






作者: 复旦联培博士杨雨辰
本研究着眼于无监督的姿态估计,旨在发挥该类算法能够利用大量室外未标注的数据的特性,增强模型性能。考虑到无监督的分割算法 [1] 在室外场景的优秀表现,研究团队探索了利用更易广泛获取的人体掩膜作为监督信号,完成端到端的无监督 3D 姿态估计的算法,近期为 ECCV 2024 接收。
智慧体育方向博士生招录中,简历投递:sunxiao@pjlab.org.cn;或添加小助手微信咨询(ID: gvxiaozhushou)
论文简介
精确的人体 3D 姿态估计是众多领域的基础,如机器人、运动表现分析等,而获取大量的自然条件下的 3D 姿态标注极其困难。具体而言,3D 姿态真值获取通常需要搭建动作捕捉环境。该方式仍然需要耗费大量人力物力,且数据受限于动作类型和人体外貌多样性,因而使得以 3D 真值为基础的全监督姿态估计算法难以泛化到更多室外场景。
本研究在以下两大问题上实现突破,实现 SOTA 无监督 3D 姿态估计结果,推动 了3D 姿态估计在更广泛复杂场景的应用。
-
提出显式利用人体结构先验,消除了以往无监督方法中还存在的有监督后处理(SPP)步骤
-
强调了无监督方法中难以区分人体左右的问题,并提出利用一致性约束进行有效解决。

论文标题:
Mask as Supervision: Leveraging Unified Mask Information for Unsupervised 3D Pose Estimation
论文链接:
https://arxiv.org/pdf/2312.07051.pdf
代码链接:
https://github.com/Charrrrrlie/Mask-as-Supervision
Pipeline
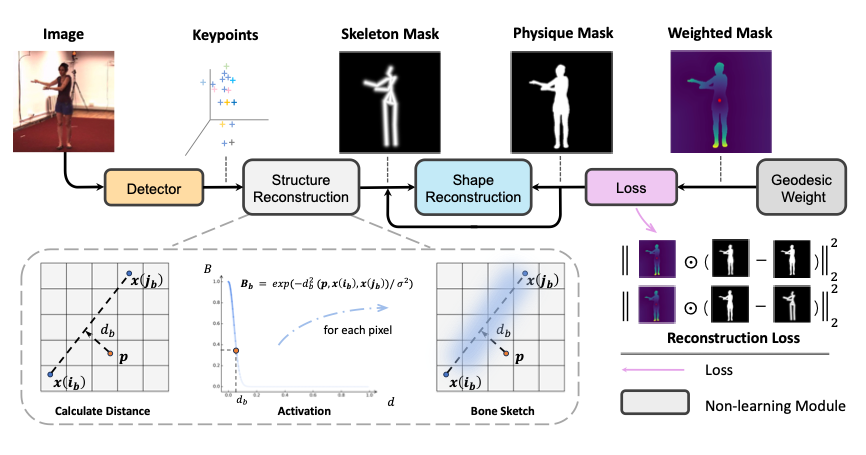
动机
无监督姿态估计的难点在于设计无需人工标注的损失函数,为检测器优化提供目标。
人体掩膜容易以无监督的方式获得,包括以视频为输入的传统静态背景建模方法,以及利用新兴的 SAM [1] 在丰富图片上的泛化能力。同时,掩膜能够看作是关键点的退化形式。如果人体关键点能从人体掩膜中被发掘,便能够实现监督信号的获取。
于是我们将关键点到人体掩膜的过程看作由粗至细粒度的补全过程,设计了包含结构信息的人体骨架掩膜和包含形状信息的人体体型掩膜,深度挖掘掩膜信息,由关键点逐步逼近真实掩膜。
消除有监督后处理步骤
姿态检测中的人体关键点包含有指定顺序和实际物理含义,一类无监督姿态估计算法并未考虑这一点,导致虽然检测的关键点和某些真值关键点相合,但无法确定具体对应关系。
较差的可解释性使得该类方法需要检测较多数量的关键点(大于 30 个),并通过训练集上的真值,学习关键点到真值姿态的映射关系,采用有监督后处理(supervised post-processing, SPP)得到最终结果。该类方法仍然需要训练集上的人工标注,与真正无监督的理念相悖。

本文算法将人体视作由刚体骨架构成的整体,构造骨架特征图。利用 [2] 扩展的高斯核,以一定宽度的线段显式建模由一对关节点连接的骨骼 B_b。当骨架的连接方式确定时,每一个关键点的物理含义将被确定。同时,其在掩膜中的最优结构,将确定关键点的目标位置。
人体左右对称的影响
由于人体的对称性,基于人体形状建模的无监督方法在左右关键点互换后,仍将得到相同的损失,从而并不能区分人体左右状态。使用有监督后处理的诸多方法中,该对称性由有监督的映射解决,并被忽略讨论。
本文强调了这一问题,并使用多视角图像进行解决。在多视角图像可用时,用以构建人体掩膜的关键点将利用相机参数投影至二维,从而通过多视角几何约束确保各视角下关键点没有出现对称性错误。
优化监督信号
考虑到将显式建模的人体骨架置于人体掩膜中,会出现多种次优的结构,这将对算法的优化产生困难。本文使用了层次化的优化方式,首先将变化范围较小的躯干部分构建人体骨架进行优化,而后将四肢纳入优化过程。此外,我们还设计了基于测地距离的权重掩膜,使得远离掩膜中心的正确关键点能减少更大损失,并容忍接近掩膜区域但位于掩膜外的错误关键点,从而平滑优化的求解空间。
实验结果
我们在常用的 Human3.6M 和 MPI-INF-3DHP 数据集上进行实验,取得了无监督算法中的 SOTA 结果。
Human3.6M数据集
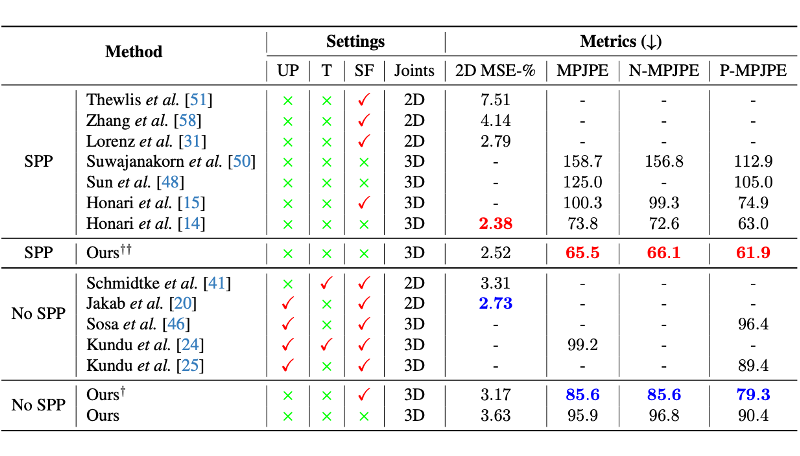
我们标注了不同方法共性的设定,包括 SPP(有监督后处理)、UP(未配对的真值姿态或基于此的先验)、T(人工设计的模板)、SF(有监督翻转,对应左右不分问题)。
可以看出,本文算法无需上述限制条件,即可实现无监督 3D 姿态估计,并取得最优性能。同时,在 SPP 的设定下,算法突出的性能也进一步说明利用掩膜信息挖掘特征的有效性。
MPI-INF-3DHP数据集
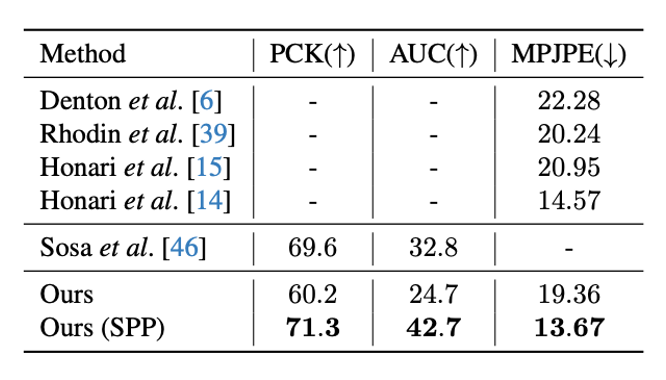
在该数据集上多数方法采用了上述 SPP 或 UP 的设定,我们在同样设定下取得了 SOTA 性能,并展示了 MPI-INF-3DHP 数据集推荐的 PCK 和 AUC 指标,方便后续工作进行比较。
利用室外场景数据
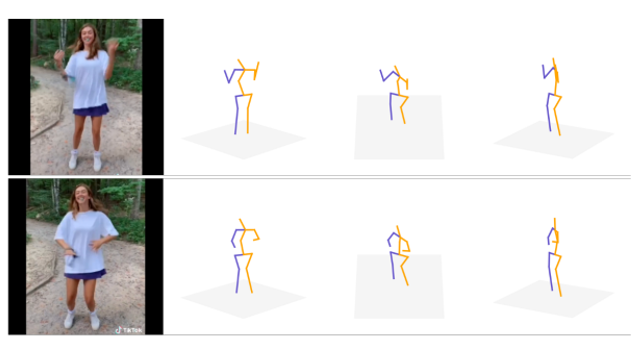
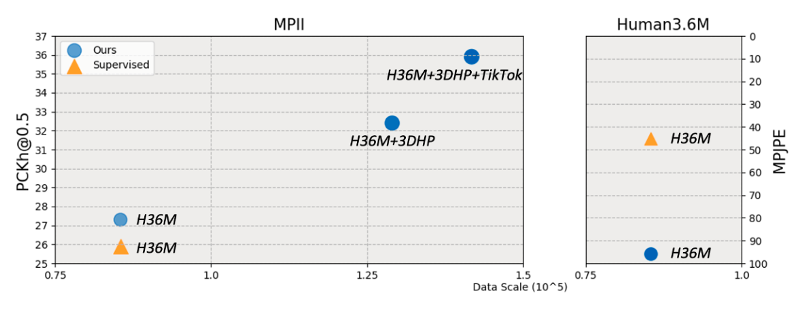
为验证本文提出的无监督算法具有利用并学习广泛来源数据的能力,我们设计了多个数据集混合训练的实验,包括引入完全无任何姿态数据标注的 TikTok 视频数据集。在数据量逐步提升时,模型在未参与训练的野外数据集 MPII 中性能表现逐步提升,从模型泛化能力的角度证明本文无监督方法的可适用性。
TikTok 数据集单目图像中得到 3D 姿态标注结果:
多个数据集混合训练的性能提升结果:
参考文献
[1] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4015–4026, 2023
[2] Xingzhe He, Bastian Wandt, and Helge Rhodin. Autolink: Self-supervised learning of human skeletons and object outlines by linking keypoints. Advances in Neural Information Processing Systems, 35:36123–36141, 2022
有兴趣实习/工作/读博的读者请联系:sunxiao@pjlab.org.cn
欢迎大家🌟该项目~
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









