







Scrapy中使用selenium
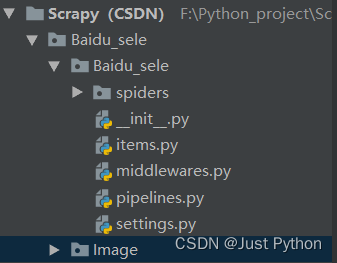
middlewares.py
在middlewares.py中自定义一个中间件
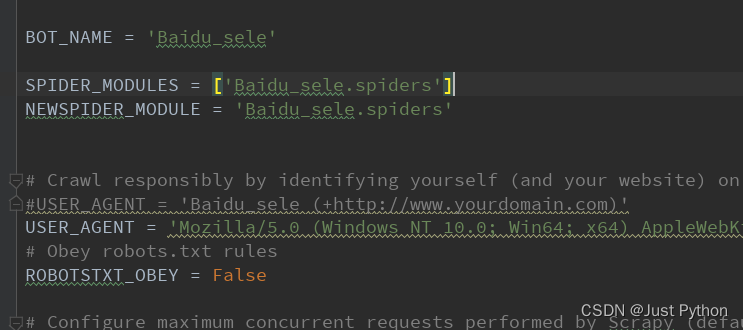
特别注意导入的模块:from scrapy.http import HtmlResponse
from selenium import webdriver
import time
from scrapy.http import HtmlResponse
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
class SeleniumMiddleware:
def process_request(self, request, spider):
driver.get('https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111110&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E8%8A%B9%E8%8F%9C&oq=%E8%8A%B9%E8%8F%9C&rsp=-1')
time.sleep(2)
# 循环滚动
for i in range(2):
driver.execute_script('document.documentElement.scrollTop=10000')
# sleep让滚动条反应
time.sleep(0.5)
# 获取网页源码
text = driver.page_source
return HtmlResponse(
url=request.url,
body=text,
request=request,
encoding='utf-8',
status=200
)
settings.py
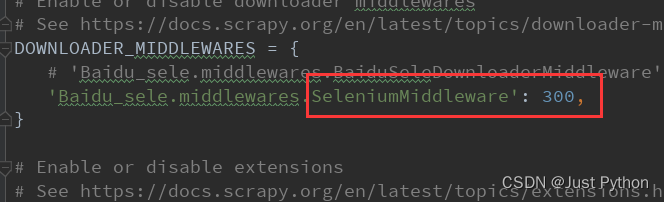
bai_sele,py
注意:不要注释掉 allowed_domains、start_urls
import scrapy
from lxml import etree
import requests
class BaiSeleSpider(scrapy.Spider):
name = 'bai_sele'
allowed_domains = ['image.baidu.com']
start_urls = ['https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111110&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E8%8A%B9%E8%8F%9C&oq=%E8%8A%B9%E8%8F%9C&rsp=-1']
def parse(self, response):
# 获取每一个照片的跳转连接,并拼接链接
img_link = response.xpath('//div[@class="imgbox-border"]/a/@href').getall()
# 构建请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
# 循环拼接跳转链接,并发送请求
for index in range(len(img_link)):
url1 = 'https://image.baidu.com' + img_link[index]
# 对图片跳转链接发送请求
res1 = requests.get(url1, headers=headers)
# 转换成html元素
html = etree.HTML(res1.text)
# 获取图片url
url2 = html.xpath('//div[@id="srcPic"]/div/img/@src')[0]
# 向链接发送请求
res = requests.get(url2, headers=headers)
with open(f'F:/Python_project/Scrapy(CSDN)/Baidu_sele/Image/{"芹菜" + str(index)}.jpg', 'wb') as f:
f.write(res.content)
















 898
898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











