







具备跨模态理解能力的多模态大模型能实现更为丰富、全面的理解与生成,在复杂场景中表现得更接近人类水平,已然成为人工智能领域的重要发展方向。从图文理解、视觉问答到图像推理,模型们看似“万事通”,但真正打动人心、贴近用户需求的模型,究竟该如何评判?
近期,司南团队发布多模态主观评测榜单 OpenVLM Subjective Leaderboard,对29个国内外主流的闭源模型(如GPT-4.1-20250414、Gemini-2.5-flash等)和开源模型(如InternVL3系列、Qwen2.5-VL系列等),围绕着视觉创意写作、指令跟随、人类偏好对齐等多个维度进行了全面评测。
相比客观评测,这份榜单采用的主观评测基准更贴近用户实际使用场景,能够更好反映模型在“场景中”的综合能力。
司南榜单官网:
https://rank.opencompass.org.cn/home
多模态主观评测榜单:
https://huggingface.co/spaces/opencompass/openvlm_subjective_leaderboard
评测工具及基准
评测工具
本次评测采用 VLMEvalKit—— 一款开源的多模态评测工具,能够为社区提供可靠、可复现的评测结果,让不同多模态模型在各类任务下的性能更透明可比。
评测基准
6大评测基准,包括MMVet, WildVision, MMAlignBench, MM-IFEval, MIA-Bench及Creation-MMBench。
- MMVet:侧重于多模态模型在视觉推理和知识问答场景下的综合表现,考查模型对视觉内容的理解、推理及知识融合能力。
- WildVision: 聚焦于开放世界下的视觉理解能力,通过真实复杂环境中的图片,让模型展现面对“野外数据”时的适应性和泛化能力。
- MMAlignBench:关注模型与人类偏好的对齐能力,主要考察模型如何将不同模态信息(如图像与文本)进行有效结合,实现高质量的跨模态理解与生成。
- MM-IFEval:是一个具有挑战性和多样性的多模态指令遵循基准,包含400个问题,分为组合级问题和感知级问题,采用综合评估策略,结合了基于规则的评估和判断模型,以更精确地评估模型的指令遵循能力。
- MIA-Bench:旨在评估多模态大型语言模型严格遵循复杂指令能力的基准,包含400对图像-提示,挑战模型遵循分层指令生成准确响应的能力。
- Creation-MMBench: 突出模型在视觉创作场景中的表现,侧重评估模型的想象力、创新性以及内容生成的多样性和吸引力。采用双重评估体系,结合视觉事实性评分(VFS)和创意奖励分(Reward),避免了单一评判标准可能带来的片面性。
主要洞察
结合最新榜单数据,我们可以观察到以下趋势和细分洞察:
-
闭源模型在视觉条件下的创意创作表现突出:
-
如GPT-4.1-20250414、Gemini-2.5-flash等闭源模型,在Creation-MMBench等主观视觉创作基准上表现突出,创意性、流畅性、内容丰富度均优于多数开源模型。即使是顶尖的开源模型,目前在该方向与闭源模型仍有一定差距。
-
-
子能力表现差异明显
-
在视觉推理和知识问答方面,部分开源模型(如Qwen2.5-VL系列和InternVL3系列)已能缩小与闭源模型的差距,展现出不俗的知识推理与理解能力。
-
但在创意生成和人类偏好对齐维度,闭源模型依旧保持较大优势,更能生成贴合人类期望、富有创意的内容。
-
对于指令跟随,开闭源模型呈现出能力较为接近的态势,但针对复杂及组合类指令而言,参数量更大的模型具有更佳的表现,展现出对指令更鲁棒的理解。
-
-
客观能力表现与主观能力表现不对等
-
部分在客观榜单排名靠前的开源模型,在主观榜单中的综合体验分不及闭源模型。这表明仅凭传统客观评测难以反映模型在实际场景下的“用户满意度”,也提示后续训练应更多考虑人类反馈和场景多样性。
-
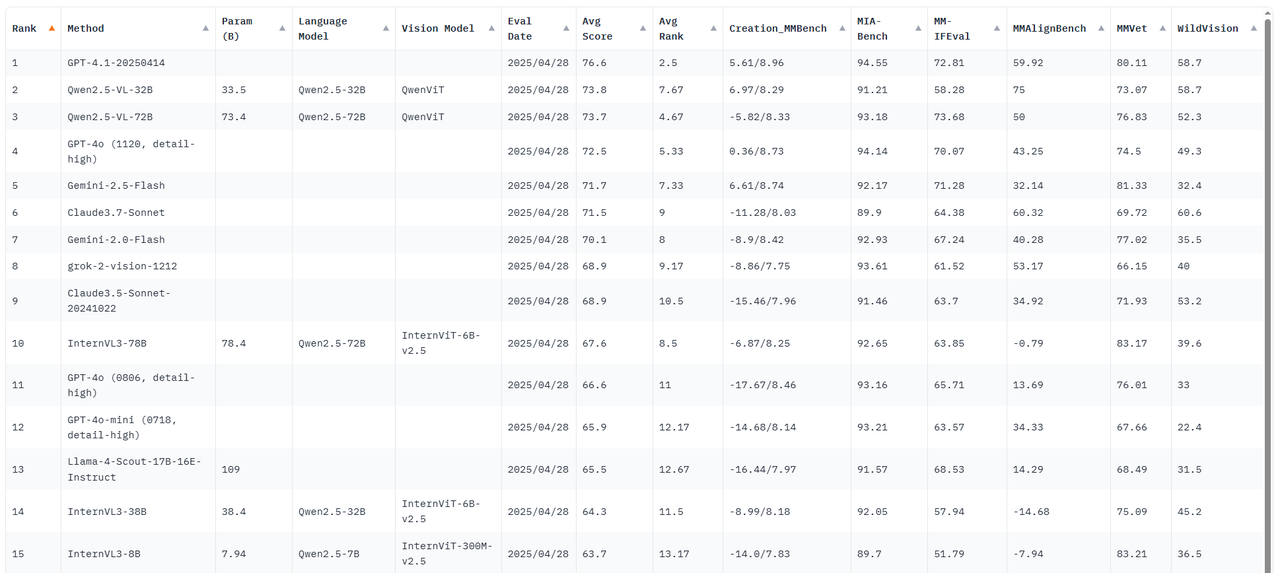
榜单部分截图
多模态大模型的评测绝不应该拘泥于传统的选择式做题,而更应该结合实际场景,针对回答的完备性、知识性、准确性、创意性等多个方面进行评估。
如何加入评测
OpenVLM Subjective Leaderboard 支持公开可用的开源或API模型,如果您想让自己的模型参与评测,请在 VLMEvalKit中创建一个 PR 以支持您的模型。
司南多模态模型特色能力榜单
精选具有影响力的多模态模型评测集,对行业内的多模态大模型进行评测,并发布基于该评测集的榜单。目前已发布的榜单还包括:
-
OpenVLM Video Leaderboard:通过视觉语言模型在MVBench、MMBench-Video等评测基准上的得分来评价视觉语言模型在视频理解任务中的表现。评测视频丰富且质量高,问答涵盖模型能力全面,更好地考察了模型的时序理解能力。
-
MMBench:评估多模态大模型在逻辑推理、属性推理、关系推理、单对象感知、多对象感知以及细粒度感知方向上的性能表现。评测基准覆盖20项细粒度能力评估,包含约3000道题。
-
VBench:评估视频生成模型在主体一致性、背景一致性、动作流畅度、美学质量、清晰度等共计15个方向上的性能表现。VBench2.0已推出,在1.0 的基础上,进一步聚焦视频的内在真实性评估。
欢迎更多的合作伙伴加入我们,共建多模态模型特色能力榜单,促进评测技术的发展和持续创新。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









