







近几年大语言模型的突破带来自然语言相关的向量数据爆炸式增长,同时为管理这些向量数据而设计的向量数据库的关注度也在不断提高。大语言模型和向量数据库的组合在多个领域都具有广泛的应用,如语义检索、推荐系统、问答机器人等。本文将探讨向量数据库在大模型场景下的应用趋势,并结合用户案例,详细介绍拓数派向量数据库 PieCloudVector 的架构设计与技术实现。
随着人工智能技术的飞速发展,大模型成为推动 AIGC 前沿发展的关键力量。借助大模型的强大数据处理能力,AIGC 能够自动生成高质量、个性化的内容,实现智能问答、情感分析和文本生成等功能,并已经在金融、传媒、文娱、电商等多个领域广泛应用。然而,大模型仍然面临诸如数据时效、私域数据、长期记忆和幻觉等挑战和局限性,这极大地限制了大模型在各种场景中的落地。
1 检索增强生成(RAG)
为有效解决大模型的局限性,当前业界广泛采用的方法是利用检索增强生成(Retrieval-Augmented Generation, RAG)技术来提升大模型的性能。
RAG 是一种将信息检索系统与生成式大语言模型结合在一起的技术,它的核心思想是让语言模型在生成回答时能够动态地从外部知识库中检索相关信息,从而提高模型生成内容的准确性和可靠性。
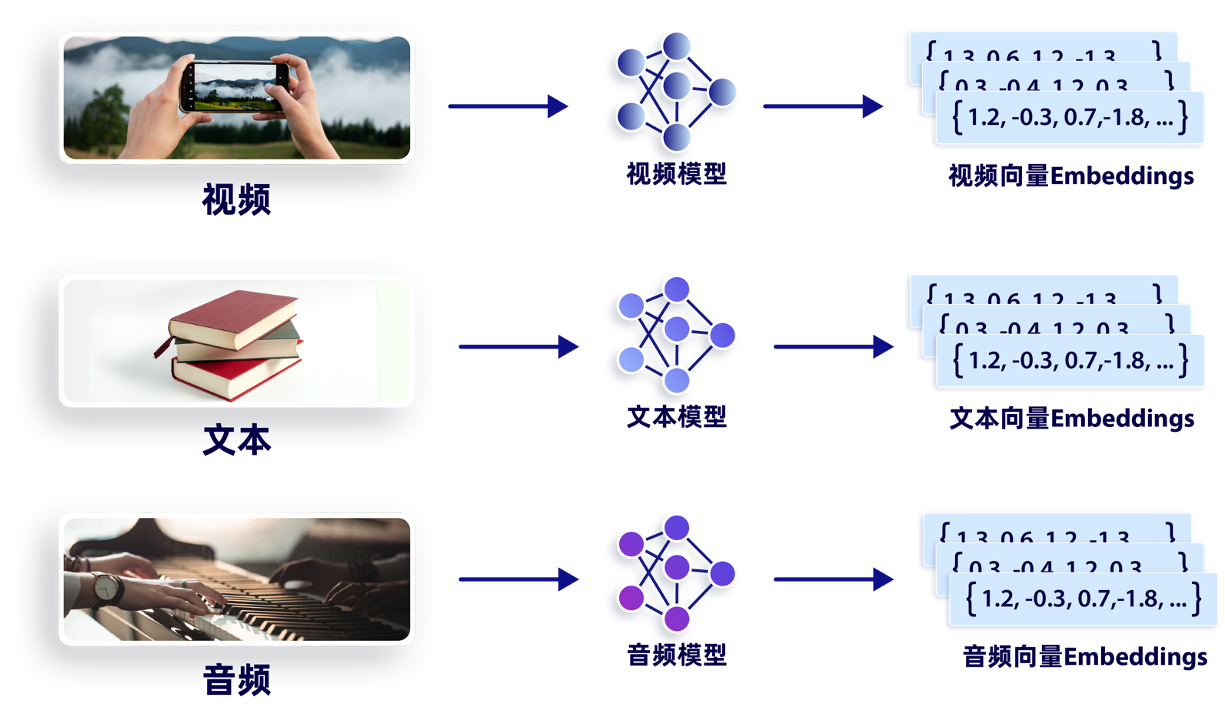
将原始数据转换为 Embeddings
整个 RAG 框架包含三个主要过程:检索、增强和生成:
-
检索(Retrieval): 将用户的查询通过 Embedding 模型转换为向量,以便与检索系统中存储的内容(通过同样的 Embedding 模型转换得到的向量数据)进行比对,通过相似性搜索(计算向量之间的距离),找出与查询最匹配的一组数据。
-
增强(Augmentation): 将用户的查询内容和检索到的相关内容一起嵌入到一个预设的提示词模板中。
-
生成(Generation): 将经过检索增强的提示词内容输入到大型语言模型中,从而生成质量更高的内容。
2 向量数据库:大模型的最佳搭档
向量数据库是一种专门用于存储和处理多维向量数据的数据库系统。 通过特定模型,我们可以把文字、图像、语音都转换成向量并存储,而向量数据库的重点工作是将向量与对应的原始数据关联起来。
将数据存储之后,向量数据库的另一项工作就是建立索引,以便对向量数据进行高效搜索。虽然不建立索引也可以进行搜索,例如使用全表扫描将记录一条一条进行比对,同样可以找出最接近的 K 个向量,但当信息库规模达到一定量级之后,这种方法将变得非常低效,而建立索引则可以大幅提高搜索性能。
最后,一个完整的向量数据库还需要配套调用接口和生态工具,以满足用户在数据类型支持、灵活性、接口易用性等多方面的需求,配套工具生态系统直接关乎向量数据库的用户友好度与实用性。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 163
163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









