






点击蓝字
关注我们,让开发变得更有趣
作者 | 武卓 英特尔 OpenVINO™ 布道师
OpenVINO™
前言
我们很高兴地宣布 OpenVINO™ 2025 的最新版本正式发布!本次更新带来了来自工程团队的更多增强功能和新特性。每一次发布,我们都在不断适应日新月异的 AI 发展趋势,迎接层出不穷的新机遇与复杂挑战。在此次版本中,我们重点增强了新模型的覆盖和实际应用场景的支持,同时在性能优化上也进行了深度打磨,帮助你的 AI 解决方案运行得更快、更高效。
目
录
01 | 新模型和应用场景 |
02 | 性能提升 |
03 | Executorch* |
04 | OpenVINO™ 模型中心 (OpenVINO™ Model Hub) |
05 | 小结 |
OpenVINO™
新模型和应用场景
在 2025.1 版本中,我们新增了以下模型的支持: Phi-4 Mini、Jina CLIP v1 和 BCE Embedding Base v1。其中,Phi-4 Mini 来自微软最新发布的开源小模型 Phi 系列。你可以在 GitHub 上尝试这个模型用它构建 LLM 聊天机器人或探索其他众多 LLM 模型。我们也非常高兴地宣布支持 Jina CLIP v1,这是一种多模态 AI 模型,可连接图像与文本数据,广泛应用于视觉搜索、多模态问答及内容生成等场景。我们在 GitHub 上提供了新的交互式示例供开发者上手体验。下图展示了该模型的输出效果:
(https://github.com/openvinotoolkit/openvino_notebooks/tree/0284702fb1c15ac768dd25b72cd824fb79ace4d6/notebooks/llm-chatbot)
(https://github.com/openvinotoolkit/openvino_notebooks/tree/442edcdf618126dd966eed5c687455edba332257/notebooks/jina-clip)
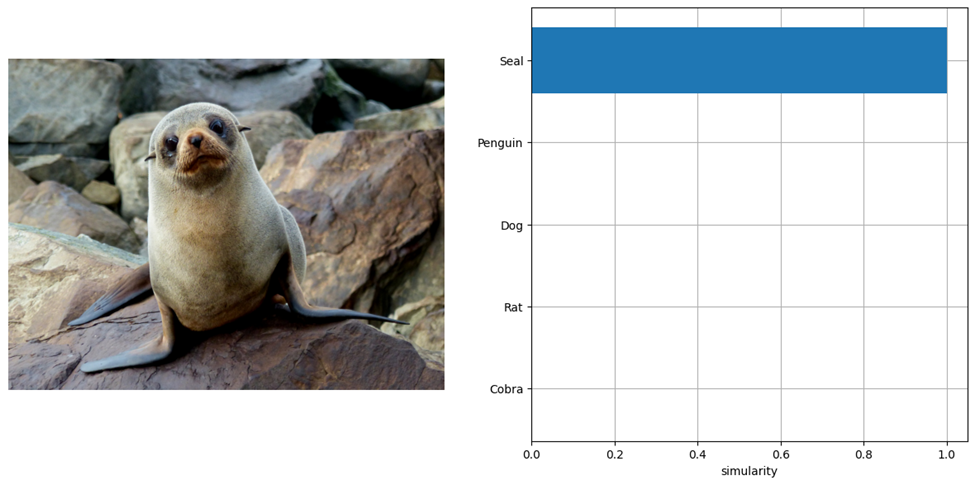
图片1: 使用 Jina CLIP 以及 OpenVINO™ 的 CLIP 模型
(https://github.com/openvinotoolkit/openvino_notebooks/tree/442edcdf618126dd966eed5c687455edba332257/notebooks/jina-clip)
在上一版本中,我们预览发布了 OpenVINO™ GenAI 图像到图像(image-to-image)转换与修复(inpainting)功能的支持。本次更新,这两项功能已全面支持,你可以通过 OpenVINO™ 快速部署如 Flux.1 和 Stable Diffusion v3 等图像生成模型的端到端流程。
OpenVINO™ 模型服务器(OVMS) 现已支持视觉语言模型(VLMs),如 Qwen2-VL、Phi-3.5-Vision 和 InternVL2。借此你可以在对话场景中发送图像进行推理,就像处理 LLM 一样。我们提供了连续批处理(continuous batching)下 VLM 部署的演示示例。此外,现在你还可以使用 OVMS 将 LLM 与 VLM 模型部署到 NPU 加速器上,在 AI PC 上实现高能效的低并发应用。我们提供了在 Docker 与裸机环境下部署 NPU 上 LLM 与 NPU 上 VLM 的完整示例代码。
(https://github.com/openvinotoolkit/model_server/tree/main/demos/continuous_batching/vlm)
(https://github.com/openvinotoolkit/model_server/tree/main/demos/llm_npu)
(https://github.com/openvinotoolkit/model_server/tree/main/demos/vlm_npu)

图2:使用 OpenVINO™ GenAI Notebook 生成不同强度的图像到图像输出示例
(https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/image-to-image-genai/image-to-image-genai.ipynb)
(https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/image-to-image-genai/image-to-image-genai.ipynb)
OpenVINO™
性能提升
我们的开发团队也在英特尔® 酷睿™ Ultra 200H 系列处理器上进一步优化了 LLM 性能。与上一版 2025.0 相比,在 2025.1 版本中 GPU 上的第二个 token 吞吐量提高了 1.4 倍,具体基准测试结果见下图。
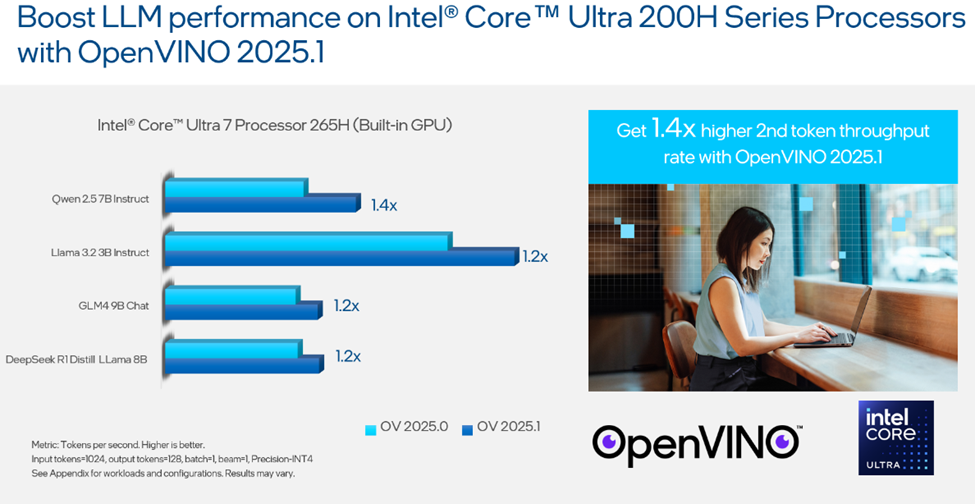
图3:OpenVINO™ 2025.1 提升英特尔® 酷睿™ Ultra 200H 系列处理器上 LLM 性能,详见附录中的负载与配置。结果可能因场景而异。
本次更新的一个重要亮点是预览支持 Token Eviction(token 清除)机制,用于智能管理 KV 缓存大小。该机制可自动保留重要 token、清除不必要信息,在保证模型表现的同时,大幅降低内存占用,尤其适用于处理长输入提示的 LLM 和 VLM 应用。Token 被清除后,KV 缓存会自动“重排”以保持上下文连贯性。
OpenVINO™
Executorch
对于 PyTorch 模型,Executorch 提供了在边缘设备上高效运行模型的能力,适用于计算资源与内存受限的场景。在此次 OpenVINO™ 新版本中,我们引入了 Executorch 的 OpenVINO™ 后端预览支持,可加速推理并提升模型在英特尔 CPU、GPU 与 NPU 上的执行效率。如需开始使用 OpenVINO™ 后端运行 Executorch,请参考 GitHub 上的相关文档。
(https://github.com/pytorch/executorch/blob/main/docs/source/build-run-openvino.md)
OpenVINO™
OpenVINO™ 模型中心
(OpenVINO™ Model Hub)
如果你对性能基准感兴趣,可以访问全新上线的 OpenVINO™ 模型中心(Model Hub)。这里提供了在 Intel CPU、集成 GPU、NPU 及其他加速器上的模型性能数据,帮助你找到最适合自己解决方案的硬件平台。
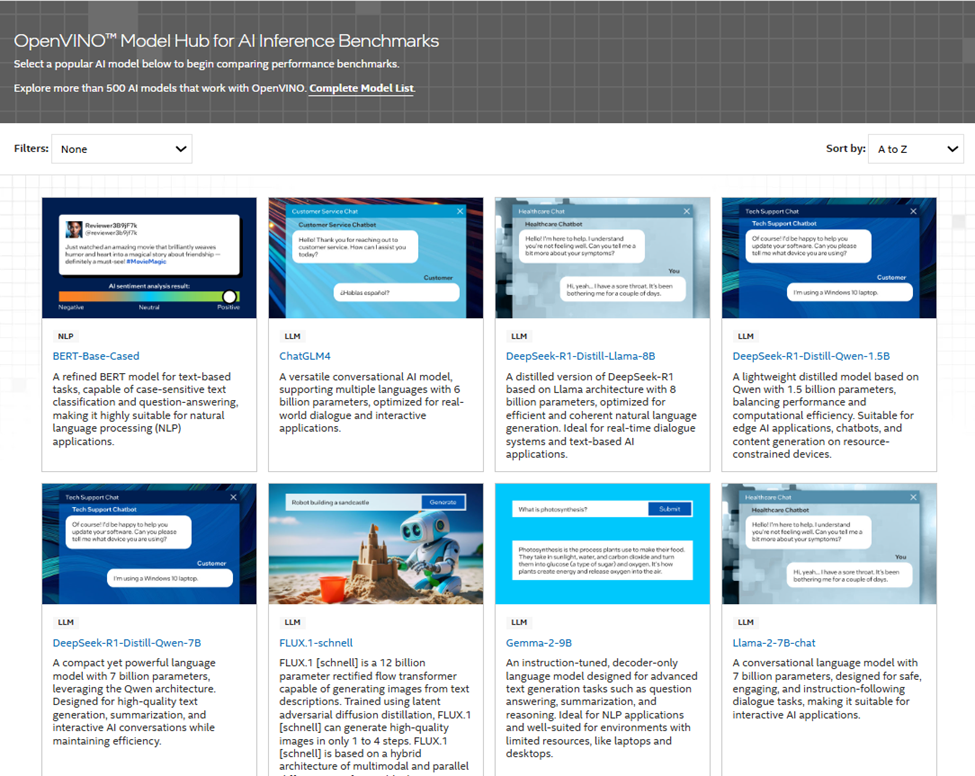
图4:OpenVINO™ 模型中心展示 AI 推理基准性能
OpenVINO™
小结
感谢你关注并参与 OpenVINO™ 的最新版本发布。我们始终致力于推动 AI 无处不在。
如果你想了解更多,欢迎注册并参加 OpenVINO™ DevCon 2025 。
通过一系列技术分享,深入了解如何借助 OpenVINO™ 强化你的 AI 工作负载,欢迎你全年持续关注与参与!
(https://bizwebcast.intel.cn/devcon2025.aspx)

OpenVINO™
附录
工作负载: |
deepseek-r1-distill-llama-8b |
glm-4-9b-chat-hf |
llama-3.2-3b-instruct |
qwen2.5-7b-instruct |
CPU Inference Engines: | Intel® Core™ Ultra 200H Processor |
Motherboard | Intel Corporation CRB SODIMM DDR5 |
CPU | Intel® Ultra 7-265H @ 2.2 GHz |
Hyper Threading | n/a |
Turbo Setting | on |
Memory | 2 x 16 GB DDR5 @ 6400MT/s |
Operating System | Windows 11 Entpr. 24H2 |
Kernel version | 10.0.26100 Build 26100 |
BIOS Vendor | Intel Corporation |
BIOS Version | MTLPEMI1.R00.4404.D55.2412181125 |
BIOS Release | 12/18/2024 |
Batch size | 1 |
Test Date | 4/2/2025 |
OpenVINO™
---------------------------------------
*OpenVINO and the OpenVINO logo are trademarks of Intel Corporation or its subsidiaries.
-----------------------------
OpenVINO 中文社区
微信号 : openvinodev
B站:OpenVINO中文社区
“开放、开源、共创”
致力于通过定期举办线上与线下的沙龙、动手实践及开发者交流大会等活动,促进人工智能开发者之间的交流学习。
○ 点击 “ 在看 ”,让更多人看见


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









