






引 言
第一视角(点击了解)理解对于AI智能体至关重要。 继2022年,上海人工智能实验室通用视觉团队在Ego4D竞赛中取得“超级队伍”的称号后,我们在第一视角领域的主流竞赛 CVPR 2024年EgoVis竞赛中,再次获得7个赛道的第一名。我们对部分国内外竞赛冠军技术方案进行了归纳整理,分享给大家,欢迎大家留言讨论!
技术报告:
https://arxiv.org/abs/2406.18070
开源代码:
https://github.com/OpenGVLab/EgoVideo

EgoVis 比赛介绍
EgoVis 2024 CVPR Workshop承接了自2022年起的Ego4D workshop和自2016年起办的EPIC比赛,主要关注可穿戴摄像头、智能眼镜和AR/VR头戴设备所带来的以人为中心的视觉感知,这些设备在辅助技术、教育、健身、娱乐、游戏、老年护理、机器人技术和增强现实等领域具有广泛的应用,对社会产生积极影响。
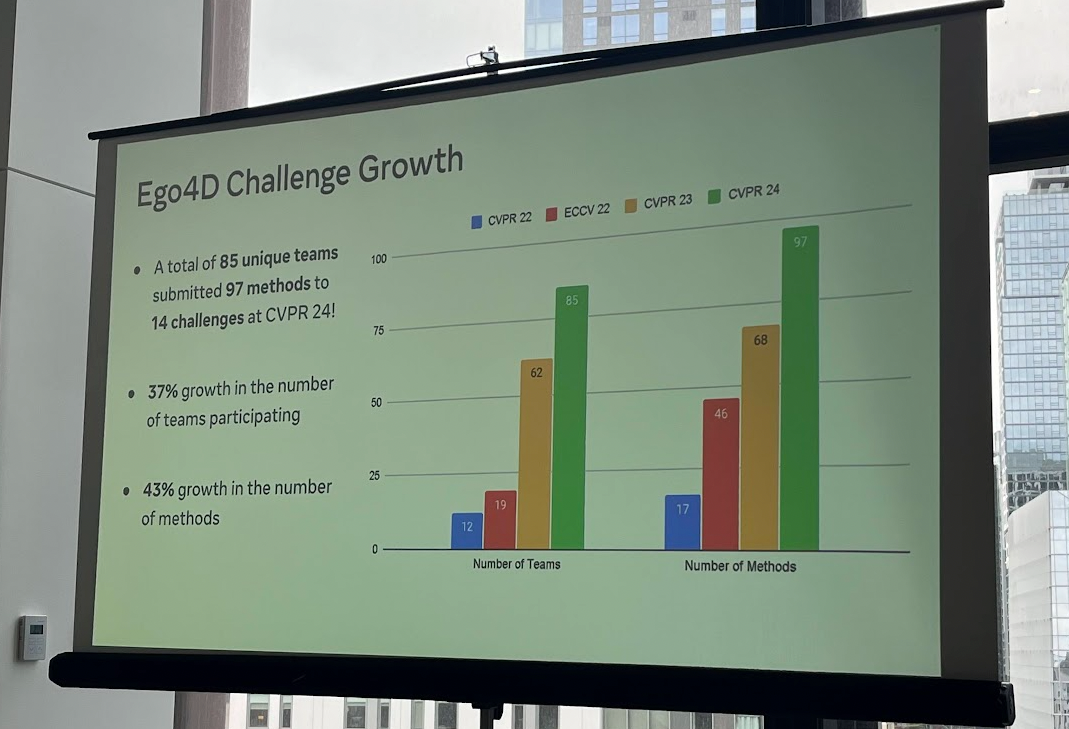
EgoVis Challenge是目前第一人称计算机视觉领域世界上最大规模的竞赛,随着智能设备和算力的不断发展,近年来受关注度得到显著提高。截止到比赛结束,有85个队伍在14个赛道中提交了97个方法。
上海人工智能实验室通用视觉团队联合浙江大学、南京大学等学校获得7个赛道的冠军,成为获得最多冠军的团队。夺得冠军的7个赛道分别为自然语言查询(Natural Language Queries),2D视觉查询(Visual Queries 2D),短期目标交互(Short-term object interaction anticipation),长期动作预测(Long-term Action Anticipation),目标跟踪(EgoTracks),领域适应动作识别(Domain Adaptation for Action Recognition),身体姿态估计(Body Pose)。
冠军赛道
-
自然语言查询(Natural Language Queries):通过先进的算法,实现对视频内容的自然语言查询,提升信息检索的准确性和效率。
-
2D视觉查询(Visual Queries 2D):利用深度学习技术,对2D视觉数据进行高效分析,推动视觉识别技术的发展。
-
短期目标交互(Short-term object interaction anticipation):预测短期内物体间的交互行为,为智能监控和自动驾驶等领域提供技术支持。
-
长期动作预测(Long-term Action Anticipation):通过深入分析视频数据,预测长时间跨度内的动作发展,为健康监护和体育分析等应用提供可能。
-
目标跟踪(EgoTracks):精确追踪视频中的目标物体,为视频监控和行为分析提供强有力的技术支持。
-
领域适应动作识别(Domain Adaptation for Action Recognition):使模型能够适应不同领域的动作识别任务,增强模型的泛化能力。
-
身体姿态估计(Body Pose):准确估计人体姿态,为健康监测、运动分析等应用提供数据支持。
现在就和我们一起看看冠军方案介绍吧!
第一人称高质量数据的获取
虽然现在有像Ego4D一样的大规模第一视角数据集的提出,并不是里面所有的数据都有高质量的标注从而适合模型的学习的。于是我们将Ego4D、EgoExoLearn、Ego4D-Goalsteps等数据集进行严格筛选,剔除掉里面不利于模型预训练的数据。同时,为了尽可能的利用更多领域的第一视角数据,我们并没有将数据集严格限制在以上数据集中,而是从HowTo100M等数据集中筛选第一视角和类似第一视角的视频,加入我们的预训练集中。最终我们筛选合并了7M视频-文本对,用于后续的模型预训练。
在高质量第一人称数据上的后训练
基于上海人工智能实验室通用视觉团队强大的视频基础模型InternVideo2,我们使用第一步骤所得来的数据进行post-pretraining。该阶段旨在缩小网络规模视频数据集与第一人称视频之间的领域差异。通过在筛选出的第一人称视频数据上执行后训练,将通用视频特征表示有效地转移到第一人称领域。这里我们使用Video-Text 的对比学习来训练模型,并且在EPIC-Kitchens数据集上进行零样本验证模型的训练成果。通过这一阶段的训练,我们得到了EgoVideo模型,一个能够更好地适应第一人称视频数据的模型,为第三阶段的任务特定微调提供了一个坚实的基础。
在各项任务上的微调
在第二阶段获得针对第一人称领域的EgoVideo模型后,第三阶段的目的是进一步调整模型,使其能够针对特定的下游任务进行优化。每个任务都有其特定的训练集,根据每个任务的不同特性,我们把EgoVideo-V(视频编码器)或EgoVideo-T(文本编码器)在这些训练集上进行微调。通过任务特定微调,EgoVideo模型在各个任务上都取得了显著的性能提升,展示了模型在处理特定任务时的适应性和有效性。
具体各项任务的定义、实现等请参考我们的技术报告
链接:https://arxiv.org/abs/2406.18070
开源代码
链接:https://github.com/OpenGVLab/EgoVideo/
后续我们也会陆续放出更强大的第一视角基础模型,可以支持更细粒度的物体交互的理解、生成,同时支撑具身智能的相关应用,敬请期待!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









