










功能结构图

数据库设计总结
该项目主要就是对文件的操作,file表,file_share表。
file表主要字段:id,用户id,父级目录id,文件的地址,文件的封面图片地址,创建和修改时间。

file_share表主要字段:id,文件id,用户id,有效类型,创建和失效时间(用于定时任务)。

基于RDAB的五张表:用户信息表,角色表,权限表,用户角色关联表(多对多关系),角色权限关联表(多对多关系)。

基础设置表:id,邮箱标题,邮箱内容前缀,默认初始化空间大小。

登录模块总结
单点登录->双token三认证(迭代方案)
版本1.0时我们采用单点登录的方式做校验的,其问题就是我们无法控制token的有效时间。并且token是存放在session中。
在版本2.0中我们使用双token三认证模型,主要就是基于长短token来实现的。长短token存放在cookie中。
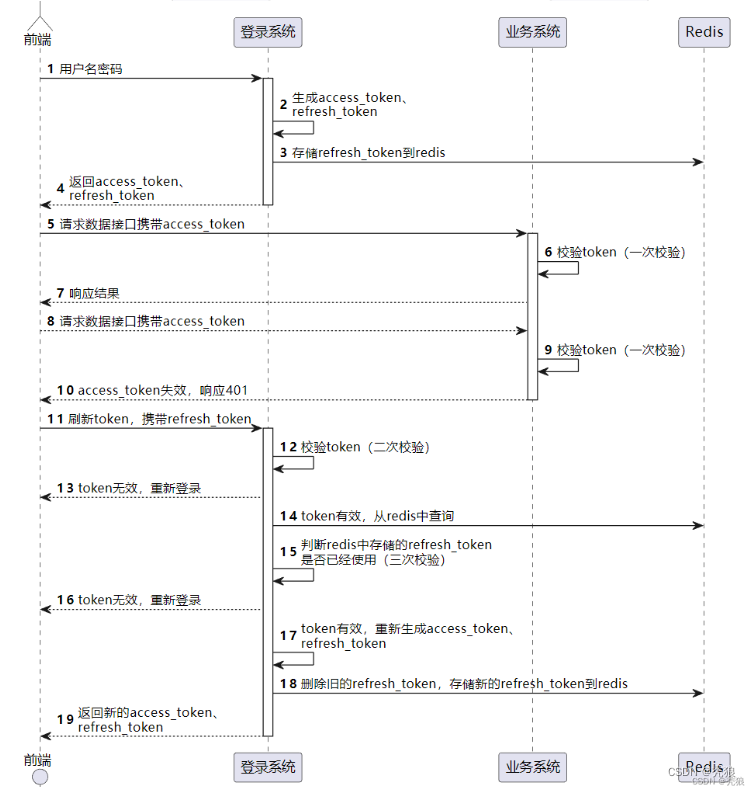
在用户登录完成之后,就会通过JWT及我们配置的私钥来生成对应的长短token,并且会将加密后的长token作为key,value为1存储到redis中,请求会携带这两个token。短token用来校验,长token用来生成新的长短token。
在执行业务的时候就会去判断短token是否有效,通过公钥进行验证。此时就是第一次验证。
当发现短token无效,就会去判断长token是否有效,也是通过公钥进行验证的。此时就会第二次验证。
如果长token有效,就会去redis中查询长token是否存在,此时就是第三次验证。
通过三次验证后,就会去刷新token生成新的长短token。
权限隔离(迭代方案)
权限隔离,项目中主要分为普通用户和管理员,刚开始使用特殊字段作为权限标识,权限扩展起来就非常的麻烦,涉及修改表字段。因此就使用RDAB模型来实现权限隔离,可扩展性高。主要分为用户表,角色表,权限表,用户关联角色表(多对多的关系),角色关联权限表(多对多的关系),并配合springSecurity实现的。
文件列表总结
文件查询
文件列表为用户操作的主要模块,特别是在查询接口上存在高并发的场景,因此通过做缓存来优化查询接口,及使用布隆过滤器解决缓存穿透的问题。
缓存优化:通过springCache来实现缓存的,保证双写一致性。(主要就是使用@Cacheable,@CachePut,@CacheEvit实现的)
解决缓存穿透问题:通过使用redisson创建布隆过滤器,在数据做插入时也在布隆过滤器进行中标记,在进行查询的时候先到布隆布隆过滤器中做判断,防止缓存穿透的安全问题。
其实只要是对应暴露的如何数据库的curd方法都存在缓存穿透的问题。
文件转移
通过递归的形式来生成一个树形结构,选择对应的文件作为其新的父文件。当然在树形结构中只有文件夹类型的文件。
文件上传
在上传文件使用ffmpeg会分段生多个文件,并配合redis记录文件的总大小,保证文件的大小不会超过用户的总空间。此时会生成多个临时文件,在最终合并的时候使用io的形式将临时文件的数据全部存储到目标文件中(并完成对目标文件的记录),最终完成文件的分段上传。
优点就是在网络不佳时,可以只上传失败的数据即可。在分段完成之后会通过IO流的形式在服务器对应的地址上生成目标文件。
文件的分享模块
分享链接验证码校验
分享链接是会生成指定或随机的6为验证码,我们可以自定义该验证码的有效时间,将文件id作为key,加密(MD5)后的验证码作为value,并设置对应的ttl。校验时直接将输入的验证码加密后到redis中去匹配校验。
用户支持时获取的邮箱验证码也是基于此方法实现的。
分享残留数据清除
此时数据库会有分享记录残留的问题。我们就会使用xxl-job做定时任务来清除残留的分享记录。
通过在xxl-job中创建执行器和对应的定时任务,此时分享残留数据清除每隔4小时执行一次,设置定时任务的时间。采用默认的轮询路由策略。定时的调用查询过期的发现链接并删除。
配置对应的xxl-job参数
# xxl-job executor配置
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
xxl.job.executor.appname=my-executor-app
xxl.job.executor.ip=
xxl.job.executor.port=9999
xxl.job.accessToken=
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
xxl.job.executor.logretentiondays=30
创建JobHander指定其名字
import com.xxl.job.core.handler.annotation.XxlJob;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
@Component
public class MyJobHandler {
private static final Logger logger = LoggerFactory.getLogger(MyJobHandler.class);
@XxlJob("myJobHandler")
public void execute() throws Exception {
// 任务逻辑
logger.info("XXL-Job, Hello World.");
// 调用清除过期分享链接的方法
}
}
在xxl-job的可视化界面中创建执行器和对应的任务并提供CORN设置定时时间,实现循环定时任务。
文件回收模块总结
文件会在一周(7天)后被主动清除,在刚开始制定解决方案的时候,考虑使用线程睡眠来实现延迟任务。缺点很明显,当任务量大时就会大量占用CPU使用权,效率非常低下。
优化方案:使用RabbitMq的延迟队列,通过自定义消息的ttl来实现延迟回收的效果,因为是异步的执行任务,所以在效率上是比较高的。
配置过程还是很简单的,创建死信交换机和死信队列绑定给普通的消息队列,对每个回收消息设置ttl,并将回收消息发送到普通的消息队列中,监听对应的死性队列并消费消息完成回收任务(真正的删除文件及删除对应所有的子文件,并非逻辑删除)。
问:那取消回收,对应的延迟回收任务还会执行吗?
监听器还是会去消费对应的回收消息,但是在回收之前还会做逻辑字段的判断,如果依旧是逻辑删除状态则执行回收,反之就不回收。
问:一直点删除和取消回收岂不是会存储产生大量的消息,最终导致消息堆积,该怎么解决呢?
项目目前是面向小用户,没有考虑百万级的数据,出现这种情况的话,首先会考虑将死性队列的类型升级为惰性队列,增加队列的容量,此时就是使用磁盘作为存储空间,这会导致大量的IO操作,效率上会低一点。
问:如果还原文件的父目录被在删除了,那在文件的还原上是怎么处理的呢?
如果还原文件的父文件被删除了,我们的就会修改被还原文件的父文件id为0,也就是主目录id。如果父目录只是逻辑删除的话,该还原文件的状态取决于父目录的逻辑删除状态。
问:处理使用rabbitMq来解决的,我们还可以使用什么方案呢?
可以考虑使用xxl-job做定时任务。我记得定时任务都有对用的id,我们可以通过id来控制回收任务的执行和取消。具体没有实现过。
自定义日志模块总结
在自定义日志信息上使用 aop + 自定义注解 + log4j来实现的,对log4j的日志功能做了增强。
通过创建自定义注解,使用aop并以自定义注解为切点,使用前置通知对指定方法做增强的效果,也即是我们记录日志信息。
通过添加自定义注解来对指定方法做日志记录,通过log4j生成对应的日志文件。
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.springframework.stereotype.Component;
@Aspect
@Component
public class MyCustomAspect {
// 定义切点,指向自定义注解
@Pointcut("@annotation(MyCustomAnnotation)")
public void annotatedWithMyCustomAnnotation() {}
// 使用@Before通知打印日志
@Before("annotatedWithMyCustomAnnotation()")
public void beforeAdvice() {
System.out.println("执行了带有MyCustomAnnotation注解的方法");
}
// 根据需要添加其他通知,比如 @After, @Around 等
}问:日志中你通常会记录哪些信息呢?
主要就是记录:日志的级别,错误,时间,调用方法名,方法的参数信息,当前线程的信息。
问:在项目中什么情况下会记录日志信息呢?
当调用重要方法时和发生异常时会记录日志的信息。
简单的介绍一下你的项目吧?
项目主要就是实现百度云盘的基础功能。主要分为:登录模块,文件列表模块,分享模块,回收站模块,管理员设置模块。这个项目已经为迭代了两个版本。
1.我先给您介绍一下登录模块吧,在旧版本中,我们使用单点登录来实现的,将token存放在s sesion中,我们无法合理的控制token的有效时间。因此在新版本中使用双token三认证来实现的......
2.我们的管理员有特殊权限,由控制标记字段优化为使用RDAB模型来实现的权限系统,提高了扩展性......
3.用户主要操作的就是文件列表,其存在高qps的情况,因此对其做了缓存,为了防止无效字段的重复查询数据也就是缓存穿透问题,我们使用布隆过滤器来解决的......
在上传上使用ffmpeg实现分段上传......
4.回收模块,回收站中文件的有效期为7天,过期后会自动删除。在刚开始考虑解决方案的时候,先是想到使用线程睡眠......
5.分享模块,我们会将分享链接信息存到mysql并提高redis来控制有效期,此时就会存在过期分享的数据残留,我们使用xxl-job来定时的清除残留数据......
6.为了提高日志记录的扩展性,使用 aop + 自定义注解 + Log4j 来实现的,主要就是.......


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









