






概述
Prometheus](Prometheus - Monitoring system & time series database) 是一个监控系统和时序数据库,特别适合监控云原生环境,它具有多维数据模型和强大的查询语言,并在一个生态系统中集成了检测、指标收集、服务发现和报警等功能。
本课程将为你从 0 讲解 Prometheus 的基本概念,然后一步一步深入带领你加深对 Prometheus 的理解。
先决条件
本课程的整个演示环境在 CentOS 7.9 上进行测试,但是整个过程基本上不需要很多的改动就可以移植到其他 Linux 发行版中。
所以在学习本课程之前你将需要有 Unix/Linux 服务器管理的基础知识,系统监控经验会有所帮助,但并不是必须要的,不需要你具有 Prometheus 本身的经验,因为我们本身就是从 0 开始讲解的,所以你不用担心。
什么是 Prometheus
Prometheus](Prometheus - Monitoring system & time series database) 是一个基于指标监控和报警的工具栈。 Prometheus 起源于 SoundCloud ,因为微服务迅速发展,导致实例数量以几何倍数递增,不得不考虑设计一个符合以下几个功能的监控系统:
-
多维数据模型,可以按照实例,服务,端点和方法之类的维度随意对数据进行切片和切块。
-
操作简单,可以随时随地部署监控服务,甚至在本地工作站上,而无需设置分布式存储后端或重新配置环境。
-
可扩展的数据收集和分散的架构,以便于可以可靠的监控服务的许多实例,独立团队可以部署独立的监控服务。
-
一种查询语言,可以利用数据模型进行有效的报警和图形展示。
但是,当时的情况是,以上的功能都分散在各个系统之中,直到 2012 年 SoundCloud 启动了一个孵化项目把这些所有功能集合到一起,也就是 Prometheus。Prometheus 是用 Go 语言编写,从一开始就是开源的,到 2016 年 Prometheus 成为继 Kubernetes 之后,成为 CNCF 的第二个成员。
到现在为止 Prometheus 提供的工具或与其他生态系统组件集成可以提供完整的监控管道:
-
检测(跟踪和暴露指标)
-
指标收集
-
指标存储
-
查询指标,用于报警、仪表板等
! Prometheus Dashboard](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210406160656.png)
Prometheus 具有足够的通用性,可以监控各个级别的实例:你自己的应用程序、第三方服务、主机或网络设备等等。此外 Prometheus 特别适用于监控动态云环境和 Kubernetes 云原生环境。
但是也需要注意的是 Prometheus 并不是万能的,目前并没有解决下面的一些问题:
-
日志和追踪(Prometheus 只处理指标,也称为时间序列)
-
基于机器学习或 AI 的异常检测
-
水平扩展、集群化的存储
这些功能显然也是非常有价值的,但是 Prometheus 本身并没有尝试去解决,而是留给了第三方解决方案。
但是整体来说与其他监控解决方案相比,Prometheus 提供了许多重要功能:
-
多维数据模型,允许对指标进行跟踪
-
强大的查询语言(PromQL)
-
时间序列处理和报警的整合
-
与服务发现集成来确定应监控的内容
-
操作简单
-
执行高效
尽管这些功能中的许多功能如今在监控系统中变得越来越普遍,但是 Prometheus 是第一个将所有功能组合在一起的开源解决方案。
操作简单
Prometheus 的整个概念很简单并且操作也非常简单。 Prometheus 用 Go 编写,直接使用独立的二进制文件即可部署,而无需依赖外部运行时(例如 JVM)、解释器(例如 Python 或 Ruby)或共享系统库。
每个 Prometheus 服务器都独立于任何其他 Prometheus 服务器收集数据并评估报警规则,并且仅在本地存储数据,而没有严格的集群或副本。
要创建用于报警的高可用性配置,你仍然可以运行两个配置相同的 Prometheus 服务器,以计算相同的报警(Alertmanager 将对通知进行去重操作):
! Prometheus Simple HA](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210406180044.png)
当然,Prometheus 的大规模部署还是非常复杂的,在后面的章节中接触到,此外 Prometheus 还暴露了一些接口,允许第三方开发者来解决一些问题,比如远程存储这些功能。
性能高效
Prometheus 需要能够同时从许多系统和服务中收集详细的指标数据,为此,特别对以下组件进行了高度优化:
-
抓取和解析传入的指标
-
写入和读取时序数据库
-
评估基于 TSDB 数据的 PromQL 表达式
根据社区的使用经验显示,一台大型 Prometheus 服务器每秒可以摄取多达 100万 个时间序列样本,并使用 1-2 字节来将每个样本存储在磁盘上。
系统架构
下图演示了 Prometheus 系统的整体架构 ! Prometheus 系统架构
一个团队通常会运行一个或多个 Prometheus 服务器,这些服务器构成了 Prometheus 监控的核心。Prometheus 服务器可以配置为使用服务发现机制(如 DNS、Consul、Kubernetes 等)来自动发现一组指标源(所谓的目标),然后 Prometheus 通过 HTTP 定期从这些目标中以 文本格式](Exposition formats | Prometheus)抓取指标,并将收集到的数据存储在本地时序数据库中。
抓取的目标可以是一个直接暴露 Prometheus 指标的应用程序,也是可以是一个将现有系统(比如 MySQL)的 metrics 指标转换为 Prometheus 指标标准格式的中间应用(也就是我们说的 exporter),然后 Prometheus 服务器通过其内置的 Web UI、其他仪表盘工具(比如 Grafana](Grafana: The open observability platform | Grafana Labs))或者直接使用其 HTTP API 来提供收集到的数据进行查询。
注意:每次抓取只会将目标的每个时间序列的当前值传输给 Prometheus,所以抓取间隔决定了存储数据的最终采样频率。目标进程本身不保留任何历史指标数据。
另外我们还可以配置 Prometheus 根据收集的指标数据生成报警,但是 Prometheus 不会直接把报警通知发送给我们,而是将原始报警转发到 Alertmanager 服务,Alertmanager 是作为单独的服务运行的,可以从多个 Prometheus 服务器上接收报警,并可以对这些报警进行分组、汇总和路由,最后可以通过 Email、Slack、PagerDuty、企业微信、Webhook 或其他通知服务来发送通知。
数据模型
Prometheus 采集的监控数据都是以指标(metric)的形式存储在内置的 TSDB 数据库中,这些数据都是时间序列:一个带时间戳的数据,这些数据具有一个标识符和一组样本值。除了存储的时间序列,Prometheus 还可以根据查询请求产生临时的、衍生的时间序列作为返回结果。
时间序列
Prometheus 会将所有采集到的样本数据以时间序列的形式保存在内存数据库中,并定时刷新到硬盘上,时间序列是按照时间戳和值的序列方式存放的,我们可以称之为向量(vector),每一条时间序列都由一个指标名称和一组标签(键值对)来唯一标识。
-
指标名称反映了被监控样本的含义(如
http_request_total表示的是对应服务器处理的 HTTP 请求总数)。 -
标签可以用来区分不同的维度(比如
method="GET"与method="POST"就可以用来区分这两种不同的 HTTP 请求指标数据)。
如下所示,可以将时间序列理解为一个以时间为 Y 轴的数字矩阵:
^
│ . . . . . . . . . . . . . . . . . . . http_request_total{method="GET",status="200"}
│ . . . . . . . . . . . . . . . . . . . http_request_total{method="POST",status="500"}
│ . . . . . . . . . . . . . . . . . .
│ . . . . . . . . . . . . . . . . . .
v
<------------------ 时间 ---------------->
需要注意的是指标名称只能由 ASCII 字符、数字、下划线以及冒号组成,同时必须匹配正则表达式 a-zA-Z_:] a-zA-Z0-9_:]*(冒号不能用来定义指标名称,是用来表示用户自定义的记录规则)。标签的名称只能由 ASCII 字符、数字以及下划线组成并满足正则表达式 a-zA-Z_] a-zA-Z0-9_]*,其中以 __ 作为前缀的标签,是系统保留的关键字,只能在系统内部使用,标签的值则可以包含任何 Unicode 编码的字符。
样本
时间序列中的每一个点就称为一个样本(sample),样本由以下 3 个部分组成:
-
指标:指标名称和描述当前样本特征的标签集
-
时间戳:精确到毫秒的时间戳数
-
样本值:一个 64 位浮点数
指标
想要暴露 Prometheus 指标服务只需要暴露一个 HTTP 端点,并提供 Prometheus 基于文本格式的指标数据即可。这种指标格式是非常友好的,基本上的格式看起来类似于下面的这段代码:
# HELP http_requests_total The total number of processed HTTP requests.
# TYPE http_requests_total counter
http_requests_total{status="200"} 8556
http_requests_total{status="404"} 20
http_requests_total{status="500"} 68
其中 # 开头的行是注释信息,用来描述下面提供的指标含义,其他未注释行代表一个样本(带有指标名、标签和样本值),使其非常容易从系统和服务中暴露指标出来。
事实上所有的指标也都是通过如下所示的格式来标识的:
<metric name>{<label name>=<label value>, ...}
例如,指标名称是 http_request_total,标签集为 method="POST", endpoint="/messages",那么我们可以用下面的方式来标识这个指标:
http_request_total{method="POST", endpoint="/messages"}
而事实上 Prometheus 的底层实现中指标名称实际上是以 __name__=<metric name> 的形式保存在数据库中的,所以上面的指标也等同与下面的指标:
{__name__="http_request_total", method="POST", endpoint="/messages"}
所以也可以认为一个指标就是一个标签集,只是这个标签集里面一定包含一个 __name__ 的标签来定义这个指标的名称。
存储格式
Prometheus 按照两个小时为一个时间窗口,将两小时内产生的数据存储在一个块(Block)中,每个块都是一个单独的目录,里面包含该时间窗口内的所有样本数据(chunks),元数据文件(meta.json)以及索引文件(index)。
其中索引文件会将指标名称和标签索引到样本数据的时间序列中,如果该期间通过 API 删除时间序列,删除记录会保存在单独的逻辑文件 tombstone 当中。
当前样本数据所在的块会被直接保存在内存数据库中,不会持久化到磁盘中,为了确保 Prometheus 发生崩溃或重启时能够恢复数据,Prometheus 启动时会通过预写日志(write-ahead-log(WAL))来重新播放记录,从而恢复数据,预写日志文件保存在 wal 目录中,wal 文件包括还没有被压缩的原始数据,所以比常规的块文件大得多。
Prometheus 保存块数据的目录结构如下所示:
.
├── 01FB9HHY61KAN6BRDYPTXDX9YF
│ ├── chunks
│ │ └── 000001
│ ├── index
│ ├── meta.json
│ └── tombstones
├── 01FB9Q76Z0J10WJZX3PYQYJ96R
│ ├── chunks
│ │ └── 000001
│ ├── index
│ ├── meta.json
│ └── tombstones
├── chunks_head
│ ├── 000014
│ └── 000015
├── lock
├── queries.active
└── wal
├── 00000011
├── 00000012
├── 00000013
├── 00000014
└── checkpoint.00000010
└── 00000000
7 directories, 17 files
查询语言
为了能够使用收集的监控数据,Prometheus 实现了自己的查询语言 PromQL。PromQL 是一种功能性的语言(类似于 SQL 语句),可以对时间序列数据进行灵活高效的计算。和类似 SQL 的语言相比,PromQL 仅用于数据读取,而不是插入、更新或者删除数据(这些操作在查询引擎之外实现的)
! Prometheus 查询语言](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210406170536.png)
后续我们会详细讲解 PromQL,这里我们先简单了解一些示例即可。
示例
比如下面的语句表示的是过滤所有状态码位为 500 的 HTTP 请求总数:
http_requests_total{status="500"}
下面的查询语句表示每个序列在 5 分钟的时间窗口内的平均每秒增长率:
rate(http_requests_total{status="500"} 5m])
我们还可以计算 status="500" 错误与按 HTTP 路径分组的请求总数的比率:
sum by(path) (rate(http_requests_total{status="500"} 5m]))
/
sum by(path) (rate(http_requests_total 5m]))
这些查询方式是 PromQL 中一些非常常见的方式,当然除此之外还有很多其他使用方法,我们将在后面专门的 PromQL 章节中进行详细的讲解。
集成报警
Prometheus 将时间序列数据的收集、处理和主动报警系统集成在一起,它的理念是在单个数据模型中尽可能多地收集有关系统的数据,以便你可以对其进行集成查询。此外用于临时查询和仪表盘使用的查询语言也可以用于定义报警规则。
例如,以下警报规则(作为规则配置文件的一部分加载到 Prometheus 中)将在 500 状态码的 HTTP 请求数量超过指定路径总流量的5%时触发报警。
alert: Many500Errors
# expr 是一个 PromQL 表达式,是整个报警规则的核心
expr: |
(
sum by(path) (rate(http_requests_total{status="500"} 5m]))
/
sum by(path) (rate(http_requests_total 5m]))
) * 100 > 5
for: 5m
labels:
severity: "critical"
annotations:
summary: "Many 500 errors for path {{$labels.path}} ({{$value}}%)"
上面是一个典型的报警规则定义规范,其中 expr 属性指定的 PromQL 表达式构成报警规则的核心,而其他基于 YAML 的配置选项则允许控制报警元数据、路由标签等。这样就可以根据收集的数据进行精确而准确的警报了。
安装配置
二进制安装prometheus
下载prometheus
解压到指定目录
mkdir /opt/app tar xvf prometheus-2.29.1.linux-amd64.tar.gz -C /opt/app mv /opt/app/prometheus-2.29.1.linux-amd64 /opt/app/prometheus
准备service文件
cat <<-"EOF" > /etc/systemd/system/prometheus.service Unit] Description="prometheus" Documentation=https://prometheus.io/ After=network.target Service] Type=simple ExecStart=/opt/app/prometheus/prometheus --config.file=/opt/app/prometheus/prometheus.yml --storage.tsdb.path=/opt/app/prometheus/data --web.enable-lifecycle Restart=on-failure RestartSecs=5s SuccessExitStatus=0 LimitNOFILE=655360 StandardOutput=syslog StandardError=syslog SyslogIdentifier=prometheus Install] WantedBy=multi-user.target EOF
启动prometheus 服务
systemctl daemon-reload systemctl restart prometheus systemctl status prometheus
检查prometheus服务
# 查看端口 进程 日志 ss -ntlp |grep 9090 ps -ef |grep prometheus |grep -v grep tail -100 /var/log/messages |grep prometheus
配置 Prometheus
前文我们已经下载完成了 Prometheus,接下来在启动之前我们需要为其创建一个配置文件。
Prometheus 通过抓取监控目标上的 HTTP 端点来收集指标,而且 Prometheus 本身也暴露 metrics 指标接口,所以自然它也可以抓取并监控其自身的运行状况,下面我们就用收集自身的数据为例进行配置说明。
将以下 Prometheus 配置保存为 prometheus.yml 文件(覆盖现有示例的 prometheus.yml 文件):
global:
scrape_interval: 5s # 抓取频率
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: "localhost:9090"]
表达式查询
Prometheus 内置了用于 PromQL 查询的表达式查询界面,浏览器中导航至 http://<host-ip>:9090/graph 并选择 Table 视图即可:
! Prometheus 查询和图形界面](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210408111516.png)
Table 选项卡显示了表达式的每个输出序列的最新值,而 Graph 选项卡是绘制随时间变化的值,当然会在图形对于服务端和浏览器来说是比较耗性能的,所以一般情况都是先在 Table 下尝试查询可能比较耗时的表达式,然后将表达式的查询时间范围缩小,再切换到 Graph 下面进行图形绘制是一个更好的做法。
我们这里使用的最新版本的 2.26.0 版本,还对查询功能做了大幅度的升级,新增了一个非常实用的功能就是有查询关键字相关的提示了,我们只需要勾选上 Use experimental editor 选项,然后在查询的时候就会有提示了。
! Prometheus 查询提示](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210408112246.png)
这里的提示功能不只是有指标名称,还有查询语句中使用到的查询函数,也包括这个函数的用法提示等信息,可以说这个功能非常实用。
比如我们这里可以查询下面的指标,表示自进程开始以来被摄入 Prometheus 本地存储中的样本总数:
prometheus_tsdb_head_samples_appended_total
然后可以使用下面的表达式了查询 1 分钟内平均每秒摄取的样本数:
rate(prometheus_tsdb_head_samples_appended_total 1m])
我们可以在 Table 和 Graph 视图下面切换查看表达式查询的结果。
PromQL 介绍
PromQL 是 Prometheus 监控系统内置的一种查询语言,PromQL 允许你以灵活的方式选择、聚合等其他方式转换和计算时间序列数据,该语言仅用于读取数据。可以说 PromQL 是我们学习 Prometheus 最困难也是最重要的部分,本章节我们将介绍 PromQL 的基础知识、理论基础,然后会深入了解更加高级的查询模式。
目标
通过对本章节 PromQL 的学习你将能够有效地构建、分享和理解 PromQL 查询,可以帮助我们从容应对报警规则、仪表盘可视化等需求,还能够避免一些在使用 PromQL 表达式的时候遇到的一些陷进。
执行
前面基础章节我们介绍了 Prometheus 整体的架构:
! Prometheus 架构中的 PromQL](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210408121947.png)
当 Prometheus 从系统和服务收集指标数据时,它会把数据存储在内置的时序数据库(TSDB)中,要对收集到的数据进行任何处理,我们都可以使用 PromQL 从 TSDB 中读取数据,同时可以对所选的数据执行过滤、聚合以及其他转换操作。
PromQL 的执行可以通过两种方式来触发:
-
在 Prometheus 服务器中,记录规则和警报规则会定期运行,并执行查询操作来计算规则结果(例如触发报警)。该执行在 Prometheus 服务内部进行,并在配置规则时自动发生。
-
外部用户和 UI 界面可以使用 Prometheus 服务提供的 HTTP API](HTTP API | Prometheus) 来执行 PromQL 查询。这就是仪表盘软件(例如 Grafana](Grafana | Query, visualize, alerting observability platform)、 PromLens](PromLens, the query builder for PromQL - PromLens) 以及 Prometheus 内置 Web UI)访问 PromQL 的方式。
场景
PromQL 可以用于许多监控场景,下面简单介绍几个相关案例。
临时查询
我们可以用 PromQL 来对收集的数据进行实时查询,这有助于我们去调试和诊断遇到的一些问题,我们一般也是直接使用内置的表达式查询界面来执行这类查询:
仪表盘
同样我们也可以基于 PromQL 查询来创建可视化的图形、表格等面板,当然一般我们都会使用 Grafana:
Grafana 原生支持 Prometheus 作为数据源,并内置支持了 PromQL 表达式的查询。
报警
Prometheus 可以直接使用基于 PromQL 对收集的数据进行的查询结果来生成报警,一个完整的报警规则如下所示:
groups:
- name: demo-service-alerts
rules:
- alert: Many5xxErrors
expr: |
(
sum by(path, instance, job) (
rate(demo_api_request_duration_seconds_count{status=~"5..",job="demo"} 1m])
)
/
sum by(path, instance, job) (
rate(demo_api_request_duration_seconds_count{job="demo"} 1m])
) * 100 > 0.5
)
for: 30s
labels:
severity: critical
annotations:
title: "{{$labels.instance}} high 5xx rate on {{$labels.path}}"
description: "The 5xx error rate for path {{$labels.path}} on {{$labels.instance}} is {{$value}}%."
除了构成报警规则核心的 PromQL 表达式(上面 YAML 文件中的 expr 属性),报警规则还包含其他的一些元数据字段,后面在具体讲解报警的章节中会详细和大家讲解。
然后,Prometheus 可以通过一个名为 Alertmanager 的组件来发送报警通知,可以配置一些接收器来接收这些报警,比如用钉钉来接收报警:
自动化
此外我们还可以构建自动化流程,针对 PromQL 执行的查询结果来做出决策,比如 Kubernetes 中基于自定义指标的 HPA。
数据模型
在开始学习 PromQL 的知识之前,我们先重新来熟悉下 Prometheus 的数据模型
Prometheus数据模型
Prometheus 会将所有采集到的样本数据以时间序列的方式保存在内存数据库中,并且定时保存到硬盘上。时间序列是按照时间戳和值的序列顺序存放的,我们称之为向量(vector),每条时间序列通过指标名称(metrics name)和一组标签集(labelset)命名。如下所示,可以将时间序列理解为一个以时间为 X 轴的数字矩阵:
^
│ . . . . . . . . . . . . . . . . . . . node_cpu_seconds_total{cpu="cpu0",mode="idle"}
│ . . . . . . . . . . . . . . . . . . . node_cpu_seconds_total{cpu="cpu0",mode="system"}
│ . . . . . . . . . . . . . . . . . . node_load1{}
│ . . . . . . . . . . . . . . . . . .
v
<------------------ 时间 ---------------->
在时间序列中的每一个点称为一个样本(sample),样本由以下三部分组成:
-
指标(metric):指标名和描述当前样本特征的标签集合
-
时间戳(timestamp):一个精确到毫秒的时间戳
-
样本值(value): 一个 float64 的浮点型数据表示当前样本的值
如下所示:
<--------------- metric ---------------------><-timestamp -><-value->
http_request_total{status="200", method="GET"}@1434417560938 => 94355
http_request_total{status="200", method="GET"}@1434417561287 => 94334
http_request_total{status="404", method="GET"}@1434417560938 => 38473
http_request_total{status="404", method="GET"}@1434417561287 => 38544
http_request_total{status="200", method="POST"}@1434417560938 => 4748
http_request_total{status="200", method="POST"}@1434417561287 => 4785
在形式上,所有的指标都通过如下格式表示:
<metric name>{<label name> = <label value>, ...}
-
指标的名称可以反映被监控样本的含义(比如,http*request_total 表示当前系统接收到的 HTTP 请求总量)。指标名称只能由 ASCII 字符、数字、下划线以及冒号组成并必须符合正则表达式
a-zA-Z*:]a-zA-Z0-9\*:]\*。 -
标签(label)反映了当前样本的特征维度,通过这些维度 Prometheus 可以对样本数据进行过滤,聚合等。标签的名称只能由 ASCII 字符、数字以及下划线组成并满足正则表达式
a-zA-Z_] a-zA-Z0-9_]*。
注意:在 TSDB 内部,指标名称也只是一个特殊的标签,标签名为
__name__,由于这个标签在 PromQL 中随时都会使用,所以在使用 PromQL 查询的时候就被单独写在了标签列表前面了。另外像method=""这样的空标签在 Prometheus 种相当于一个不存在的标签,在 Prometheus 代码里面是明确地剥离了空标签的,并不会存储它们。
每个不同的 metric_name和 label 组合都称为时间序列,在 Prometheus 的表达式语言中,表达式或子表达式包括以下四种类型之一:
-
瞬时向量(Instant vector):一组时间序列,每个时间序列包含单个样本,它们共享相同的时间戳。也就是说,表达式的返回值中只会包含该时间序列中的最新的一个样本值。而相应的这样的表达式称之为瞬时向量表达式。 -
区间向量(Range vector):一组时间序列,每个时间序列包含一段时间范围内的样本数据,这些是通过将时间选择器附加到方括号中的瞬时向量(例如 5m]5 分钟)而生成的。 -
标量(Scalar):一个简单的数字浮点值。 -
字符串(String):一个简单的字符串值。
所有这些指标都是 Prometheus 定期从 metrics 接口那里采集过来的。采集的间隔时间的设置由 prometheus.yml 配置中的 scrape_interval 指定。最多抓取间隔为 30 秒,这意味着至少每 30 秒就会有一个带有新时间戳记录的新数据点,这个值可能会更改,也可能不会更改,但是每隔 scrape_interval 都会产生一个新的数据点。
指标类型
从存储上来讲所有的监控指标都是相同的,但是在不同的场景下这些指标又有一些细微的差异。 例如,在 Node Exporter 返回的样本中指标 node_load1 反应的是当前系统的负载状态,随着时间的变化这个指标返回的样本数据是在不断变化的。而指标 node_cpu_seconds_total 所获取到的样本数据却不同,它是一个持续增大的值,因为其反应的是 CPU 的累计使用时间,从理论上讲只要系统不关机,这个值是会一直变大。
为了能够帮助用户理解和区分这些不同监控指标之间的差异,Prometheus 定义了 4 种不同的指标类型:Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)。
在 node-exporter(后面会详细讲解)返回的样本数据中,其注释中也包含了该样本的类型。例如:
# HELP node_cpu_seconds_total Seconds the cpus spent in each mode.
# TYPE node_cpu_seconds_total counter
node_cpu_seconds_total{cpu="cpu0",mode="idle"} 362812.7890625
Counter
Counter (只增不减的计数器) 类型的指标其工作方式和计数器一样,只增不减,所以它对于存储诸如服务的 HTTP 请求数量或使用的 CPU 时间之类的信息非常有用。常见的监控指标,如 http_requests_total、node_cpu_seconds_total 都是 Counter 类型的监控指标。
可能你会觉得一直增加的数据没什么用处,了解服务从开始有多少请求有什么价值吗?但是需要记住,每个指标都存储了时间戳的,所有你的 HTTP 请求数现在可能是 1000 万,但是 Prometheus 也会记录之前某个时间点的值,我们可以去查询过去一个小时内的请求数,当然更多的时候我们想要看到的是请求数增加或减少的速度有多快,因此通常情况对于 Counter 指标我们都是去查看变化率而不是本身的数字。PromQL 内置的聚合操作和函数可以让用户对这些数据进行进一步的分析,例如,通过 rate() 函数获取 HTTP 请求的增长率:
rate(http_requests_total 5m])
Gauge
与 Counter 不同,Gauge(可增可减的仪表盘)类型的指标侧重于反应系统的当前状态,因此这类指标的样本数据可增可减。常见指标如 node_memory_MemFree_bytes(当前主机空闲的内存大小)、node_memory_MemAvailable_bytes(可用内存大小)都是 Gauge 类型的监控指标。由于 Gauge 指标仍然带有时间戳存储,所有我们可以看到随时间变化的值,通常可以直接把它们绘制出来,这样就可以看到值本身而不是变化率了,通过 Gauge 指标,用户可以直接查看系统的当前状态。
这些简单的指标类型都只是为每个样本获取一个数字,但 Prometheus 的强大之处在于如何让你跟踪它们,比如我们绘制了两张图,一个是 HTTP 请求的变化率,另一个是分配的 gauge 类型的实际内存,直接从图上就可以看出这两个之间有一种关联性,当请求出现峰值的时候,内存的使用也会出现峰值,但是我们仔细观察也会发现在峰值过后,内存使用量并没有恢复到峰值前的水平,整体上它在逐渐增加,这表明很可能应用程序中存在内存泄露的问题,通过这些简单的指标就可以帮助我们找到这些可能存在的问题。
关联性
对于 Gauge 类型的监控指标,通过 PromQL 内置函数 delta() 可以获取样本在一段时间范围内的变化情况。例如,计算 CPU 温度在两个小时内的差异:
delta(cpu_temp_celsius{host="zeus"} 2h])
还可以直接使用 predict_linear() 对数据的变化趋势进行预测。例如,预测系统磁盘空间在 4 个小时之后的剩余情况:
predict_linear(node_filesystem_free_bytes 1h], 4 * 3600)
Histogram 和 Summary
除了 Counter 和 Gauge 类型的监控指标以外,Prometheus 还定义了 Histogram 和 Summary 的指标类型。Histogram 和 Summary 主用用于统计和分析样本的分布情况。
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如 CPU 的平均使用率、页面的平均响应时间,这种方式也有很明显的问题,以系统 API 调用的平均响应时间为例:如果大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 WEB 页面的响应时间落到中位数上,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在 0~10ms 之间的请求数有多少而 10~20ms 之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram 和 Summary 都是为了能够解决这样的问题存在的,通过 Histogram 和Summary 类型的监控指标,我们可以快速了解监控样本的分布情况。
Summary
摘要用于记录某些东西的平均大小,可能是计算所需的时间或处理的文件大小,摘要显示两个相关的信息:count(事件发生的次数)和 sum(所有事件的总大小),如下图计算摘要指标可以返回次数为 3 和总和 15,也就意味着 3 次计算总共需要 15s 来处理,平均每次计算需要花费 5s。下一个样本的次数为 10,总和为 113,那么平均值为 11.3,因为两组指标都记录有时间戳,所以我们可以使用摘要来构建一个图表,显示平均值的变化率,比如图上的语句表示的是 5 分钟时间段内的平均速率。
Summary
例如,指标 prometheus_tsdb_wal_fsync_duration_seconds 的指标类型为 Summary,它记录了 Prometheus Server 中 wal_fsync 的处理时间,通过访问 Prometheus Server 的 /metrics 地址,可以获取到以下监控样本数据:
# HELP prometheus_tsdb_wal_fsync_duration_seconds Duration of WAL fsync.
# TYPE prometheus_tsdb_wal_fsync_duration_seconds summary
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
从上面的样本中可以得知当前 Prometheus Server 进行 wal_fsync 操作的总次数为 216 次,耗时 2.888716127000002s。其中中位数(quantile=0.5)的耗时为 0.012352463,9 分位数(quantile=0.9)的耗时为 0.014458005s。
Histogram
摘要非常有用,但是平均值会隐藏一些细节,上图中 10 与 113 的总和包含非常广的范围,如果我们想查看时间花在什么地方了,那么我们就需要直方图了。直方图以 bucket 桶的形式记录数据,所以我们可能有一个桶用于需要 1s 或更少的计算,另一个桶用于 5 秒或更少、10 秒或更少、20 秒或更少、60 秒或更少。该指标返回每个存储桶的计数,其中 3 个在 5 秒或更短的时间内完成,6 个在 10 秒或更短的时间内完成。Prometheus 中的直方图是累积的,因此所有 10 次计算都属于 60 秒或更少的时间段,而在这 10 次中,有 9 次的处理时间为 20 秒或更少,这显示了数据的分布。所以可以看到我们的大部分计算都在 10 秒以下,只有一个超过 20 秒,这对于计算百分位数很有用。
Histogram
在 Prometheus Server 自身返回的样本数据中,我们也能找到类型为 Histogram 的监控指标prometheus_tsdb_compaction_chunk_range_seconds_bucket:
# HELP prometheus_tsdb_compaction_chunk_range_seconds Final time range of chunks on their first compaction
# TYPE prometheus_tsdb_compaction_chunk_range_seconds histogram
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="100"} 71
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="400"} 71
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="1600"} 71
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="6400"} 71
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="25600"} 405
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="102400"} 25690
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="409600"} 71863
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="1.6384e+06"} 115928
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="6.5536e+06"} 2.5687892e+07
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="2.62144e+07"} 2.5687896e+07
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="+Inf"} 2.5687896e+07
prometheus_tsdb_compaction_chunk_range_seconds_sum 4.7728699529576e+13
prometheus_tsdb_compaction_chunk_range_seconds_count 2.5687896e+07
与 Summary 类型的指标相似之处在于 Histogram 类型的样本同样会反应当前指标的记录的总数(以 _count 作为后缀)以及其值的总量(以 _sum 作为后缀)。不同在于 Histogram 指标直接反应了在不同区间内样本的个数,区间通过标签 le 进行定义。
PromQL 基础
在继续深入学习 PromQL 查询细节之前,我们先来看看 PromQL 查询的一些理论基础。
嵌套结构
与 SQL 查询语言(SELECT * FROM ...)不同,PromQL 是一种嵌套的函数式语言,就是我们要把需要查找的数据描述成一组嵌套的表达式,每个表达式都会评估为一个中间值,每个中间值都会被用作它上层表达式中的参数,而查询的最外层表达式表示你可以在表格、图形中看到的最终返回值。比如下面的查询语句:
histogram_quantile( # 查询的根,最终结果表示一个近似分位数。
0.9, # histogram_quantile() 的第一个参数,分位数的目标值
# histogram_quantile() 的第二个参数,聚合的直方图
sum by(le, method, path) (
# sum() 的参数,直方图过去5分钟每秒增量。
rate(
# rate() 的参数,过去5分钟的原始直方图序列
demo_api_request_duration_seconds_bucket{job="demo"} 5m]
)
)
)
PromQL 表达式不仅仅是整个查询,而是查询的任何嵌套部分(比如上面的rate(...)部分),你可以把它作为一个查询本身来运行。在上面的例子中,每行注释代表一个表达式。
结果类型
在查询 Prometheus 时,有两个 类型 的概念经常出现,区分它们很重要。
-
抓取目标报告的指标类型:counter、gauge、histogram、summary。
-
PromQL 表达式的结果数据类型:字符串、标量、瞬时向量或区间向量。
PromQL 实际上没有直接的指标类型的概念,只关注表达式的结果类型。每个 PromQL 表达式都有一个类型,每个函数、运算符或其他类型的操作都要求其参数是某种表达式类型。例如,rate() 函数要求它的参数是一个区间向量,但是 rate() 本身评估为一个瞬时向量输出,所以 rate() 的结果只能用在期望是瞬时向量的地方。
PromQL 中可能的表达式类型包括:
-
string(字符串):字符串只会作为某些函数(如label_join()和label_replace())的参数出现。 -
scalar(标量):一个单一的数字值,如 1.234,这些数字可以作为某些函数的参数,如histogram_quantile(0.9, ...)或topk(3, ...),也会出现在算术运算中。 -
instant vector(瞬时向量):一组标记的时间序列,每个序列有一个样本,都在同一个时间戳,瞬时向量可以由 TSDB 时间序列选择器直接产生,如node_cpu_seconds_total,也可以由任何函数或其他转换来获取。
node_cpu_seconds_total{cpu="0", mode="idle"} → 19165078.75 @ timestamp_1
node_cpu_seconds_total{cpu="0", mode="system"} → 381598.72 @ timestamp_1
node_cpu_seconds_total{cpu="0", mode="user"} → 23211630.97 @ timestamp_1
-
range vector(区间向量):一组标记的时间序列,每个序列都有一个随时间变化的样本范围。在 PromQL 中只有两种方法可以生成区间向量:在查询中使用字面区间向量选择器(如node_cpu_seconds_total 5m]),或使用子查询表达式(如<expression> 5m:10s]),当想要在指定的时间窗口内聚合一个序列的行为时,区间向量非常有用,就像rate(node_cpu_seconds_total 5m])计算每秒增加率一样,在node_cpu_seconds_total指标的最后 5 分钟内求平均值。
node_cpu_seconds_total{cpu="0", mode="idle"} → 19165078.75 @ timestamp_1, 19165136.3 @ timestamp_2, 19165167.72 @ timestamp_3
node_cpu_seconds_total{cpu="0", mode="system"} → 381598.72 @ timestamp_1, 381599.98 @ timestamp_2, 381600.58 @ timestamp_3
node_cpu_seconds_total{cpu="0", mode="user"} → 23211630.97 @ timestamp_1, 23211711.34 @ timestamp_2, 23211748.64 @ timestamp_3
注意:但是指标类型呢?如果你已经使用过 PromQL,你可能知道某些函数仅适用于特定类型的指标!例如,
histogram_quantile()函数仅适用于直方图指标,rate()仅适用于计数器指标,deriv()仅适用于Gauge。但是 PromQL 实际上并没有检查你是否传入了正确类型的指标——这些函数通常会运行并为错误类型的输入指标返回一些无意义的数据,这取决于用户是否传入了遵守某些假设的时间序列(比如在直方图的情况下有一个有意义的le标签,或者在计数器的情况下单调递增)。
查询类型和评估时间
PromQL 查询中对时间的引用只有相对引用,比如 5m],表示过去 5 分钟,那么如何指定一个绝对的时间范围,或在一个表格中显示查询结果的时间戳?在 PromQL 中,这样的时间参数是与表达式分开发送到 Prometheus 查询 API 的,确切的时间参数取决于你发送的查询类型,Prometheus 有两种类型的 PromQL 查询:瞬时查询和区间查询。
瞬时查询
瞬时查询用于类似表格的视图,你想在一个时间点上显示 PromQL 查询的结果。一个瞬时查询有以下参数:
-
PromQL 表达式
-
一个评估的时间戳
在查询的时候可以选择查询过去的数据,比如 foo 1h] 表示查询 foo 序列最近 1 个小时的数据,访问过去的数据,对于计算一段时间内的比率或平均数等聚合会非常有用。
瞬时查询
在 Prometheus 的 WebUI 界面中表格视图中的查询就是瞬时查询,API 接口 /api/v1/query?query=xxxx&time=xxxx 中的 query 参数就是 PromQL 表达式,time 参数就是评估的时间戳。瞬时查询可以返回任何有效的 PromQL 表达式类型(字符串、标量、即时和范围向量)。
下面来看一个瞬时查询的示例,看看它是如何进行评估工作的。比如 http_requests_total 在指定的时间戳来评估表达式,http_requests_total 是一个瞬时向量选择器,它可以选择该时间序列的最新样本,最新意味着查询最近 5 分钟的样本数据。
如果我们在一个有最近样本的时间戳上运行此查询,结果将包含两个序列,每个序列都有一个样本:
即时
注意每个返回的样本输出时间戳不再是原始样本被采集的时间戳,而会被设置为评估的时间戳。
如果在时间戳之前有一个 >5m 的间隙,这个时候如果我们执行相同的查询:
空数据
这个情况下查询的结果将返回为空,因为很显然在最近 5 分钟内没有能够匹配的样本。
区间查询
区间查询主要用于图形,想在一个指定的时间范围内显示一个 PromQL 表达式,范围查询的工作方式与即时查询完全相同,这些查询在指定时间范围的评估步长中进行评估。当然,这在后台是高度优化的,在这种情况下,Prometheus 实际上并没有运行许多独立的即时查询。
区间查询包括以下一些参数:
-
PromQL 表达式
-
开始时间
-
结束时间
-
评估步长
在开始时间和结束时间之间的每个评估步长上评估表达式后,单独评估的时间片被拼接到一个单一的区间向量中。区间查询允许传入瞬时向量类型或标量类型的表达式,但始终返回一个范围向量(标量或瞬时向量在一个时间范围内被评估的结果)。
在 Prometheus 的 WebUI 界面中图形视图中的查询就是区间查询,API 接口 /api/v1/query_range?query=xxx&start=xxxxxx&end=xxxx&step=14 中的 query 参数就是 PromQL 表达式,start 为开始时间,end 为结束时间,step 为评估的步长。
区间查询
比如把上面的 http_requests_total 表达式作为一个范围查询来进行评估,它的评估结果如下所示:
区间查询
注意每个评估步骤的行为与独立的瞬时查询完全一样,而且每个独立的瞬时查询都没有查询的总体范围的概念,在我们这个示例中最终的结果将是一个区间向量,其中包含两个选定序列在一定时间范围内的样本,但也将包含某些时间步长的序列数据的间隙。
选择时间序列
本节我们将学习如何用不同的方式来选择数据,如何在单个时间戳或一段时间范围内基于标签过滤数据,以及如何使用移动时间的方式来选择数据。
过滤指标名称
最简单的 PromQL 查询就是直接选择具有指定指标名称的序列,例如,以下查询将返回所有具有指标名称 demo_api_request_duration_seconds_count 的序列:
demo_api_request_duration_seconds_count
该查询将返回许多具有相同指标名称的序列,但有不同的标签组合 instance、job、method、path 和 status 等。输出结果如下所示:
API 请求响应时长查询
根据标签过滤
如果我们只查询 demo_api_request_duration_seconds_count 中具有 method="GET" 标签的那些指标序列,则可以在指标名称后用大括号加上这个过滤条件:
demo_api_request_duration_seconds_count{method="GET"}
此外我们还可以使用逗号来组合多个标签匹配器:
demo_api_request_duration_seconds_count{instance="demo-service-0:10000",method="GET",job="demo"}
上面将得到 demo 任务下面 demo-service-0:10000 这个实例且 method="GET" 的指标序列数据:
过滤 API 请求计数
需要注意的是组合使用多个匹配条件的时候,是过滤所有条件都满足的时间序列。
除了相等匹配之外,Prometheus 还支持其他几种匹配器类型:
-
!=:不等于 -
=~:正则表达式匹配 -
!~:正则表达式不匹配
甚至我们还可以完全省略指标名称,比如直接查询所有 path 标签以 /api 开头的所有序列:
{path=~"/api.*"}
该查询会得到一些具有不同指标名称的序列:
正则表达式匹配的序列
注意: Prometheus 中的正则表达式总是针对完整的字符串而不是部分字符串匹配。因此,在匹配任何以
/api开通的路径时,不需要以^开头,但需要在结尾处添加.*,这样可以匹配path="/api"这样的序列。
前面我们说过在 Prometheus 内部,指标名称本质上是一个名为 __name__ 的特性标签,所以查询 demo_api_request_duration_seconds_count 实际上和下面的查询方式是等效的:
{__name__="demo_api_request_duration_seconds_count"}
按上面的方法编写的选择器,可以得到一个瞬时向量,其中包含所有选定序列的单个最新值。事实上有些函数要求你不是传递一个单一的值,而是传递一个序列在一段时间范围内的值,也就是前面我们说的区间向量。这个时候我们可以通过附加一个<数字><单位>]形式的持续时间指定符,将即时向量选择器改变为范围向量选择器(例如5m]表示 5 分钟)。
比如要查询最近 5 分钟的可用内存,可以执行下面的查询语句:
demo_memory_usage_bytes{type="free"} 5m]
将得到如下所示的查询结果:
范围向量查询
可以使用的有效的时间单位为:
-
ms-毫秒 -
s-秒 -
m- 分钟 -
h- 小时 -
d- 天 -
y- 年
有时我们还需要以时移方式访问过去的数据,通常用来与当前数据进行比较。要将过去的数据时移到当前位置,可以使用 offset <duration> 修饰符添加到任何范围或即时序列选择器进行查询(例如 my_metric offset 5m 或 my_metric 1m] offset 7d)。
例如,要选择一个小时前的可用内存,可以使用下面的查询语句:
demo_memory_usage_bytes{type="free"} offset 1h
这个时候查询的值则是一个小时之前的数据:
时移数据查询
练习:
1.构建一个查询,选择所有时间序列。
{job!=""}
或者:
{__name__=~".+"}
2.构建一个查询,查询所有指标名称为 demo_api_request_duration_seconds_count 并且 method 标签不为 POST 的序列。
demo_api_request_duration_seconds_count{method!="POST"}
3.使用 demo_memory_usage_bytes 指标查询一小时前的 1 分钟时间范围的的可用空闲内存。
demo_memory_usage_bytes{type="free"} 1m] offset 1h
变化率
通常来说直接绘制一个原始的 Counter 类型的指标数据用处不大,因为它们会一直增加,一般来说是不会去直接关心这个数值的,因为 Counter 一旦重置,总计数就没有意义了,比如我们直接执行下面的查询语句:
demo_api_request_duration_seconds_count{job="demo"}
可以得到下图所示的图形:
Prometheus Counter Graph
可以看到所有的都是不断增长的,一般来说我们更想要知道的是 Counter 指标的变化率,PromQL 提供了不同的函数来计算变化率。
rate
用于计算变化率的最常见函数是 rate(),rate() 函数用于计算在指定时间范围内计数器平均每秒的增加量。因为是计算一个时间范围内的平均值,所以我们需要在序列选择器之后添加一个范围选择器。
例如我们要计算 demo_api_request_duration_seconds_count 在最近五分钟内的每秒平均变化率,则可以使用下面的查询语句:
rate(demo_api_request_duration_seconds_count 5m])
可以得到如下所示的图形:
! Prometheus Rate Graph](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210412170701.png)
现在绘制的图形看起来显然更加有意义了,进行 rate 计算的时候是选择指定时间范围下的第一和最后一个样本进行计算,下图是表示瞬时计算的计算方式:
往往我们需要的是绘制一个图形,那么就需要进行区间查询,指定一个时间范围内进行多次计算,将结果串联起来形成一个图形:
对于 rate() 和相关函数有几个需要说明的:
-
当被抓取指标进的程重启时,
Counter指标可能会重置为 0,但rate()函数会自动处理这个问题,它会假设Counter指标的值只要是减少了就认为是被重置了,然后它可以调整后续的样本,例如,如果时间序列的值为5,10,4,6],则将其视为5,10,14,16]。 -
变化率是从指定的时间范围下包含的样本进行计算的,需要注意的是这个时间窗口的边界并不一定就是一个样本数据,可能会不完全对齐,所以,即使对于每次都是增加整数的
Counter,也可能计算结果是非整数。
rate 注意点:
另外我们需要注意当把 rate() 与一个聚合运算符(例如 sum())或一个随时间聚合的函数(任何以 _over_time 结尾的函数)结合起来使用时,总是先取用 rate() 函数,然后再进行聚合,否则,当你的目标重新启动时,rate() 函数无法检测到 Counter 的重置。
注意:
rate()函数需要在指定窗口下至少有两个样本才能计算输出。一般来说,比较好的做法是选择范围窗口大小至少是抓取间隔的4倍,这样即使在遇到窗口对齐或抓取故障时也有可以使用的样本进行计算,例如,对于 1 分钟的抓取间隔,你可以使用 4 分钟的 Rate 计算,但是通常将其四舍五入为 5 分钟。所以如果使用query_range区间查询,例如在绘图中,那么范围应该至少是步长的大小,否则会丢失一些数据。
irate
由于使用 rate 或者 increase 函数去计算样本的平均增长速率,容易陷入长尾问题当中,其无法反应在时间窗口内样本数据的突发变化。
例如,对于主机而言在 2 分钟的时间窗口内,可能在某一个由于访问量或者其它问题导致 CPU 占用 100%的情况,但是通过计算在时间窗口内的平均增长率却无法反应出该问题。
为了解决该问题,PromQL 提供了另外一个灵敏度更高的函数irate(v range-vector)。irate 同样用于计算区间向量的计算率,但是其反应出的是瞬时增长率。
irate 函数是通过区间向量中最后两个样本数据来计算区间向量的增长速率。这种方式可以避免在时间窗口范围内的长尾问题,并且体现出更好的灵敏度,通过 irate 函数绘制的图标能够更好的反应样本数据的瞬时变化状态。那既然是使用最后两个点计算,那为什么还要指定类似于 1m] 的时间范围呢?这个 1m] 不是用来计算的,irate 在计算的时候会最多向前在 1m] 范围内找点,如果超过 1m] 没有找到数据点,这个点的计算就放弃了。
irate
由于 rate() 提供了更平滑的结果,因此在长期趋势分析或者告警中更推荐使用 rate 函数,因为当速率只出现一个短暂的峰值时,不应该触发该报警。
使用 irate() 函数上面的表达式会出现一些短暂下降的图形:
irate 示例
除了计算每秒速率,你还可以使用 increase() 函数查询指定时间范围内的总增量,它基本上相当于速率乘以时间范围选择器中的秒数:
increase(demo_api_request_duration_seconds_count{job="demo"} 1h])
比如上面表达式的结果和使用 rate() 函数计算的结果整体图形趋势都是一样的,只是 Y 轴的数据不一样而已,一个表示数量,一个表示百分比。rate()、irate() 和 increase() 函数只能输出非负值的结果,对于跟踪一个可以上升或下降的值的指标(如温度、内存或磁盘空间),可以使用 delta() 和 deriv() 函数来代替。
deriv() 函数可以计算一个区间向量中各个时间序列二阶导数,使用简单线性回归,deriv(v range-vector) 的参数是一个区间向量,返回一个瞬时向量,这个函数一般只用在 Gauge 类型的时间序列上。例如,要计算在 15 分钟的窗口下,每秒钟磁盘使用量上升或下降了多少:
deriv 函数
还有另外一个 predict_linear() 函数可以预测一个 Gauge 类型的指标在未来指定一段时间内的值,例如我们可以根据过去 15 分钟的变化情况,来预测一个小时后的磁盘使用量是多少,可以用如下所示的表达式来查询:
predict_linear(demo_disk_usage_bytes{job="demo"} 15m], 3600)
磁盘空间预测
这个函数可以用于报警,告诉我们磁盘是否会在几个小时候内用完。
聚合
我们知道 Prometheus 的时间序列数据是多维数据模型,我们经常就有根据各个维度进行汇总的需求。
基于标签聚合
例如我们想知道我们的 demo 服务每秒处理的请求数,那么可以将单个的速率相加就可以。
sum(rate(demo_api_request_duration_seconds_count{job="demo"} 5m]))
可以得到如下所示的结果:
计算每秒处理请求数
但是我们可以看到绘制出来的图形没有保留任何标签维度,一般来说可能我们希望保留一些维度,例如,我们可能更希望计算每个 instance 和 path 的变化率,但并不关心单个 method 或者 status 的结果,这个时候我们可以在 sum() 聚合器中添加一个 without() 的修饰符:
sum without(method, status) (rate(demo_api_request_duration_seconds_count{job="demo"} 5m]))
上面的查询语句相当于用 by() 修饰符来保留需要的标签的取反操作:
sum by(instance, path, job) (rate(demo_api_request_duration_seconds_count{job="demo"} 5m]))
现在得到的 sum 结果是就是按照 instance、path、job 来进行分组去聚合的了:
分组聚合
这里的分组概念和 SQL 语句中的分组去聚合就非常类似了。
除了 sum() 之外,Prometheus 还支持下面的这些聚合器:
-
sum():对聚合分组中的所有值进行求和 -
min():获取一个聚合分组中最小值 -
max():获取一个聚合分组中最大值 -
avg():计算聚合分组中所有值的平均值 -
stddev():计算聚合分组中所有数值的标准差 -
stdvar():计算聚合分组中所有数值的标准方差 -
count():计算聚合分组中所有序列的总数 -
count_values():计算具有相同样本值的元素数量 -
bottomk(k, ...):计算按样本值计算的最小的 k 个元素 -
topk(k,...):计算最大的 k 个元素的样本值 -
quantile(φ,...):计算维度上的 φ-分位数(0≤φ≤1) -
group(...):只是按标签分组,并将样本值设为 1。
练习:
1.按
job分组聚合,计算我们正在监控的所有进程的总内存使用量(process_resident_memory_bytes指标):
sum by(job) (process_resident_memory_bytes)
2.计算 demo_cpu_usage_seconds_total 指标有多少不同的 CPU 模式:
count (group by(mode) (demo_cpu_usage_seconds_total))
3.计算每个 job 任务和指标名称的时间序列数量:
count by (job, __name__) ({__name__ != ""})
基于时间聚合
前面我们已经学习了如何使用 sum()、avg() 和相关的聚合运算符从标签维度进行聚合,这些运算符在一个时间内对多个序列进行聚合,但是有时候我们可能想在每个序列中按时间进行聚合,例如,使尖锐的曲线更平滑,或深入了解一个序列在一段时间内的最大值。
为了基于时间来计算这些聚合,PromQL 提供了一些与标签聚合运算符类似的函数,但是在这些函数名前面附加了 _over_time():
-
avg_over_time(range-vector):区间向量内每个指标的平均值。 -
min_over_time(range-vector):区间向量内每个指标的最小值。 -
max_over_time(range-vector):区间向量内每个指标的最大值。 -
sum_over_time(range-vector):区间向量内每个指标的求和。 -
count_over_time(range-vector):区间向量内每个指标的样本数据个数。 -
quantile_over_time(scalar, range-vector):区间向量内每个指标的样本数据值分位数。 -
stddev_over_time(range-vector):区间向量内每个指标的总体标准差。 -
stdvar_over_time(range-vector):区间向量内每个指标的总体标准方差。
例如,我们查询 demo 实例中使用的 goroutine 的原始数量,可以使用查询语句 go_goroutines{job="demo"},这会产生一些尖锐的峰值图:
goroutines
我们可以通过对图中的每一个点来计算 10 分钟内的 goroutines 数量进行平均来使图形更加平滑:
avg_over_time(go_goroutines{job="demo"} 10m])
这个查询结果生成的图表看起来就平滑很多了:
平滑
比如要查询 1 小时内内存的使用率则可以用下面的查询语句:
100 * (1 - ((avg_over_time(node_memory_MemFree_bytes 1h]) + avg_over_time(node_memory_Cached_bytes 1h]) + avg_over_time(node_memory_Buffers_bytes 1h])) / avg_over_time(node_memory_MemTotal_bytes 1h])))
子查询
上面所有的 _over_time() 函数都需要一个范围向量作为输入,通常情况下只能由一个区间向量选择器来产生,比如 my_metric 5m]。但是如果现在我们想使用例如 max_over_time() 函数来找出过去一天中 demo 服务的最大请求率应该怎么办呢?
请求率 rate 并不是一个我们可以直接选择时间的原始值,而是一个计算后得到的值,比如:
rate(demo_api_request_duration_seconds_count{job="demo"} 5m])
如果我们直接将表达式传入 max_over_time() 并附加一天的持续时间查询的话就会产生错误:
# ERROR!
max_over_time(
rate(
demo_api_request_duration_seconds_count{job="demo"} 5m]
) 1d]
)
实际上 Prometheus 是支持子查询的,它允许我们首先以指定的步长在一段时间内执行内部查询,然后根据子查询的结果计算外部查询。子查询的表示方式类似于区间向量的持续时间,但需要冒号后添加了一个额外的步长参数:<duration>:<resolution>]。
这样我们可以重写上面的查询语句,告诉 Prometheus 在一天的范围内评估内部表达式,步长分辨率为 15s:
max_over_time(
rate(
demo_api_request_duration_seconds_count{job="demo"} 5m]
) 1d:15s] # 在1天内明确地评估内部查询,步长为15秒
)
也可以省略冒号后的步长,在这种情况下,Prometheus 会使用配置的全局 evaluation_interval 参数进行评估内部表达式:
max_over_time(
rate(
demo_api_request_duration_seconds_count{job="demo"} 5m]
) 1d:]
)
这样就可以得到过去一天中 demo 服务最大的 5 分钟请求率,不过冒号仍然是需要的,以明确表示运行子查询。子查询还允许添加一个偏移修饰符 offset 来对内部查询进行时间偏移,类似于瞬时和区间向量选择器。
但是也需要注意长时间计算子查询代价也是非常昂贵的,我们可以使用记录规则(后续会讲解)预先记录中间的表达式,而不是每次运行外部查询时都实时计算它。
练习:
输出过去一小时内 demo 服务的最大 95 分位数延迟值(1 分钟内平均),按 path 划分:
max_over_time(
histogram_quantile(0.95, sum by(le, path) (
rate(demo_api_request_duration_seconds_bucket 1m])
)
) 1h:]
)
运算
Prometheus 的查询语言支持基本的逻辑运算和算术运算。
算术运算符
在 Prometheus 系统中支持下面的二元算术运算符:
-
+加法 -
-减法 -
*乘法 -
/除法 -
%模 -
^幂等
最简单的我们可以将一个数字计算当做一个 PromQL 语句,用于标量与标量之间计算,比如:
(2 + 3 / 6) * 2^2
可以得到如下所示的结果:
! 标量计算](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210416163447.png)
图形中返回的是一个值为 10 的标量(scalar)类型的数据。
二元运算同样适用于向量和标量之间,例如我们可以将一个字节数除以两次 1024 来转换为 MiB,如下查询语句:
demo_batch_last_run_processed_bytes{job="demo"} / 1024 / 1024
最后计算的结果就是 MiB 单位的了:
! 向量和标量运算](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210416163824.png)
另外 PromQL 的一个强大功能就是可以让我们在向量与向量之间进行二元运算。
例如 demo_api_request_duration_seconds_sum 的数据包含了在 path、method、status 等不同维度上花费的总时间,指标 demo_api_request_duration_seconds_count 包含了上面同维度下的请求总次数。则我们可以用下面的语句来查询过去 5 分钟的平均请求持续时间:
rate(demo_api_request_duration_seconds_sum{job="demo"} 5m])
/
rate(demo_api_request_duration_seconds_count{job="demo"} 5m])
PromQL 会通过相同的标签集自动匹配操作符左边和右边的元素,并将二元运算应用到它们身上。由于上面两个指标的标签集合都是一致的,所有可以得到相同标签集的平均请求延迟结果:
! 向量与向量运算](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210416165340.png)
向量匹配
一对一
上面的示例其实就是一对一的向量匹配,但是一对一向量匹配也有两种情况,就是是否按照所有标签匹配进行计算,下图是匹配所有标签的情况:
! onetoone](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211006160513.png)
图中我们两个指标 foo 和 bar,分别生成了 3 个序列:
# TYPE foo gauge
foo{color="red", size="small"} 4
foo{color="green", size="medium"} 8
foo{color="blue", size="large"} 16
# TYPE bar gauge
bar{color="green", size="xlarge"} 2
bar{color="blue", size="large"} 7
bar{color="red", size="small"} 5
当我们执行查询语句 foo{} + bar{} 的时候,对于向量左边的每一个元素,操作符都会尝试在右边里面找到一个匹配的元素,匹配是通过比较所有的标签来完成的,没有匹配的元素会被丢弃,我们可以看到其中的 foo{color="green", size="medium"} 与 bar{color="green", size="xlarge"} 两个序列的标签是不匹配的,其余两个序列标签匹配,所以计算结果会抛弃掉不匹配的序列,得到的结果为其余序列的值相加。
上面例子中其中不匹配的标签主要是因为第二个 size 标签不一致造成的,那么如果我们在计算的时候忽略掉这个标签可以吗?如下图所示:
! onetoone](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211006162136.png)
同样针对上面的两个指标,我们在进行计算的时候可以使用 on 或者 ignoring 修饰符来指定用于匹配的标签进行计算,由于示例中两边的标签都具有 color 标签,所以在进行计算的时候我们可以基于该标签(on (color))或者忽略其他的标签(ignoring (size))进行计算,这样得到的结果就是所以匹配的标签序列相加的结果,要注意结果中的标签也是匹配的标签。
一对多与多对一
上面讲解的一对一的向量计算是最直接的方式,在多数情况下,on 或者 ignoring 修饰符有助于是查询返回合理的结果,但通常情况用于计算的两个向量之间并不是一对一的关系,更多的是一对多或者多对一的关系,对于这种场景我们就不能简单使用上面的方式进行处理了。
多对一和一对多两种匹配模式指的是一侧的每一个向量元素可以与多侧的多个元素匹配的情况,在这种情况下,必须使用 group 修饰符:group_left 或者 group_right 来确定哪一个向量具有更高的基数(充当多的角色)。多对一和一对多两种模式一定是出现在操作符两侧表达式返回的向量标签不一致的情况,因此同样需要使用 ignoring 和 on 修饰符来排除或者限定匹配的标签列表。
例如 demo_num_cpus 指标告诉我们每个实例的 CPU 核心数量,只有 instance 和 job 这两个标签维度。
! demo_num_cpus 指标](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210416171427.png)
而 demo_cpu_usage_seconds_total 指标则多了一个 mode 标签的维度,将每个 mode 模式(idle、system、user)的 CPU 使用情况分开进行了统计。
! demo_cpu_usage_seconds_total 指标](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210416171541.png)
如果要计算每个模式的 CPU 使用量除以核心数,我们需要告诉除法运算符按照 demo_cpu_usage_seconds_total 指标上额外的 mode 标签维度对结果进行分组,我们可以使用 group_left(表示左边的向量具有更高的基数)修饰符来实现。同时,我们还需要通过 on() 修饰符明确将所考虑的标签集减少到需要匹配的标签列表:
rate(demo_cpu_usage_seconds_total{job="demo"} 5m])
/ on(job, instance) group_left
demo_num_cpus{job="demo"}
上面的表达式可以正常得到结果:
! group_left 模式](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210416173045.png)
除了 on() 之外,还可以使用相反的 ignoring() 修饰符,可以用来将一些标签维度从二元运算操作匹配中忽略掉,如果在操作符的右侧有额外的维度,则应该使用 group_right(表示右边的向量具有更高的基数)修饰符。
比如上面的查询语句同样可以用 ignoring 关键字来完成:
rate(demo_cpu_usage_seconds_total{job="demo"} 5m])
/ ignoring(mode) group_left
demo_num_cpus{job="demo"}
得到的结果和前面用 on() 查询的结果是一致的。
到这里我们就知道了如何在 PromQL 中进行标量和向量之间的运算了。不过我们在使用 PromQL 查询数据的时候还行要避免使用关联查询,先想想能不能通过 Relabel(后续会详细介绍)的方式给原始数据多加个 Label,一条语句能查出来的何必用 Join 呢?时序数据库不是关系数据库。
练习:
1.计算过去 5 分钟所有 POST 请求平均数的总和相对于所有请求平均数总和的百分比。
sum(rate(demo_api_request_duration_seconds_count{method="POST"} 5m]))
/
sum(rate(demo_api_request_duration_seconds_count 5m])) * 100
2.计算过去 5 分钟内每个实例的 user 和 system 的模式(demo_cpu_usage_seconds_total 指标)下 CPU 使用量平均值总和。
sum by(instance, job) (rate(demo_cpu_usage_seconds_total{mode=~"user|system"} 5m]))
或者
sum without(mode) (rate(demo_cpu_usage_seconds_total{mode=~"user|system"} 5m]))
或者
rate(demo_cpu_usage_seconds_total{mode="user"} 5m]) + ignoring(mode)
rate(demo_cpu_usage_seconds_total{mode="system"} 5m])
阈值
PromQL 通过提供一组过滤的二元运算符(>、<、== 等),允许根据其样本值过滤一组序列,这种过滤最常见的场景就是在报警规则中使用的阈值。比如我们想查找在过去 15 分钟内的 status="500" 错误率大于 20% 的所有 HTTP 路径,我们在 rate 表达式后面添加一个 >0.2 的过滤运算符:
rate(demo_api_request_duration_seconds_count{status="500",job="demo"} 15m]) > 0.2
这个查询只会将错误率大于 20% 的数据过滤出来。
! >20%](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210604115346.png)
注意:由于在图形中的每个步长都是完全独立评估表达式的,因此根据每个步骤的过滤条件,某些比率会出现或消失(因此存在间隙)。 一般来说,二元过滤运算符在图形中并不常见,大多数在报警条件中出现,用来表示阈值。
这种过滤方式不仅适用于单个数字,PromQL 还允许你用一组时间序列过滤另一组序列。与上面的二元运算一样,比较运算符会自动应用于比较左侧和右侧具有相同标签集的序列之间。 on() / ignoring() 和 group_left() / group_right() 修饰符的作用也与我们前面学习的二元算术运算符一样。
以下示例是选择所有具有 500 错误率且至少比同一路径的总请求率大 50 倍的路径:
rate(demo_api_request_duration_seconds_count{status="500",job="demo"} 5m]) * 50
> ignoring(status)
sum without(status) (rate(demo_api_request_duration_seconds_count{job="demo"} 5m]))
不过需要注意的是我们必须忽略匹配中的 status 标签,因为在左边一直有这个标签,而右边没有这个标签。
! 错误率](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210604115543.png)
比如我们还可以计算 demo 演示服务实例在一小时内的预测磁盘使用量,但要过滤只有那些预测磁盘已满的实例。
predict_linear(demo_disk_usage_bytes{job="demo"} 1h], 3600) >= demo_disk_total_bytes{job="demo"}
Prometheus 支持以下过滤操作:
-
== -
!= -
< -
<= -
> -
>=
有时你可能想知道比较运算符的结果而不实际删除任何输出系列。要实现这一点,我们可以向运算符添加一个 bool 修饰符来保留所有的序列,但是把输出样本值设置为 1(比较为真)或 0(比较为假)。
例如,要简单地显示一组数据中哪些请求率高于或低于 0.2/s,我们可以这样查询:
rate(demo_api_request_duration_seconds_count{job="demo"} 5m]) > bool 0.2
我们可以看到输入序列的结果为 0 或 1,把数字条件转换为了布尔输出值。
! bool修饰符](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210604115043.png)
练习:
1.构建一个查询,显示使用少于 20MB 内存的目标(
process_resident_memory_bytes指标)。
process_resident_memory_bytes / 1024^2 < 20
2.构建一个查询,显示 Prometheus 服务内部所有在过去 5 分钟内没有收到任何查询的 HTTP 处理器。
rate(prometheus_http_requests_total 5m]) == 0
集合操作
有的时候我们需要过滤或将一组时间序列与另一组时间序列进行合并,Prometheus 提供了 3 个在瞬时向量之间操作的集合运算符。
-
and(集合交集):比如对较高错误率触发报警,但是只有当对应的总错误率超过某个阈值的时候才会触发报警 -
or(集合并集):对序列进行并集计算 -
unless(除非):比如要对磁盘空间不足进行告警,除非它是只读文件系统。
union
与算术和过滤二元运算符类似,这些集合运算符会尝试根据相同的标签集在左侧和右侧之间查找来匹配序列,除非你提供 on() 或 ignoring() 修饰符来指定应该如何找到匹配。
注意:与算术和过滤二进制运算符相比,集合运算符没有
group_left()或group_right()修饰符,因为集合运算符总是进行多对多的匹配,也就是说,它们总是允许任何一边的匹配序列与另一边的多个序列相匹配。
对于 and 运算符,如果找到一个匹配的,左边的序列就会成为输出结果的一部分,如果右边没有匹配的序列,则不会输出任何结果。
例如我们想筛选出第 90 个百分位延迟高于 50ms 的所有 HTTP 端点,但只针对每秒收到多个请求的维度组合,查询方式如下所示:
histogram_quantile(0.9, rate(demo_api_request_duration_seconds_bucket{job="demo"} 5m])) > 0.05
and
rate(demo_api_request_duration_seconds_count{job="demo"} 5m]) > 1
有的时候我们也需要对两组时间序列进行合并操作,而不是交集,这个时候我们可以使用 or 集合运算符,产生的结果是运算符左侧的序列,加上来自右侧但左侧没有匹配标签集的时间序列。比如我们要列出所有低于 10 或者高于 30 的请求率,则可以用下面的表达式来查询:
rate(demo_api_request_duration_seconds_count{job="demo"} 5m]) < 10
or
rate(demo_api_request_duration_seconds_count{job="demo"} 5m]) > 30
我们可以看到在图中使用值过滤器和集合操作会导致时间序列在图中有断点现象,这取决于他们在图中的时间间隔下是否能够与过滤器进行匹配,所以一般情况下,我们建议只在告警规则中使用这种过滤操作。
还有一个 unless 操作符,它只会保留左边的时间序列,如果右边不存在相等的标签集合的话。
练习:
1.构建一个查询,显示按 path、method、status(5 分钟内平均)划分的 demo API 请求的第 95 个百分位延迟,除非这个维度组合每秒收到的请求少于 1 个请求(5 分钟内平均)。
histogram_quantile(0.95, sum by(path, method, status, le) (rate(demo_api_request_duration_seconds_bucket 5m]))) unless sum by(path, method, status) (rate(demo_api_request_duration_seconds_count 5m])) < 1
排序
本节我们将学习如何对查询结果进行排序,或者只选择一组序列中最大或最小的值。
我们可以使用 sort()(升序) 或者 sort_desc()(降序)函数来实现对输出结果进行排序,例如,要显示按值排序的每个路径请求率,从最高到最低,我们可以用下面的语句进行查询:
sort_desc(sum by(path) (rate(demo_api_request_duration_seconds_count{job="demo"} 5m])))
有的时候我们并不是对所有的时间序列感兴趣,只对最大或最小的几个序列感兴趣,我们可以使用 topk() 和 bottomk() 这两个运算符来操作,可以返回 K 个最大或最小的序列,比如只显示每个 path 和 method 的前三的请求率,我们可以使用下面的语句来查询。
topk(3, sum by(path, method) (rate(demo_api_request_duration_seconds_count{job="demo"} 5m])))
直方图
在这一节中,我们将学习直方图指标,了解如何根据这些指标来计算分位数。Prometheus 中的直方图指标允许一个服务记录一系列数值的分布。直方图通常用于跟踪请求的延迟或响应大小等指标值,当然理论上它是可以跟踪任何根据某种分布而产生波动数值的大小。Prometheus 直方图是在客户端对数据进行的采样,它们使用的一些可配置的(例如延迟)bucket 桶对观察到的值进行计数,然后将这些 bucket 作为单独的时间序列暴露出来。
下图是一个非累积直方图的例子:
! 非累积直方图](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210417140114.png)
在 Prometheus 内部,直方图被实现为一组时间序列,每个序列代表指定桶的计数(例如10ms以下的请求数、25ms以下的请求数、50ms以下的请求数等)。 在 Prometheus 中每个 bucket 桶的计数器是累加的,这意味着较大值的桶也包括所有低数值的桶的计数。在作为直方图一部分的每个时间序列上,相应的桶由特殊的 le 标签表示。le 代表的是小于或等于。
与上面相同的直方图在 Prometheus 中的累积直方图如下所示:
! Prometheus 直方图](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210603145656.png)
可以看到在 Prometheus 中直方图的计数是累计的,这是很奇怪的,因为通常情况下非累积的直方图更容易理解。Prometheus 为什么要这么做呢?想象一下,如果直方图指标中加入了额外的标签,或者划分了更多的 bucket,那么样本数据的分析就会变得越来越复杂,如果直方图是累积的,在抓取指标时就可以根据需要丢弃某些 bucket,这样可以在降低 Prometheus 维护成本的同时,还可以粗略计算样本值的分位数。通过这种方法,用户不需要修改应用代码,便可以动态减少抓取到的样本数量。另外直方图还提供了 _sum 指标和 _count 指标,所以即使你丢弃了所有的 bucket,仍然可以通过这两个指标值来计算请求的平均响应时间。通过累积直方图的方式,还可以很轻松地计算某个 bucket 的样本数占所有样本数的比例。
我们在演示的 demo 服务中暴露了一个直方图指标 demo_api_request_duration_seconds_bucket,用于跟踪 API 请求时长的分布,由于这个直方图为每个跟踪的维度导出了 26 个 bucket,因此这个指标有很多时间序列。我们可以先来看下来自一个服务实例的一个请求维度组合的直方图,查询语句如下所示:
demo_api_request_duration_seconds_bucket{instance="demo-service-0:10000", method="POST", path="/api/bar", status="200", job="demo"}
正常我们可以看到 26 个序列,每个序列代表一个 bucket,由 le 标签标识:
! 26个序列](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210603164356.png)
直方图可以帮助我们了解这样的问题,比如"我有多少个请求超过了100ms的时间?" (当然需要直方图中配置了一个以 100ms 为边界的桶),又比如"我99%的请求是在多少延迟下完成的?",这类数值被称为百分位数或分位数。在 Prometheus 中这两个术语几乎是可以通用,只是百分位数指定在 0-100 范围内,而分位数表示在 0 和 1 之间,所以第 99 个百分位数相当于目标分位数 0.99。
如果你的直方图桶粒度足够小,那么我们可以使用 histogram_quantile(φ scalar, b instant-vector) 函数用于计算历史数据指标一段时间内的分位数。该函数将目标分位数 (0 ≤ φ ≤ 1) 和直方图指标作为输入,就是大家平时讲的 pxx,p50 就是中位数,参数 b 一定是包含 le 这个标签的瞬时向量,不包含就无从计算分位数了,但是计算的分位数是一个预估值,并不完全准确,因为这个函数是假定每个区间内的样本分布是线性分布来计算结果值的,预估的准确度取决于 bucket 区间划分的粒度,粒度越大,准确度越低。
回到我们的演示服务,我们可以尝试计算所有维度在所有时间内的第 90 个百分位数,也就是 90% 的请求的持续时间。
# BAD!
histogram_quantile(0.9, demo_api_request_duration_seconds_bucket{job="demo"})
但是这个查询方式是有一点问题的,当单个服务实例重新启动时,bucket 的 Counter 计数器会被重置,而且我们常常想看看现在的延迟是多少(比如在过去 5 分钟内),而不是整个时间内的指标。我们可以使用 rate() 函数应用于底层直方图计数器来实现这一点,该函数会自动处理 Counter 重置,又可以只计算每个桶在指定时间窗口内的平均增长。
我们可以这样去计算过去 5 分钟内第 90 个百分位数的 API 延迟:
# GOOD!
histogram_quantile(0.9, rate(demo_api_request_duration_seconds_bucket{job="demo"} 5m]))
这个查询就好很多了。
! API 延迟](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210603170845.png)
这个查询会显示每个维度(job、instance、path、method 和 status)的第 90 个百分点,但是我们可能对单独的这些维度并不感兴趣,想把他们中的一些指标聚合起来,这个时候我们可以在查询的时候使用 Prometheus 的 sum 运算符与 histogram_quantile() 函数结合起来,计算出聚合的百分位,假设在我们想要聚合的维度之间,直方图桶的配置方式相同(桶的数量相同,上限相同),我们可以将不同维度之间具有相同 le 标签值的桶加在一起,得到一个聚合直方图。然后,我们可以使用该聚合直方图作为 histogram_quantile() 函数的输入。
注意:这是假设直方图的桶在你要聚合的所有维度之间的配置是相同的,桶的配置也应该是相对静态的配置,不会一直变化,因为这会破坏你使用
histogram_quantile()查看的时间范围内的结果。
下面的查询计算了第 90 个百分位数的延迟,但只按 job、instance 和 path 维度进行聚合结果:
数据对比
有的时候我们可能需要去访问过去的数据,并和当前数据进行对比。例如,我们可能想比较今天的请求率和一周前的请求率之间的差异。我们可以在任何区间向量或瞬时向量选择器上附加一个偏移量 offset<duration> 的修饰符(比如 my_metric offset 5m 或者 my_metric 1m] offset 7d)。
让我们来看一个示例,在我们的 demo 服务中暴露了一个 Counter 指标 demo_items_shipped_total,该指标追踪物品的运输情况,用 5 分钟来模拟"每日"流量周期,所以我们不必等待一整天才能查看该时段的数据。
我们只使用第一个演示服务实例来测试即可,首先我们来看看它的速率:
rate(demo_items_shipped_total{instance="demo-service-0:10000"} 1m])
! 对比](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210604165153.png)
该服务还暴露了一个 0 或 1 的布尔指标,告诉我们现在是否是假期:
! holiday 指标](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210604165455.png)
将假期与发货商品率进行比较,注意到节假日时它会减少!我们可以尝试将当前的发货速度与 7"天"(7 * 5 分钟)前的速度进行比较,看看是否有什么不正常的情况。
rate(demo_items_shipped_total{instance="demo-service-0:10000"} 1m])
/
rate(demo_items_shipped_total{instance="demo-service-0:10000"} 1m] offset 35m)
通常情况下,该比率约为 1,但当当天或前一天是假期时,我们得到的比率比正常情况下要略低或高。
! 对比](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210604170248.png)
但是,如果原因只是假期,我们想忽略这个较低或较高的比率。我们可以在过去或现在是假期的时候过滤掉这个比率,方法是附加一个 unless 集合操作符。
(
rate(demo_items_shipped_total{instance="demo-service-0:10000"} 1m])
/
rate(demo_items_shipped_total{instance="demo-service-0:10000"} 1m] offset 35m)
)
unless
(
demo_is_holiday == 1 # Is it currently a holiday?
or
demo_is_holiday offset 35m == 1 # Was it a holiday 7 "days" ago?
)
或者另外一种方法,我们只需要比较今天和一周前是否有相同的节日:
(
rate(demo_items_shipped_total{instance="demo-service-0:10000"} 1m])
/
rate(demo_items_shipped_total{instance="demo-service-0:10000"} 1m] offset 35m)
)
unless
(
demo_is_holiday
!=
demo_is_holiday offset 35m
)
这样我们就可以过滤掉当前时间有假期或过去有假期的结果。
检测
本节我们将学习如何来检查我们的实例数据抓取健康状况。
检查抓取实例
每当 Prometheus 抓取一个目标时,它都会存储一个合成的样本,其中包含指标名称 up 和被抓取实例的 job 和 instance 标签,如果抓取成功,则样本的值被设置为 1,如果抓取失败,则设置为 0,所以我们可以通过如下所示的查询来获取当前哪些实例处于正常或挂掉的状态:
up{job="demo"}
正常三个演示服务实例都处于正常状态,所以应该都为1。如果我们将第一个实例停掉,重新查询则第一个实例结果为0:
! up](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210922110731.png)
如果只希望显示 down 掉的实例,可以通过过滤0值来获取:
up{job="demo"} == 0
! down](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210922111123.png)
或者获取挂掉实例的总数:
count by(job) (up{job="demo"} == 0)
! count](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210922111212.png)
一般情况下这种类型的查询会用于指标抓取健康状态报警。
注意:因为
count()是一个聚合运算符,它期望有一组维度的时间序列作为其输入,并且可以根据by或without子句将输出序列分组。任何输出组只能基于现有的输入序列,如果根本没有输入序列,就不会产生输出。
检查序列数据
在某些情况下,只查看序列的样本值是不够的,有时还需要检测是否存在某些序列,上面我们用 up{job="demo"} == 0 语句来查询所有无法抓取的演示服务实例,但是只有已经被抓取的目标才会被加上 up 指标,如果 Prometheus 都没有抓取到任何的演示服务目标应该怎么办呢?比如它的抓取配置出问题了,服务发现可能返回也为空,或者由于 Prometheus 自身出了某些问题。
在这种情况下,absent() 函数就非常有用了,absent() 将一个瞬时向量作为其输入,当输入包含序列时,将返回一个空结果,不包含时将返回单个输出序列,而且样本值为1。
例如,查询语句 absent(up{job="demo"}) 将得到一个空的输出结果,如果测试一个没有被抓取的 job 是否存在的时候,将得到样本值1。
! non-existent](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210922114313.png)
这可以帮助我们检测序列是否存在的情况。此外还有一个 absent() 的变种,叫做 absent_over_time(),它接受一个区间向量,告诉你在该输入向量的整个时间范围内是否有样本
服务发现
Relabeling 重新标记
Relabeling 重新标记用于配置 Prometheus 元信息的方式,它是转换和过滤 Prometheus 中 label 标签对象的核心,本章节我们将了解 Relabeling 规则的工作原理,并能够将它们应用于不同的场景中。
概述
Prometheus 发现、抓取和处理不同类型的 label 标签对象,根据标签值操作或过滤这些对象非常有用,比如:
-
只监视具有特定服务发现注解的某些目标,通常在服务发现中使用
-
向目标抓取请求添加 HTTP 查询参数
-
仅存储从指定目标中提取样本的子集
-
将抓取序列的两个标签值合并为一个标签
Relabeling 是作为一系列转换步骤实现的,我们可以在 Prometheus 的配置文件中应用这些步骤来过滤或修改标记对象,我们可以对一下类型的标记对象应用 Relabeling 操作:
-
发现的抓取目标(
relabel_configs) -
抓取的单个样本(
metric_relabel_configs) -
发送给 Alertmanager 的报警(
alert_relabel_configs) -
写到远程存储的样本(
write_relabel_configs)
! relabel configs](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210922161930.png)
平时在配置监控目标的时候我们更多的会使用
relabel_configs与metric_relabel_configs两个配置,采集数据之前,通过relabel_configs,采集数据之后,写入存储之前,通过metric_relabel_configs进行配置。
所有这些 relabeling 配置块都是相同类型的 relabel_config,每个配置块都由一个规则列表组成,这些规则依次应用与每个标记的对象。
! relabeling rules](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210922162119.png)
例如,一个 relabeling 规则可以根据正则表达式的匹配来保留或丢弃一个对象,可以修改其标签,也可以将一整组标签映射到另一组。一旦一个 relabeling 步骤决定放弃一个有标签的对象,就不会对这个对象执行进一步的 relabeling 步骤,它将从输出列表中删除。
隐藏的标签与元数据
以双下划线__开头的标签属于特殊的标签,它们在重新标记后会被删除。标记对象的来源最初可以附加这些隐藏的标签,以提供关于标记对象的额外元数据,这些特殊的标签可以在 relabeling 阶段被用来对对象的标签进行修改。
对于抓取指标,其中就包含一些隐藏的标签,可以用来控制目标应该如何被抓取。
-
__address__:包含应该被抓取目标的地址,它最初默认为服务发现机制提供的<host>:<port>,如果在此之前没有明确地将实例标签 instance 设置为其他值,那么在 relabeling 之后,Prometheus 会将 instance 标签设置为__address__的值。 -
__scheme__:抓取目标的请求模式,包括 http 与 https,默认为 http。 -
__metrics_path__:表示用于采集指标的 HTTP 路径,默认为/metrics。 -
__param_<name>: 包含 HTTP 查询参数名称和它们的值。
上面的这些标签都可以使用 relabeling 规则来设置或覆盖,这样就可以为抓取目标进行自定义抓取行为。
此外,服务发现机制也可以提供一组以 __meta_ 开头的标签,包含关于目标的特定发现元数据。例如,当发现 Kubernetes 集群中的 pod 时,Kubernetes 服务发现引擎将为每个 pod 目标提供一个 __meta_kubernetes_pod_name 的标签,包含被发现的 pod 的名字,以及一个 __meta_kubernetes_pod_ready 标签,表明 pod 是否处于就绪状态,关于服务发现生成的元标签可以查看官方文档 Configuration | Prometheus 了解更多。
如果一个 relabeling 步骤需要将一个值保存到一个临时标签中(以便在随后的步骤中处理),那么我们可以使用 __tmp 标签名称前缀进行标记,以 __tmp 开通的标签是不会被 Prometheus 本身使用的。
规则
Relabeling 规则主要由以下的一些配置属性组成,但对于每种类型的操作,只使用这些字段的一个子集。
-
action:执行的 relabeling 动作,可选值包括replace、keep、drop、hashmod、labelmap、labeldrop或者labelkeep,默认值为replace。 -
separator:分隔符,一个字符串,用于在连接源标签source_labels时分隔它们,默认为;。 -
source_labels:源标签,使用配置的分隔符串联的标签名称列表,并与提供的正则表达式进行匹配。 -
target_label:目标标签,当使用 replace 或者 hashmod 动作时,应该被覆盖的标签名。 -
regex:正则表达式,用于匹配串联的源标签,默认为(.*),匹配任何源标签。 -
modulus:模数,串联的源标签哈希值的模,主要用于 Prometheus 水平分片。 -
replacement:replacement 字符串,写在目标标签上,用于替换 relabeling 动作,它可以参考由 regex 捕获的正则表达式捕获组。
设置或替换标签值
Relabeling 的一个常见操作就是设置或者覆盖一个标签的值,我们可以通过 replace 这个操作来完成,如果没有指定 action 字段,则默认就是 replace。
一个 replace 动作的规则配置方式如下所示:
action: replace source_labels: <source label name list>] separator: <source labels separator> # 默认为 ';' regex: <regular expression> # 默认为 '(.*)' (匹配任何值)) replacement: <replacement string> # 默认为 '$1' (使用第一个捕获组作为 replacement) target_label: <target label>
该操作按顺序执行以下步骤:
-
使用提供的 separator 分隔符将 source_labels 中的标签列表值连接起来
-
测试 regex 中的正则表达式是否与上一步连接的字符串匹配,如果不匹配,就跳到下一个 relabeling 规则,不替换任何东西
-
如果正则匹配,就提取正则表达式捕获组中的值,并将 replacement 字符串中对这些组的引用($1, $2, ...)用它们的值替换
-
把经过正则表达式替换的 replacement 字符串作为 target_label 标签的新值存储起来
下面我们来简单看一看 replace 操作的示例。
设置一个固定的标签值
最简单的 replace 例子就是将一个标签设置为一个固定的值,比如你可以把 env 标签设置为 production:
action: replace replacement: production target_label: env
这里我们并没有设置规则的大部分属性,这是因为大部分的默认值已经可以满足这里的需求了,这里会将替换的字符串 production 作为 target_label 标签 env 的新值存储起来,也就是将 env 标签的值设置为 production。
替换抓取任务端口
另一个稍微复杂的示例是重写一个被抓取任务实例的端口,我们可以用一个固定的 80 端口来替换 __address__ 标签的端口:
action: replace source_labels: __address__] regex: ( ^:]+)(?::\d+)? # 第一个捕获组匹配的是 host,第二个匹配的是 port 端口。 replacement: "$1:80" target_label: __address__
这里我们替换的源标签为 __address__,然后通过正则表达式 ( ^:]+)(?::\d+)? 进行匹配,这里有两个捕获组,第一个匹配的是 host($1),第二个匹配的是端口($2),所以在 replacement 字符串中我们保留第一个捕获组 $1,然后将端口更改为 80,这样就可以将 __address__ 的实例端口更改为 80 端口,然后重新写会 __address__ 这个目标标签。
保留或丢弃对象
Relabeling 另一个常见的用例就是过滤有标签的对象,keep 或 drop 这两个动作可以来完成,使用这两个操作,可以帮助我们完成如下的一些操作:
-
来自服务发现的哪些目标应该被抓取
-
从目标中抓取哪些指定的序列样本,或将其发送到远程存储
-
哪些报警要发送到 Alertmanager
一个 keep 动作的配置规则如下所示:
action: keep source_labels: <source label name list>] separator: <source labels separator> # 默认为 ';' regex: <regular expression> # 默认为 '(.*)' (匹配任何值)
keep 操作同样按顺序执行如下步骤:
-
使用 separator 分隔符将 source_labels 中列出的标签值连接起来
-
测试 regex 中的正则表达式是否与上一步的连接字符串匹配
-
如果不匹配,该对象将从最终输出列表中删除
-
如果匹配,则保留该对象
drop 动作和 keep 类似,只是它是删除一个对象而不是保留。
同样接下来看一看 keep 和 drop 的示例。
只抓取具有注解的目标
在服务发现的时候,我们可能只想抓取那些具有特定元数据标签的目标,例如,下面的配置让我们只抓取 Kubernetes 中具有 example.io/should_be_scraped=true 这个 annotation 的目标。
action: keep source_labels: __meta_kubernetes_service_annotation_example_io_should_be_scraped] regex: true
Kubernetes 服务发现机制下面会将 labels 标签与 annotation 作为元信息输出到 Prometheus,这些元信息都包含 __meta_ 前缀,这里我们的配置就是保留具有 example.io/should_be_scraped 这个 annotation 标签,且值为 true 的目标。
只存储特定的指标
当使用 metric_relabel_configs 来控制目标的抓取方式时,我们可以使用下面的规则来只存储指标名称以 api_ 或 http_ 开头的指标。
action: keep source_labels: __name__] regex: "(api_|http_).*"
标签集映射
有时我们可能想把源标签的值映射到一组新的标签中去,这个时候就可以使用 labelmap 这个动作了。labelmap 最常用的使用场景就是从服务发现中获取一组隐藏的或临时的元数据标签,并将它们映射到新的目标标签中。
labelmap 动作的配置规则如下所示:
action: labelmap regex: <regular expression> # 默认为 '(.*)' replacement: <replacement string> # 默认为 '$1'
和前面的一些 action 不同,labelmap 是对标签名而不是标签值进行重新匹配和操作。labelmap 按顺序执行以下步骤:
-
将 regex 中的正则表达式与所有标签名进行匹配
-
将匹配的标签名的任何匹配值复制到由
replacement字符串决定的新的标签名中
下面我们看一个使用 labelmap 映射 Kubernetes Service 标签的示例。当使用基于 Kubernetes 的服务发现来发现 pod 端点时,我们可能希望每个端点的最终目标标签也包含 Kubernetes Service 标签,这样可以更好的区分端点数据。Kubernetes 服务发现机制会将这些标签添加到 Prometheus 中去,标签名称格式为 __meta_kubernetes_service_label_<labelname>,我们可以提取这些元数据标签中的 <labelname> 部分,并将相应的标签值映射到一组以 k8s_ 为前缀的新标签名称上,如下所示:
action: labelmap regex: __meta_kubernetes_service_label_(.+) replacement: "k8s_$1"
通过上面的 labelmap 操作,regex 正则表达式中匹配标签名,然后将标签名对应的值复制到 k8s_$1 的新标签中,$1 就是匹配的标签名这个捕获组。
保留或删除标签
有的时候我们也有保留或删除一些标签的需求,比如有的目标在时间序列上提供了许多额外的标签,这些标签用途不大,这个时候我们就可以使用 labelkeep 和 labeldrop 这两个操作,使用这两个操作可以有选择地保留或删除一些标签。
labelkeep 的配置规则如下所示:
action: labelkeep regex: <regular expression> # 默认为'(.*)'
一样 labelkeep 按顺序执行下面的步骤:
-
首先将 regex 中的正则表达式与所有标签名称进行匹配
-
它只保留那些匹配的标签
labeldrop 与 labelkeep 类似,只是它是删除那些匹配正则表达式的标签而不是保留。
下面我们看一看 labelkeep/labeldrop 操作的简单示例。
从报警中删除高可用副本标签
当运行两个相同的 Prometheus 作高可用的时候,通常两个服务器都被配置为有一个外部标签(通过全局配置选项 external_labels),表明它们代表哪个副本,例如:replica: A 和 replica: B,在从两个副本向同一个 Alertmanager 实例发送报警之前,Prometheus 需要删除这个副本标签,这样 Alertmanager 就不会把收到的报警看成不同的报警了,否则可能我们会收到两个同样的报警通知。这个时候我们就可以使用 labeldrop 来实现这个操作。
action: labeldrop regex: replica
这条配置规则很简单的,就是匹配 replica 这个标签,然后执行 labeldrop 删除标签动作即可。
删除指标中不需要的标签
有的时候我们抓取的指标在每个时间序列上都附加了一些额外的标签,这些标签对于我们来说用处不大,还会增加 Prometheus 的存储压力,所以我们可以想办法删除不需要的额外标签。
比如现在我们想要删除一 info_ 开头的标签,我们可以使用下面的配置规则来完成。
action: labeldrop regex: info_.*
同样也只是配置一个要删除的目标标签的正则表达式即可,只要匹配了的标签都会执行 labeldrop 操作将该标签进行删除。
标签值哈希和分片
在一些场景下我们可能需要运行多个几乎相同的 Prometheus 副本来横向扩展,每个副本只抓取部分目标,这样可以降低 Prometheus 的压力,在这种情况下 hashmod 操作有助于我们对目标进行分片操作。
hashmod 的配置规则如下所示:
action: hashmod source_labels: <source label name list>] modulus: <modulus value> target_label: <target label>
该操作按顺序执行下面的步骤:
-
首先使用分隔符将源标签集 source_labels 的值连接起来
-
计算连接后的字符串的哈希值
-
将
modulus中提供的模数应用于哈希值,以将哈希值限制在 0 和modulus-1之间 -
将上一步的模数值存储在 target_label 目标标签中
使用 hashmod 的主要场景是将一个服务的整体目标进行分片,用于水平扩展 Prometheus,通过首先根据每个目标的一个或多个标签计算基于哈希的模数来实现的,然后只保留具有特定输出模数值的目标。比如为了根据 instance 标签对目标进行分片,只保留分片 2 的实例,我们可以把 hashmod 和 keep 结合起来操作。
- action: hashmod source_labels: instance] modulus: 10 target_label: __tmp_hashmod - action: keep source_labels: __tmp_hashmod] regex: 2
首先通过 hashmod 操作对 instance 标签进去哈希操作,将取模后的值存储在临时标签 __tmp_hashmod 中,然后通过第二个 keep 操作,只保留分片数为 2 的指标,这样就达到了分片的目的。
到这里我们基本上就了解了 relabeling 的使用,接下来我们可以来了解下服务发现在 Prometheus 中的使用。
服务发现
接下来我们将学习 Prometheus 中是如何使用服务发现来查找和抓取目标的。我们知道在 Prometheus 配置文件中可以通过一个 static_configs 来配置静态的抓取任务,但是在云环境下,特别是容器环境下,抓取目标地址是经常变动的,所以用静态的方式就不能满足这些场景了。所以我们需要监控系统能够动态感知这个变化,不可能每次变动都去手动重新配置的,为了应对复杂的动态环境,Prometheus 也提供了与基础设施中的服务发现集成的功能。
! 服务发现](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210924122153.png)
Prometheus 已经支持多种内置的服务发现机制:
-
发现云服务商的 VM 虚拟机
-
Kubernetes 上的自动发现
-
通用的服务查找,例如 DNS、Consul、Zookeeper 或自定义发现机制
我们都可以通过 Prometheus 配置文件中的 scrape_config 部分进行配置,Prometheus 会不断更新动态的抓取目标列表,自动停止抓取旧的实例,开始抓取新的实例,Prometheus 特别适合运行于 Kubernetes 集群下面,可以自动发现监控目标。
此外大部分服务发现机制还会提供目标的一些元数据,通常都是带有 __ 的前缀, 比如标签、注解、服务名等等,可以在 relabeling 阶段使用这些元数据来过滤修改目标,这些元信息标签在重新标记阶段后被删除。
基于 Consul 的服务发现
Consul](Consul by HashiCorp) 是由 HashiCorp](HashiCorp) 开发的一个支持多数据中心的分布式服务发现和键值对存储服务的开源软件,是一个通用的服务发现和注册中心工具,被大量应用于基于微服务的软件架构当中。
接下来我们就来尝试使用 Prometheus 基于 Consul 的服务发现来监控前面的 3 个 demo 服务:
192.168.31.46:10000 192.168.31.46:10001 192.168.31.46:10002
我们将 demo 服务注册到 Consul,然后配置 Prometheus 从 Consul 中发现演示服务实例,并使用 Relabeling 操作来过滤调整目标标签。关于 Consul 本身的使用可以查看官方文档 Tutorials | Consul | HashiCorp Developer 了解更多。
! consul](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210924150903.png)
安装配置 Consul
在页面 Install | Consul | HashiCorp Developer 下载符合自己系统的安装文件,比如我们这里是 Linux 系统,使用下面命令下载安装即可:
☸ ➜ wget https://releases.hashicorp.com/consul/1.10.2/consul_1.10.2_linux_amd64.zip ☸ ➜ unzip consul_1.10.2_linux_amd64.zip # 将 consul 二进制移动到 PATH 路径下去 ☸ ➜ mv consul /usr/local/bin ☸ ➜ consul version Consul v1.10.2 Revision 3cb6eeedb Protocol 2 spoken by default, understands 2 to 3 (agent will automatically use protocol >2 when speaking to compatible agents)
当执行 consul 命令后正常有命令提示,证明已经安装完成。接着创建一个用于注册 demo 服务的 Consul 配置文件 demo-service.json:
{
"services":
{
"id": "demo1",
"name": "demo",
"address": "192.168.31.46",
"port": 10000,
"meta": {
"env": "production"
},
"checks":
{
"http": "http://192.168.31.46:10000/api/foo",
"interval": "1s"
}
]
},
{
"id": "demo2",
"name": "demo",
"address": "192.168.31.46",
"port": 10001,
"meta": {
"env": "production"
},
"checks":
{
"http": "http://192.168.31.46:10001/api/foo",
"interval": "1s"
}
]
},
{
"id": "demo3",
"name": "demo",
"address": "192.168.31.46",
"port": 10002,
"meta": {
"env": "staging"
},
"checks":
{
"http": "http://192.168.31.46:10002/api/foo",
"interval": "1s"
}
]
}
]
}
当然一般情况下我们也是在 Consul 中进行动态注册服务,但是这里我们只是简单演示 Prometheus 基于 Consul 的服务发现,这里只使用 Consul 配置文件静态注册服务即可。Consul 允许使用 JSON 中的 meta属性将 key-value 元数据与每个注册的服务实例相关联,比如这里我们配置的 env 属性和部署环境 production 或 staging 进行关联,后面我们可以通过使用 Prometheus 里面的 Relabeling 操作提取该字段并将其映射到每个抓取实例的标签中去。
为了查看更多的日志信息,我们可以在 dev 模式下运行 Consul,如下所示:
☸ ➜ consul agent -dev -config-file=demo-service.json -client 0.0.0.0
==> Starting Consul agent...
Version: '1.10.2'
Node ID: 'a4a9418c-7f7d-a2da-c81e-94d3d37601aa'
Node name: 'node2'
Datacenter: 'dc1' (Segment: '<all>')
Server: true (Bootstrap: false)
Client Addr: 0.0.0.0] (HTTP: 8500, HTTPS: -1, gRPC: 8502, DNS: 8600)
Cluster Addr: 127.0.0.1 (LAN: 8301, WAN: 8302)
Encrypt: Gossip: false, TLS-Outgoing: false, TLS-Incoming: false, Auto-Encrypt-TLS: false
==> Log data will now stream in as it occurs:
......
这里我们在启动命令后面使用 -client 参数指定了客户端绑定的 IP 地址,默认为 127.0.0.1。除了我们注册的 3 个 demo 服务之外,Consul agent 还会将自己注册为一个名为 consul 的服务,我们可以在浏览器中访问 http://<nodeip>:8500 查看注册的服务。
! consul ui](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210928112849.png)
在 Consul UI 页面中可以看到有 consul 和 demo 两个 Service 服务。
配置 Consul 自动发现
上面我们通过 Consul 注册了 3 个 demo 服务,接下来我们将配置 Prometheus 通过 Consul 来自动发现 demo 服务。
在 Prometheus 的配置文件 prometheus.yml 文件中的 scrape_configs 部分添加如下所示的抓取配置:
scrape_configs:
- job_name: "consul-sd-demo"
consul_sd_configs:
- server: "localhost:8500"
relabel_configs:
- action: keep
source_labels: __meta_consul_service, __meta_consul_health]
regex: demo;passing
- action: labelmap
regex: __meta_consul_service_metadata_(.*)
replacement: consul_$1
这里我们添加了一个名为 consul-sd-demo 的抓取任务,通过 consul_sd_configs 配置用于自动发现的 Consul 服务地址,然后使用 relabel_configs 进行了重新标记配置,首先只保留服务名称为 demo,且健康状态为 passing 的,否则也会抓取 Consul Agent 本身,而它自身是不提供 metrics 接口数据的,另外还使用 labelmap 进行了标签映射,将所有 Consul 元标签映射到 Prometheus 中以 consul_ 为前缀的标签中。
配置完成后重新启动 Prometheus,然后重新查看 Prometheus 页面上的 targets 页面,验证上面的配置是否存在:
! targets](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210928115134.png)
正常情况下是可以看到会有一个 consul-sd-demo 的任务,下面有 3 个自动发现的抓取目标。
我们将鼠标悬停在 Labels 标签区域就可以看到目标任务在重新标记 Relabeling 之前的原始标签。比如我们将查看第一个 demo 实例在 Relabel 之前包含如下所示的这些原始标签:
! raw labels](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210928115523.png)
通过查看网络请求接口 http://<promtheus addr>/api/v1/targets?state=active 也可以获取对应的原始标签数据:
{
"discoveredLabels": {
"__address__": "192.168.31.46:10000",
"__meta_consul_address": "127.0.0.1",
"__meta_consul_dc": "dc1",
"__meta_consul_health": "passing",
"__meta_consul_node": "node2",
"__meta_consul_service": "demo",
"__meta_consul_service_address": "192.168.31.46",
"__meta_consul_service_id": "demo1",
"__meta_consul_service_metadata_env": "production",
"__meta_consul_service_port": "10000",
"__meta_consul_tagged_address_lan": "127.0.0.1",
"__meta_consul_tagged_address_lan_ipv4": "127.0.0.1",
"__meta_consul_tagged_address_wan": "127.0.0.1",
"__meta_consul_tagged_address_wan_ipv4": "127.0.0.1",
"__meta_consul_tags": ",,",
"__metrics_path__": "/metrics",
"__scheme__": "http",
"job": "consul-sd-demo"
},
"labels": {
"consul_env": "production",
"instance": "192.168.31.46:10000",
"job": "consul-sd-demo"
},
"scrapePool": "consul-sd-demo",
"scrapeUrl": "http://192.168.31.46:10000/metrics",
"globalUrl": "http://192.168.31.46:10000/metrics",
"lastError": "",
"lastScrape": "2021-09-28T11:56:01.919216851+08:00",
"lastScrapeDuration": 0.013357276,
"health": "up"
}
我们在 relabel_configs 中首先配置了一个 keep 操作,只保留原始标签 __meta_consul_service 值为 demo,且 __meta_consul_health 为 passing 状态的抓取任务。然后使用 labelmap 进行标签映射,这里我们将匹配 __meta_consul_service_metadata_(.*) 所有标签,这里只有 __meta_consul_service_metadata_env 这个原始标签符合正则表达式,其中的 env 就是匹配的捕获组,在 replacement 中用 $1 代替,替换成标签 consul_$1,也就是 consul_env 这个标签了,所以 Relabeling 过后就只剩下下面的几个目标标签了:
instance: "192.168.31.46:10000" job: "consul-sd-demo" consul_env: "production"
其中的 instance 标签是在重新标记之后,自动从 __address__ 转变而来的。由于没有重新修改 __metrics_path__ 和 __scheme__ 标签,所以默认的抓取目标就是通过 HTTP 端点 /metrics 进行抓取。
现在如果我们将 demo1 这个服务杀掉,则在 Consul 中注册的服务就会出现一个不健康的实例:
! unhealth](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210928123021.png)
当然此时 Prometheus 中就只剩下两个正常 demo 服务的实例了:
! targets](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210928123934.png)
当服务正常后就又可以自动发现对应的服务了。这样我们就完成了 Prometheus 基于 Consul 的一个简单的自动发现配置。
基于文件的服务发现
除了基于 Consul 的服务发现之外,Prometheus 也允许我们进行自定义的发现集成,可以通过 watch 一组本地文件来获取抓取目标以及标签信息,也就是我们常说的基于文件的服务发现方式。
! file](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210928141059.png)
基于文件的服务发现提供了一种更通用的方式来配置静态目标,并作为一个接口插入自定义服务发现机制。
它读取一组包含零个或多个 <static_config> 列表的文件,对所有定义的文件的变更通过磁盘监视被检测到并立即应用,文件可以以 YAML 或 JSON 格式提供。文件必须包含一个静态配置的列表:
JSON json { "targets": "<host>", ... ], "labels": { "<labelname>": "<labelvalue>", ... } }, ... ]
YAML yaml - targets: - '<host>' ] labels: <labelname>: <labelvalue> ... ]
文件内容也会在指定的刷新间隔时间内定期重新读取。
# Patterns for files from which target groups are extracted.
files:
- <filename_pattern> ... ]
# Refresh interval to re-read the files.
refresh_interval: <duration> | default = 5m ]
其中 <filename*pattern> 可以是一个以 .json、.yml 或 .yaml 结尾的路径,最后一个路径段可以包含一个匹配任何字符序列的 *,例如:my/path/tg_*.json。
创建文件
接下来我们来创建一个用于服务发现的目标文件,在与 prometheus.yml 文件相同目录下面创建一个名为 targets.yml 的文件,内容如下所示:
- targets:
- "192.168.31.46:10000"
- "192.168.31.46:10001"
labels:
env: production
- targets:
- "192.168.31.46:10002"
labels:
env: staging
该文件中我们列举了 3 个 demo 服务实例,给前两个实例添加上了 env=production 的标签,后面一个加上了 env=staging 的标签,当然该文件也可以使用 JSON 格式进行配置:
{
"targets": "<host>", ... ],
"labels": {
"<labelname>": "<labelvalue>", ...
}
},
...
]
如果是 YAML 文件则格式为:
- targets:
- '<host>' ]
labels:
<labelname>: <labelvalue> ... ]
配置文件服务发现
用于发现的目标文件创建完成后,要让 Prometheus 能够从上面的 targets.yml 文件中自动读取抓取目标,需要在 prometheus.yml 配置文件中的 scrape_configs 部分添加如下所示的抓取配置:
- job_name: "file-sd-demo"
file_sd_configs:
- files:
- "targets.yml"
重新 reload 或者重启下 Prometheus 让其重新读取配置文件信息,然后同样前往 Prometheus UI 的 targets 页面下面查看是否有上面定义的抓取目标。
! targets](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210928145651.png)
然后我们可以尝试改变 targets.yml 的内容,比如为第三个实例增加一个 role: sd 的标签,不用重新加载 Prometheus 配置,Prometheus 将 watch 该文件,并自动接收任何变化。
注意:当在生产环境 Prometheus 服务器中改变
file_sd目标文件时,确保改变是原子的,以避免重新加载出现错误,最好的方法是在一个单独的位置创建更新的文件,然后将其重命名为目标文件名(使用mv命令或rename()系统调用)。
! change targets](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20210928145846.png)
这样我们就完成了基于文件的通用服务发现机制,可以让我们动态地改变 Prometheus 的监控目标,而不需要重新启动或重新加载 Prometheus 服务。当然除了基于 Consul 和文件的服务发现之外,更多的时候我们会在 Kubernetes 环境下面使用 Prometheus,由于这部分内容比较独立,后续我们再进行单独讲解。
Exporter 介绍
前面我们介绍了我们可以通过一个 metrics 接口为 Prometheus 提供监控指标,最好的方式就是直接在目标应用中集成该接口,但是有的应用并没有内置支持 metrics 接口,比如 linux 系统、mysql、redis、kafka 等应用,这种情况下我们就可以单独开发一个应用来专门提供 metrics 服务,这就是我们这里说的 Exporter,广义上讲所有可以向 Prometheus 提供监控样本数据的程序都可以被称为一个 Exporter,Exporter 的一个实例就是我们要监控的 target。
! Exporter](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211014104306.png)
Prometheus 社区提供了丰富的 Exporter 实现,涵盖了从基础设施、中间件以及网络等各个方面的监控实现,当然社区也出现了很多其他的 Exporter,如果有必要,我们也可以完全根据自己的需求开发一个 Exporter,但是最好以官方的 Exporter 开发的最佳实践](Writing exporters | Prometheus)文档作为参考实现方式,我们会在后续内容中介绍如何开发一个合格的 Exporter。官方提供的主要 Exporter 如下所示:
-
数据库:Consul exporter、Memcached exporter、MySQL server exporter
-
硬件相关:Node/system metrics exporter
-
HTTP:HAProxy exporter
-
其他监控系统:AWS CloudWatch exporter、Collectd exporter、Graphite exporter、InfluxDB exporter、JMX exporter、SNMP exporter、StatsD exporter、Blackbox exporter
由于 Exporter 是用于提供监控指标的独立服务,所以我们需要单独部署该服务来提供指标服务,比如 Node Exporter 就需要在操作系统上独立运行来收集系统的相关监控数据转换为 Prometheus 能够识别的 metrics 接口,接下来我们主要和大家来介绍几个比较常见的 Exporter 的使用。
Node Exporter 是用于暴露 *NIX 主机指标的 Exporter,比如采集 CPU、内存、磁盘等信息。采用 Go 编写,不存在任何第三方依赖,所以只需要下载解压即可运行。
由于 Node Exporter 是一个独立的二进制文件,可以直接从 Prometheus 下载页面](Download | Prometheus) 下载解压运行:
☸ ➜ wget https://github.com/prometheus/node_exporter/releases/download/v1.2.2/node_exporter-1.2.2.linux-amd64.tar.gz # 国内加速可以使用下面的命令下载 # wget https://download.fastgit.org/prometheus/node_exporter/releases/download/v1.2.2/node_exporter-1.2.2.linux-amd64.tar.gz ☸ ➜ tar -xvf node_exporter-1.2.2.linux-amd64.tar.gz node_exporter-1.2.2.linux-amd64/ node_exporter-1.2.2.linux-amd64/LICENSE node_exporter-1.2.2.linux-amd64/NOTICE node_exporter-1.2.2.linux-amd64/node_exporter ☸ ➜ cd node_exporter-1.2.2.linux-amd64 && ls -la total 18084 drwxr-xr-x 2 3434 3434 56 Aug 6 21:50 . dr-xr-x---. 5 root root 4096 Oct 14 11:50 .. -rw-r--r-- 1 3434 3434 11357 Aug 6 21:49 LICENSE -rwxr-xr-x 1 3434 3434 18494215 Aug 6 21:45 node_exporter -rw-r--r-- 1 3434 3434 463 Aug 6 21:49 NOTICE
直接执行 node_exporter 文件即可运行:
☸ ➜ ./node_exporter level=info ts=2021-10-14T03:52:31.947Z caller=node_exporter.go:182 msg="Starting node_exporter" version="(version=1.2.2, branch=HEAD, revision=26645363b486e12be40af7ce4fc91e731a33104e)" level=info ts=2021-10-14T03:52:31.947Z caller=node_exporter.go:183 msg="Build context" build_context="(go=go1.16.7, user=root@b9cb4aa2eb17, date=20210806-13:44:18)" ...... level=info ts=2021-10-14T03:52:31.948Z caller=node_exporter.go:199 msg="Listening on" address=:9100 level=info ts=2021-10-14T03:52:31.948Z caller=tls_config.go:191 msg="TLS is disabled." http2=false
从日志上可以看出 node_exporter 监听在 9100 端口上,默认的 metrics 接口通过 /metrics 端点暴露,我们可以通过访问 http://localhost:9100/metrics 来获取监控指标数据:
☸ ➜ curl http://localhost:9100/metrics ...... # HELP node_load1 1m load average. # TYPE node_load1 gauge node_load1 0.01 # HELP node_load15 15m load average. # TYPE node_load15 gauge node_load15 0.05 # HELP node_load5 5m load average. # TYPE node_load5 gauge node_load5 0.04 # HELP node_memory_Active_anon_bytes Memory information field Active_anon_bytes. # TYPE node_memory_Active_anon_bytes gauge node_memory_Active_anon_bytes 8.4393984e+07 # HELP node_memory_Active_bytes Memory information field Active_bytes. # TYPE node_memory_Active_bytes gauge node_memory_Active_bytes 1.8167808e+08 # HELP node_memory_Active_file_bytes Memory information field Active_file_bytes. # TYPE node_memory_Active_file_bytes gauge node_memory_Active_file_bytes 9.7284096e+07 # HELP node_memory_AnonHugePages_bytes Memory information field AnonHugePages_bytes. # TYPE node_memory_AnonHugePages_bytes gauge node_memory_AnonHugePages_bytes 3.5651584e+07 # HELP node_memory_AnonPages_bytes Memory information field AnonPages_bytes. # TYPE node_memory_AnonPages_bytes gauge node_memory_AnonPages_bytes 8.159232e+07 # HELP node_memory_Bounce_bytes Memory information field Bounce_bytes. # TYPE node_memory_Bounce_bytes gauge node_memory_Bounce_bytes 0 ......
该 metrics 接口数据就是一个标准的 Prometheus 监控指标格式,我们只需要将该端点配置到 Prometheus 中即可抓取该指标数据。为了了解 node_exporter 可配置的参数,我们可以使用 ./node_exporter -h 来查看帮助信息:
☸ ➜ ./node_exporter -h
--web.listen-address=":9100" # 监听的端口,默认是9100
--web.telemetry-path="/metrics" # metrics的路径,默认为/metrics
--web.disable-exporter-metrics # 是否禁用go、prome默认的metrics
--web.max-requests=40 # 最大并行请求数,默认40,设置为0时不限制
--log.level="info" # 日志等级: debug, info, warn, error, fatal]
--log.format=logfmt # 置日志打印target和格式: logfmt, json]
--version # 版本号
--collector.{metric-name} # 各个metric对应的参数
......
其中最重要的参数就是 --collector.<name>,通过该参数可以启用我们收集的功能模块,node_exporter 会默认采集一些模块,要禁用这些默认启用的收集器可以通过 --no-collector.<name> 标志来禁用,如果只启用某些特定的收集器,基于先使用 --collector.disable-defaults 标志禁用所有默认的,然后在通过指定具体的收集器 --collector.<name> 来进行启用。下图列出了默认启用的收集器:
! 默认收集器](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/node-exporter-default-collectors.png)
一般来说为了方便管理我们可以使用 docker 容器来运行 node_exporter,但是需要注意的是由于采集的是宿主机的指标信息,所以需要访问主机系统,如果使用 docker 容器来部署的话需要添加一些额外的参数来允许 node_exporter 访问宿主机的命名空间,如果直接在宿主机上运行的,我们可以用 systemd 来管理,创建一个如下所示的 service unit 文件:
☸ ➜ cat /etc/systemd/system/node_exporter.service Unit] Description=node exporter service Documentation=https://prometheus.io After=network.target Service] Type=simple User=root Group=root ExecStart=/usr/local/bin/node_exporter # 有特殊需求的可以在后面指定参数配置 Restart=on-failure Install] WantedBy=multi-user.target
然后就可以使用 systemd 来管理 node_exporter 了:
☸ ➜ cp node_exporter /usr/local/bin/node_exporter
☸ ➜ systemctl daemon-reload
☸ ➜ systemctl start node_exporter
☸ ➜ systemctl status node_exporter
● node_exporter.service - node exporter servoce
Loaded: loaded (/etc/systemd/system/node_exporter.service; disabled; vendor preset: disabled)
Active: active (running) since Thu 2021-10-14 15:29:46 CST; 5s ago
Docs: https://prometheus.io
Main PID: 18679 (node_exporter)
Tasks: 5
Memory: 6.5M
CGroup: /system.slice/node_exporter.service
└─18679 /usr/local/bin/node_exporter
Oct 14 15:29:46 node1 node_exporter 18679]: level=info ts=2021-10-14T07:29:46.137Z caller=node_exporter.go:..._zone
Oct 14 15:29:46 node1 node_exporter 18679]: level=info ts=2021-10-14T07:29:46.137Z caller=node_exporter.go:...=time
Oct 14 15:29:46 node1 node_exporter 18679]: level=info ts=2021-10-14T07:29:46.137Z caller=node_exporter.go:...timex
Oct 14 15:29:46 node1 node_exporter 18679]: level=info ts=2021-10-14T07:29:46.137Z caller=node_exporter.go:...ueues
Oct 14 15:29:46 node1 node_exporter 18679]: level=info ts=2021-10-14T07:29:46.137Z caller=node_exporter.go:...uname
Oct 14 15:29:46 node1 node_exporter 18679]: level=info ts=2021-10-14T07:29:46.137Z caller=node_exporter.go:...mstat
Oct 14 15:29:46 node1 node_exporter 18679]: level=info ts=2021-10-14T07:29:46.137Z caller=node_exporter.go:...r=xfs
Oct 14 15:29:46 node1 node_exporter 18679]: level=info ts=2021-10-14T07:29:46.137Z caller=node_exporter.go:...r=zfs
Oct 14 15:29:46 node1 node_exporter 18679]: level=info ts=2021-10-14T07:29:46.137Z caller=node_exporter.go:...:9100
Oct 14 15:29:46 node1 node_exporter 18679]: level=info ts=2021-10-14T07:29:46.137Z caller=tls_config.go:191...false
Hint: Some lines were ellipsized, use -l to show in full.
这里我们用 systemd 的方式在两个节点上(node1、node2)分别启动 node_exporter,启动完成后我们使用静态配置的方式在之前的 Prometheus 配置中新增一个 node_exporter 的抓取任务,来采集这两个节点的监控指标数据,配置文件如下所示:
global:
scrape_interval: 5s
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: "localhost:9090"]
- job_name: "demo"
scrape_interval: 15s # 会覆盖global全局的配置
scrape_timeout: 10s
static_configs:
- targets: "localhost:10000", "localhost:10001", "localhost:10002"]
- job_name: "node_exporter" # 新增 node_exporter 任务
static_configs:
- targets: "node1:9100", "node2:9100"] # node1、node2 在 hosts 中做了映射
上面配置文件最后我们新增了一个名为 node_exporter 的抓取任务,采集的目标使用静态配置的方式进行配置,然后重新加载 Prometheus,正常在 Prometheus 的 WebUI 的目标页面就可以看到上面配置的 node_exporter 任务了。
常用监控指标
本节我们来了解一些关于节点监控的常用指标,比如 CPU、内存、IO 监控等。
CPU 监控
对于节点我们首先能想到的就是要先对 CPU 进行监控,因为 CPU 是处理任务的核心,根据 CPU 的状态可以分析出当前系统的健康状态。要对节点进行 CPU 监控,需要用到 node_cpu_seconds_total 这个监控指标,在 metrics 接口中该指标内容如下所示:
# HELP node_cpu_seconds_total Seconds the CPUs spent in each mode.
# TYPE node_cpu_seconds_total counter
node_cpu_seconds_total{cpu="0",mode="idle"} 13172.76
node_cpu_seconds_total{cpu="0",mode="iowait"} 0.25
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 0.01
node_cpu_seconds_total{cpu="0",mode="softirq"} 87.99
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 309.38
node_cpu_seconds_total{cpu="0",mode="user"} 79.93
node_cpu_seconds_total{cpu="1",mode="idle"} 13168.98
node_cpu_seconds_total{cpu="1",mode="iowait"} 0.27
node_cpu_seconds_total{cpu="1",mode="irq"} 0
node_cpu_seconds_total{cpu="1",mode="nice"} 0
node_cpu_seconds_total{cpu="1",mode="softirq"} 74.1
node_cpu_seconds_total{cpu="1",mode="steal"} 0
node_cpu_seconds_total{cpu="1",mode="system"} 314.71
node_cpu_seconds_total{cpu="1",mode="user"} 78.83
node_cpu_seconds_total{cpu="2",mode="idle"} 13182.78
node_cpu_seconds_total{cpu="2",mode="iowait"} 0.69
node_cpu_seconds_total{cpu="2",mode="irq"} 0
node_cpu_seconds_total{cpu="2",mode="nice"} 0
node_cpu_seconds_total{cpu="2",mode="softirq"} 66.01
node_cpu_seconds_total{cpu="2",mode="steal"} 0
node_cpu_seconds_total{cpu="2",mode="system"} 309.09
node_cpu_seconds_total{cpu="2",mode="user"} 79.44
node_cpu_seconds_total{cpu="3",mode="idle"} 13185.13
node_cpu_seconds_total{cpu="3",mode="iowait"} 0.18
node_cpu_seconds_total{cpu="3",mode="irq"} 0
node_cpu_seconds_total{cpu="3",mode="nice"} 0
node_cpu_seconds_total{cpu="3",mode="softirq"} 64.49
node_cpu_seconds_total{cpu="3",mode="steal"} 0
node_cpu_seconds_total{cpu="3",mode="system"} 305.86
node_cpu_seconds_total{cpu="3",mode="user"} 78.17
从接口中描述可以看出该指标是用来统计 CPU 每种模式下所花费的时间,是一个 Counter 类型的指标,也就是会一直增长,这个数值其实是 CPU 时间片的一个累积值,意思就是从操作系统启动起来 CPU 开始工作,就开始记录自己总共使用的时间,然后保存下来,而且这里的累积的 CPU 使用时间还会分成几个不同的模式,比如用户态使用时间、空闲时间、中断时间、内核态使用时间等等,也就是平时我们使用 top 命令查看的 CPU 的相关信息,而我们这里的这个指标会分别对这些模式进行记录。
接下来我们来对节点的 CPU 进行监控,我们也知道一个一直增长的 CPU 时间对我们意义不大,一般我们更希望监控的是节点的 CPU 使用率,也就是我们使用 top 命令看到的百分比。
top命令
要计算 CPU 的使用率,那么就需要搞清楚这个使用率的含义,CPU 使用率是 CPU 除空闲(idle)状态之外的其他所有 CPU 状态的时间总和除以总的 CPU 时间得到的结果,理解了这个概念后就可以写出正确的 promql 查询语句了。
要计算除空闲状态之外的 CPU 时间总和,更好的方式是不是直接计算空闲状态的 CPU 时间使用率,然后用 1 减掉就是我们想要的结果了,所以首先我们先过滤 idle 模式的指标,在 Prometheus 的 WebUI 中输入 node_cpu_seconds_total{mode="idle"} 进行过滤:
idle cpu
要计算使用率,肯定就需要知道 idle 模式的 CPU 用了多长时间,然后和总的进行对比,由于这是 Counter 指标,我们可以用 increase 函数来获取变化,使用查询语句 increase(node_cpu_seconds_total{mode="idle"} 1m]),因为 increase 函数要求输入一个区间向量,所以这里我们取 1 分钟内的数据:
idle cpu increase
我们可以看到查询结果中有很多不同 cpu 序号的数据,我们当然需要计算所有 CPU 的时间,所以我们将它们聚合起来,我们要查询的是不同节点的 CPU 使用率,所以就需要根据 instance 标签进行聚合,使用查询语句 sum(increase(node_cpu_seconds_total{mode="idle"} 1m])) by (instance):
idle cpu sum
这样我们就分别拿到不同节点 1 分钟内的空闲 CPU 使用时间了,然后和总的 CPU (这个时候不需要过滤状态模式)时间进行比较即可,使用查询语句 sum(increase(node_cpu_seconds_total{mode="idle"} 1m])) by (instance) / sum(increase(node_cpu_seconds_total 1m])) by (instance)
cpu使用率
然后计算 CPU 使用率就非常简单了,使用 1 减去乘以 100 即可:(1 - sum(increase(node_cpu_seconds_total{mode="idle"} 1m])) by (instance) / sum(increase(node_cpu_seconds_total 1m])) by (instance) ) * 100。这就是能够想到的最直接的 CPU 使用率查询方式了,当然前面我们学习的 promql 语法中提到过更多的时候我们会去使用 rate 函数,而不是用 increase 函数进行计算,所以最终的 CPU 使用率的查询语句为:(1 - sum(rate(node_cpu_seconds_total{mode="idle"} 1m])) by (instance) / sum(rate(node_cpu_seconds_total 1m])) by (instance) ) * 100。
内存监控
除了 CPU 监控之外,我们可能最关心的就是节点内存的监控了,平时我们查看节点的内存使用情况基本上都是使用 free 命令来查看:
! free命令](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211025101437.png)
free 命令的输出会显示系统内存的使用情况,包括物理内存、交换内存(swap)和内核缓冲区内存等,所以要对内存进行监控我们需要先了解这些概念,我们先了解下 free 命令的输出内容:
-
Mem 行(第二行)是内存的使用情况 -
Swap 行(第三行)是交换空间的使用情况 -
total列显示系统总的可用物理内存和交换空间大小 -
used列显示已经被使用的物理内存和交换空间 -
free列显示还有多少物理内存和交换空间可用使用 -
shared列显示被共享使用的物理内存大小 -
buff/cache列显示被 buffer 和 cache 使用的物理内存大小 -
available列显示还可以被应用程序使用的物理内存大小
其中我们需要重点关注的 free 和 available 两列。free 是真正尚未被使用的物理内存数量,而 available 是从应用程序的角度看到的可用内存,Linux 内核为了提升磁盘操作的性能,会消耗一部分内存去缓存磁盘数据,就是 buffer 和 cache,所以对于内核来说,buffer 和 cache 都属于已经被使用的内存,只是应用程序需要内存时,如果没有足够的 free 内存可以用,内核就会从 buffer 和 cache 中回收内存来满足应用程序的请求。所以从应用程序的角度来说 available = free + buffer + cache,不过需要注意这只是一个理想的计算方式,实际中的数据有较大的误差。
如果要在 Prometheus 中来查询内存使用,则可以用 node_memory_* 相关指标,同样的要计算使用的,我们可以计算可使用的内存,使用 promql 查询语句 node_memory_Buffers_bytes + node_memory_Cached_bytes + node_memory_MemFree_bytes。
然后计算可用内存的使用率,和总的内存相除,然后同样用 1 减去即可,语句为 (1- (node_memory_Buffers_bytes + node_memory_Cached_bytes + node_memory_MemFree_bytes) / node_memory_MemTotal_bytes) * 100,这样计算出来的就是节点内存使用率。
当然如果想要查看各项内存使用直接使用对应的监控指标即可,比如要查看节点总内存,直接使用 node_memory_MemTotal_bytes 指标即可获取。
磁盘监控
接下来是比较中的磁盘监控,对于磁盘监控我们不仅对磁盘使用情况感兴趣,一般来说对于磁盘 IO 的监控也是非常有必要的。
磁盘容量监控
要监控磁盘容量,需要用到 node_filesystem_* 相关的指标,比如要查询节点磁盘空间使用率,则可以同样用总的减去可用的来进行计算,磁盘可用空间使用 node_filesystem_avail_bytes 指标,但是由于会有一些我们不关心的磁盘信息,所以我们可以使用 fstype 标签过滤关心的磁盘信息,比如 ext4 或者 xfs 格式的磁盘:
! 可用磁盘空间](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211025144133.png)
要查询磁盘空间使用率,则使用查询语句 (1 - node_filesystem_avail_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"}) * 100 即可:
! 磁盘空间使用率](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211025144314.png)
这样就可以得到我们关心的磁盘空间使用率了。
磁盘 IO 监控
要监控磁盘 IO,就要区分是读的 IO,还是写的 IO,读 IO 使用 node_disk_reads_completed 指标,写 IO 使用 node_disk_writes_completed_total 指标。
磁盘读 IO 使用 sum by (instance) (rate(node_disk_reads_completed_total 5m])) 查询语句即可:
当然如果你想根据 device 进行聚合也是可以的,我们这里是全部聚合在一起了。
磁盘写 IO 使用 sum by (instance) (rate(node_disk_writes_completed_total 5m])) 查询语句即可:
如果要计算总的读写 IO,则加起来即可 `rate(node_disk_reads_completed_total 5m]) + rate(node_disk_writes_completed_total 5m])
目录 CPU 监控 ](常用监控指标 - Prometheus 入门到实战监控) 内存监控 ](常用监控指标 - Prometheus 入门到实战内存监控) 磁盘监控 ](常用监控指标 - Prometheus 入门到实战磁盘监控) 网络 IO 监控 ](常用监控指标 - Prometheus 入门到实战网络-IO-监控)
](https://github.com/cnych/qikqiak.com/edit/master/docs/node-exporter/metrics.md)
常用监控指标
本节我们来了解一些关于节点监控的常用指标,比如 CPU、内存、IO 监控等。
CPU 监控
对于节点我们首先能想到的就是要先对 CPU 进行监控,因为 CPU 是处理任务的核心,根据 CPU 的状态可以分析出当前系统的健康状态。要对节点进行 CPU 监控,需要用到 node_cpu_seconds_total 这个监控指标,在 metrics 接口中该指标内容如下所示:
# HELP node_cpu_seconds_total Seconds the CPUs spent in each mode.
# TYPE node_cpu_seconds_total counter
node_cpu_seconds_total{cpu="0",mode="idle"} 13172.76
node_cpu_seconds_total{cpu="0",mode="iowait"} 0.25
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 0.01
node_cpu_seconds_total{cpu="0",mode="softirq"} 87.99
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 309.38
node_cpu_seconds_total{cpu="0",mode="user"} 79.93
node_cpu_seconds_total{cpu="1",mode="idle"} 13168.98
node_cpu_seconds_total{cpu="1",mode="iowait"} 0.27
node_cpu_seconds_total{cpu="1",mode="irq"} 0
node_cpu_seconds_total{cpu="1",mode="nice"} 0
node_cpu_seconds_total{cpu="1",mode="softirq"} 74.1
node_cpu_seconds_total{cpu="1",mode="steal"} 0
node_cpu_seconds_total{cpu="1",mode="system"} 314.71
node_cpu_seconds_total{cpu="1",mode="user"} 78.83
node_cpu_seconds_total{cpu="2",mode="idle"} 13182.78
node_cpu_seconds_total{cpu="2",mode="iowait"} 0.69
node_cpu_seconds_total{cpu="2",mode="irq"} 0
node_cpu_seconds_total{cpu="2",mode="nice"} 0
node_cpu_seconds_total{cpu="2",mode="softirq"} 66.01
node_cpu_seconds_total{cpu="2",mode="steal"} 0
node_cpu_seconds_total{cpu="2",mode="system"} 309.09
node_cpu_seconds_total{cpu="2",mode="user"} 79.44
node_cpu_seconds_total{cpu="3",mode="idle"} 13185.13
node_cpu_seconds_total{cpu="3",mode="iowait"} 0.18
node_cpu_seconds_total{cpu="3",mode="irq"} 0
node_cpu_seconds_total{cpu="3",mode="nice"} 0
node_cpu_seconds_total{cpu="3",mode="softirq"} 64.49
node_cpu_seconds_total{cpu="3",mode="steal"} 0
node_cpu_seconds_total{cpu="3",mode="system"} 305.86
node_cpu_seconds_total{cpu="3",mode="user"} 78.17
从接口中描述可以看出该指标是用来统计 CPU 每种模式下所花费的时间,是一个 Counter 类型的指标,也就是会一直增长,这个数值其实是 CPU 时间片的一个累积值,意思就是从操作系统启动起来 CPU 开始工作,就开始记录自己总共使用的时间,然后保存下来,而且这里的累积的 CPU 使用时间还会分成几个不同的模式,比如用户态使用时间、空闲时间、中断时间、内核态使用时间等等,也就是平时我们使用 top 命令查看的 CPU 的相关信息,而我们这里的这个指标会分别对这些模式进行记录。
接下来我们来对节点的 CPU 进行监控,我们也知道一个一直增长的 CPU 时间对我们意义不大,一般我们更希望监控的是节点的 CPU 使用率,也就是我们使用 top 命令看到的百分比。
! top命令](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211024161926.png)
要计算 CPU 的使用率,那么就需要搞清楚这个使用率的含义,CPU 使用率是 CPU 除空闲(idle)状态之外的其他所有 CPU 状态的时间总和除以总的 CPU 时间得到的结果,理解了这个概念后就可以写出正确的 promql 查询语句了。
要计算除空闲状态之外的 CPU 时间总和,更好的方式是不是直接计算空闲状态的 CPU 时间使用率,然后用 1 减掉就是我们想要的结果了,所以首先我们先过滤 idle 模式的指标,在 Prometheus 的 WebUI 中输入 node_cpu_seconds_total{mode="idle"} 进行过滤:
! idle cpu](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211024162537.png)
要计算使用率,肯定就需要知道 idle 模式的 CPU 用了多长时间,然后和总的进行对比,由于这是 Counter 指标,我们可以用 increase 函数来获取变化,使用查询语句 increase(node_cpu_seconds_total{mode="idle"} 1m]),因为 increase 函数要求输入一个区间向量,所以这里我们取 1 分钟内的数据:
! idle cpu increase](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211024163218.png)
我们可以看到查询结果中有很多不同 cpu 序号的数据,我们当然需要计算所有 CPU 的时间,所以我们将它们聚合起来,我们要查询的是不同节点的 CPU 使用率,所以就需要根据 instance 标签进行聚合,使用查询语句 sum(increase(node_cpu_seconds_total{mode="idle"} 1m])) by (instance):
! idle cpu sum](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211024163614.png)
这样我们就分别拿到不同节点 1 分钟内的空闲 CPU 使用时间了,然后和总的 CPU (这个时候不需要过滤状态模式)时间进行比较即可,使用查询语句 sum(increase(node_cpu_seconds_total{mode="idle"} 1m])) by (instance) / sum(increase(node_cpu_seconds_total 1m])) by (instance):
! cpu使用](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211024163902.png)
然后计算 CPU 使用率就非常简单了,使用 1 减去乘以 100 即可:(1 - sum(increase(node_cpu_seconds_total{mode="idle"} 1m])) by (instance) / sum(increase(node_cpu_seconds_total 1m])) by (instance) ) * 100。这就是能够想到的最直接的 CPU 使用率查询方式了,当然前面我们学习的 promql 语法中提到过更多的时候我们会去使用 rate 函数,而不是用 increase 函数进行计算,所以最终的 CPU 使用率的查询语句为:(1 - sum(rate(node_cpu_seconds_total{mode="idle"} 1m])) by (instance) / sum(rate(node_cpu_seconds_total 1m])) by (instance) ) * 100。
! CPU使用率](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211024164515.png)
可以和 top 命令的结果进行对比(下图为 node2 节点),基本上是保持一致的,这就是监控节点 CPU 使用率的方式。
! 对比top命令](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211024165821.png)
内存监控
除了 CPU 监控之外,我们可能最关心的就是节点内存的监控了,平时我们查看节点的内存使用情况基本上都是使用 free 命令来查看:
! free命令](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211025101437.png)
free 命令的输出会显示系统内存的使用情况,包括物理内存、交换内存(swap)和内核缓冲区内存等,所以要对内存进行监控我们需要先了解这些概念,我们先了解下 free 命令的输出内容:
-
Mem 行(第二行)是内存的使用情况 -
Swap 行(第三行)是交换空间的使用情况 -
total列显示系统总的可用物理内存和交换空间大小 -
used列显示已经被使用的物理内存和交换空间 -
free列显示还有多少物理内存和交换空间可用使用 -
shared列显示被共享使用的物理内存大小 -
buff/cache列显示被 buffer 和 cache 使用的物理内存大小 -
available列显示还可以被应用程序使用的物理内存大小
其中我们需要重点关注的 free 和 available 两列。free 是真正尚未被使用的物理内存数量,而 available 是从应用程序的角度看到的可用内存,Linux 内核为了提升磁盘操作的性能,会消耗一部分内存去缓存磁盘数据,就是 buffer 和 cache,所以对于内核来说,buffer 和 cache 都属于已经被使用的内存,只是应用程序需要内存时,如果没有足够的 free 内存可以用,内核就会从 buffer 和 cache 中回收内存来满足应用程序的请求。所以从应用程序的角度来说 available = free + buffer + cache,不过需要注意这只是一个理想的计算方式,实际中的数据有较大的误差。
如果要在 Prometheus 中来查询内存使用,则可以用 node_memory_* 相关指标,同样的要计算使用的,我们可以计算可使用的内存,使用 promql 查询语句 node_memory_Buffers_bytes + node_memory_Cached_bytes + node_memory_MemFree_bytes。
! available Mem](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211025105006.png)
然后计算可用内存的使用率,和总的内存相除,然后同样用 1 减去即可,语句为 (1- (node_memory_Buffers_bytes + node_memory_Cached_bytes + node_memory_MemFree_bytes) / node_memory_MemTotal_bytes) * 100,这样计算出来的就是节点内存使用率。
! 内存使用率](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211025105743.png)
当然如果想要查看各项内存使用直接使用对应的监控指标即可,比如要查看节点总内存,直接使用 node_memory_MemTotal_bytes 指标即可获取。
! 总内存](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211025110122.png)
磁盘监控
接下来是比较中的磁盘监控,对于磁盘监控我们不仅对磁盘使用情况感兴趣,一般来说对于磁盘 IO 的监控也是非常有必要的。
磁盘容量监控
要监控磁盘容量,需要用到 node_filesystem_* 相关的指标,比如要查询节点磁盘空间使用率,则可以同样用总的减去可用的来进行计算,磁盘可用空间使用 node_filesystem_avail_bytes 指标,但是由于会有一些我们不关心的磁盘信息,所以我们可以使用 fstype 标签过滤关心的磁盘信息,比如 ext4 或者 xfs 格式的磁盘:
! 可用磁盘空间](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211025144133.png)
要查询磁盘空间使用率,则使用查询语句 (1 - node_filesystem_avail_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"}) * 100 即可:
! 磁盘空间使用率](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211025144314.png)
这样就可以得到我们关心的磁盘空间使用率了。
磁盘 IO 监控
要监控磁盘 IO,就要区分是读的 IO,还是写的 IO,读 IO 使用 node_disk_reads_completed 指标,写 IO 使用 node_disk_writes_completed_total 指标。
磁盘读 IO 使用 sum by (instance) (rate(node_disk_reads_completed_total 5m])) 查询语句即可:
! 磁盘读IO](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211025145244.png)
当然如果你想根据 device 进行聚合也是可以的,我们这里是全部聚合在一起了。
磁盘写 IO 使用 sum by (instance) (rate(node_disk_writes_completed_total 5m])) 查询语句即可:
! 磁盘写IO](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211025145440.png)
如果要计算总的读写 IO,则加起来即可 `rate(node_disk_reads_completed_total 5m]) + rate(node_disk_writes_completed_total 5m])
网络 IO 监控
上行带宽需要用到的指标是 node_network_receive_bytes,由于我们对网络贷款的瞬时变化比较关注,所以一般我们会使用 irate 函数来计算网络 IO,比如计算上行带宽用查询语句 sum by(instance) (irate(node_network_receive_bytes_total{device!~"bond.*?|lo"} 5m])) 即可:
上行带宽
下行带宽用到的指标为 node_network_transmit_bytes,同样的方式查询语句为 sum by(instance) (irate(node_network_transmit_bytes{device!~"bond.*?|lo"} 5m])):
下行带宽
当然我们还可以根据网卡设备进行分别聚合计算,最后还可以根据自己的需求将结果进行单位换算。
textfile 自定义指标收集器
node_exporter 除了本身可以收集系统指标之外,还可以通过 textfile 模块来采集我们自定义的监控指标,这对于系统监控提供了更灵活的使用空间,比如我们通过脚本采集的监控数据就可以通过该模块暴露出去,用于 Prometheus 进行监控报警。默认情况下 node_exporter 会启用 textfile 组建,但是需要使用 --collector.textfile.directory 参数设置一个用于采集的路径,所有生成的监控指标将放在该目录下,并以 .prom 文件名后缀结尾。
所有自定义生成的监控指标需要按照如下所示的方式进行存储,比如我们使用 shell 或者 python 脚本写入的文件:
# HELP example_metric Metric read from /some/path/textfile/example.prom # TYPE example_metric untyped example_metric 1
这其实就是一个标准的 metrics 接口内容格式,这里如果没有加上 HELP 信息的话,系统会帮助生成一个简单的描述信息,但是如果有多个文件中出现了相同的指标名称,那么需要保证这些指标的 HELP 和 TYPE 要一致,否则采集会出错。
一般来说输出指标到 .prom 文件的脚本任务会放入到 crontab 中去执行,按照需求设置采集指标的时间,但是如果 node_exporter 采集的时候正好文件在执行写入操作,可能会导致文件出现问题,我们可以将任务先转移到一个临时文件,然后通过临时文件的重命名进行操作,降低风险,如下所示:
*/5 * * * * $TEXTFILE/printMetrics.sh > /path/to/directory/metrics.prom.$$ && mv /path/to/directory/metrics.prom.$$ /path/to/directory/metrics.prom
对于 .prom 文件的采集,系统会自动的加入采集文件的修改时间,通过该指标我们可以设置告警用于判断是否文件发生了变化,比如采集指标时间为每 10 分钟一次,那么修改时间应该 <15 分钟,否则就应该报警上次的采集未成功,指标名称为 node_textfile_mtime_seconds,指标收集时间为 unixtime 格式时间。
同时除了加载一些探测信息,使用该方式还可以用于静态信息的收集,比如定义的系统角色信息,或者服务器特殊的配置信息等等,这些也都可以通过 metrics 的方式进行传递。
echo 'role{role="application_server"} 1' > /path/to/directory/role.prom.$$
mv /path/to/directory/role.prom.$$ /path/to/directory/role.prom
这里我们以官方提供的一个脚本用于采集文件夹目录大小的 shell 脚本为例进行说明,脚本地址为:https://github.com/prometheus-community/node-exporter-textfile-collector-scripts/blob/master/directory-size.sh,内容如下所示:
#!/bin/sh
#
# Expose directory usage metrics, passed as an argument.
#
# Usage: add this to crontab:
#
# */5 * * * * prometheus directory-size.sh /var/lib/prometheus | sponge /var/lib/node_exporter/directory_size.prom
#
# sed pattern taken from https://www.robustperception.io/monitoring-directory-sizes-with-the-textfile-collector/
#
# Author: Antoine Beaupré <anarcat@debian.org>
echo "# HELP node_directory_size_bytes Disk space used by some directories"
echo "# TYPE node_directory_size_bytes gauge"
du --block-size=1 --summarize "$@" \
| sed -ne 's/\\/\\\\/;s/"/\\"/g;s/^\( 0-9]\+\)\t\(.*\)$/node_directory_size_bytes{directory="\2"} \1/p'
首先需要在 node_exporter 启动程序中指定 textfile 采集器目录,我们这里指定的目录为 /root/p8strain/textfile:
! textfile](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211027171017.png)
然后重新启动 node_exporter:
☸ ➜ systemctl daemon-reload ☸ ➜ systemctl restart node_exporter
这样 node_exporter 就会开始去收集我们指定有的 textfile 目录里面的自定义指标数据了。为了使用上面的测试脚本,我们可以将生成的文件放入临时文件,然后重新命令,另外一种方式就是可以使用 sponge 命令来保证以原子方式写入内容 <collector_script> | sponge <output_file>,我们这里是 CentOS 系统,需要额外安装该工具:
☸ ➜ yum -y install epel-release ☸ ➜ yum -y install moreutils
将上面的示例脚本保存为 directory-size.sh,放入 /root/p8strain 目录下面,然后在 crontab 中加入如下命令来统计该目录的大小:
☸ ➜ crontab -e # 加入如下所示定时任务 ☸ ➜ crontab -l */5 * * * * /root/p8strain/directory-size.sh /root/p8strain | sponge /root/p8strain/textfile/directory_size.prom
正常就会在 /root/p8strain/textfile 目录下面生成上面指定的 directory_size.prom 指标文件,内容如下所示:
# HELP node_directory_size_bytes Disk space used by some directories
# TYPE node_directory_size_bytes gauge
node_directory_size_bytes{directory="/root/p8strain"} 459378688
在 Kubernetes 上部署 Prometheus
前面我们已经了解了 Prometheus 的基本使用方式,主要是使用的二进制方式进行部署的,在实际生产环境来说,Prometheus 更适合用来部署在 Kubernetes 集群中,本节我们将介绍如何用手动方式在 Kubernetes 集群上部署 Prometheus,关于 Kubernetes 本身的使用可以参考我们的另外课程 《Kubernetes 进阶训练营》](https://youdianzhishi.com/web/course/1030)。
安装
由于我们这里是要运行在 Kubernetes 系统中,所以我们直接用 Docker 镜像的方式运行。这里我们使用的实验环境是基于 Kubernetes v1.22 版本,一共 3 个节点:
☸ ➜ kubectl get nodes NAME STATUS ROLES AGE VERSION master1 Ready control-plane,master 49d v1.22.2 node1 Ready <none> 49d v1.22.2 node2 Ready <none> 49d v1.22.2
为了方便管理,我们将监控相关的所有资源对象都安装在 kube-mon 这个 namespace 下面,没有的话可以提前创建:
☸ ➜ kubectl create ns kube-mon
为了能够方便的管理配置文件,我们这里将 prometheus.yml 配置文件用 ConfigMap 的形式进行管理:
# config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-mon
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: 'localhost:9090']
我们这里暂时只配置了对 prometheus 本身的监控,直接创建该资源对象:
☸ ➜ kubectl apply -f https://p8s.io/docs/k8s/manifests/prometheus/config-1.yaml configmap "prometheus-config" created
配置文件创建完成了,以后如果我们有新的资源需要被监控,我们只需要将上面的 ConfigMap 对象更新即可。现在我们来创建 prometheus 的 Pod 资源:
# prometheus-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: kube-mon
labels:
app: prometheus
spec:
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: prometheus
containers:
- image: prom/prometheus:v2.31.1
name: prometheus
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus" # 指定tsdb数据路径
- "--storage.tsdb.retention.time=24h"
- "--web.enable-admin-api" # 控制对admin HTTP API的访问,其中包括删除时间序列等功能
- "--web.enable-lifecycle" # 支持热更新,直接执行localhost:9090/-/reload立即生效
ports:
- containerPort: 9090
name: http
volumeMounts:
- mountPath: "/etc/prometheus"
name: config-volume
- mountPath: "/prometheus"
name: data
resources:
requests:
cpu: 200m
memory: 1024Mi
limits:
cpu: 200m
memory: 1024Mi
volumes:
- name: data
persistentVolumeClaim:
claimName: prometheus-data
- configMap:
name: prometheus-config
name: config-volume
持久化
另外为了 prometheus 的性能和数据持久化我们这里是直接将通过一个 LocalPV 来进行数据持久化的,注意一定不能使用 nfs 来持久化数据,通过 --storage.tsdb.path=/prometheus 指定数据目录,创建如下所示的一个 PVC 资源对象,注意是一个 LocalPV,和 node2 节点具有亲和性:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: prometheus-local
labels:
app: prometheus
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 20Gi
storageClassName: local-storage
local:
path: /data/k8s/prometheus
persistentVolumeReclaimPolicy: Retain
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node2
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus-data
namespace: kube-mon
spec:
selector:
matchLabels:
app: prometheus
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
storageClassName: local-storage
由于 prometheus 可以访问 Kubernetes 的一些资源对象,所以需要配置 rbac 相关认证,这里我们使用了一个名为 prometheus 的 serviceAccount 对象:
# rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: kube-mon
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: kube-mon
由于我们要获取的资源信息,在每一个 namespace 下面都有可能存在,所以我们这里使用的是 ClusterRole 的资源对象,值得一提的是我们这里的权限规则声明中有一个 nonResourceURLs 的属性,是用来对非资源型 metrics 进行操作的权限声明,这个在以前我们很少遇到过,然后直接创建上面的资源对象即可:
☸ ➜ kubectl apply -f https://p8s.io/docs/k8s/manifests/prometheus/rbac.yaml serviceaccount "prometheus" created clusterrole.rbac.authorization.k8s.io "prometheus" created clusterrolebinding.rbac.authorization.k8s.io "prometheus" created
现在我们就可以添加 promethues 的资源对象了:
☸ ➜ kubectl apply -f https://p8s.io/docs/k8s/manifests/prometheus/deploy.yaml
deployment.apps/prometheus created
☸ ➜ kubectl get pods -n kube-mon
NAME READY STATUS RESTARTS AGE
prometheus-df4f47d95-vksmc 0/1 CrashLoopBackOff 3 98s
☸ ➜ kubectl logs -f prometheus-df4f47d95-vksmc -n kube-mon
level=info ts=2019-12-12T03:08:49.424Z caller=main.go:332 msg="Starting Prometheus" version="(version=2.14.0, branch=HEAD, revision=edeb7a44cbf745f1d8be4ea6f215e79e651bfe19)"
level=info ts=2019-12-12T03:08:49.424Z caller=main.go:333 build_context="(go=go1.13.4, user=root@df2327081015, date=20191111-14:27:12)"
level=info ts=2019-12-12T03:08:49.425Z caller=main.go:334 host_details="(Linux 3.10.0-1062.4.1.el7.x86_64 #1 SMP Fri Oct 18 17:15:30 UTC 2019 x86_64 prometheus-df4f47d95-vksmc (none))"
level=info ts=2019-12-12T03:08:49.425Z caller=main.go:335 fd_limits="(soft=1048576, hard=1048576)"
level=info ts=2019-12-12T03:08:49.425Z caller=main.go:336 vm_limits="(soft=unlimited, hard=unlimited)"
level=error ts=2019-12-12T03:08:49.425Z caller=query_logger.go:85 component=activeQueryTracker msg="Error opening query log file" file=/prometheus/queries.active err="open /prometheus/queries.active: permission denied"
panic: Unable to create mmap-ed active query log
goroutine 1 running]:
github.com/prometheus/prometheus/promql.NewActiveQueryTracker(0x7ffd8cf6ec5d, 0xb, 0x14, 0x2b4f400, 0xc0006f33b0, 0x2b4f400)
/app/promql/query_logger.go:115 +0x48c
main.main()
/app/cmd/prometheus/main.go:364 +0x5229
权限
创建 Pod 后,我们可以看到并没有成功运行,出现了 open /prometheus/queries.active: permission denied 这样的错误信息,这是因为我们的 prometheus 的镜像中是使用的 nobody 这个用户,然后现在我们通过 LocalPV 挂载到宿主机上面的目录的 ownership 却是 root:
☸ ➜ ls -la /data/k8s total 36 drwxr-xr-x 6 root root 4096 Dec 12 11:07 . dr-xr-xr-x. 19 root root 4096 Nov 9 23:19 .. drwxr-xr-x 2 root root 4096 Dec 12 11:07 prometheus
所以当然会出现操作权限问题了,这个时候我们就可以通过 securityContext 来为 Pod 设置下 volumes 的权限,通过设置 runAsUser=0 指定运行的用户为 root,也可以通过设置一个 initContainer 来修改数据目录权限:
......
initContainers:
- name: fix-permissions
image: busybox
command: chown, -R, "nobody:nobody", /prometheus]
volumeMounts:
- name: data
mountPath: /prometheus
这个时候我们重新更新下 prometheus:
☸ ➜ kubectl apply -f https://p8s.io/docs/k8s/manifests/prometheus/deploy-fixed.yaml deployment.apps/prometheus configured ☸ ➜ kubectl get pods -n kube-mon NAME READY STATUS RESTARTS AGE prometheus-649968556c-t4prd 1/1 Running 1 (14m ago) 27h ☸ ➜ kubectl logs -f prometheus-649968556c-t4prd -n kube-mon ts=2021-12-15T06:55:25.752Z caller=main.go:444 level=info msg="Starting Prometheus" version="(version=2.31.1, branch=HEAD, revision=411021ada9ab41095923b8d2df9365b632fd40c3)" ts=2021-12-15T06:55:25.752Z caller=main.go:449 level=info build_context="(go=go1.17.3, user=root@9419c9c2d4e0, date=20211105-20:35:02)" ts=2021-12-15T06:55:25.752Z caller=main.go:450 level=info host_details="(Linux 3.10.0-1160.25.1.el7.x86_64 #1 SMP Wed Apr 28 21:49:45 UTC 2021 x86_64 prometheus-649968556c-t4prd (none))" ts=2021-12-15T06:55:25.752Z caller=main.go:451 level=info fd_limits="(soft=1048576, hard=1048576)" ts=2021-12-15T06:55:25.752Z caller=main.go:452 level=info vm_limits="(soft=unlimited, hard=unlimited)" ts=2021-12-15T06:55:25.756Z caller=web.go:542 level=info component=web msg="Start listening for connections" address=0.0.0.0:9090 ts=2021-12-15T06:55:26.150Z caller=main.go:839 level=info msg="Starting TSDB ..." ...... ts=2021-12-15T06:55:27.048Z caller=main.go:869 level=info msg="TSDB started" ts=2021-12-15T06:55:27.048Z caller=main.go:996 level=info msg="Loading configuration file" filename=/etc/prometheus/prometheus.yml ts=2021-12-15T06:55:27.050Z caller=main.go:1033 level=info msg="Completed loading of configuration file" filename=/etc/prometheus/prometheus.yml totalDuration=1.555486ms db_storage=754ns remote_storage=38.847µs web_handler=433ns query_engine=852ns scrape=1.030952ms scrape_sd=73.933µs notify=894ns notify_sd=2.504µs rules=19.359µs ts=2021-12-15T06:55:27.050Z caller=main.go:811 level=info msg="Server is ready to receive web requests."
Pod 创建成功后,为了能够在外部访问到 prometheus 的 webui 服务,我们还需要创建一个 Service 对象:
# prometheus-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: kube-mon
labels:
app: prometheus
spec:
selector:
app: prometheus
type: NodePort
ports:
- name: web
port: 9090
targetPort: http
为了方便测试,我们这里创建一个 NodePort 类型的服务,当然我们可以创建一个 Ingress对象,通过域名来进行访问:
☸ ➜ kubectl apply -f https://p8s.io/docs/k8s/manifests/prometheus/svc.yaml service "prometheus" created ☸ ➜ kubectl get svc -n kube-mon NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE prometheus NodePort 10.111.160.152 <none> 9090:30407/TCP 4m33s
应用监控
前面我们和大家介绍了 Prometheus 的数据指标是通过一个公开的 HTTP(S) 数据接口获取到的,我们不需要单独安装监控的 agent,只需要暴露一个 metrics 接口,Prometheus 就会定期去拉取数据;对于一些普通的 HTTP 服务,我们完全可以直接重用这个服务,添加一个 /metrics 接口暴露给 Prometheus;而且获取到的指标数据格式是非常易懂的,不需要太高的学习成本。
现在很多服务从一开始就内置了一个 /metrics 接口,比如 Kubernetes 的各个组件都直接提供了数据指标接口,有一些服务即使没有原生集成该接口,也完全可以使用一些 exporter 来获取到指标数据,比如 mysqld_exporter、node_exporter,这些 exporter 就有点类似于传统监控服务中的 agent,作为服务一直存在,用来收集目标服务的指标数据然后直接暴露给 Prometheus。
普通应用
对于普通应用只需要能够提供一个满足 Prometheus 格式要求的 /metrics 接口就可以让 Prometheus 来接管监控,比如 Kubernetes 集群中非常重要的 CoreDNS 插件,一般默认情况下就开启了 /metrics 接口:
☸ ➜ kubectl get cm coredns -n kube-system -o yaml
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153 # 开启 metrics
forward . /etc/resolv.conf {
max_concurrent 1000
}
cache 30
loop
reload
loadbalance
}
kind: ConfigMap
metadata:
creationTimestamp: "2021-10-25T12:33:14Z"
managedFields:
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:data:
.: {}
f:Corefile: {}
manager: kubeadm
operation: Update
time: "2021-10-25T12:33:14Z"
name: coredns
namespace: kube-system
resourceVersion: "266"
uid: a93814d5-53a8-4bf6-9804-db6ec4c726cd
上面 ConfigMap 中 prometheus :9153 就是开启 prometheus 的插件:
☸ ➜ kubectl get pods -n kube-system -l k8s-app=kube-dns -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES coredns-7568f67dbd-jw9cc 1/1 Running 5 (9m54s ago) 2d19h 10.244.0.23 master1 <none> <none> coredns-7568f67dbd-vv5v5 1/1 Running 5 (9m54s ago) 2d19h 10.244.0.25 master1 <none> <none>
我们可以先尝试手动访问下 /metrics 接口,如果能够手动访问到那证明接口是没有任何问题的:
☸ ➜ curl http://10.244.0.25:9153/metrics
# HELP coredns_build_info A metric with a constant '1' value labeled by version, revision, and goversion from which CoreDNS was built.
# TYPE coredns_build_info gauge
coredns_build_info{goversion="go1.16.4",revision="053c4d5",version="1.8.4"} 1
# HELP coredns_cache_entries The number of elements in the cache.
# TYPE coredns_cache_entries gauge
coredns_cache_entries{server="dns://:53",type="denial"} 2
coredns_cache_entries{server="dns://:53",type="success"} 1
# HELP coredns_cache_hits_total The count of cache hits.
# TYPE coredns_cache_hits_total counter
coredns_cache_hits_total{server="dns://:53",type="success"} 20
# HELP coredns_cache_misses_total The count of cache misses.
# TYPE coredns_cache_misses_total counter
coredns_cache_misses_total{server="dns://:53"} 4
......
我们可以看到可以正常访问到,从这里可以看到 CoreDNS 的监控数据接口是正常的了,然后我们就可以将这个 /metrics 接口配置到 prometheus.yml 中去了,直接加到默认的 prometheus 这个 job 下面:
# prometheus-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-mon
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: 'localhost:9090']
- job_name: 'coredns'
static_configs:
- targets: '10.244.0.23:9153', '10.244.0.25:9153']
当然,我们这里只是一个很简单的配置,scrape_configs 下面可以支持很多参数,例如:
-
basic_auth和bearer_token:比如我们提供的/metrics接口需要 basic 认证的时候,通过传统的用户名/密码或者在请求的 header 中添加对应的 token 都可以支持 -
kubernetes_sd_configs或consul_sd_configs:可以用来自动发现一些应用的监控数据
这些大部分属性前面我们已经介绍过了,现在我们重新更新这个 ConfigMap 资源对象:
☸ ➜ kubectl apply -f https://p8s.io/docs/k8s/manifests/prometheus/config-2.yaml configmap/prometheus-config configured
配置文件内容变更后,隔一会儿被挂载到 Pod 中的 prometheus.yml 文件也会更新,由于我们之前的 Prometheus 启动参数中添加了 --web.enable-lifecycle 参数,所以现在我们只需要执行一个 reload 命令即可让配置生效:
☸ ➜ kubectl get pods -n kube-mon -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES prometheus-649968556c-t4prd 1/1 Running 1 (17m ago) 27h 10.244.2.46 node2 <none> <none> ☸ ➜ curl -X POST "http://10.244.2.46:9090/-/reload"
由于 ConfigMap 通过 Volume 的形式挂载到 Pod 中去的热更新需要一定的间隔时间才会生效,所以需要稍微等一小会儿。
这个时候我们再去看 Prometheus 的 Dashboard 中查看采集的目标数据:
! prometheus webui coredns](https://www.qikqiak.com/k8strain2/assets/img/monitor/prometheus-webui-coredns.png)
可以看到我们刚刚添加的 coredns 这个任务已经出现了,然后同样的我们可以切换到 Graph 下面去,我们可以找到一些 CoreDNS 的指标数据,至于这些指标数据代表什么意义,一般情况下,我们可以去查看对应的 /metrics 接口,里面一般情况下都会有对应的注释。
! prometheus webui coredns metrics](https://www.qikqiak.com/k8strain2/assets/img/monitor/prometheus-webui-coredns-metrics.png)
到这里我们就在 Prometheus 上配置了第一个 Kubernetes 应用。
使用 exporter 监控
上面我们也说过有一些应用可能没有自带 /metrics 接口供 Prometheus 使用,在这种情况下,我们就需要利用 exporter 服务来为 Prometheus 提供指标数据了。Prometheus 官方为许多应用就提供了对应的 exporter 应用,也有许多第三方的实现,我们可以前往官方网站进行查看: exporters](Exporters and integrations | Prometheus),当然如果你的应用本身也没有 exporter 实现,那么就要我们自己想办法去实现一个 /metrics 接口了,只要你能提供一个合法的 /metrics 接口,Prometheus 就可以监控你的应用。
比如我们这里通过一个 redis-exporter](GitHub - oliver006/redis_exporter: Prometheus Exporter for Redis Metrics. Supports Redis 2.x, 3.x, 4.x, 5.x, 6.x, and 7.x) 的服务来监控 redis 服务,对于这类应用,我们一般会以 sidecar 的形式和主应用部署在同一个 Pod 中,比如我们这里来部署一个 redis 应用,并用 redis-exporter 的方式来采集监控数据供 Prometheus 使用,如下资源清单文件:
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
namespace: kube-mon
spec:
selector:
matchLabels:
app: redis
template:
metadata:
labels:
app: redis
spec:
containers:
- name: redis
image: redis:4
resources:
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 6379
- name: redis-exporter
image: oliver006/redis_exporter:latest
resources:
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 9121
---
kind: Service
apiVersion: v1
metadata:
name: redis
namespace: kube-mon
spec:
selector:
app: redis
ports:
- name: redis
port: 6379
targetPort: 6379
- name: prom
port: 9121
targetPort: 9121
可以看到上面我们在 redis 这个 Pod 中包含了两个容器,一个就是 redis 本身的主应用,另外一个容器就是 redis_exporter。现在直接创建上面的应用:
☸ ➜ kubectl apply -f https://p8s.io/docs/k8s/manifests/prometheus/redis.yaml
创建完成后,我们可以看到 redis 的 Pod 里面包含有两个容器:
☸ ➜ kubectl get pods -n kube-mon NAME READY STATUS RESTARTS AGE prometheus-79b8774f68-7m8zr 1/1 Running 0 54m redis-7c8bdd45cc-ssjbz 2/2 Running 0 2m1s ☸ ➜ kubectl get svc -n kube-mon NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE prometheus NodePort 10.111.160.152 <none> 9090:30407/TCP 27h redis ClusterIP 10.110.14.69 <none> 6379/TCP,9121/TCP 2m14s
我们可以通过 9121 端口来校验是否能够采集到数据:
☸ ➜ curl 10.110.14.69:9121/metrics
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 0
go_gc_duration_seconds{quantile="0.25"} 0
go_gc_duration_seconds{quantile="0.5"} 0
go_gc_duration_seconds{quantile="0.75"} 0
go_gc_duration_seconds{quantile="1"} 0
go_gc_duration_seconds_sum 0
go_gc_duration_seconds_count 0
......
# HELP redis_up Information about the Redis instance
# TYPE redis_up gauge
redis_up 1
# HELP redis_uptime_in_seconds uptime_in_seconds metric
# TYPE redis_uptime_in_seconds gauge
redis_uptime_in_seconds 100
同样的,现在我们只需要更新 Prometheus 的配置文件:
- job_name: "redis"
static_configs:
- targets: "redis:9121"]
由于我们这里是通过 Service 去配置的 redis 服务,当然直接配置 Pod IP 也是可以的,因为和 Prometheus 处于同一个 namespace,所以我们直接使用 servicename 即可。配置文件更新后,重新加载:
☸ ➜ kubectl apply -f https://p8s.io/docs/k8s/manifests/prometheus/config-3.yaml # 隔一会儿执行reload操作 ☸ ➜ curl -X POST "http://10.244.3.174:9090/-/reload"
这个时候我们再去看 Prometheus 的 Dashboard 中查看采集的目标数据:
! prometheus webui redis](https://www.qikqiak.com/k8strain2/assets/img/monitor/prometheus-webui-redis.png)
可以看到配置的 redis 这个 job 已经生效了。切换到 Graph 下面可以看到很多关于 redis 的指标数据,我们选择任意一个指标,比如 redis_exporter_scrapes_total,然后点击执行就可以看到对应的数据图表了:
! prometheus webui redisquery](https://www.qikqiak.com/k8strain2/assets/img/monitor/prometheus-webui-redis-query.png)
节点监控
前面我们和大家学习了怎样用 Promethues 来监控 Kubernetes 集群中的应用,但是对于 Kubernetes 集群本身的监控也是非常重要的,我们需要时时刻刻了解集群的运行状态。
监控方案
对于集群的监控一般我们需要考虑以下几个方面:
-
Kubernetes 节点的监控:比如节点的 cpu、load、disk、memory 等指标
-
内部系统组件的状态:比如 kube-scheduler、kube-controller-manager、kubedns/coredns 等组件的详细运行状态
-
编排级的 metrics:比如 Deployment 的状态、资源请求、调度和 API 延迟等数据指标
Kubernetes 集群的监控方案目前主要有以下几种方案:
-
cAdvisor: cAdvisor](https://github.com/google/cadvisor) 是 Google 开源的容器资源监控和性能分析工具,它是专门为容器而生,本身也支持 Docker 容器。 -
kube-state-metrics: kube-state-metrics](https://github.com/kubernetes/kube-state-metrics) 通过监听 API Server 生成有关资源对象的状态指标,比如 Deployment、Node、Pod,需要注意的是 kube-state-metrics 只是简单提供一个 metrics 数据,并不会存储这些指标数据,所以我们可以使用 Prometheus 来抓取这些数据然后存储。 -
metrics-server:metrics-server 也是一个集群范围内的资源数据聚合工具,是 Heapster 的替代品,同样的,metrics-server 也只是显示数据,并不提供数据存储服务。
不过 kube-state-metrics 和 metrics-server 之间还是有很大不同的,二者的主要区别如下:
-
kube-state-metrics 主要关注的是业务相关的一些元数据,比如 Deployment、Pod、副本状态等
-
metrics-server 主要关注的是 资源度量 API](https://github.com/kubernetes/community/blob/master/contributors/design-proposals/instrumentation/resource-metrics-api.md) 的实现,比如 CPU、文件描述符、内存、请求延时等指标。
监控集群节点
要监控节点同样我们这里使用 node_exporter](https://github.com/prometheus/node_exporter),由于每个节点我们都需要获取到监控指标数据,所以我们可以通过 DaemonSet 控制器来部署该服务,这样每一个节点都会自动运行一个 node-exporter 的 Pod,如果我们从集群中删除或者添加节点后,也会进行自动扩展。
在部署 node-exporter 的时候有一些细节需要注意,如下资源清单文件:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: kube-mon
labels:
app: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true
nodeSelector:
kubernetes.io/os: linux
containers:
- name: node-exporter
image: prom/node-exporter:v1.3.1
args:
- --web.listen-address=$(HOSTIP):9100
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
- --path.rootfs=/host/root
- --no-collector.hwmon # 禁用不需要的一些采集器
- --no-collector.nfs
- --no-collector.nfsd
- --no-collector.nvme
- --no-collector.dmi
- --no-collector.arp
- --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|var/lib/containerd/.+|/var/lib/docker/.+|var/lib/kubelet/pods/.+)($|/)
- --collector.filesystem.ignored-fs-types=^(autofs|binfmt_misc|cgroup|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|sysfs|tracefs)$
ports:
- containerPort: 9100
env:
- name: HOSTIP
valueFrom:
fieldRef:
fieldPath: status.hostIP
resources:
requests:
cpu: 150m
memory: 180Mi
limits:
cpu: 150m
memory: 180Mi
securityContext:
runAsNonRoot: true
runAsUser: 65534
volumeMounts:
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: root
mountPath: /host/root
mountPropagation: HostToContainer
readOnly: true
tolerations: # 添加容忍
- operator: "Exists"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: root
hostPath:
path: /
由于我们要获取到的数据是主机的监控指标数据,而我们的 node-exporter 是运行在容器中的,所以我们在 Pod 中需要配置一些 Pod 的安全策略,这里我们就添加了 hostPID: true、hostIPC: true、hostNetwork: true 3 个策略,用来使用主机的 PID namespace、IPC namespace 以及主机网络,这些 namespace 就是用于容器隔离的关键技术,要注意这里的 namespace 和集群中的 namespace 是两个完全不相同的概念。
另外我们还将主机的 /dev、/proc、/sys这些目录挂载到容器中,这些因为我们采集的很多节点数据都是通过这些文件夹下面的文件来获取到的,比如我们在使用 top 命令可以查看当前 cpu 使用情况,数据就来源于文件 /proc/stat,使用 free 命令可以查看当前内存使用情况,其数据来源是来自 /proc/meminfo 文件。
另外由于我们集群使用的是 kubeadm 搭建的,所以如果希望 master 节点也一起被监控,则需要添加相应的容忍,然后直接创建上面的资源对象:
☸ ➜ kubectl apply -f https://p8s.io/docs/k8s/manifests/prometheus/node-exporter.yaml ☸ ➜ kubectl get pods -n kube-mon -l app=node-exporter -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES node-exporter-b6w2v 1/1 Running 0 25m 192.168.31.31 master1 <none> <none> node-exporter-dmldp 1/1 Running 8 (20m ago) 25m 192.168.31.108 node1 <none> <none> node-exporter-wdxsb 1/1 Running 6 (22m ago) 25m 192.168.31.46 node2 <none> <none>
部署完成后,我们可以看到在 3 个节点上都运行了一个 Pod,由于我们指定了 hostNetwork=true,所以在每个节点上就会绑定一个端口 9100,我们可以通过这个端口去获取到监控指标数据:
☸ ➜ curl 10.151.31.31:9100/metrics
...
node_filesystem_device_error{device="shm",fstype="tmpfs",mountpoint="/rootfs/var/lib/docker/containers/aefe8b1b63c3aa5f27766053ec817415faf8f6f417bb210d266fef0c2da64674/shm"} 1
node_filesystem_device_error{device="shm",fstype="tmpfs",mountpoint="/rootfs/var/lib/docker/containers/c8652ca72230496038a07e4fe4ee47046abb5f88d9d2440f0c8a923d5f3e133c/shm"} 1
node_filesystem_device_error{device="tmpfs",fstype="tmpfs",mountpoint="/dev"} 0
node_filesystem_device_error{device="tmpfs",fstype="tmpfs",mountpoint="/dev/shm"} 0
...
服务发现
由于我们这里每个节点上面都运行了 node-exporter 程序,当然我们也可以手动的把所有节点用静态的方式配置到 Prometheus 中去,但是以后要新增或者去掉节点的时候就还得手动去配置,那么有没有一种方式可以让 Prometheus 去自动发现我们节点的 node-exporter 程序,并且按节点进行分组呢?这就是 Prometheus 里面非常重要的服务发现功能了。
节点发现
在 Kubernetes 下,Promethues 通过与 Kubernetes API 集成,主要支持 5 中服务发现模式,分别是:Node、Service、Pod、Endpoints、Ingress。
我们通过 kubectl 命令可以很方便的获取到当前集群中的所有节点信息:
☸ ➜ kubectl get nodes NAME STATUS ROLES AGE VERSION master1 Ready control-plane,master 55d v1.22.2 node1 Ready <none> 55d v1.22.2 node2 Ready <none> 55d v1.22.2
但是要让 Prometheus 也能够获取到当前集群中的所有节点信息的话,我们就需要利用 Node 的服务发现模式,同样的,在 prometheus.yml 文件中配置如下的 job 任务即可:
- job_name: "nodes"
kubernetes_sd_configs:
- role: node
通过指定 kubernetes_sd_configs 的模式为node,Prometheus 就会自动从 Kubernetes 中发现所有的 node 节点并作为当前 job 监控的目标实例,发现的节点 /metrics 接口是默认的 kubelet 的 HTTP 接口。
prometheus 的 ConfigMap 更新完成后,同样的我们执行 reload 操作,让配置生效:
☸ ➜ kubectl apply -f kubectl apply -f https://p8s.io/docs/k8s/manifests/prometheus/config-4.yaml # 隔一会儿执行reload操作 ☸ ➜ curl -X POST "http://10.244.2.46:9090/-/reload"
配置生效后,我们再去 prometheus 的 dashboard 中查看 Targets 是否能够正常抓取数据:
! prometheus webui nodes](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211220155000.png)
我们可以看到上面的 nodes 这个 job 任务已经自动发现了我们 3 个 node 节点,但是在获取数据的时候失败了,出现了类似于下面的错误信息:
server returned HTTP status 400 Bad Request
这个是因为 prometheus 去发现 Node 模式的服务的时候,访问的端口默认是 10250,而默认是需要认证的 https 协议才有权访问的,但实际上我们并不是希望让去访问 10250 端口的 /metrics 接口,而是 node-exporter 绑定到节点的 9100 端口,所以我们应该将这里的 10250 替换成 9100,但是应该怎样替换呢?
relabel
这里我们就需要使用到 Prometheus 提供的 relabel_configs 中的 replace 能力了,relabel 可以在 Prometheus 采集数据之前,通过 Target 实例的 Metadata 信息,动态重新写入 Label 的值。除此之外,我们还能根据 Target 实例的 Metadata 信息选择是否采集或者忽略该 Target 实例。比如我们这里就可以去匹配 __address__ 这个 Label 标签,然后替换掉其中的端口,如果你不知道有哪些 Label 标签可以操作的话,可以切换到 Service Discovery 页面找到 nodes 任务,下面的 Discovered Labels 就是我们可以操作的标签:
! prometheus webui relabel before](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211220155107.png)
现在我们来替换掉端口,修改 ConfigMap:
- job_name: "nodes"
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: __address__]
regex: "(.*):10250"
replacement: "${1}:9100"
target_label: __address__
action: replace
这里就是一个正则表达式,去匹配 __address__ 这个标签,然后将 host 部分保留下来,port 替换成了 9100,现在我们重新更新配置文件,执行 reload 操作,然后再去看 Prometheus 的 Dashboard 的 Targets 路径下面 nodes 这个 job 任务是否正常了:
! prometheus webui sd nodes](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211220155345.png)
我们可以看到现在已经正常了,但是还有一个问题就是我们采集的指标数据 Label 标签就只有一个节点的 hostname,这对于我们在进行监控分组分类查询的时候带来了很多不方便的地方,要是我们能够将集群中 Node 节点的 Label 标签也能获取到就很好了。这里我们可以通过 labelmap 这个属性来将 Kubernetes 的 Label 标签添加为 Prometheus 的指标数据的标签:
- job_name: "kubernetes-nodes"
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: __address__]
regex: "(.*):10250"
replacement: "${1}:9100"
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
添加了一个 action 为 labelmap,正则表达式是 __meta_kubernetes_node_label_(.+) 的配置,这里的意思就是表达式中匹配都的数据也添加到指标数据的 Label 标签中去。
重新配置后的监控目标标签就多了很多了:
! nodes labelmap](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211220155542.png)
对于 kubernetes_sd_configs 下面可用的元信息标签如下:
-
__meta_kubernetes_node_name:节点对象的名称 -
_meta_kubernetes_node_label:节点对象中的每个标签 -
_meta_kubernetes_node_annotation:来自节点对象的每个注释 -
_meta_kubernetes_node_address:每个节点地址类型的第一个地址(如果存在)
关于 kubernets_sd_configs 更多信息可以查看官方文档: kubernetes_sd_config](Configuration | Prometheus)
另外由于 kubelet 也自带了一些监控指标数据,就上面我们提到的 10250 端口,所以我们这里也把 kubelet 的监控任务也一并配置上:
- job_name: "kubelet"
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
但是这里需要特别注意的是这里必须使用 https 协议访问,这样就必然需要提供证书,我们这里是通过配置 insecure_skip_verify: true 来跳过了证书校验,但是除此之外,要访问集群的资源,还必须要有对应的权限才可以,也就是对应的 ServiceAccount 棒的 权限允许才可以,我们这里部署的 prometheus 关联的 ServiceAccount 对象前面我们已经提到过了,这里我们只需要将 Pod 中自动注入的 /var/run/secrets/kubernetes.io/serviceaccount/ca.crt 和 /var/run/secrets/kubernetes.io/serviceaccount/token 文件配置上,就可以获取到对应的权限了。
现在我们再去更新下配置文件,执行 reload 操作,让配置生效,然后访问 Prometheus 的 Dashboard 查看 Targets 路径:
现在可以看到我们上面添加的 kubelet 和 nodes 这两个 job 任务都已经配置成功了,而且二者的 Labels 标签都和集群的 node 节点标签保持一致了。
现在我们就可以切换到 Graph 路径下面查看采集的一些指标数据了,比如查询 node_load1 指标:
我们可以看到将 3 个节点对应的 node_load1 指标数据都查询出来了,同样的,我们还可以使用 PromQL 语句来进行更复杂的一些聚合查询操作,还可以根据我们的 Labels 标签对指标数据进行聚合。
到这里我们就把 Kubernetes 集群节点使用 Prometheus 监控起来了,接下来我们再来和大家学习下怎样监控 Pod 或者 Service 之类的资源对象。
容器监控
说到容器监控我们自然会想到 cAdvisor,我们前面也说过 cAdvisor 已经内置在了 kubelet 组件之中,所以我们不需要单独去安装,cAdvisor 的数据路径为 /api/v1/nodes/<node>/proxy/metrics,但是我们不推荐使用这种方式,因为这种方式是通过 APIServer 去代理访问的,对于大规模的集群会对 APIServer 造成很大的压力,所以我们可以直接通过访问 kubelet 的 /metrics/cadvisor 这个端点来获取 cAdvisor 的数据。
cAdvisor
我们这里使用 node 的服务发现模式,因为每一个节点下面都有 kubelet,自然都有 cAdvisor 采集到的数据指标,配置如下:
- job_name: "cadvisor"
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
- replacement: /metrics/cadvisor # <nodeip>/metrics -> <nodeip>/metrics/cadvisor
target_label: __metrics_path__
# 下面的方式不推荐使用
# - target_label: __address__
# replacement: kubernetes.default.svc:443
# - target_label: __metrics_path__
# replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
上面的配置和我们之前配置 node-exporter 的时候几乎是一样的,区别是我们这里使用了 https 的协议,另外需要注意的是配置了 ca.cart 和 token 这两个文件,这两个文件是 Prometheus 的 Pod 启动后自动注入进来的,然后加上 __metrics_path__ 的访问路径 /metrics/cadvisor,现在同样更新下配置,然后查看 Targets 路径:
! prometheus webui cadvisor](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211222114816.png)
指标查询
我们可以切换到 Graph 路径下面查询容器相关数据,比如我们这里来查询集群中所有 Pod 的 CPU 使用情况,kubelet 中的 cAdvisor 采集的指标和含义,可以查看 Monitoring cAdvisor with Prometheus](https://github.com/google/cadvisor/blob/master/docs/storage/prometheus.md) 说明,比如其中有一项:
container_cpu_usage_seconds_total Counter Cumulative cpu time consumed seconds
container_cpu_usage_seconds_total 是容器累计使用的 CPU 时间,用它除以 CPU 的总时间,就可以得到容器的 CPU 使用率了。
首先计算容器的 CPU 占用时间,由于节点上的 CPU 有多个,所以需要将容器在每个 CPU 上占用的时间累加起来,Pod 在 1m 内累积使用的 CPU 时间为:(根据 pod 和 namespace 进行分组查询)
sum(rate(container_cpu_usage_seconds_total{image!="",pod!=""} 1m])) by (namespace, pod)
然后计算 CPU 的总时间,这里的 CPU 数量是容器分配到的 CPU 数量,container_spec_cpu_quota 这个指标就是容器的 CPU 配额,它的值是容器指定的 CPU 个数 * 100000,所以 Pod 在 1s 内 CPU 的总时间为:Pod 的 CPU 核数 * 1s:
sum(container_spec_cpu_quota{image!="", pod!=""}) by(namespace, pod) / 100000
由于
container_spec_cpu_quota是容器的 CPU 配额,所以只有配置了resource-limitCPU 的 Pod 才可以获得该指标数据。
将上面这两个语句的结果相除,就得到了容器的 CPU 使用率:
(sum(rate(container_cpu_usage_seconds_total{image!="",pod!=""} 1m])) by (namespace, pod))
/
(sum(container_spec_cpu_quota{image!="", pod!=""}) by(namespace, pod) / 100000) * 100
在 promethues 里面执行上面的 promQL 语句可以得到下面的结果:
! prometheus cadvisor cpu rate](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211222122058.png)
Pod 内存使用率的计算就简单多了,不过我们也要想了解几个和 Pod 内存使用率相关的指标:
整体来说 container_memory_max_usage_bytes > container_memory_usage_bytes >= container_memory_working_set_bytes > container_memory_rss,从上面的指标描述来看似乎 container_memory_usage_bytes 指标可以更容易用来跟踪内存使用率,但是该指标还包括在内存压力下可能被驱逐的缓存(比如文件系统缓存),更好的指标是使用 container_memory_working_set_bytes,因为 kubelet 也是根据该指标来判断是否 OOM 的,所以用 working set 指标来评估内存使用率更加科学,对应的 PromQL 语句如下所示:
sum(container_memory_working_set_bytes{image!=""}) by(namespace, pod) / sum(container_spec_memory_limit_bytes{image!=""}) by(namespace, pod) * 100 != +inf
在 Promethues 里面执行上面的 promQL 语句可以得到下面的结果:
监控 APIServer
APIServer 作为 Kubernetes 最核心的组件,当然他的监控也是非常有必要的,对于 APIServer 的监控我们可以直接通过 Kubernetes 的 Service 来获取:
☸ ➜ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 33d
自动发现
上面这个 Service 就是我们集群的 apiserver 在集群内部的 Service 地址,要自动发现 Service 类型的服务,我们就需要用到 role 为 Endpoints 的 kubernetes_sd_configs,我们可以在 ConfigMap 对象中添加上一个 Endpoints 类型的服务的监控任务:
- job_name: "apiservers"
kubernetes_sd_configs:
- role: endpoints
上面这个任务是定义的一个类型为 endpoints 的 kubernetes_sd_configs ,添加到 Prometheus 的 ConfigMap 的配置文件中,然后更新配置:
☸ ➜ kubectl apply -f https://p8s.io/docs/k8s/manifests/prometheus/config-8.yaml # 隔一会儿执行reload操作 ☸ ➜ curl -X POST "http://10.244.2.46:9090/-/reload"
更新完成后,我们再去查看 Prometheus 的 Dashboard 的 target 页面:
! prometheus webui apiserver](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211223105612.png)
relabel
我们可以看到 apiservers 任务下面出现了很多实例,这是因为这里我们使用的是 Endpoints 类型的服务发现,所以 Prometheus 把所有的 Endpoints 服务都抓取过来了,同样的,上面我们需要的服务名为 kubernetes 这个 apiserver 的服务也在这个列表之中,那么我们应该怎样来过滤出这个服务来呢?同样还是需要使用relabel_configs 这个配置,只是我们这里不是使用 replace 这个动作了,而是 keep,就是只把符合我们要求的给保留下来,哪些才是符合我们要求的呢?我们要过滤的服务是 default 这个 namespace 下面,服务名为 kubernetes 的元数据,所以这里我们就可以根据对应的 __meta_kubernetes_namespace 和 __meta_kubernetes_service_name 这两个元数据来进行过滤,另外由于 kubernetes 这个服务对应的端口是 443,需要使用 https 协议,所以这里我们需要使用 https 的协议,对应的就需要将 ca 证书配置上,如下所示:
- job_name: "apiservers"
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels:
__meta_kubernetes_namespace,
__meta_kubernetes_service_name,
__meta_kubernetes_endpoint_port_name,
]
action: keep
regex: default;kubernetes;https
现在重新更新配置文件、重新加载 Prometheus,切换到 Prometheus 的 Targets 路径下查看:
! prometheus apiserver target](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211223105951.png)
现在可以看到 apiserver 这个任务下面只有 apiserver 这一个实例了,现在我们切换到 Graph 路径下面查看下采集到的数据,比如查询 apiserver 的总的请求数:
这样我们就完成了对 Kubernetes APIServer 的监控。
监控 Pod
前面的 apiserver 实际上就是一种特殊的 Endpoints,现在我们同样来配置一个任务用来专门发现普通类型的 Endpoint,其实就是 Service 关联的 Pod 列表,由于并不是所有的 Endpoints 都会提供 metrics 接口,所以需要我们主动告诉 Prometheus 去发现哪些 Endpoints,当然告诉的方式有很多,不过约定俗成的一种方式是通过 annotations 注解进行通知,如下所示:
- job_name: "endpoints"
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
# 保留 Service 的注解为 prometheus.io/scrape: true 的 Endpoints
- source_labels: __meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
# 指标接口协议通过 prometheus.io/scheme 这个注解获取 http 或 https
- source_labels: __meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
# 指标接口端点路径通过 prometheus.io/path 这个注解获取
- source_labels: __meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
# 直接接口地址端口通过 prometheus.io/port 注解获取
- source_labels:
__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ( ^:]+)(?::\d+)?;(\d+) # RE2 正则规则,+是一次或多次,?是0次或1次,其中?:表示非匹配组(意思就是不获取匹配结果)
replacement: $1:$2
# 映射 Service 的 Label 标签
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
# 将 namespace 映射成标签
- source_labels: __meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
# 将 Service 名称映射成标签
- source_labels: __meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
# 将 Pod 名称映射成标签
- source_labels: __meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
注意我们这里在 relabel_configs 区域做了大量的配置,特别是第一个保留__meta_kubernetes_service_annotation_prometheus_io_scrape 为 true 的才保留下来,这就是说要想自动发现集群中的 Endpoint,就需要我们在 Service 的 annotations 区域添加 prometheus.io/scrape=true 的注解,我们也可以借助 Relabeler - The playground for Prometheus relabeling rules 这个工具来帮助我们配置 Relabel。现在我们先将上面的配置更新,查看下效果:
! prometheus k8s endpoints](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20211227150940.png)
我们可以看到 endpoints 这一个任务下面只发现了 5 个任务,这是因为我们在 relabel_configs 中过滤了 annotations 有 prometheus.io/scrape=true 的 Service,而现在我们系统中只有两个这样的服务符合要求,比如 kube-dns 这个 Service 下面有两个实例,所以出现了两个实例:
☸ ➜ kubectl get svc kube-dns -n kube-system -o yaml
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/port: "9153" # metrics 接口的端口
prometheus.io/scrape: "true" # 这个注解可以让prometheus自动发现
creationTimestamp: "2021-10-25T12:33:14Z"
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
kubernetes.io/name: CoreDNS
name: kube-dns
namespace: kube-system
......
现在我们在之前创建的 redis 这个 Service 中添加上 prometheus.io/scrape=true 这个注解:
# redis-svc.yaml
kind: Service
apiVersion: v1
metadata:
name: redis
namespace: kube-mon
annotations:
prometheus.io/scrape: "true" # 让上面的自动发现能获取该服务
prometheus.io/port: "9121" # 指定metrics接口访问端口
spec:
selector:
app: redis
ports:
- name: redis
port: 6379
targetPort: 6379
- name: prom
port: 9121
targetPort: 9121
由于 redis 服务的 metrics 接口在 9121 这个 redis-exporter 服务上面,所以我们还需要添加一个 prometheus.io/port=9121 这样的 annotations,然后更新这个 Service:
☸ ➜ kubectl apply -f https://p8s.io/docs/k8s/manifests/prometheus/redis-svc.yaml
更新完成后,去 Prometheus 查看 Targets 路径,可以看到 redis 服务自动出现在了 endpoints 这个任务下面:
这样以后我们有了新的服务,如果服务本身提供了 /metrics 接口,我们就完全不需要用静态的方式去配置了,现在我们就可以将之前配置的 redis 静态配置去掉了。
Alertmanager 告警
前面我们学习 Prometheus 的时候了解到 Prometheus 包含一个报警模块,就是我们的 AlertManager,Alertmanager 主要用于接收 Prometheus 发送的告警信息,它支持丰富的告警通知渠道,而且很容易做到告警信息进行去重,降噪,分组等,是一款前卫的告警通知系统。
介绍
通过在 Prometheus 中定义告警规则,Prometheus 会周期性的对告警规则进行计算,如果满足告警触发条件就会向 Alertmanager 发送告警信息。
! alertmanager workflow](https://bxdc-static.oss-cn-beijing.aliyuncs.com/images/20200326101221.png)
在 Prometheus 中一条告警规则主要由以下几部分组成:
-
告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容
-
告警规则:告警规则实际上主要由
PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后触发告警
在 Prometheus 中,还可以通过 Group(告警组)对一组相关的告警进行统一定义。Alertmanager 作为一个独立的组件,负责接收并处理来自 Prometheus Server 的告警信息。Alertmanager 可以对这些告警信息进行进一步的处理,比如当接收到大量重复告警时能够消除重复的告警信息,同时对告警信息进行分组并且路由到正确的通知方,Prometheus 内置了对邮件、Slack 多种通知方式的支持,同时还支持与 Webhook 的集成,以支持更多定制化的场景。例如,目前 Alertmanager 还不支持钉钉,用户完全可以通过 Webhook 与钉钉机器人进行集成,从而通过钉钉接收告警信息。同时 AlertManager 还提供了静默和告警抑制机制来对告警通知行为进行优化。
安装
从官方文档 Configuration | Prometheus 中我们可以看到下载 AlertManager 二进制文件后,可以通过下面的命令运行:
./alertmanager --config.file=simple.yml
其中 -config.file 参数是用来指定对应的配置文件的,由于我们这里同样要运行到 Kubernetes 集群中来,所以我们使用 Docker 镜像的方式来安装,使用的镜像是:prom/alertmanager:v0.23.0。
首先,指定配置文件,同样的,我们这里使用一个 ConfigMap 资源对象:
# config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alert-config
namespace: kube-mon
data:
config.yml: |-
global:
# 当 alertmanager 持续多长时间未接收到告警后标记告警状态为 resolved
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.163.com:25'
smtp_from: ' email protected]' # 163邮箱地址
smtp_auth_username: ' email protected]'
smtp_auth_password: '<邮箱密码>' # 使用网易邮箱的授权码
smtp_hello: '163.com'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: 'alertname', 'cluster']
# 当一个新的报警分组被创建后,需要等待至少 group_wait 时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 相同的group之间发送告警通知的时间间隔
group_interval: 30s
# 如果一个报警信息已经发送成功了,等待 repeat_interval 时间来重新发送他们,不同类型告警发送频率需要具体配置
repeat_interval: 1h
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
routes:
- receiver: email
group_wait: 10s
match:
team: node
receivers:
- name: 'default'
email_configs:
- to: ' email protected]'
send_resolved: true # 接受告警恢复的通知
- name: 'email'
email_configs:
- to: ' email protected]'
send_resolved: true
分组
分组机制可以将详细的告警信息合并成一个通知,在某些情况下,比如由于系统宕机导致大量的告警被同时触发,在这种情况下分组机制可以将这些被触发的告警合并为一个告警通知,避免一次性接受大量的告警通知,而无法对问题进行快速定位。
这是 AlertManager 的配置文件,我们先直接创建这个 ConfigMap 资源对象:
☸ ➜ kubectl apply -f https://p8s.io/docs/alertmanager/manifests/config.yaml configmap/alert-config created
然后配置 AlertManager 的容器,直接使用一个 Deployment 来进行管理即可,对应的 YAML 资源声明如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: kube-mon
labels:
app: alertmanager
spec:
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
volumes:
- name: alertcfg
configMap:
name: alert-config
containers:
- name: alertmanager
image: prom/alertmanager:v0.23.0
imagePullPolicy: IfNotPresent
args:
- "--config.file=/etc/alertmanager/config.yml"
ports:
- containerPort: 9093
name: http
volumeMounts:
- mountPath: "/etc/alertmanager"
name: alertcfg
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 100m
memory: 256Mi
这里我们将上面创建的 alert-config 这个 ConfigMap 资源对象以 Volume 的形式挂载到 /etc/alertmanager 目录下去,然后在启动参数中指定了配置文件 --config.file=/etc/alertmanager/config.yml,然后我们可以来创建这个资源对象:
☸ ➜ kubectl apply -f https://p8s.io/docs/alertmanager/manifests/deploy.yaml deployment.apps/alertmanager created
为了可以访问到 AlertManager,同样需要我们创建一个对应的 Service 对象:
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: kube-mon
labels:
app: alertmanager
spec:
selector:
app: alertmanager
type: NodePort
ports:
- name: web
port: 9093
targetPort: http
使用 NodePort 类型也是为了方便测试,创建上面的 Service 这个资源对象:
☸ ➜ kubectl apply -f https://p8s.io/docs/alertmanager/manifests/service.yaml service/alertmanager created
AlertManager 的容器启动起来后,我们还需要在 Prometheus 中配置下 AlertManager 的地址,让 Prometheus 能够访问到 AlertManager,在 Prometheus 的 ConfigMap 资源清单中添加如下配置:
alerting:
alertmanagers:
- static_configs:
- targets: "alertmanager:9093"]
更新这个资源对象后,稍等一小会儿,执行 reload 操作即可。



















 96
96

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
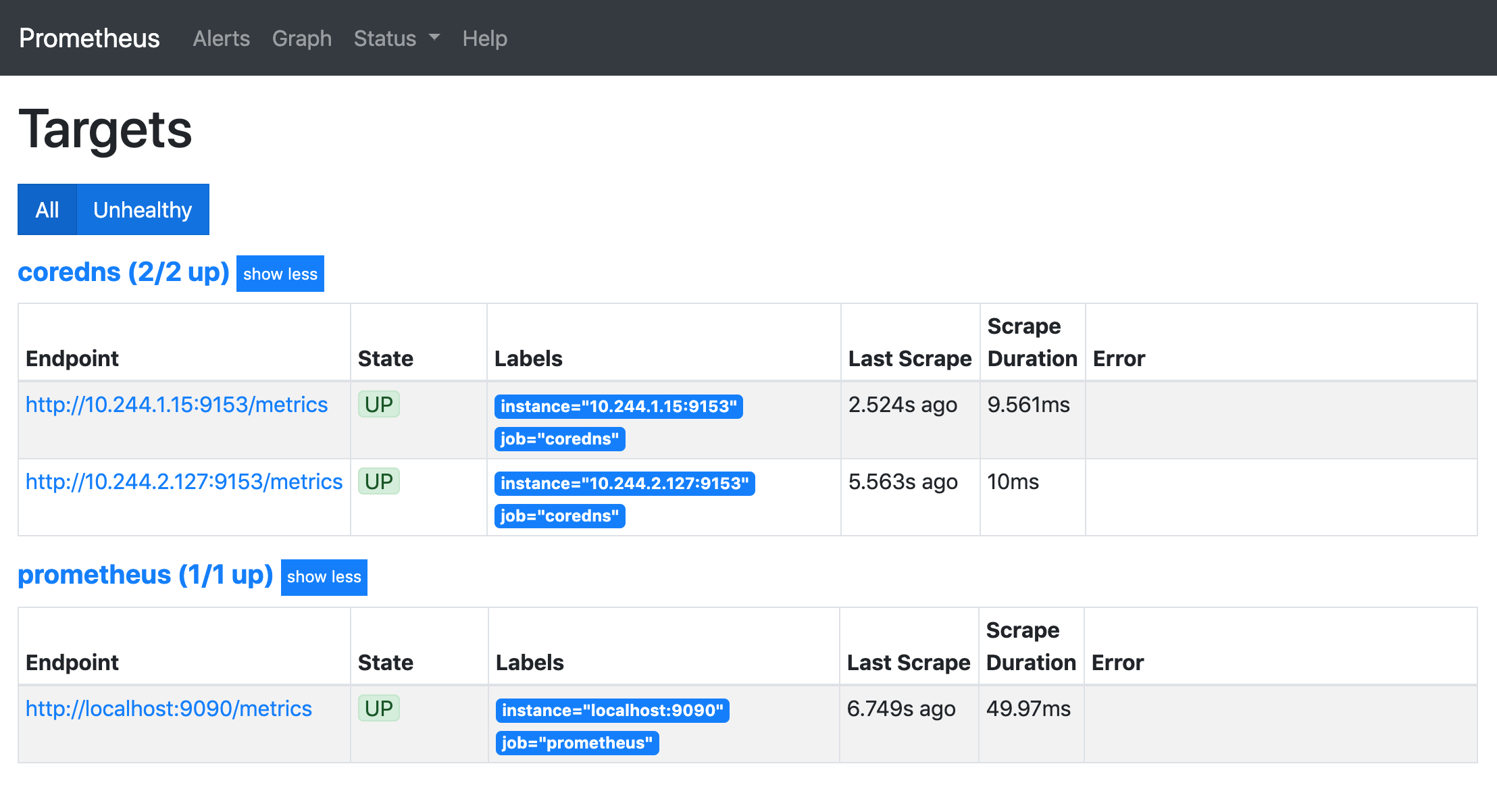{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}