据长度len及数据指针ptr, 实际数据值并不在数据单元描述中,而是存在ptr指向的地址, 对于定长数据, 存在以下几个问题:
- 读写访问不够高效。每次访问(读/写)都需要先获取数据描述单元,然后通过数据描述单元中ptr访问数据,不能直接访问数据。
- 内存使用更多。比如存放N行int32_t数据,数据描述单元结构占12个字节,从而总共需要N * (12+4)字节,而实际数据只有N * 4个字节, 空间会放大4倍,导致内存访问、数据物化和数据shuffle时开销均更高。
- SIMD计算不够友好。 一批数据对应的实际数据不一定连续存放,对SIMD的使用不够友好。
- 序列化/物化开销更多。在进行数据序列化和数据物化时,需要进行指针的swizzling,即将指针转换为相对偏移。
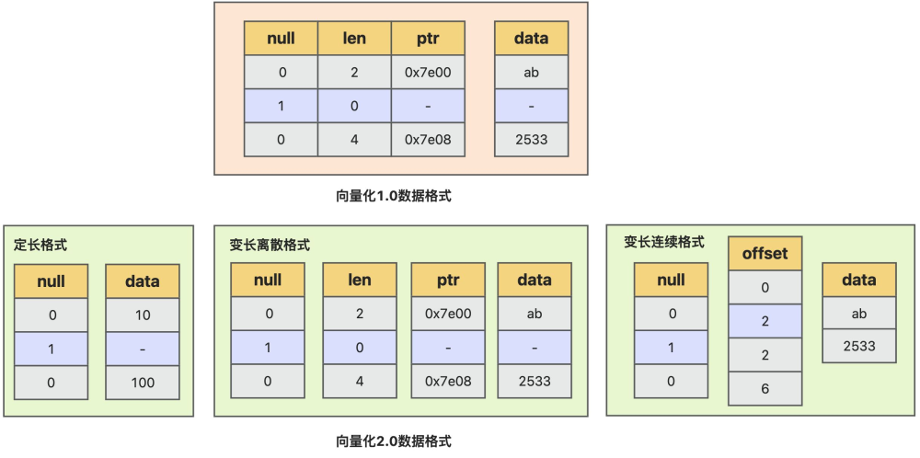
为优化向量化1.0数据格式带来的以上不足,向量化引擎2.0中,实现了新的按列的数据格式。将数据描述信息null, len, ptr信息, 分别按列的方式, 分开连续存放, 避免数据信息冗余存储, 针对不同数据类型和使用场景, 实现了3种数据格式: 定长数据格式、 变长离散格式、变长连续格式:
- 定长数据格式,只需要null bitmap和连续的数据信息, length信息, 只需要存放一份length值, 不需要一批数据中每个数据冗余存放相同值, 也不再需要间接访问的指针信息。相比以前向量化1.0数据格式, 数据信息没有冗余存放,更加节省空间; 可以直接访问, 并且访问数据局部性更好; 数据能确保连续存放,对于SIMD使用也更友好; 此外在进行物化及序列化时,不需要对数据进行指针的swizzling操作, 效率更高。
- 变长离散格式是指一批数据中, 每个数据在内存中存放可能是不连续的, 每个数据使用数据地址指针和长度描述, 长度信息和指针信息, 分别按列的方式连续存放; 使用这种格式, 存储层如果是编码数据, 投影时不需要深拷贝数据, 只需要投影len和ptr信息, 并且对于短路计算场景, 一批数据可能仅计算其中几行, 这时也可以使用该格式描述并且不需要重整数据。
- 变长连续格式是指数据是连续存放在内存中的, 每个数据的长度信息和偏移地址, 使用offset数组描述, 该描述格式, 相比离散格式, 在数据组织时, 需要确保数据连续, 对数据访问和数据按批copy效率更高, 不过对于短路计算场景及列存编码数据投影不是很友好, 需要对数据进行数据重整及深拷贝, 当前该格式主要用于按列物化场景。
算子及表达式性能优化
向量化引擎2.0, 对算子及表达式实现进行了全面优化, 主要优化思路是基于新的格式, 使用batch数据属性信息、算法数据结构优化及特化实现, 从而减少CPU数据Cache Miss, 降低CPU分支预测错误及CPU指令开销, 提升整体执行性能; 向量化2.0 将Sort、Hash Join、Hash Group By、数据Shuffle、聚合计算等算子和表达式按新格式进行了重新设计与实现,整体计算性能全面提升;
- 利用batch数据属性信息
向量化引擎2.0, 维护了执行过程中过程中, batch数据的特征信息, 包括是否不存在null, 是否batch中行均不需要被过滤等信息, 利用这些信息, 可大大加速表达式计算, 比如NULL如果不存在, 则表达式计算过程中不需要考虑对NULL的特殊处理, 如果数据行均没有被过滤, 则不需要计算时每行去判断是否已经被过滤, 并且数据是连续的, 没有被过滤, 对使用SIMD计算也更友好;
- 算法及数据结构优化
在算法及数据结构优化方面, 实现了更加紧凑的中间结果物化结构, 支持按行/列物化数据, 空间更省, 访问也更更加高效; Sort算子实现了sort key与非sort key分离物化,结合对sort key保序编码(将多列数据编码为1列, 可直接使用memcpy进行比较), Sort在比较过程中访问数据Cache Miss更低, 比较计算本身更快, 整体排序效率更高; HashGroupBy 对Hash表结构均进行了优化, HashBucket中数据存放更加紧凑, 并对低基数Group Key使用ARRAY优化, 分组及聚合结果内存连续存放等优化等;
- 特化实现优化
特化实现优化, 主要是利用模版, 针对不同场景, 进行更加高效的实现, 比如Hash Join特化实现了将多列定长join key编码为一个定长列,并且将join key数据放入到bucket中, 对数据预期也进行了优化, 减少了多列数据访问时数据Cache Miss; 支持聚合计算特化实现, 不同的聚合计算进行特化分开实现, 从而减少每次计算聚合函数指令及分支判断, 执行效率大幅提升;
存储向量化优化
存储层全面支持新的向量化格式,对于投影、谓词下压、聚合下压和groupby下压更多地使用SIMD。投影定长和变长数据时,按列类型、列长度,以及是否包含null等信息定制化模板,按批浅拷投影。计算下压谓词时,对于简单的谓词计算,直接在列编码上进行;复杂的谓词,投影成新向量化格式在表达式上按批计算。聚合下压充分利用了中间层的预聚合信息,如count、sum、max、min等。groupby下压则利用充分利用编码数据信息,对于字典类型的编码,加速效果非常明显。
向量化引擎2.0使用说明
支持向量化1.0和2.0算子混跑
当前支持向量化引擎2.0的算子包括:Hash Join、Hash Group By、AGGR、Hash Distinct、Sort、PX框架相关算子、Exchange、RunTime Filter相关算子、TempTable相关算子、Material、SubplanScan、Limit、TableScan。对于其他不支持的算子,会使用向量化引擎1.0执行, 同一个计划中,支持向量化1.0算子和向量化引擎2.0算子混合一起执行,具体不支持向量化引擎2.0的算子对应语句类型如下:
- 所有 DML 语句
- CTE
- Connect By
- 集合类语句
- window function
- Union
- 聚合语句(使用 Merge 算法时)
- JOIN 语句(使用 NLJ 算法时)
- Distinct 语句(使用 Merge 算法时)
- 关联子查询(无法改写,只能使用 subplan filter驱动执行时)
- Pivot、Unpivot 语句
- DBLink
- 使用 Sequence 对象
如何观测是否使用向量化引擎2.0
通过查看物理算子名称(GV$SQL_PLAN_MONITOR.PLAN_OPERATION及GV$OB_PLAN_CACHE_PLAN_EXPLAIN.OPERATOR),可确定是否使用了向量化引擎2.0算子,如果使用了向量化引擎2.0算子,则算子名称上有 VEC_字样。
向量化引擎2.0性能表现
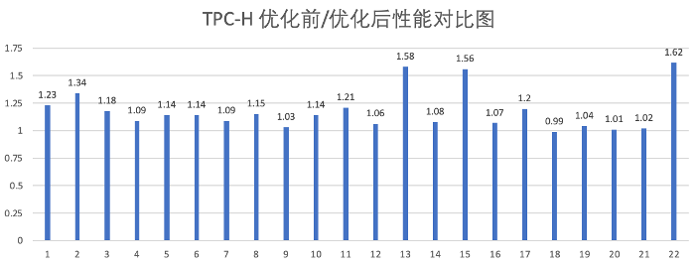
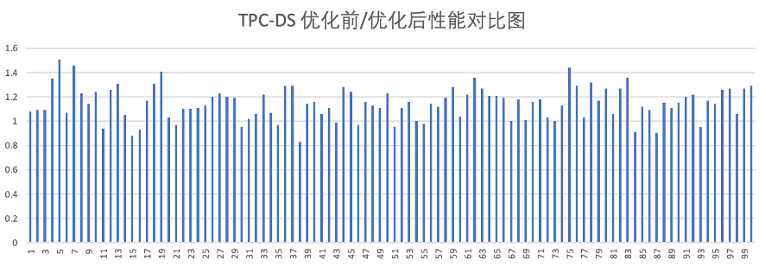
对比向量化引擎1.0, 向量化引擎2.0实现性能整体提升情况如下:
- ClickBench整体性能提升30%;
- TPC-H 68% query 存在10%~40%提升;
- TPC-DS 56%的query 存在10%~40%提升;

总结
向量化引擎2.0通过对数据格式、 算子、表达式以及计算下压存储引擎实现优化,更进一步挖掘了SIMD计算、特化实现及按批访问和处理数据等带来的性能提升,使OceanBase能够更快地处理AP场景的SQL请求。OceanBase向量化引擎的优化工作还在继续,后续版本将在性能方面取得更多突破, 也期待和对向量化引擎优化感兴趣的同学一起交流。
















 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









