







大语言模型(LLMs)发展迅猛,但其在工具使用能力的训练上仍面临挑战。ToolRL通过创新的奖励设计,大幅提升LLMs的工具使用和泛化性能。想知道它是如何做到的吗?一起了解这一前沿研究,探索大模型训练的新突破!
论文标题
ToolRL: Reward is All Tool Learning Needs
来源
arXiv:2504.13958v1 [cs.LG] 16 Apr 2025
https://arxiv.org/abs/2504.13958
文章核心
研究背景
大语言模型(LLMs)在复杂推理任务中展现出强大能力,工具集成推理(Tool-Integrated Reasoning, TIR)成为提升其能力的重要方向,通过与外部工具交互解决LLMs知识过时、计算不准确等问题。
研究问题
- 目前训练LLMs进行TIR任务主要依赖监督微调(SFT),但SFT在泛化、探索和适应性方面存在不足,难以捕捉最优工具使用的策略灵活性。
- 在强化学习(RL)用于TIR时,奖励设计面临挑战,如多工具多参数调用场景下,粗粒度奖励信号无法提供有效学习所需的精细反馈。

主要贡献
- 系统性研究:首次对基于RL的通用工具选择和应用训练进行系统研究,探索多种奖励策略对LLMs工具使用能力的影响。
- 创新奖励设计:提出专门针对TIR的原则性奖励设计框架,将奖励分解为格式奖励和正确性奖励,通过细粒度评估工具调用的多个组件,更好地反映真实世界工具使用的复杂性。
- 有效训练方法:将奖励设计应用于组相对策略优化(GRPO)算法训练LLMs,实验表明该方法在多个工具使用和问答基准测试中优于基础模型和SFT模型,且训练的模型在未见场景和任务目标上具有良好的泛化能力。
方法论精要
1. 核心算法/框架
采用组相对策略优化(GRPO)算法,它是近端策略优化(PPO)的变体,通过在分组样本中引入优势归一化来稳定训练。整个方法还涉及到工具集成推理(TIR)的多个环节,包括Dask Definition、TIR Rollout、Reward Design和RL Training with GRPO。
2. 关键设计
Dask Definition
在工具集成推理(TIR)中,工具调用(Tool Call)是核心元素。工具调用由工具名称(Tool Name)和参数(Parameters)组成,每个参数又包含参数名称(Parameter Name)和参数内容(Parameter Content)。例如,在调用一个天气查询工具时,工具名称是“weather_query”,参数名称可能是“city”,参数内容则是具体的城市名,如“Beijing”。这种结构化的定义有助于清晰地表示工具调用的信息,为后续的奖励设计和模型训练提供基础。
TIR Rollout
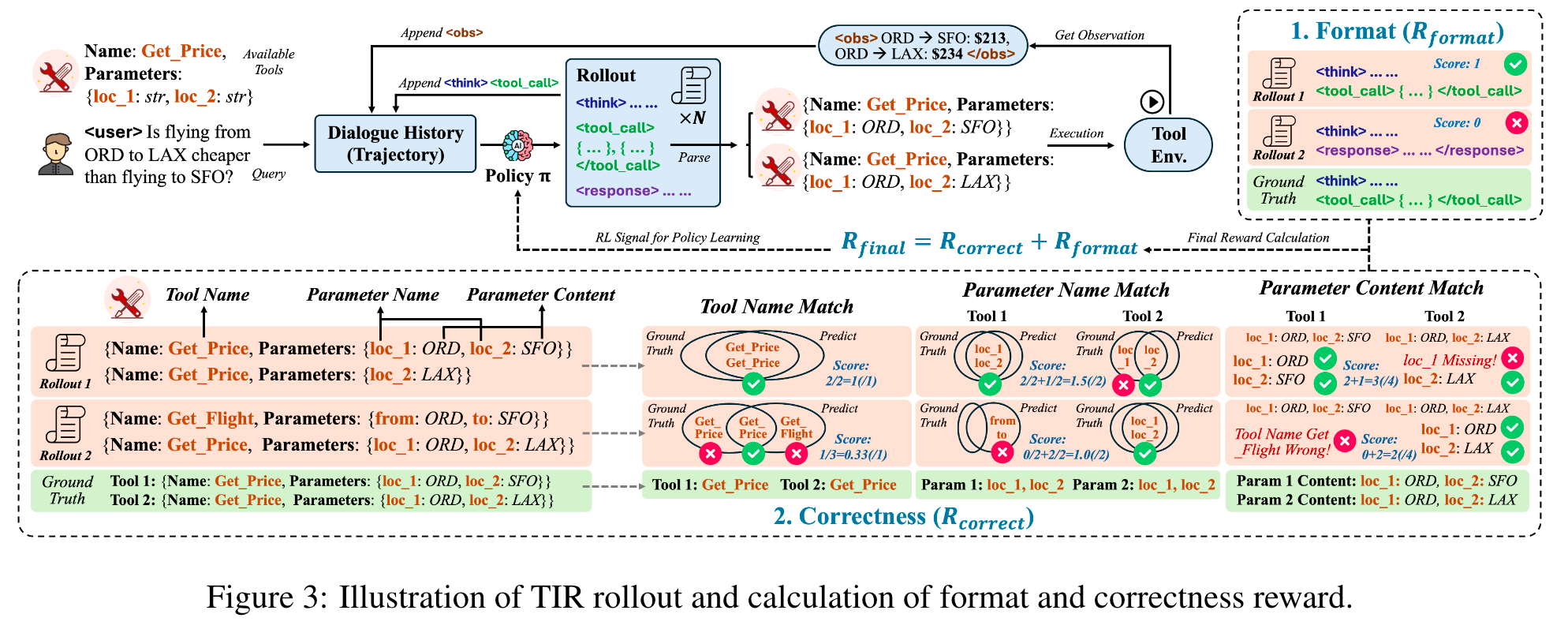
TIR Rollout过程从一个查询(Query)开始,模型生成一个工具调用序列(Tool Call Sequence)。在这个过程中,模型会根据当前的策略和输入信息,决定选择哪些工具以及如何设置工具的参数。每个工具调用都会产生一个输出(Output),这些输出会作为新的信息反馈给模型,影响后续的工具调用决策。例如,在一个多步骤的推理任务中,第一步调用一个数据查询工具获取相关数据,第二步根据这些数据调用一个计算工具进行计算,以此类推,直到得出最终的答案。

Reward Design
- 格式奖励(Format Reward):用于检查模型输出是否包含正确顺序的所有必需特殊令牌。如果模型输出的工具调用格式正确,即包含了所有必要的特殊令牌且顺序正确,则格式奖励取值为1;否则为0。例如,在一个特定的工具调用格式中,要求必须先出现工具名称,然后是参数列表,如果模型输出的顺序混乱或者缺少必要的部分,格式奖励就为0。
- 正确性奖励(Correctness Reward):通过工具名称匹配、参数名称匹配和参数内容匹配三个部分评估预测工具调用与真实调用的准确性。具体来说,工具名称匹配检查预测的工具名称与真实的工具名称是否一致;参数名称匹配检查预测的参数名称与真实的参数名称是否一致;参数内容匹配检查预测的参数内容与真实的参数内容是否一致。每个部分的匹配结果会进行量化,最终归一化到[-3, 3]范围。
整体奖励为格式奖励与正确性奖励之和,取值范围是[-3, 4] 。
RL Training with GRPO
在GRPO训练中,将训练数据按照查询进行分组。对于每个查询组,计算该组内所有样本的奖励均值和标准差,然后对样本的优势进行归一化处理。通过这种方式,GRPO算法可以在分组样本中引入优势归一化,从而稳定训练过程,避免训练过程中的剧烈波动。在训练过程中,模型根据奖励信号不断调整工具选择和使用策略,实现更有效的工具集成推理。
3. 创新性技术组合
将自定义的奖励设计与GRPO算法相结合,在训练过程中,模型根据奖励信号不断调整工具选择和使用策略,实现更有效的工具集成推理。同时,通过Dask Definition对工具调用进行结构化定义,为奖励设计和模型训练提供了清晰的基础;TIR Rollout过程模拟了真实的工具使用场景,使模型能够在动态的环境中学习和优化。
4. 实验验证方式
构建包含ToolACE、Hammer(Masked)和xLAM的混合数据集用于训练。选择伯克利函数调用排行榜(BFCL)、API - Bank和Bamboogle等基准测试进行评估。对比基线包括原始指令模型、在RL数据上进行SFT的模型、在SFT模型上应用GRPO的模型以及标准PPO模型,通过对比不同模型在各基准测试中的表现来验证方法的有效性。
实验洞察
- 性能优势:在BFCL基准测试中,基于Qwen - 2.5 - Instruct系列从头训练的GRPO模型,相比在相同数据量上进行SFT训练的模型,绝对准确率提升约10%;在API - Bank测试中,同样表现出色,优于多数基线模型。在Bamboogle测试中,该模型也取得了较高的准确率,且在处理自由形式的工具使用时,能有效调用工具,不依赖过多工具调用次数即可获得正确答案。
- 效率突破:论文中虽未明确提及训练/推理速度的优化程度,但从实验结果来看,GRPO算法结合特定奖励设计在训练过程中表现出良好的稳定性和收敛性,一定程度上反映了其在训练效率方面的优势。
- 消融研究:研究发现,添加长度奖励不一定能提升任务性能,在小模型中甚至可能降低性能;动态调整奖励尺度比突然改变更有助于模型学习和泛化;细粒度的奖励分解能提供更丰富的学习信号,相比粗粒度奖励公式,更有利于训练和提升最终任务性能。
本文由AI辅助完成。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









