







2.2019年NTIRE图像着色挑战的目标是:(i)衡量和推动最先进的图像着色;(ii)比较不同的解决方案。
2.1 DIV2K Dataset
NTIRE 2017和NTIRE 2018图像超分辨率挑战赛[27,28]使用的DIV2K Dataset[1]也用于我们挑战赛的训练。DIV2K有1000张不同的2K分辨率RGB图像,其中800张用于训练,100张用于验证,100张用于测试。手工采集的高质量图像内容多样。
由于在线可以得到DIV2K测试集的低分辨率彩色版本,我们以DIV2K的训练和验证集作为challenge使用的训练和验证集,另外准备20张图像作为challenge的测试集。
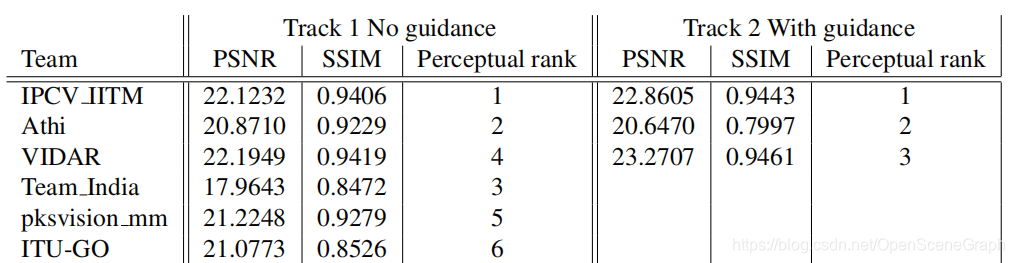 NTIRE 2019着色挑战结果和最终排名。
NTIRE 2019着色挑战结果和最终排名。

NTIRE 2019图像着色挑战赛有两条赛道。访问数据和提交彩色结果要求登记在Codalab比赛轨道。
轨道1:无引导图像着色使用彩色图像的灰度版本作为输入,目的是在不添加任何额外信息的情况下估计场景的颜色信息。对于RGB到灰度色彩空间我们采用标准常用的线性变换:
I = 0.2989·R + 0.5870·G + 0.1140·B, (1)
其中I为灰度值,R、G、B分别为原始RGB彩色图像的红、绿、蓝通道值。
轨道2:带引导的图像着色,除了轨道1输入的灰度图像外,还提供一些引导色种子作为输入。对于每个输入图像,我们在5到15个像素之间随机采样,并提供这些像素的颜色信息及其(x, y)图像坐标,以帮助着色过程。
2.3 挑战阶段
(1)开发阶段:参与者得到对DIV2K数据集的灰度、彩色序列图像和灰度验证图像;一个带有排行榜的在线验证服务器为上传的彩色结果提供了即时反馈到灰色验证图像。
(2)测试阶段:参与者获得测试灰度图像,并提交着色结果、代码和方法说明书。挑战结束后,最终的结果会公布给参与者。
2.4 评估协议
定量度量是用分贝测量的峰值信噪比(PSNR)和结构相似性指数(SSIM)[29],两者都是在着色结果和地面真值(GT)彩色图像之间计算的全参考度量。我们报告了一组图像的平均值。由于我们发现PSNR和SSIM指标都不能反映着色性能的视觉质量,所以我们在本报告中也报告了主观视觉质量的排名。主观非引用的方式进行比较,三个人谁不知道地面真理彩色图像彩色化的结果进行比较,我们排着彩色的结果基于比较的结果。
3. 挑战结果
轨道1和轨道2的注册人数分别为81人和107人;6/3个小组进入最后阶段,提交他们的结果、代码/可执行文件和事实表。表1报告了最终的测试结果和挑战的排名,而表2中提供了自报告的运行时和主要细节。方法在第4节中有简要描述,团队成员在附录A中列出。

图1 不同方法着色结果的视觉例子(轨道1:没有指导)。

图2 不同方法着色结果的视觉例子(轨道2:有指导)。
3.1 网络结构和主要思想
挑战中提出的所有方法都是基于深度学习的方法,但值得注意的是,Athi团队在引导着色轨道中采用的方法除外。为了扩大接收域,大多数方法都采用了编解码器或基于U-net[21]的结构。其中ResNet架构[9]和密集网(DenseNet)架构[10]是大部分方法的基础。
3.2 恢复真实度
生成高质量的彩色估计仍然是一个非常具有挑战性的任务。无论是无制导航迹还是制导航迹,所有的方法都没有达到高PSNR的估计。在测试数据集上,无导轨和有导轨的最佳PSNR指标分别为22.19dB和23.27dB。VIDAR团队在两个赛道上获得最高的PSNR和SSIM分数。为了达到较高的保真度估计,他们在训练阶段只采用了RMSE损失。我们注意到,来自Track 2的引导色像素帮助VIDAR提高了~ 1.08dB PSNR。
3.3感知质量
不同团队提供的着色结果的一些可视化示例可以在图1中找到,图1中是没有指导的轨道1,图2中是有指导的轨道2。从图中可以看出,虽然VIDAR团队取得了最好的PSNR和SSIM指数,但他们实际上并没有产生太多的颜色信息,估计结果仍然看起来是灰色的。为了提高感知质量,一些团队在训练阶段也采用了感知损失[14,11]或生成式对抗网络(GAN)[6]损失。IPCV IITM团队提供了最好的结果感知质量,是2019年NTIRE图像着色挑战赛的获胜者,而Athi和VIDAR团队在两个赛道上以一致的表现进入下一个位置。
3.4 总结
挑战的测试阶段。这一点和所提出的解决方案所达到的感知质量表明了图像着色任务的难度,还有很大的改进空间。挑战中提出的解决方案相当多样化,包括在最终排名中排名第二的非深度学习解决方案(Athi团队)。正如预期的那样,在几个引导色像素的形式下使用额外的信息有助于稳定和提高着色结果。将在其他图像上验证过的深度学习解决方案部署到图像映射中,包括恢复和增强任务[13,35,11,28,4,2,3],并不能保证在图像着色任务上有良好的感知结果。图像着色的挑战是向基准测试迈进了一步,进一步的研究是必要的,以确定更好的损失为这个任务,也为设计解决方案,能够看到大的上下文和推断可信的颜色。
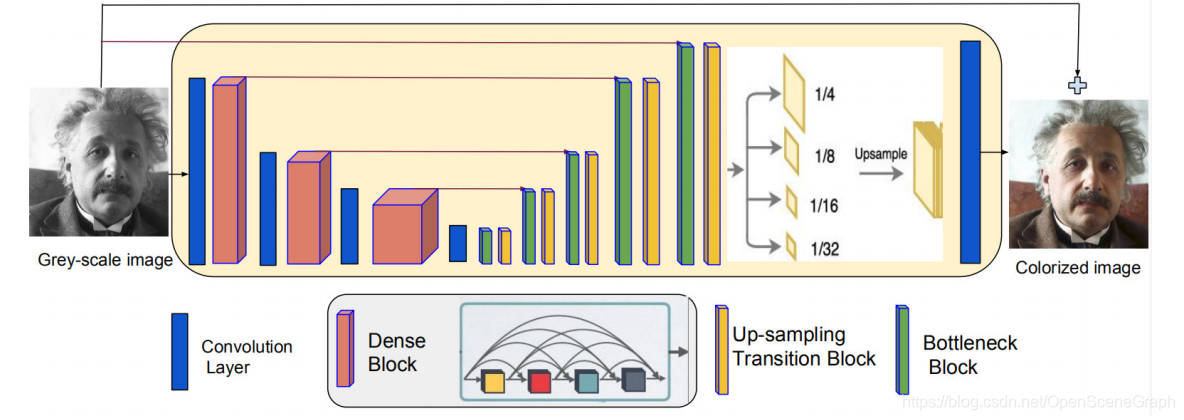
图3 IPCV IITM网络结构
4.挑战方法和团队
4.1 IPCV IITM
IPCV IITM提出了一种具有多层金字塔池化模块的深度密度残差编解码器结构,用于从灰度输入估计彩色图像(见图3)。它有助于解决梯度消失和特征传播的问题,同时大大降低了模型的复杂性。该编码器具有与[31]中提到的网络类似的结构。
第一个、第二个和第三个密集块分别包含12、16和24个密集单元。具体来说,每个密集单元由batch norm, ReLU, conv1 * 1(无通道=4 * GR),以及batch norm, ReLU, conv3 * 3(无通道=GR)组成。在我们的网络中,增长率(GR)被设置为32。这些块的权重使用预先训练好的DenseNet-121网络[10]的初始层进行初始化。一个区块中的每一层都收到来自所有早期层的特征图,这加强了前向和后向传递过程中的信息流,使得训练更深层次的网络更容易。该解码器接受编码器在不同层次上估计的特征,利用瓶颈块对其进行处理,然后通过双线性上采样和卷积提高其空间分辨率。瓶颈块与编码器中的密集单元具有类似的结构。所述解码器中具有较高空间分辨率的中间特征与相应大小的编码器特征连接。最后,译码器输出在被馈给最后一层之前,通过4个尺度的池化和上采样的多尺度上下文聚合来增强。最终的输出是底真彩色图像和输入图像之间的残差。首先使用L1损失对着色网络进行训练,
然后用MSE损失进行微调。作者也尝试使用自定义损失定义在其他颜色域或对抗性损失,但这些损失没有导致提出的模型的稳定训练.
4.2. Athi
Athi team直接采用[33]中提出的着色网络参加无引导轨道。而对于引导轨迹,Athi团队首先从引导像素中创建一个带有颜色的虚拟图像,然后将虚拟图像传输到YCbCr空间中。对于输入灰度图像,他们将灰度值分配到R、G、B平面,并从RGB转换到YCbCr颜色空间。然后在得到的输入灰度图像的Y通道中,检查伪图像的Y通道中最近的值。并在不改变Y通道值的情况下,将对应的Cb和Cr通道值赋给输出图像。该方法不能获得高PSNR的RGB重建结果。但是,在我们的非参考主观评价测试中,Athi生成的结果在感知质量上优于其他PSNR指数高得多的算法生成的结果。
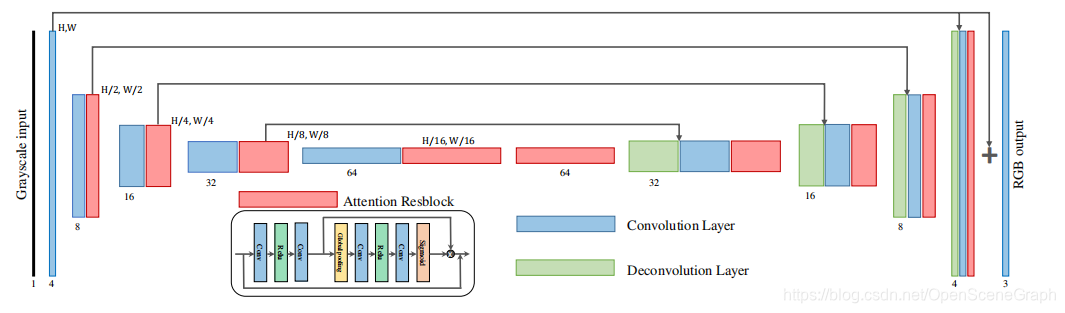
4.3 VIDAR
为了获得最佳的PSNR结果,VIDAR团队利用回归方法对灰度图像进行着色。VIDAR提出了一种U-Net[21]类网络,利用residual 信道注意块[34,25]将灰度图像重构为彩色图像。VIDAR所采用的网络如图4.2所示。对于轨道2,被引导的像素首先被重新组织到原始图像的网格中,其中其他像素被设为零。VIDAR还利用了一个掩码,掩码的值是在引导像素的位置上的,其他的值设置为零。然后,将引导像素图像和掩模连接起来,构成该网络的输入,而不是灰度图像。在进入网络之前,采用9×9高斯滤波器进行处理。在网络中,导像素图像和掩模首先经过一个卷积层,然后将灰度图像的特征图连接起来作为新的输入到剩余的网络中。
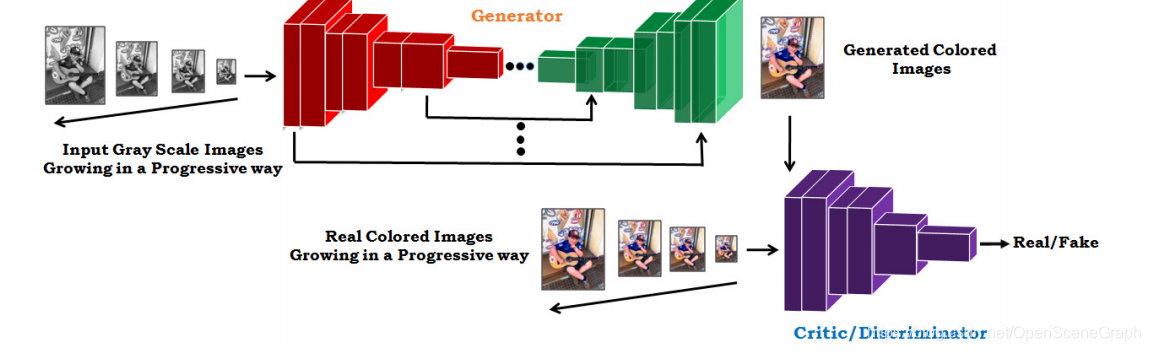
4.4 Team India
印度团队提出了一个使用基于自我注意的渐进GAN[30]的灰度图像着色框架。框架(见图5)由最先进的技术来稳定和更好的图像彩色化;(1)Self-Attention机制 (ii)输入通道的渐进增长(iii)发生器和鉴别器的光谱归一化(iv)对发生器学习率更高的批评家在我们的案例中5:1是最有效的(v)基于铰链的对抗损失。发生器的灵感来自于U-Net[21]架构,其编码器作为一个预先训练的ResNet-34[9]遵循一个34层解码器;预先训练好的编码器被用作特征提取器。
然后U-Net的输出被传递到一个预先训练过的vggg -16[26]来计算感知/内容损失,然后将其反向传播到生成器。在发生器和鉴别器中通过谱归一化对权值进行初始化,在发生器和鉴别器的每个卷积层之间都使用了自关注。然后鉴别器使用铰链版本的对抗性损失是向后传播到发生器和鉴别器。他们在层之间使用批处理标准化,并且在生成器中没有任何激活函数;而在鉴别器中,他们使用的是dropout值为0.2,同时使用LeakyReLU作为激活函数,alpha = 0.2。训练过程是在耸立的进步成长氮化镓[15]尽管他们不逐步增长我们的模型,他们只是不断输入大小在训练过程在64×64采样图像,它从64开始增长,96,128,160逐步192×192样品。最后的模型使用192 *训练制度。他们使用了带有超参数的ADAM optimizer[16],其中包含了一个循环学习率查找器。解决方案在[24]中有详细的描述。
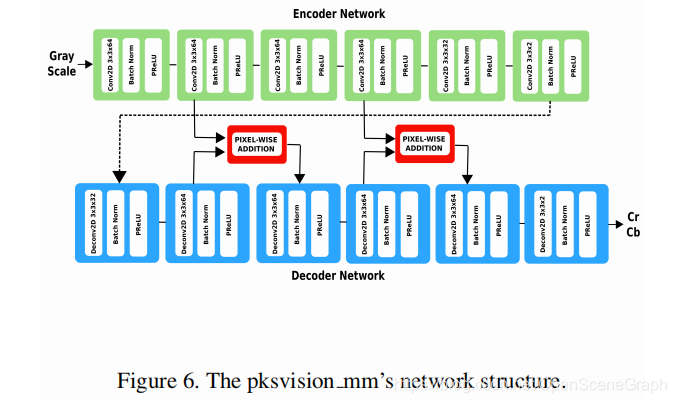
4.5 pksvision_mm
pksvision_mm 团队提出了一个方法,如图6所示,根据条件生成乱发广告 sarial网络(cGAN)框架(19日13)。具体来说,该网络以一幅灰度图像作为输入,预测其对应的色度分量(Cb,Cr)。编码器子网由6个卷积层组成,除倒数第二层和最后一层分别由32、2个卷积核组成外,每一层由64个卷积核组成。译码子网络由六个转置卷积层组成。生成器模型中每个滤波器的空间维度为3×3,stride为1。在编码器和解码器子网络的每一层之后是参数化ReLU (PReLU)[8]和批处理标准化(BN)[12]。在编码器的第2,4层和译码器的第2,4层之间分别给出了剩余的跳跃连接,以保持空间信息,同时也减少了使用对称连接时灰度特征的影响。译码层由传统的转置卷积运算组成。为了保持特征的完整性和避免结果中的模糊伪影,对输入的空间维度进行了保留。在主模型的代价计算过程中,还提出了一种表示网络(如图7所示),提取输入彩色图像的潜在特征,在YCbCr颜色空间中重构给定图像。
ITU-GO团队使用胶囊网络(CapsNet)[23]来解决图像着色问题。[23]中提出的原始CapsNet模型的特征检测器部分使用vgg19[26]的前两层进行更新,并从ImageNet[22]上预训练的原始vgg19模型初始化。针对图像间的问题,采用均方误差(MSE)对原始CapsNet模型的边缘损失进行修正。训练和测试阶段以基于patch的方式进行,使用9×9×3个灰度/颜色patch对。实验室颜色映射被选择为[32]中的颜色补丁的颜色速度。首先使用ILSVRC 2012数据集(ImageNet)通过创建相同类型的patch对(9×9×3)对网络进行10个epoch的训练,然后使用提供的DIV2K数据集[1](同时使用训练集和验证集)对得到的网络进行再训练。最终的模型用于从测试集预测图像,在CIE实验空间中通过RMSE、对抗性和feature loss对网络进行训练。总共有2216,243个参数,其中768个是不可训练的,模型大小约8.9 MB,网络处理一张输入图像大约需要7秒。详细描述了ITU-GO提出的解决方案在[20]。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









