






一、朴素贝叶斯的基本概念
1.1 定义
朴素贝叶斯是一种基于贝叶斯定理的分类算法,假设特征之间条件独立(即“朴素”假设)。
1.2 核心公式:贝叶斯定理
说明:
-
𝑃(𝐶∣𝑋): 后验概率,给定特征 X 时类别 C 的概率。
-
𝑃(𝑋∣𝐶): 似然概率,给定类别 C 时特征 X 的概率。
-
𝑃(𝐶): 先验概率,类别 C 的概率。
-
𝑃(𝑋): 证据(归一化常数),通常在分类时可忽略。
1.3 朴素假设:特征 X=(x1,x2,…,xn) 在给定类别 𝐶 下条件独立
二、分类决策
朴素贝叶斯分类器通过最大化后验概率进行分类,即选择P(C|X)最大的类别。
由于P(X)对所有类别相同,常使用最大化P(X|C)P(C)的规则
扩展:为避免数值下溢,实际计算中常使用对数形式
三、不同类型的朴素贝叶斯模型
根据特征分布的不同,朴素贝叶斯有多种变体:
3.1 高斯朴素贝叶斯(Gaussian Naive Bayes)
假设特征服从正态分布,适用于连续特征。
对于特征在类别C下的概率:
其中、
分别为类别C下特征
的均值和方差
3.2 多项式朴素贝叶斯(Multinomial Naive Bayes)
适用于离散特征(如词频)
-
𝑁𝑥𝑖,𝐶: 类别 C 中特征 xi 的计数
-
𝑁𝐶: 类别 C 中所有特征的总数
-
𝛼: 拉普拉斯平滑参数
-
𝑛: 特征总数
3.3 伯努利朴素贝叶斯(Bernoulli Naive Bayes)
适用于二值特征(0/1)
四、实例:基于朴素贝叶斯的好瓜预测
目标是根据一系列已知特征,判断一个西瓜是“好瓜”(标记为“是”)还是“坏瓜”(标记为“否”)。
任务: 对一个给定的西瓜样本进行二分类(好瓜/坏瓜)
4.1 训练数据
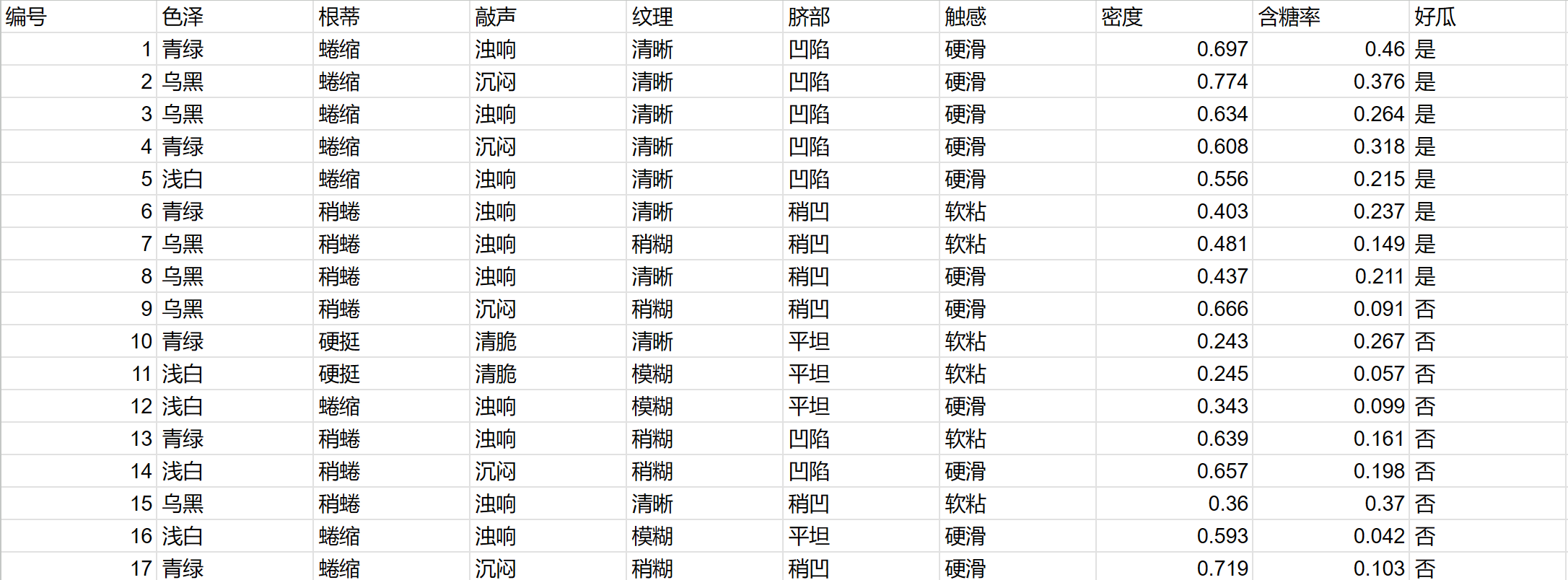
数据集摘要:
- 总样本数: 17
- 好瓜 (是) 数量: 8
- 坏瓜 (否) 数量: 9
4.2 测试数据
![]()
4.3 代码实现
import pandas as pd
import math
# 1. 数据准备
data = {
'色泽': ['青绿', '乌黑', '乌黑', '青绿', '浅白', '青绿', '乌黑', '乌黑', '乌黑', '青绿', '浅白', '浅白', '青绿',
'浅白', '乌黑', '浅白', '青绿'],
'根蒂': ['蜷缩', '蜷缩', '蜷缩', '蜷缩', '蜷缩', '稍蜷', '稍蜷', '稍蜷', '稍蜷', '硬挺', '硬挺', '蜷缩', '稍蜷',
'稍蜷', '稍蜷', '蜷缩', '蜷缩'],
'敲声': ['浊响', '沉闷', '浊响', '沉闷', '浊响', '浊响', '浊响', '浊响', '沉闷', '清脆', '清脆', '浊响', '浊响',
'沉闷', '浊响', '浊响', '沉闷'],
'纹理': ['清晰', '清晰', '清晰', '清晰', '清晰', '清晰', '稍糊', '清晰', '稍糊', '清晰', '模糊', '模糊', '稍糊',
'稍糊', '清晰', '模糊', '稍糊'],
'脐部': ['凹陷', '凹陷', '凹陷', '凹陷', '凹陷', '稍凹', '稍凹', '稍凹', '稍凹', '平坦', '平坦', '平坦', '凹陷',
'凹陷', '稍凹', '平坦', '稍凹'],
'触感': ['硬滑', '硬滑', '硬滑', '硬滑', '硬滑', '软粘', '软粘', '硬滑', '硬滑', '软粘', '软粘', '硬滑', '软粘',
'硬滑', '软粘', '硬滑', '硬滑'],
'密度': [0.697, 0.774, 0.634, 0.608, 0.556, 0.403, 0.481, 0.437, 0.666, 0.243, 0.245, 0.343, 0.639, 0.657, 0.360,
0.593, 0.719],
'含糖率': [0.460, 0.376, 0.264, 0.318, 0.215, 0.237, 0.149, 0.211, 0.091, 0.267, 0.057, 0.099, 0.161, 0.198, 0.370,
0.042, 0.103],
'好瓜': ['是', '是', '是', '是', '是', '是', '是', '是', '否', '否', '否', '否', '否', '否', '否', '否', '否']
}
df = pd.DataFrame(data)
discrete_cols = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感']
continuous_cols = ['密度', '含糖率']
target_col = '好瓜'
# --- 2. 训练模型:计算所需概率 ---
# 计算先验概率 P(y)
prior_prob_counts = df[target_col].value_counts()
prior_prob = (prior_prob_counts / len(df)).to_dict()
print("1. 先验概率:")
for class_label, prob in prior_prob.items():
print(f" P(好瓜={class_label}) = {prior_prob_counts[class_label]}/{len(df)} = {prob:.4f}")
# 计算离散特征的条件概率 P(xi|y)
cond_prob_discrete_direct = {}
print("\n2. 离散特征条件概率:")
for feature in discrete_cols:
cond_prob_discrete_direct[feature] = {}
for value in df[feature].unique():
cond_prob_discrete_direct[feature][value] = {}
for class_label in df[target_col].unique():
class_subset = df[df[target_col] == class_label]
count_feature_class = class_subset[class_subset[feature] == value].shape[0]
count_class = class_subset.shape[0]
prob_val = 0 if count_class == 0 else count_feature_class / count_class
cond_prob_discrete_direct[feature][value][class_label] = prob_val
if feature in ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感'] and \
value in ['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑']:
print(
f" P({feature}={value} | 好瓜={class_label}) = {count_feature_class}/{count_class} = {prob_val:.4f}")
# 计算连续特征的均值和标准差
mean_std_continuous = {}
print("\n3. 连续特征统计量:")
for feature in continuous_cols:
mean_std_continuous[feature] = {}
for class_label in df[target_col].unique():
class_subset = df[df[target_col] == class_label]
mean = class_subset[feature].mean()
std = class_subset[feature].std()
if std == 0: std = 1e-6
mean_std_continuous[feature][class_label] = {'mean': mean, 'std': std}
print(f" 特征'{feature}', 类别'{class_label}': Mean={mean:.3f}, StdDev={std:.3f}")
# 高斯概率密度函数
def gaussian_pdf(x, mean, std):
if std == 0: return 1e-6
exponent = math.exp(-((x - mean) ** 2 / (2 * std ** 2)))
return (1 / (math.sqrt(2 * math.pi) * std)) * exponent
# --- 3. 预测函数 ---
def predict_watermelon_detailed(test_data, prior_p, cond_p_discrete, mean_std_cont):
print(f"测试样本: {test_data}")
final_numeric_product_scores = {}
log_sum_scores = {}
for class_label in prior_p.keys():
print(f"\n计算类别为 '{class_label}' 的情况:")
current_prior_prob_val = prior_p[class_label]
current_log_prior_prob_val = math.log(current_prior_prob_val)
print(f" 1. 先验概率 P(好瓜={class_label}) = {current_prior_prob_val:.4f}")
total_numeric_prod = current_prior_prob_val
total_log_sum = current_log_prior_prob_val
# 离散特征
print(" 2. 离散特征条件概率:")
for feature in discrete_cols:
value = test_data[feature]
# 使用直接频率计算的条件概率
cond_p_val = cond_p_discrete[feature][value][class_label]
print(f" P({feature}={value} | 好瓜={class_label}) = {cond_p_val:.4f}")
total_numeric_prod *= cond_p_val
if cond_p_val > 0: # 防止 log(0)
total_log_sum += math.log(cond_p_val)
else: # 如果概率为0,整个乘积为0,对数和为负无穷
total_log_sum = -float('inf')
# 连续特征
print(" 3. 连续特征条件概率 (高斯PDF):")
for feature in continuous_cols:
x_val = test_data[feature]
stats = mean_std_cont[feature][class_label]
pdf_val = gaussian_pdf(x_val, stats['mean'], stats['std'])
print(
f" P({feature}={x_val} | 好瓜={class_label}) (μ={stats['mean']:.3f}, σ={stats['std']:.3f}) ≈ {pdf_val:.4f}")
total_numeric_prod *= pdf_val
if pdf_val > 0: # 防止 log(0)
total_log_sum += math.log(pdf_val)
else: # 如果PDF为0
total_log_sum = -float('inf')
final_numeric_product_scores[class_label] = total_numeric_prod
log_sum_scores[class_label] = total_log_sum
print(
f" => 对于类别 '{class_label}', 总连乘概率 P(好瓜={class_label}) * Π P(xi|好瓜={class_label}) ≈ {total_numeric_prod:.6e}")
print("\n4. 比较各类别的最终连乘概率:")
for class_label, score in final_numeric_product_scores.items():
print(f" P(好瓜={class_label}, X) ≈ {score:.6e}")
prediction_result = max(log_sum_scores, key=log_sum_scores.get) if all(
s != -float('inf') for s in log_sum_scores.values()) else \
max(final_numeric_product_scores, key=final_numeric_product_scores.get)
return prediction_result, log_sum_scores, final_numeric_product_scores
# --- 4. 进行预测 ---
test_sample = {
'色泽': '青绿', '根蒂': '蜷缩', '敲声': '浊响', '纹理': '清晰',
'脐部': '凹陷', '触感': '硬滑', '密度': 0.697, '含糖率': 0.460
}
prediction, detailed_log_scores, detailed_numeric_scores = predict_watermelon_detailed(
test_sample,
prior_prob,
cond_prob_discrete_direct,
mean_std_continuous
)
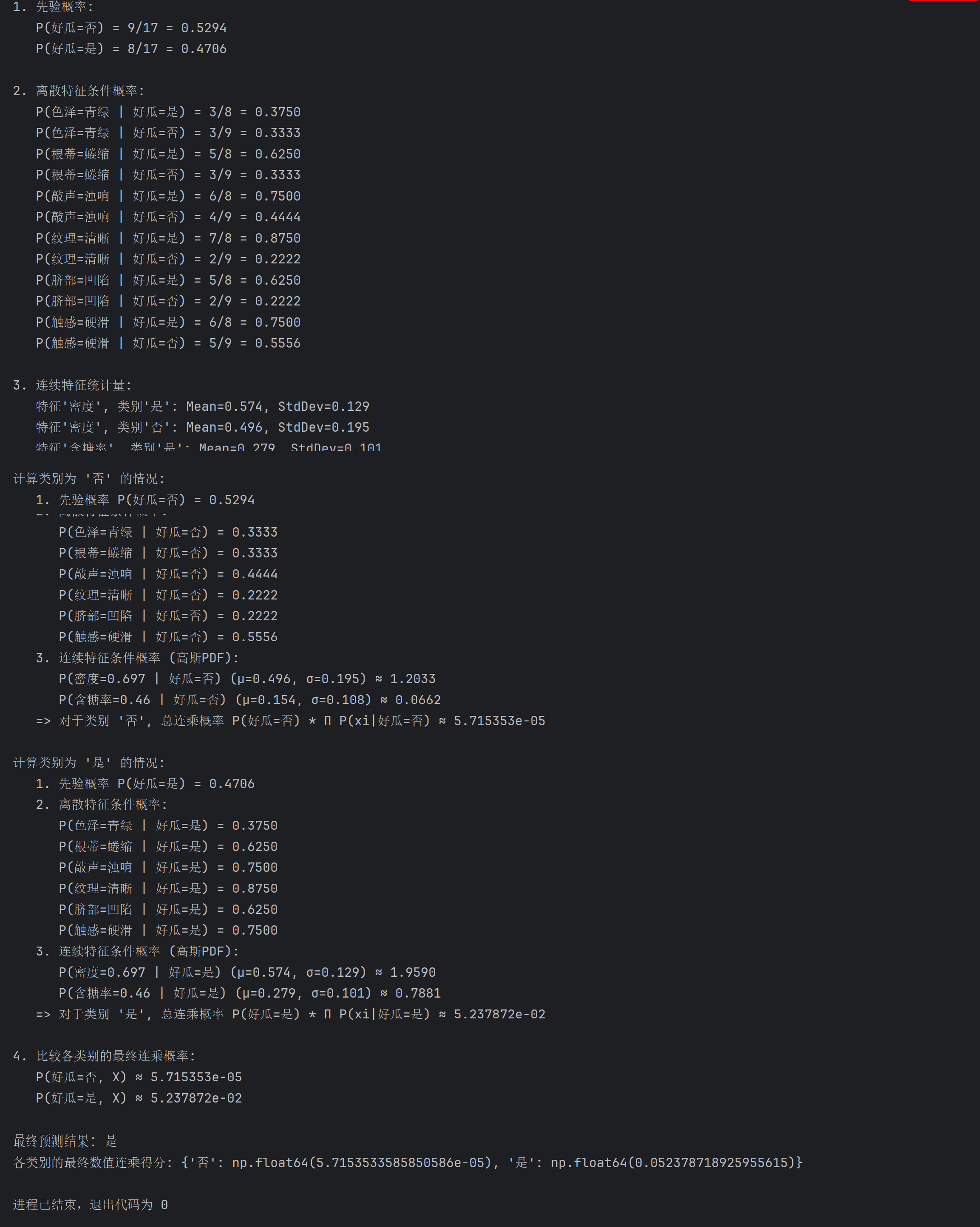
print(f"\n最终预测结果: {prediction}")
print(f"各类别的最终数值连乘得分: {detailed_numeric_scores}")4.4 代码运行结果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











