







 本文介绍了Python爬虫中BeautifulSoup4(bs4)的基础知识,包括其作用、安装方法以及如何查找和提取网页数据。通过一个实例展示了如何利用bs4爬取优美图库的图片,包括获取页面源码、解析子页面链接和下载图片的步骤。
本文介绍了Python爬虫中BeautifulSoup4(bs4)的基础知识,包括其作用、安装方法以及如何查找和提取网页数据。通过一个实例展示了如何利用bs4爬取优美图库的图片,包括获取页面源码、解析子页面链接和下载图片的步骤。
Python爬虫:bs4解析
html语法
<标签 属性=“值” 属性=“值”>
被标记内容
</标签>
什么是bs4
bs4全称:beautifulsoup4,可以解析和提取网页中的数据,但需要使用特定的一些语法
bs4安装
pip install bs4
从bs4中查找数据的方法
1.find(标签,属性=值) 查找一个
举例:find(“table”,id=“3”) 查找一个id=3的内容,相当于查找一个html中<table id="3">xxxxx<table/>
2.find_all(标签,属性=值) 和find用法一致,只是能够用于查找所有值。
bs4的基本使用
使用bs4对数据进行解析主要通过两个步骤
1.把页面源代码交给beautifulsoup进行处理,生成bs对象
page = BeautifulSoup(resp.text,“html.parser”)
html.parser用来指定html解析器,相当于告诉bs4我提供的内容就是属于html内容的。
2.从bs对象中查找数据
page.find("table",class_="hq_table")
由于class是python的关键词,如果想要查找class是html中的class关键词,bs4提供一种方式区分python关键字和html关键字:可以在class的后面加“_”。
同样可以采用另一种写法来区别关键字:
page.find("table",attrs={"class":"hq_table"})
3.拿取数据
使用.text获取数据字段
例如:name = tds[0].text
实例:使用bs4爬取优美图库图片
思路
1.拿到主页面的源代码,然后提取到子页面的链接地址href
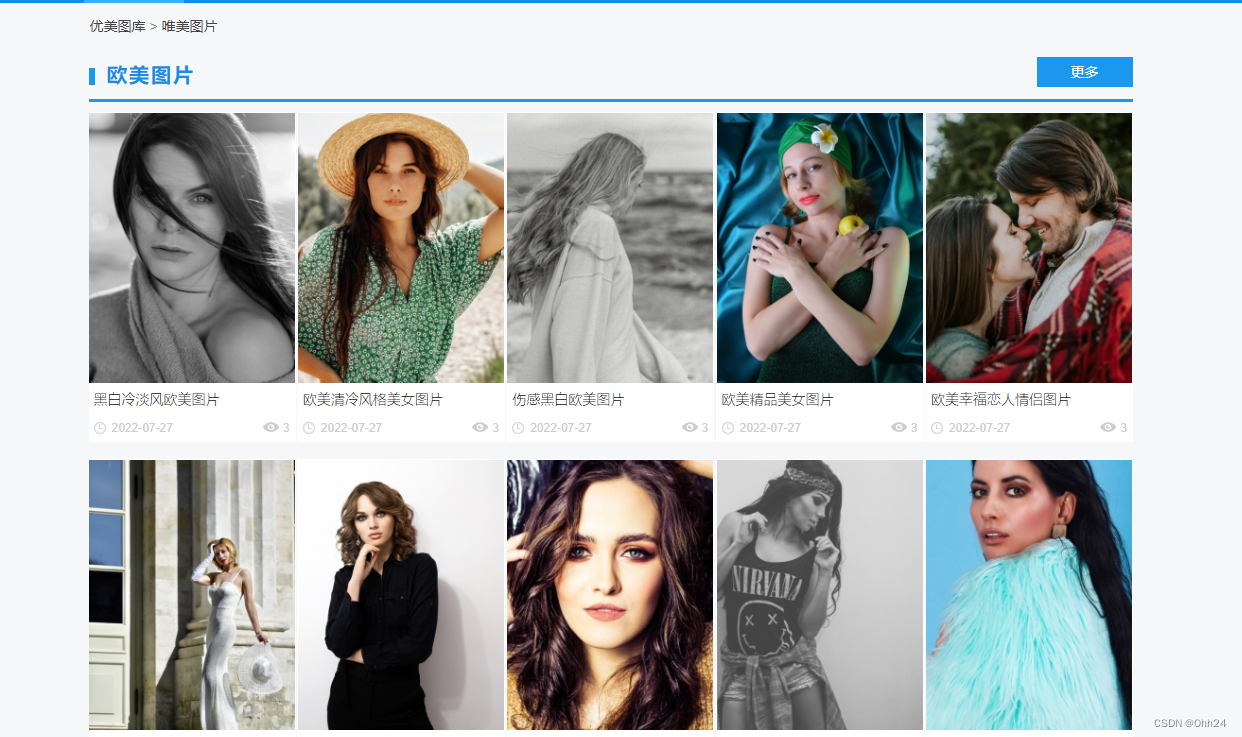
在网页中查看源代码,先搜索关键词“黑白冷淡风欧美图片”,发现源代码中可以找到相应结果,说明该网页是属于服务器渲染。

2.通过href拿到子页面的内容,从子页面中找到图片的下载地址
通过上述的源代码,可以找到href定位到该图片的子页面
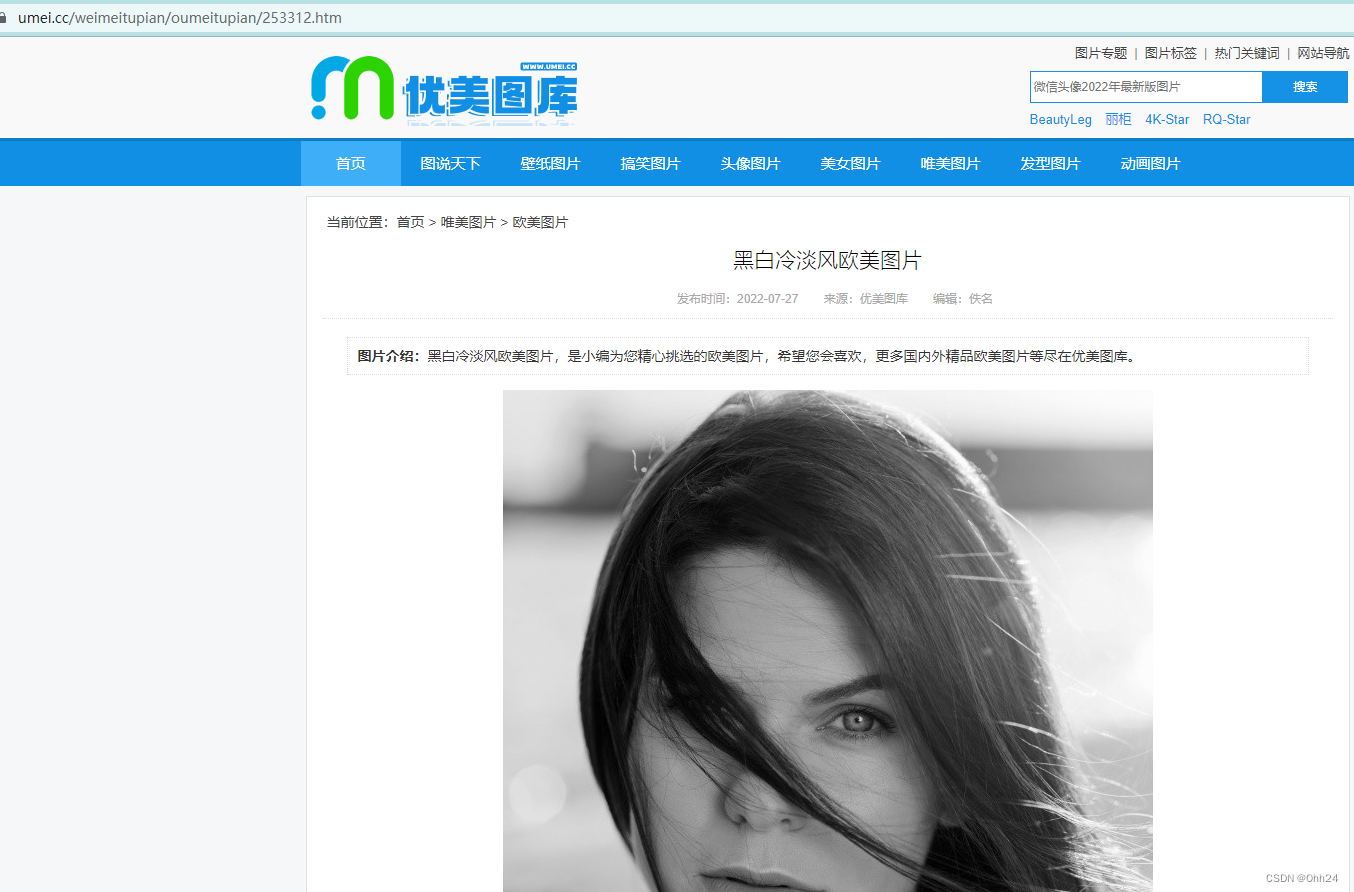
在子页面中查看源代码,发现该图片的下载地址(img -&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









