







多模态大模型(MLLMs)在视觉、语言理解等领域展现出强大的能力,但如何让这些模型更好地对齐人类偏好,生成更符合人类认知习惯的内容,仍然是一个核心挑战。近日,上海人工智能实验室联合团队发布了最新研究成果 OmniAlign-V,针对这一问题提出了新的数据集和评测基准。
核心贡献
1.探索多模态训练对对齐能力的影响
探索了语言数据和多模态数据对多模态大语言模型的语言能力以及多模态客观/主观指标的影响,发现:
-
高质量语言数据的加入并不能增强多模态模型的对齐能力,还会降低通用视觉问答(General VQA )任务上的性能。
2. 提出 OmniAlign-V-SFT 数据集
-
包含 205k 开放式问题,涵盖知识性、创造性问题,并提供完备的长输出回答。覆盖自然图像和信息图像在内的九种任务。
-
通过精心设计的 Prompt Pipeline 确保问题质量和多样性。采用 GPT-4o 生成数据,结合多步后处理,提升数据质量。
-
实验表明,在 LLaVA-Next 框架下,OmniAlign-V-SFT 数据集能够大幅提升模型回复的完备性。同时,在 General VQA 任务(特别是 MMVet/MMMU)上模型效果提升显著。
3. 提出 OmniAlign-V-DPO 数据集
-
基于 OmniAlign-V-SFT 数据集构建,可进一步提升模型主观能力,优化人类偏好对齐。
-
经过实验验证,该数据集能够在大规模训练的 MLLMs(如 InternVL2-8B)上激发模型潜力,显著增强其对齐能力。
4. 提出 MM-AlignBench 评测基准
-
专注于 MLLMs 人类偏好对齐能力评测
-
包含 252 道人工筛选的开放式问题,确保数据多样性、准确性和合理性。
目前该项工作的论文、代码、SFT数据、DPO数据,Benchmark,Checkpoints、均已完全开源。
Paper:
[2502.18411] OmniAlign-V: Towards Enhanced Alignment of MLLMs with Human Preference
GitHub:
https://github.com/PhoenixZ810/OmniAlign-V
MM-AlignBench 现已在司南评测社区集上线,欢迎大家使用。
https://hub.opencompass.org.cn/dataset-detail/MM-AlignBench
MM-AlignBench 现已集成至多模态大模型开源评测工具 VLMEvalKit 中,欢迎大家使用。
https://github.com/open-compass/VLMEvalKit
探索实验
多模态训练是否影响语言能力?
研究团队对多个主流开源 MLLMs 在纯语言对齐基准(AlignBench/AlpacaEval2/ArenaHard) 上进行了测试,结果发现经过多模态训练的模型语言能力出现严重退化,这表明多模态数据训练可能削弱 LLM 本身的语言能力。
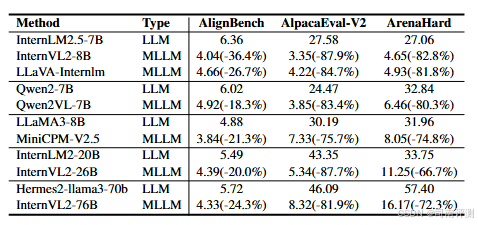
得分由 Qwen2.5-72B 进行 judge
语言数据能否改善多模态模型的对齐能力?
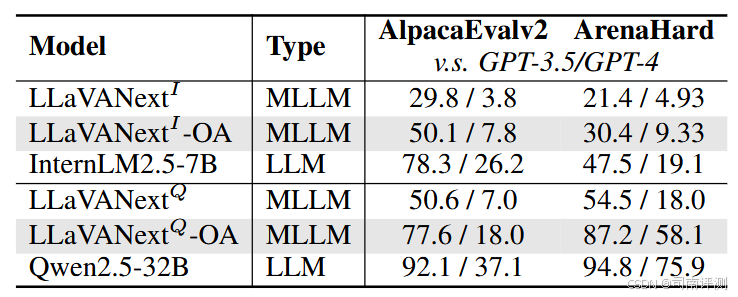
团队进一步实验,使用 LLaVA 框架,并用 InternLM2.5-7B 作为基础模型,采用 LLaVANext-780k 高质量数据,并替换其中的 ShareGPT 数据为更新的 Magpie-LLaMA3.3 和 Condor,在语言对齐基准(AlignBench/AlpacaEval2/ArenaHard)、多模态对齐基准(WildVision)以及 General VQA 基准(MMVet/MMBench/AI2D/OCRBench)上进行评测。
结果表明:
-
加入了高质量的语言数据之后,模型在语言基准上的能力确实提升了,但是,无论是多模态主观对齐还是 General VQA 任务,都出现了性能下降的情况。
-
语言数据对多模态对齐能力的影响是十分有限的,在 General VQA 任务以外,仍然需要带有开放式问题以及完备回答的多模态训练数据。

为了展示性能差异,此处 AlpacaEval2 和 Arenahard 的结果均与 GPT3.5 进行对比
OmniAlign-V 数据构建
OmniAlign-V-SFT 数据集
基于上述实验观察,研究团队认为,当前的多模态数据过于看重 VQA 任务的能力,因此数据面临答案过于简短、单一,缺少对预训练知识的运用与理解的问题。
再结合从纯语言数据组成中吸取的经验,研究团队提出多模态数据还应包含以下特点:
-
开放式,创造性,需要预训练知识的问题。
-
全面,完备,美观,符合指令跟随的回答。
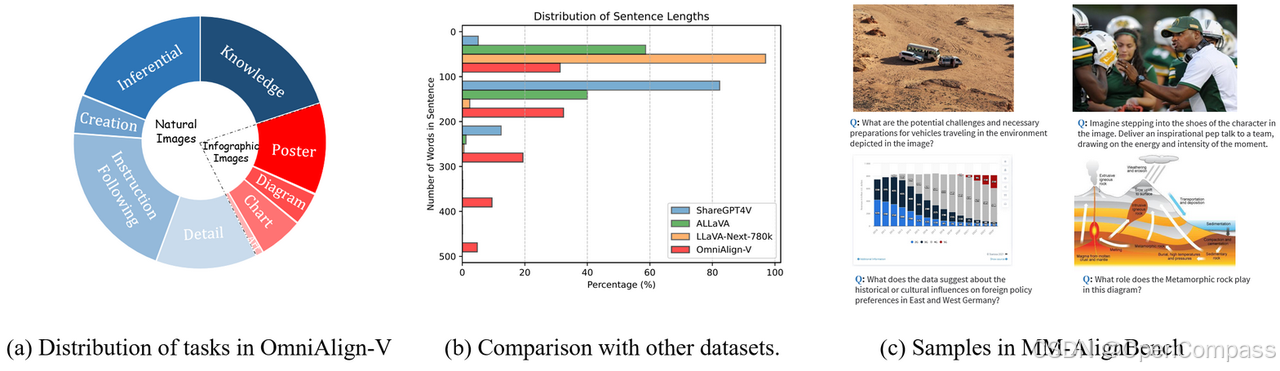
基于以上原则,研究团队提出了 OmniAlign-V 数据构建 Pipeline,如下图所示:

Pipeline of OmniAlign-V
研究团队根据图片场景将图片分为自然图片(Natural)和信息图片(Infographic)两大类,为了得到包含丰富信息的数据,
首先,对自然图片进行了图像复杂度以及物体种类数目的两轮筛选,确保筛选出的图片具有丰富的语义信息。
其次,将自然图片分为 Knowledge/Creation/Inferential 三类任务,将信息图片分为 Chart/Diagram/Poster/Art 四类任务,对不同任务分别应用对应的精心设计的 Pipeline 以及 GPT-4o 生成的对话数据。
而后,再对 Knowledge/Inferential/Chart 分别应用不同的后处理优化,增强了 Inferencial 和 Chart 数据的完备性和准确性,并在 Knowledge 基础上额外添加了 Instruction-Following 指令,将其作为 Instruction-Following 任务。(具体的操作步骤可以参考论文)
最终,得到了 OmniAlign-V-SFT 数据集,包含了 205k 高质量的多模态数据。
OmniAlign-V-DPO 数据集
研究团队发现 OmniAlign-V-SFT 数据集的回答质量较高,非常适合作为 DPO 训练的 正样本(positive sample)。因此,团队对 LLaVANext-InternLM2.5-7B 模型输出应用 reject sampling,生成对应的 负样本(negative sample),由此构建 OmniAlign-V-DPO 数据集,用于进一步优化模型的主观对齐能力。
MM-AlignBench 对齐基准
另外,研究团队发现当前多模态模型对齐基准存在 图像质量低、问题模糊、任务多样性不足 等问题。因此提出 MM-AlignBench,作为专门评估 MLLMs 对齐能力的基准。
从经过预筛选的 3000+ 张图片中人工挑选了 252 张分布多样且高质量的图片,每张图片以及对应的问题都经过人工审查,确保图片和任务问题的多样性以及准确性、合理性。
效果验证
SFT 训练带来的提升
研究团队在 LLaVA/LLaVA-Next 框架下,分别使用 InternLM2.5-7B/Qwen2.5-32B 进行实验,并在 3 个多模态对齐基准和 5 个主流 VQA 基准 上进行了评测。

SFT 多模态评测结果
可以看出:
-
在添加了 OmniAlign-V-SFT 数据集后,模型在 3 个多模态对齐基准上的表现均有大幅提升;
-
在多个 General VQA Benchmark 上均有不同程度的涨点,尤其是在 MMVet 和 MMMU 上涨点十分显著;
-
LLaVANext-Qwen2.5-32B 在 MMVet 和 MMMU 上分别增加了 9.2 和 5.5!这有力验证了 OmniAlign-V 数据集的有效性。
-
此外还发现,经过 OmniAlign-V-SFT 训练后,模型在语言对齐基准上也有一定程度的上涨,这也验证了,当添加部分高质量的多模态对齐数据后,能够有效减少 LLM 在多模态训练当中面临的语言能力退化问题。
SFT 语言评测结果
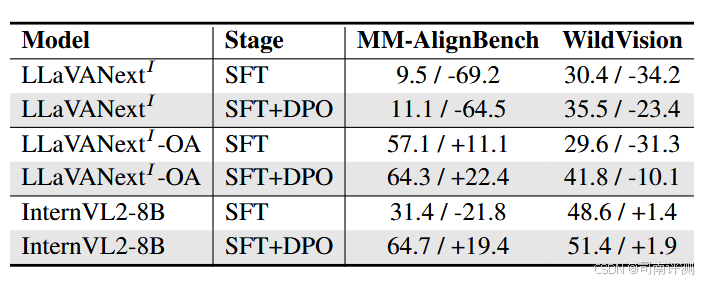
DPO 训练的效果
此外,采用 OmniAlign-V-DPO 进行 DPO 训练后,模型的对齐能力进一步增强。
-
对于未接受长上下文训练的模型,OmniAlign-V-DPO 影响较小;
-
对于经过高质量长上下文训练的模型(如 InternVL2-8B),OmniAlign-V-DPO 能够显著提升对齐能力。
DPO 实验结果
MM-AlignBench 评测表现
研究团队测试了当前主流 MLLMs 在 MM-AlignBench 上的结果:
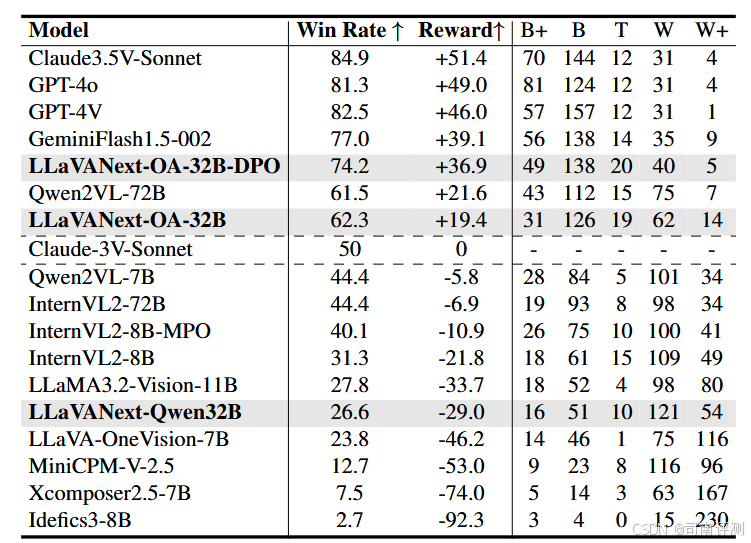
MM-AlignBench Leaderboard
-
经过 SFT+DPO 训练后,LLaVANext-OA-32B-DPO 的对齐性能提升明显,在 MMAlignBench 上的性能已经超越了QwenVL2-72B。
-
即使是 QwenVL2-72B 和 InternVL2-78B,在 MMAlignBench 上的表现距离闭源模型(GPT/Gemini/Claude Series)也有较大的差距。
MM-AlignBench 与其他基准的相关性分析
研究团队进一步对 MM-AlignBench 和其他 General VQA Benchmark 计算了相关度,SRCC score 如下所示:
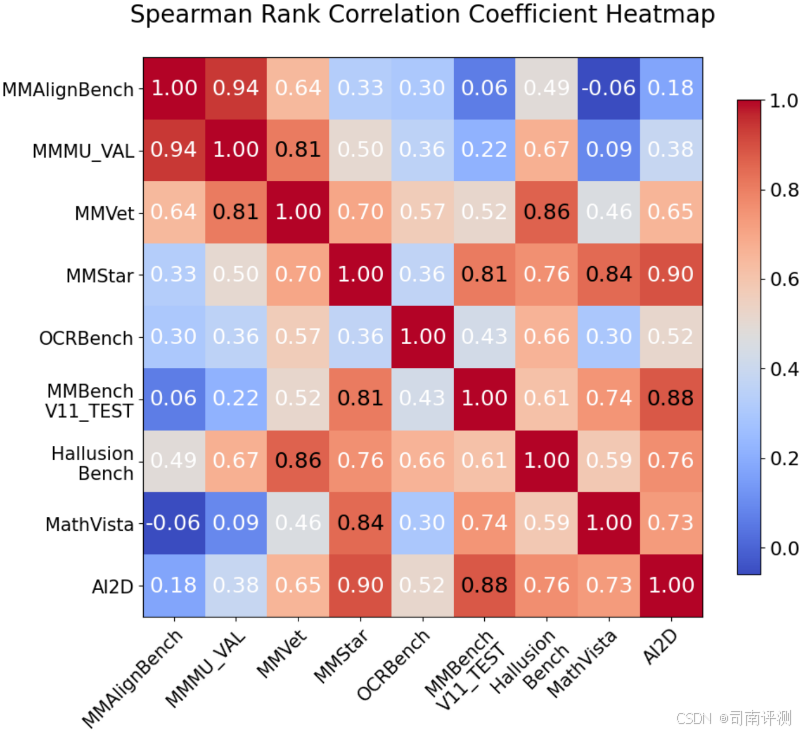
MM-AlignBench 与其他基准的相关性统计
-
MM-AlignBench 与现有多模态评测基准(如 MMBench、OCRBench)相关性较低,但 与 MMMU 表现出极高的相关性。
-
作为一项涵盖大量跨学科任务的评测基准,MMMU 对模型的知识先验深度和广度提出了极高的要求。尽管 MMMU 采用选择题形式,答案具有唯一正确解,而 MM-AlignBench 则以开放式问答为主,两者的题型设计存在显著差异,但它们所考察的核心能力却高度相似。
-
这一现象表明,MM-AlignBench 不仅覆盖了广泛的任务领域,还深入挖掘了模型在知识先验上的表现,进一步验证了其评测维度的全面性与挑战性。
上述对多模态大语言模型对齐能力的研究,也引起研究团队的思考:
究竟什么才是通向真正模态融合的正确路径?在多模态微调过程中,大语言模型往往会面临一个棘手的问题——语言能力的“灾难性遗忘”。然而,像GPT-4o 等闭源模型却能够成功实现文本与图像模态的深度融合,充分释放其庞大的预训练语言知识潜能。这背后的技术路线究竟是如何设计的?又是怎样做到如此高效且精准的模态融合的?
这些问题还待继续探索,希望本项工作能给大家带来些许启发。
欢迎大家与我探讨交流!邮箱地址:zxy2855064151@sjtu.edu.cn


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









