







✨前言
📢首先祝大家假期愉快🚀
这个假期,大家是怎么玩的呢❓
小博主我趁着假期也摆了几天😜
因此有好几天没有更新文章了……

今天偷偷的发一篇文章,浅浅做个样子吧😬
今儿写的文章是继上次写的:
这些好看的皮肤,这不嗖的一下,统统都到电脑里了~
嗖的一下系列的更新💨
主要实现的是多线程获取LOL英雄皮肤图片
👉话不多说,直接开始👇
🎮代码实现
import requests
import json
from jsonpath import jsonpath
import os
import threading
# 获取英雄基本信息
def get_info():
# 英雄列表链接
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?ts=2774774'
# 发送请求,并将html转为json格式
json_data = json.loads(requests.get(url, headers=headers).text)
# 获取英雄名
name = jsonpath(json_data, '$..name')
# 获取英雄id
heroID = jsonpath(json_data, '$..heroId')
return name, heroID
# 获取英雄皮肤
def get_skin(name, heroID):
# 创建对应英雄文件
file_path = f'./lol英雄皮肤/{name}'
if not os.path.exists(file_path):
os.makedirs(file_path)
n = 0
while True:
# 拼接链接
url = f'https://game.gtimg.cn/images/lol/act/img/skin/big{int(heroID)*1000+n}.jpg'
res = requests.get(url, headers=headers)
if res.status_code == 200:
with open(f'{file_path}/{name}-{n}.jpg', 'wb') as f:
f.write(res.content)
else:
break
n += 1
print(f'{name} 皮肤下载完成')
if __name__ == '__main__':
if not os.path.exists('./lol英雄皮肤'):
os.makedirs('./lol英雄皮肤')
# 构建请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
# 调用获取英雄名和id的函数
name, heroID = get_info()
threads = []
for i in range(len(name)):
t = threading.Thread(target=get_skin(name[i], heroID[i]))
threads.append(t)
for t in threads:
t.start()
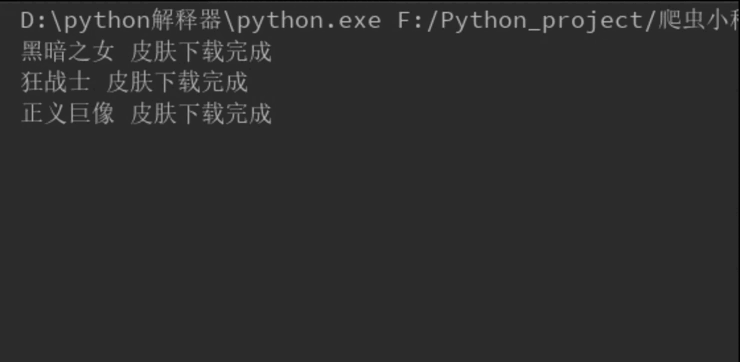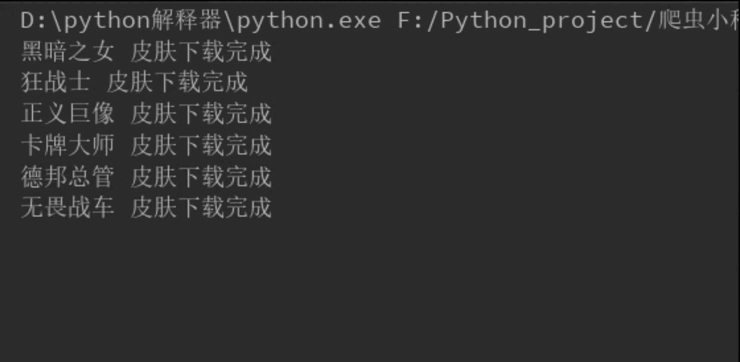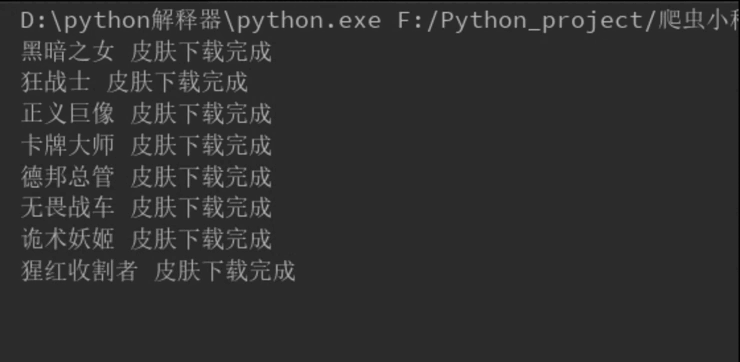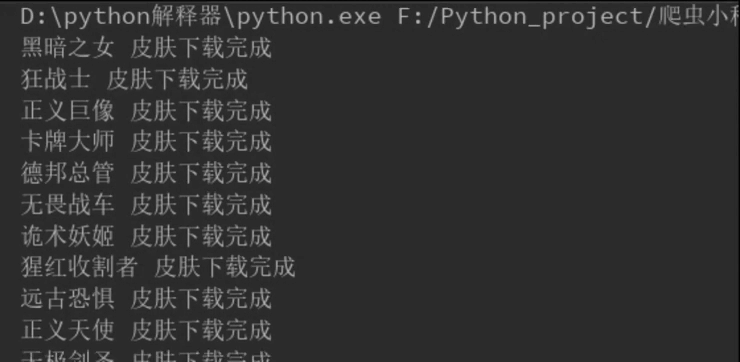
- 实现效果




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











