







在大语言模型(LLMs)蓬勃发展的今天,工具集成推理(TIR)成为提升其能力的关键路径。但现有方法在工具使用效率上问题重重。这篇论文提出的OTC-PO框架,能让模型精准控制工具调用,大幅提升效率,快来一探究竟!
论文标题
OTC: Optimal Tool Calls via Reinforcement Learning
来源
arXiv:2504.14870v1 [cs.AI] 21 Apr 2025
https://arxiv.org/abs/2504.14870
文章核心
研究背景
大语言模型(LLMs)通过强化学习(RL)进行微调后展现出强大推理能力,但面对需要外部交互的任务,其内部推理能力不足。工具集成推理(TIR)成为解决该问题的有效范式,使LLMs能借助外部工具拓展功能。
研究问题
-
现有基于RL优化TIR的方法,常忽略工具使用的效率和成本。频繁且不必要的工具调用会增加计算和时间开销,还可能导致模型过度依赖外部工具,限制内部推理能力发展。
-
仅优化答案准确性,会忽视单个工具使用的成本和有效性,出现工具过度使用或使用不足的情况,影响推理效果。
-
监督微调(SFT)通常对不同的模型-问题对执行统一策略,无法适应不同模型和问题对工具调用需求的差异。
主要贡献
1. 系统解决工具效率问题:首次通过RL系统性地解决工具效率问题,识别出LLMs在TIR中的认知卸载现象,引入工具生产率概念衡量TIR的有效性和效率。
2. 提出OTC-PO算法:基于每个问题和模型对存在最优工具调用次数的观察,提出简单、可扩展且通用的OTC-PO算法,能与多种RL算法兼容,仅需少量代码修改即可实现。
3. 实现并验证新方法:实现了OTC-PPO和OTC-GRPO两种典型方法,在多个基准测试和基线实验中,显著降低工具调用成本,同时在域内和域外评估中保持较高准确率。
方法论精要
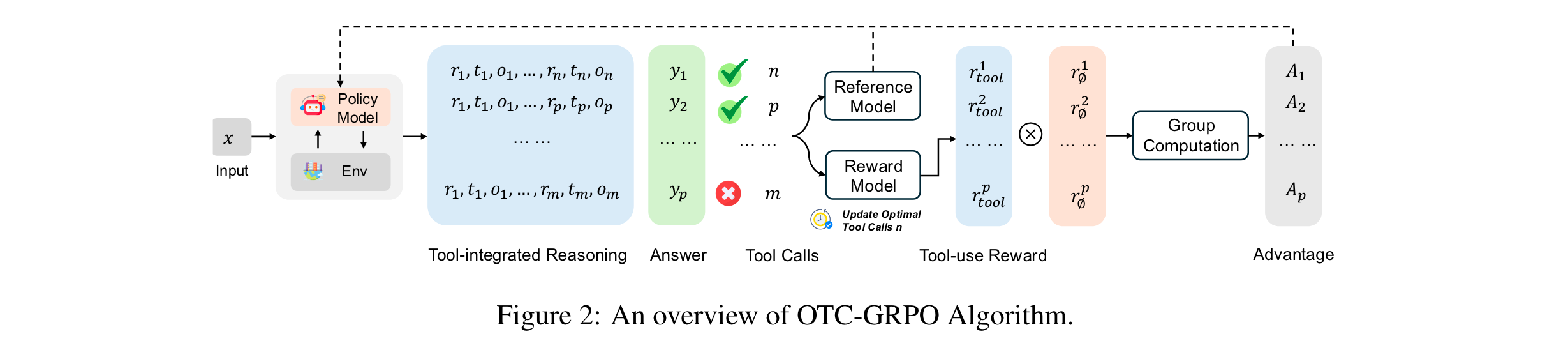
1. 核心算法/框架:Optimal Tool Call-controlled Policy Optimization(OTC-PO)框架,该框架可与多种RL算法结合,通过设计新的奖励机制优化工具调用策略。
2. 关键参数设计原理:引入工具集成奖励,通过缩放系数反映工具效率来调整传统奖励信号。在OTC-PPO中,根据当前轨迹中工具调用次数(m)设计工具奖励 r t o o l = c o s ( m ∗ π 2 m + c ) r_{tool }=cos \left(\frac{m * \pi}{2 m+c}\right) rtool=cos(2m+cm∗π) , c c c为控制奖励衰减率的平滑常数;在OTC-GRPO中,根据当前轨迹工具调用次数 m m m和近似最优工具调用次数 n n n设计奖励,当 n = 0 n = 0 n=0且 m = 0 m = 0 m=0时 r t o o l = 1 r_{tool } = 1 rtool=1 ,其他情况按不同公式计算。
3. 创新性技术组合:将工具集成奖励与传统奖励函数相乘,构建最终工具集成奖励函数 r ϕ t o o l ( q , y ) = α ∗ r t o o l ∗ r ϕ ( q , y ) r_{\phi}^{tool }(q, y)=\alpha * r_{tool } * r_{\phi}(q, y) rϕtool(q,y)=α∗rtool∗rϕ(q,y) , α \alpha α为超参数。这种设计在保证答案正确时,鼓励模型减少工具使用,避免reward hack问题。
4. 实验验证方式:使用NQ、HotpotQA等数据集进行搜索任务实验,使用ToRL提供的数据集进行代码任务实验。对比基线包括SFT、Base-RL、RAG、IRCoT、Search-R1和ToRL等方法,通过精确匹配(EM)、平均工具调用次数(TC)和新定义的工具生产率(TP)等指标评估模型性能。
实验洞察
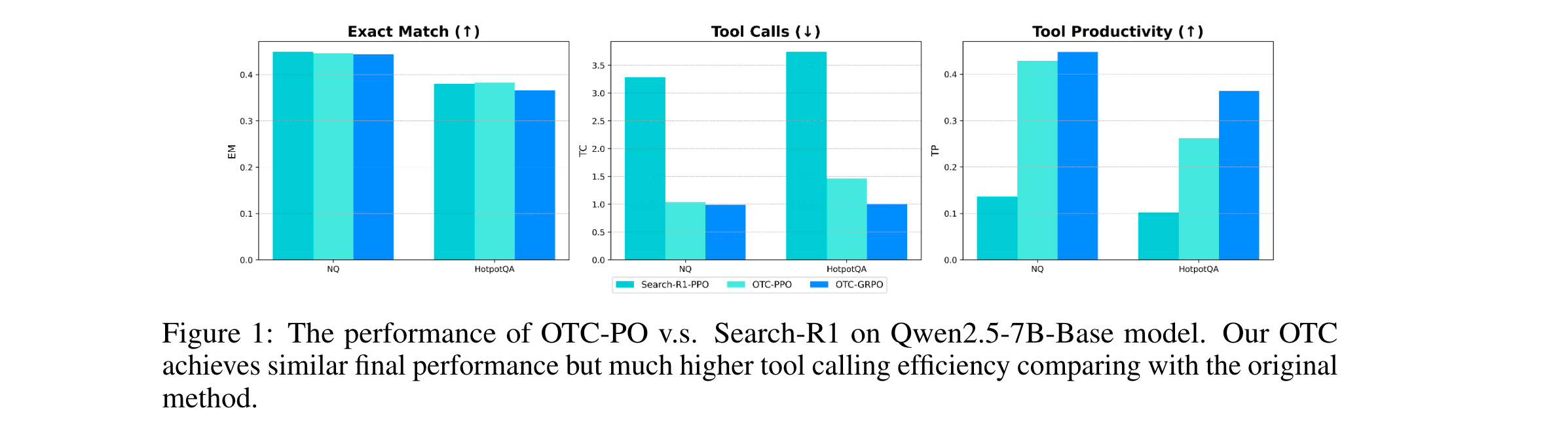
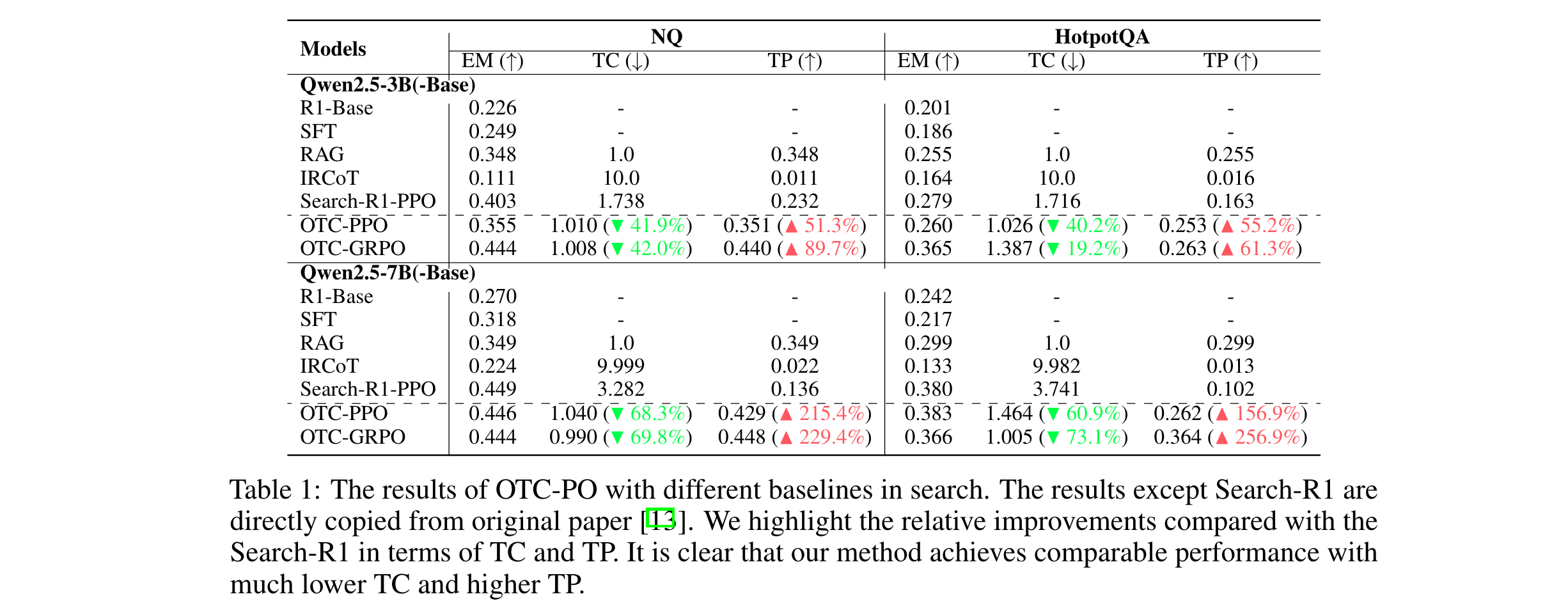
1. 性能优势:在搜索任务中,与Search-R1相比,OTC-PPO和OTC-GRPO显著降低TC并提高TP。如在Qwen2.5-7B-Base模型的NQ数据集上,OTC-GRPO的TC降低69.8%,TP提高229.4%;在HotpotQA数据集上,OTC-GRPO的TC降低73.1%,TP提高256.9%,且在大模型上能保持较高EM分数。
2. 效率突破:训练时,OTC-PO方法使用更少工具调用和更短响应,训练优化更快更高效,减少训练中实时工具交互的时间和成本。推理时,在多数测试用例中,OTC-PO能用更少工具调用得到与基线相同的答案,在约90%的测试用例中展现出效果和效率的平衡。
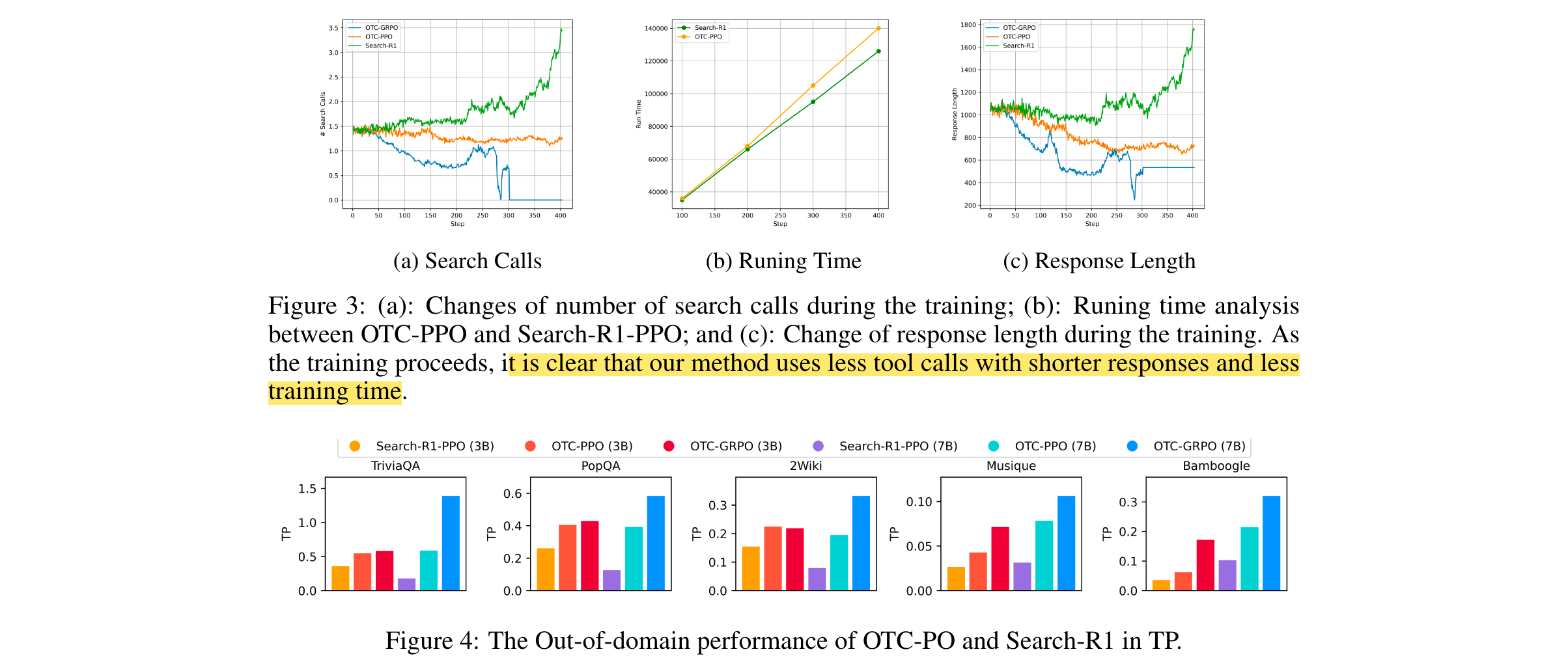
3. 消融研究:通过对比不同模型在不同数据集上的工具使用行为,发现随着模型规模增大,若不加以惩罚,模型倾向于过度依赖外部工具调用。同时,通过分析工具过度使用和使用不足的情况,验证了OTC-PO在控制工具调用数量上的有效性。

END: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁


















 1832
1832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









