







项目需求:
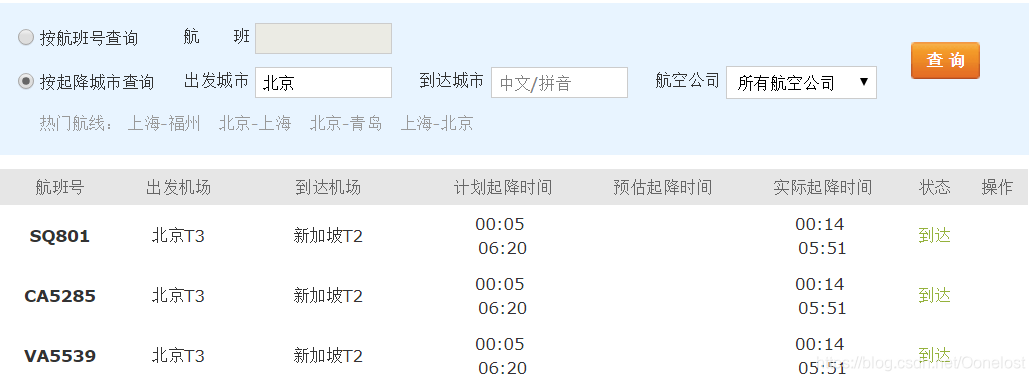
- 因为数学建模比赛数据统计分析,需要得到某机场一天所有航班实际的起降时间
代码分析:
- 以离开北京机场为例,到达北京机场的时间同理
from pyquery import PyQuery as pq
# 打开「depart.txt」文件,方便数据的存入
fout = open('E:/depart.txt', 'w', encoding='utf8')
# 此处url必须写全 https://flights.ctrip.com/actualtime/depart-bjs.p1/ 出发的链接
#当日共有59页数据
for i in range(1,59):
cpage = 'https://flights.ctrip.com/actualtime/depart-bjs.p' + str(i) + '/'
# 获取当前链接的页面结构给d
d = pq(url=cpage)
for i in range(20): #每页有20行数据
datarow = d('.bg_0').eq(i).html() # 根据.bg_0属性获取第i行的结构
ddata=pq(datarow)
#到达时间为第四列,replace()函数为了文件的格式化
fout.write(ddata('td').eq(3).text().replace("\n"," ")) # 写入文件内容
fout.write("\n")
# 关闭文件
fout.close()
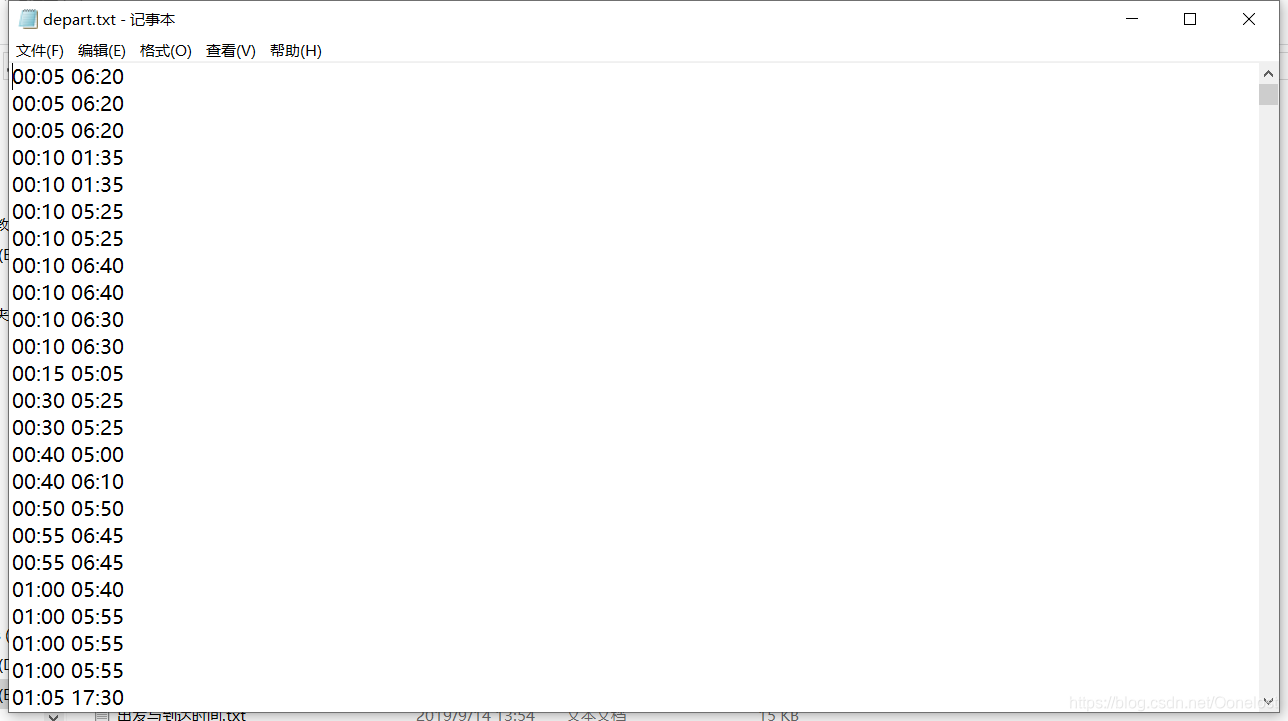
测试结果:
知识拓展
PyQuery库介绍
- PyQuery库也是一个非常强大又灵活的网页解析库,PyQuery 是 Python 仿照 jQuery 的严格实现。
- 官方文档:官方文档链接
PyQuery库使用
- 初始化(可加载一段HTML字符串,或一个HTML文件,或是一个url地址)
from pyquery import PyQuery as pq
#字符串初始化
doc = pq("<html><title>hello</title></html>")
#URL初始化,此处url必须写全
doc = pq(url="http://www.baidu.com",encoding='utf-8')
#文件初始化
d = pq(filename=‘path_to_html_file’)
- html() 和 text() ——获取相应的HTML块或文本块
p = pq("<head><title>hello</title></head>")
p('head').html() # 返回<title>hello</title>
p('head').text() # 返回hello
- 根据HTML标签来获取元素
d = pq('<div><p>test 1</p><p>test 2</p></div>')
d('p') # 返回[<p>,<p>]
print d('p') # 返回<p>test 1</p><p>test 2</p>
print d('p').html() # 返回test 1
#注意:当获取到的元素不只一个时,html()、text()方法只返回首个元素的相应内容块
- eq(index) ——根据给定的索引号得到指定元素
#接上例,若想得到第二个p标签内的内容,则可以:
print d('p').eq(1).html() # 返回test 2
- 直接根据类名、id名获取元素
d = pq("<div><p id='1'>test 1</p><p class='2'>test 2</p></div>")
d('#1').html() # 返回test 1
d('.2').html() # 返回test 2
- 获取属性值与修改属性值
#获取属性值:
d = pq("<p id='my_id'><a href='http://hello.com'>hello</a></p>")
d('a').attr('href') # 返回http://hello.com
d('p').attr('id') # 返回my_id
#修改属性值:
d('a').attr('href', 'http://baidu.com')
- 返回后面全部的元素块:nextAll(selector=None)
d = pq("<p id='1'>hello</p><p id='2'>world</p><img scr='' />")
d('p:first').nextAll() # 返回[<p#2>, <img>]
d('p:last').nextAll() # 返回[<img>]
- 获取子元素与父元素
# children(selector=None) ——获取子元素
d = pq("<span><p id='1'>hello</p><p id='2'>world</p></span>")
d.children() # 返回[<p#1>, <p#2>]
d.children('#2') # 返回[<p#2>]
#parents(selector=None)——获取父元素
d = pq("<span><p id='1'>hello</p><p id='2'>world</p></span>")
d('p').parents() # 返回[<span>]
d('#1').parents('span') # 返回[<span>]
d('#1').parents('p') # 返回[]














 2263
2263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









