







Qwen3技术报告深度解析:双模式架构与多语言能力升级
本文聚焦Qwen3技术报告,解析其创新性的思考与非思考双模式架构,以及在多语言支持、模型效率和性能表现上的突破。通过36万亿token预训练和119种语言覆盖,Qwen3在代码生成、数学推理等任务中展现出超越同类模型的竞争力,为开源大模型发展树立新标杆。
📄 论文标题:Qwen3 Technical Report
🌐 来源:arXiv:2505.09388v1 [cs.CL] 链接:https://arxiv.org/abs/2505.09388v1
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
1. 研究背景与核心目标
随着大语言模型(LLMs)向通用人工智能(AGI)迈进,提升模型的推理效率、多语言能力和计算资源利用率成为关键挑战。Qwen3作为Qwen系列的最新版本,旨在通过架构创新和训练策略优化,实现性能、效率与全球化能力的全面提升,缩小开源模型与专有模型的差距。
2. 模型架构与创新设计
1. 双模式统一框架
Qwen3首次将思考模式(Thinking Mode)与非思考模式(Non-thinking Mode)整合至单一模型:
- 思考模式:针对复杂多步推理任务(如数学证明、代码生成),通过动态生成推理链提升准确性;
- 非思考模式:面向快速响应需求(如对话交互、信息检索),基于上下文直接生成答案,减少延迟。
两者通过聊天模板(如<font style="color:rgba(0, 0, 0, 0.85);">/think</font>和<font style="color:rgba(0, 0, 0, 0.85);">/no_think</font>标签)动态切换,避免传统模型需在专用推理模型(如QwQ-32B)和对话模型(如GPT-4o)间切换的成本。
2. 计算资源优化:思考预算机制
引入思考预算(Thinking Budget)机制,允许用户为思考过程分配token数量(如16K-32K tokens)。通过自适应调整计算资源,模型可在推理深度与响应速度间平衡,例如在数学竞赛任务AIME中,增加预算可使准确率提升10%-15%。
3. 混合专家(MoE)与稠密模型协同
Qwen3包含6个稠密模型(0.6B-32B参数)和2个MoE模型(30B-A3B和235B-A22B):
- MoE模型:旗舰模型Qwen3-235B-A22B采用128个专家、每token激活8个专家的设计,总参数235B但每次推理仅激活22B参数,兼顾性能与效率;
- 稠密模型:如Qwen3-32B在代码生成任务LiveCodeBench v5中得分70.7,超越参数更大的Qwen2.5-72B。
3. 训练策略
1. 超大规模预训练数据
- 数据量:使用36万亿token训练,较Qwen2.5翻倍,覆盖119种语言(含濒危语种),解决29→119种语言支持的跨越式升级;
- 数据生成:通过Qwen2.5-VL从PDF提取文本、Qwen2.5-Math生成数学题、Qwen2.5-Coder合成代码数据,构建跨领域(STEM、代码、多语言)的高质量语料。
2. 三阶段预训练流程
- 通用阶段(S1):30万亿token构建基础语言能力;
- 推理阶段(S2):5万亿token强化STEM和编码推理,学习率衰减加速;
- 长上下文阶段(S3):通过YARN和Dual Chunk Attention技术,将上下文长度从4K扩展至32K tokens,支持长文档理解。
3. 训练后优化:四阶段能力对齐
Qwen3 通过四阶段训练后流程,实现模型能力与人类偏好及下游任务的精准对齐,兼顾推理深度与响应灵活性:
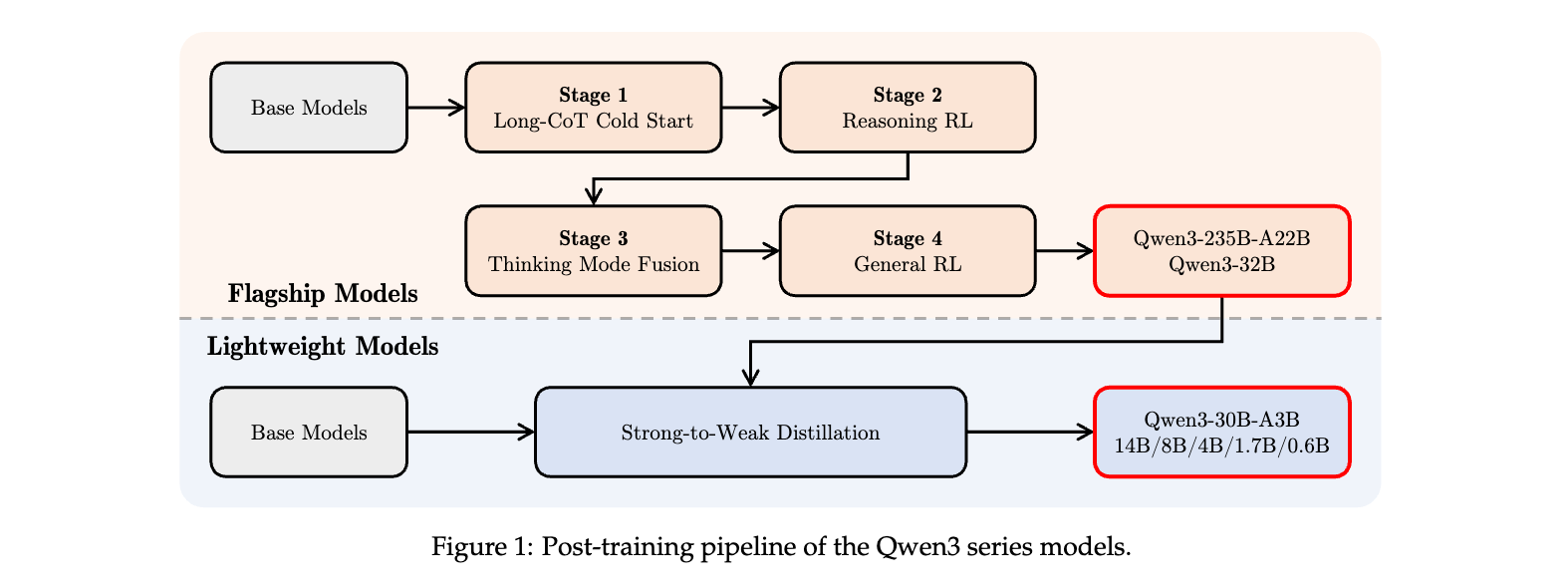
长链式思维冷启动(Long-CoT Cold Start)
- 使用 Qwen2.5-72B-Instruct 筛选复杂问题(如数学证明、逻辑推理),排除无需推理的简单查询,构建包含 STEM、代码等领域的高质量数据集;
- 通过 QwQ-32B 生成多候选推理链,人工筛选去除重复、错误推理路径,保留逻辑连贯的长链式思维(Long-CoT)数据,为模型注入基础推理模式。
推理强化学习(Reasoning RL)
- 采用 GRPO 算法优化模型参数,使用 3,995 个高难度查询 - 验证对训练,覆盖数学、代码等领域;
- 通过控制模型熵值平衡探索与利用,例如在 AIME’24 任务中,经 170 步 RL 训练后得分从 70.1 提升至 85.1,验证了强化学习对复杂推理能力的提升效果。
思考模式融合(Thinking Mode Fusion)
- 将 “思考” 与 “非思考” 数据混合进行监督微调(SFT),设计聊天模板(如
/think和/no_think标签)实现模式切换; - 引入 “思考预算” 动态截断机制,当推理 token 达到用户设定阈值时,自动终止思考并生成答案,例如在 32K 上下文任务中,该机制可使延迟降低 30% 同时保持准确率 > 90%。

通用强化学习(General RL)
- 构建覆盖 20 + 任务的奖励系统,包括指令遵循(IFEval 严格提示准确率 85.0)、工具调用(ToolUse 准确率 86.5)、多语言对齐(Multi-IF 得分 73.0)等;
- 结合规则奖励(如格式检查)、参考答案奖励(如 MATH-500 准确率 98.0)和人类偏好奖励,提升模型在开放场景中的实用性。
4. 性能评估与基准测试
1. 推理与代码任务
- 数学推理:Qwen3-235B-A22B在AIME’24/’25中分别得85.7/81.5分,超越DeepSeek-R1(79.8/77.3)和GPT-4o(74.3/79.2);
- 代码生成:在LiveCodeBench v5中得分70.7,CodeForces评级2056(98.2% percentile),接近人类专家水平。
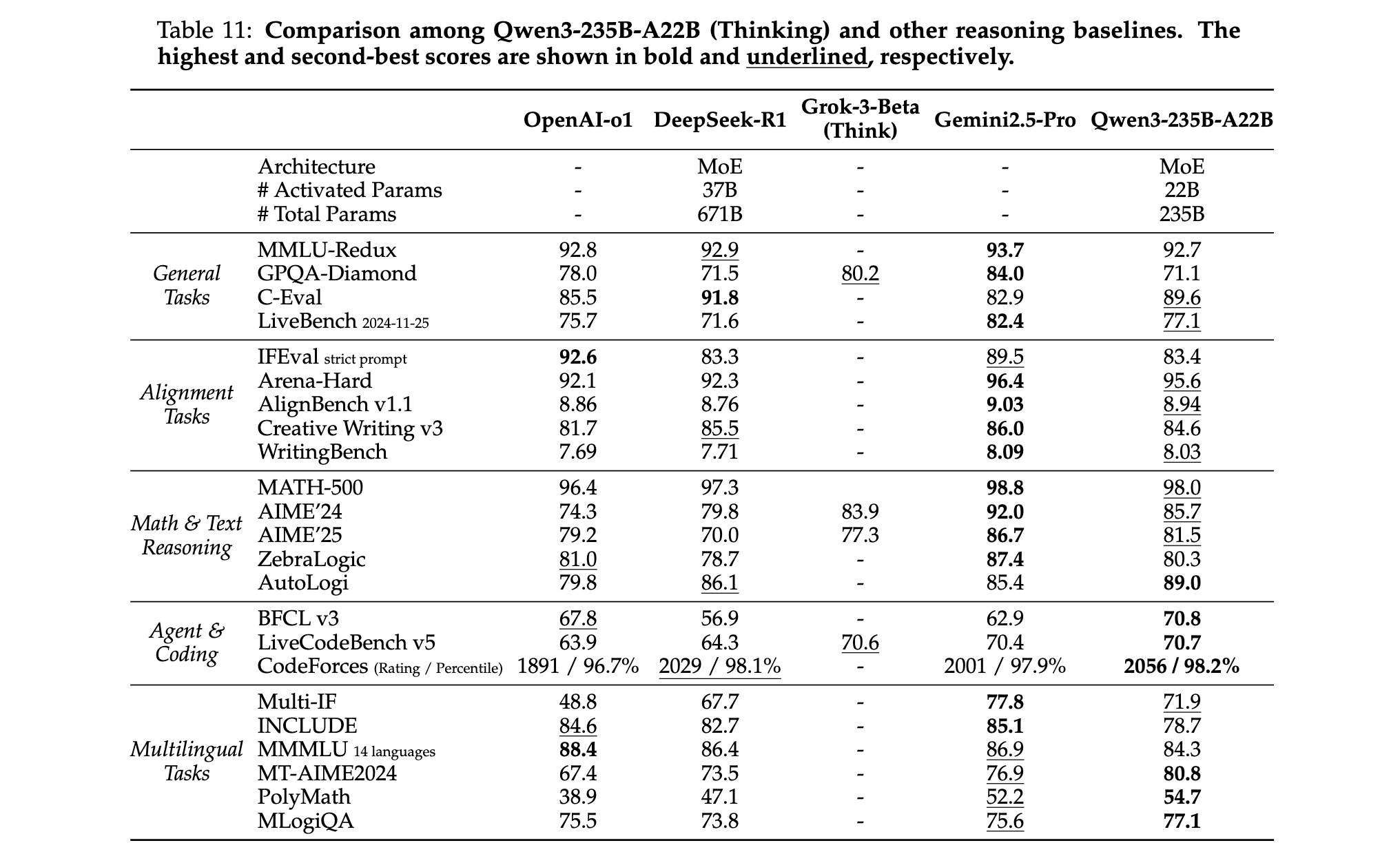
2. 多语言能力
- 覆盖范围:支持119种语言,在MGSM(多语言数学推理)中得分83.53,MMMLU(多语言常识)得分86.7,超越Llama-4和DeepSeek-V3;
- 小语种表现:在Belebele基准的印尼语、越南语等语言中,Qwen3-32B较Qwen2.5-32B提升10%-15%。

3. 模型效率对比
- 参数效率:Qwen3 MoE模型以1/5激活参数实现与稠密模型相当性能,如Qwen3-30B-A3B(3B激活参数)在MMLU得分81.38,接近Qwen3-14B(14B参数)的81.05;
- 蒸馏优化:通过“强到弱蒸馏”(Strong-to-Weak Distillation),小模型(如0.6B)性能较Qwen2.5提升20%,训练成本降低90%。
5. 讨论:核心技术有效性与实证分析
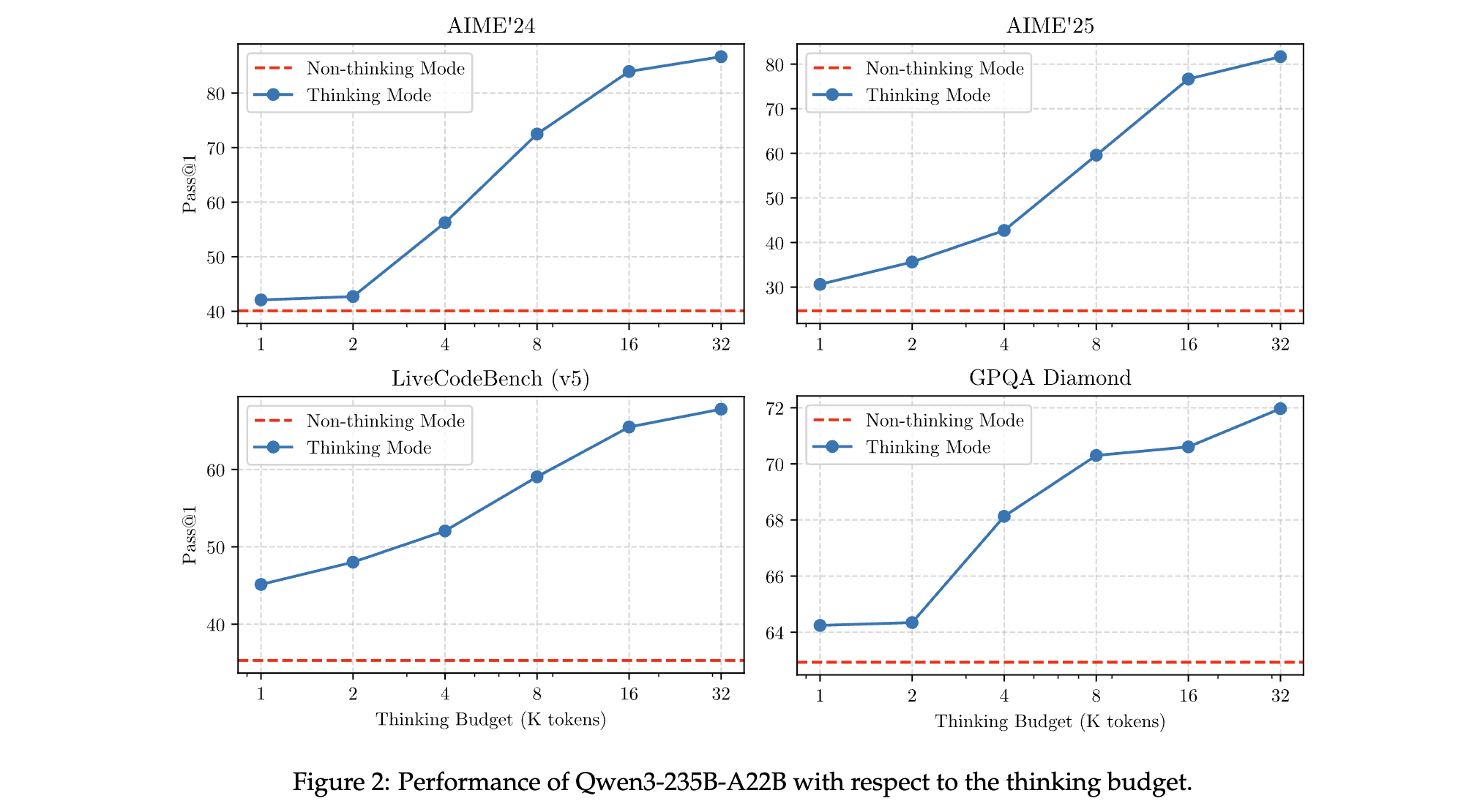
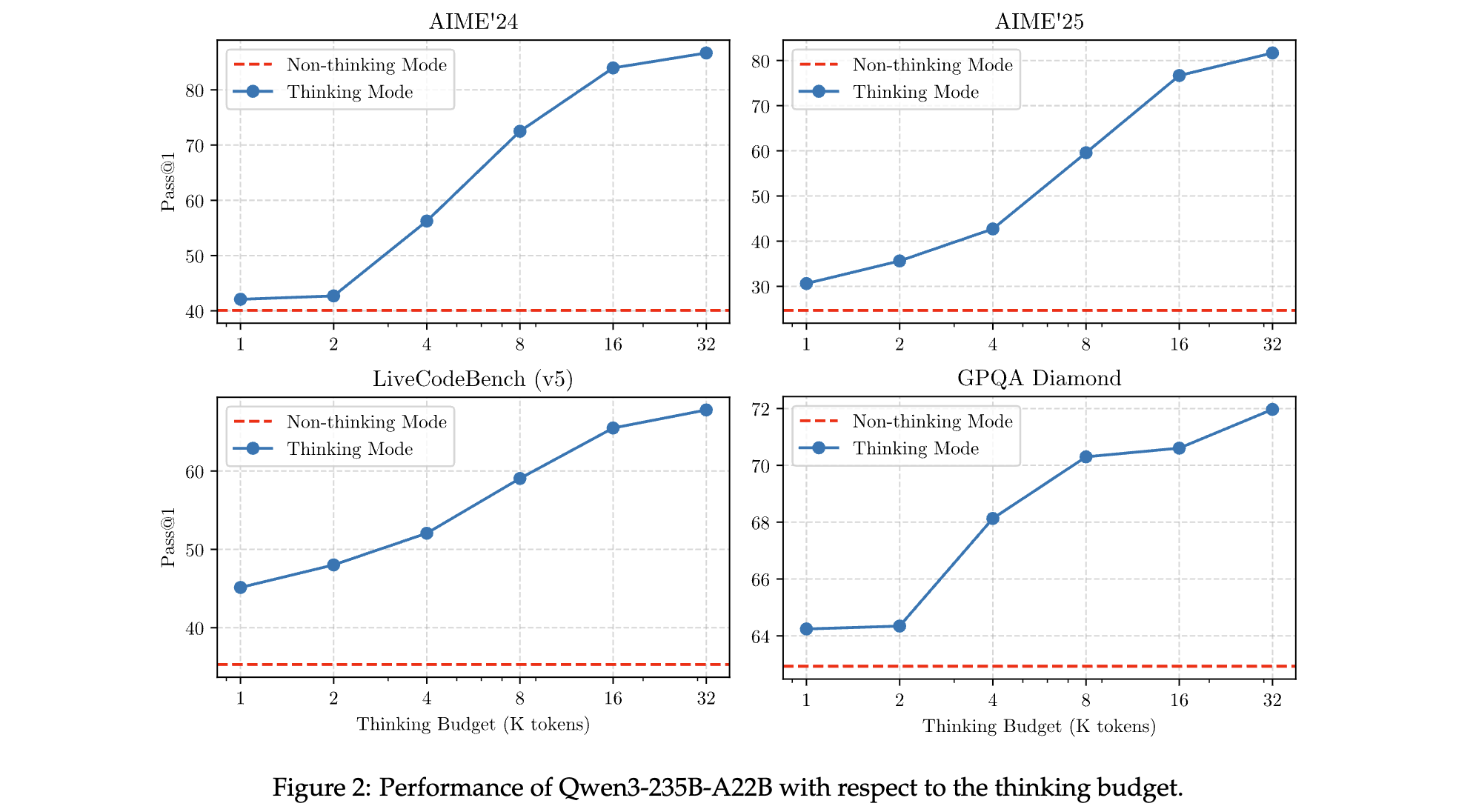
1. 思考预算机制的动态性能验证
为验证思考预算对模型智能水平的提升作用,研究团队在数学(AIME)、编码(LiveCodeBench)、STEM(GPQA-Diamond)等 4 个基准测试中调整思考预算(token 数):
- 性能 - 预算正相关:Qwen3-235B-A22B 在 AIME’24 任务中,预算从 16K tokens 增至 32K 时,准确率从 81.9% 提升至 85.7%;在 LiveCodeBench v5 中,复杂代码生成成功率提升 12%。
- 延迟权衡:预算增加伴随推理延迟上升(如 32K 预算下延迟增加 25%),但模型支持通过
stop-thinking指令强制终止思考,在实时场景中可平衡效率与准确性。 - 未来潜力:若突破 32K token 限制(如扩展至 64K),模型性能有望进一步提升,相关探索列为后续研究方向。
2. 在线蒸馏的效率革命
对比在线蒸馏(On-policy Distillation)与传统强化学习(RL)的性能及成本,以 Qwen3-8B 模型为例
- 性能优势:
- 蒸馏后 AIME’24 得分从 55.0%(离线蒸馏)提升至 74.4%,超越 RL 的 67.6%;
- Pass@64(多路径探索准确率)从 90.0% 提升至 93.3%,显示蒸馏能增强模型推理多样性。
- 成本锐减:蒸馏仅需 1,800 GPU 小时,为 RL(17,920 小时)的 1/10,大幅降低训练开销。
- 机制解析:通过教师模型(如 Qwen3-235B)的输出 logits 指导学习,学生模型可高效继承复杂推理能力,避免 RL 需从头探索的低效性。

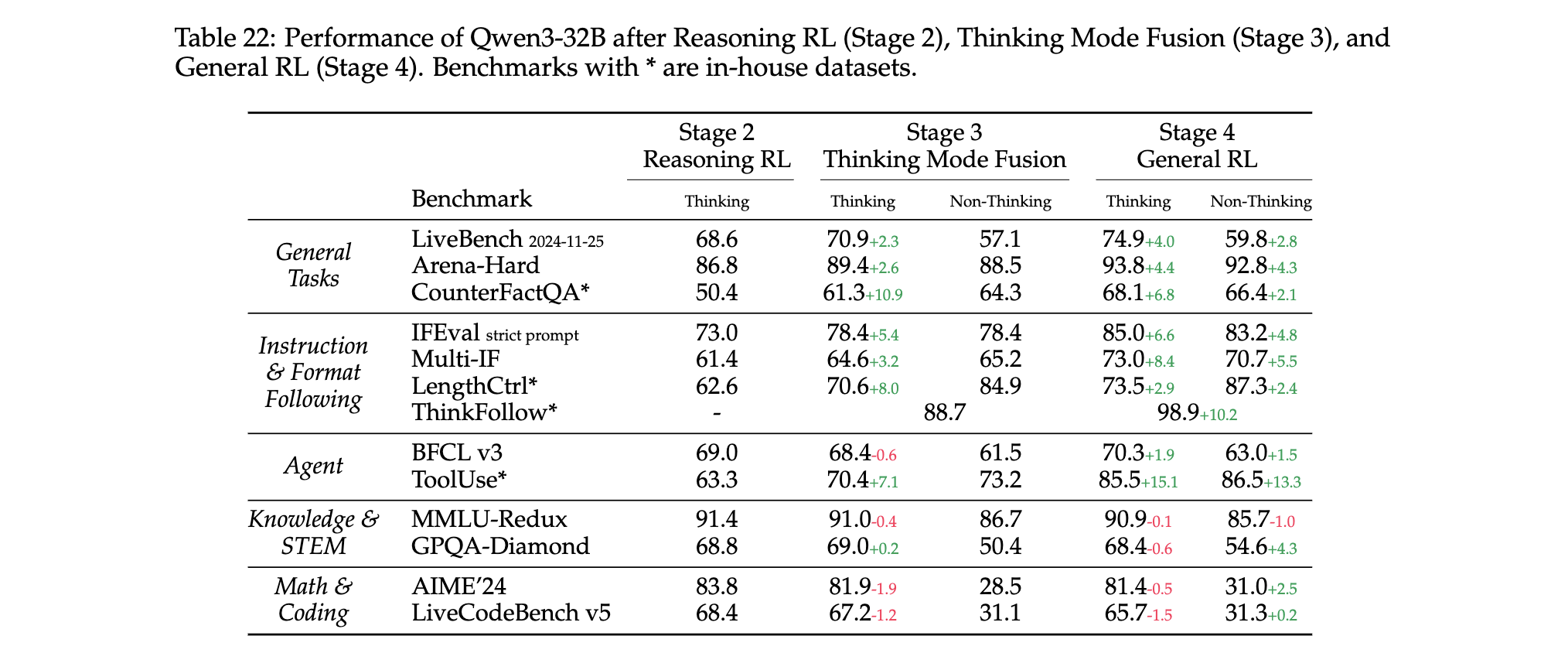
3. 思考模式融合的多阶段效果
通过 Qwen3-32B 模型的分阶段评估,揭示思考模式融合(Stage 3)与通用强化学习(Stage 4)的影响:
- 模式切换能力:
- Stage 3 后 ThinkFollow 得分 88.7,模型初步具备模式切换能力,但存在偶发错误;
- Stage 4 后得分提升至 98.9,实现多轮对话中
/think标签的精准响应。
- 通用能力增强:
- 指令遵循(IFEval 严格提示准确率)从 73.0% 提升至 85.0%,多语言任务(Multi-IF)得分提升 8.4%;
- 工具调用(ToolUse)准确率从 63.3% 提升至 86.5%,支持复杂流程的稳定执行。
- 专业任务权衡:
- 数学推理(AIME’24)在 Stage 3 后得分下降 1.9%,推测因通用任务训练稀释了专业能力;
- 团队选择接受这一 trade-off,以换取模型在开放场景中的综合适用性。
总结与未来方向
Qwen3通过双模式架构、MoE高效推理和大规模多语言训练,实现了开源模型在复杂任务和全球化场景中的突破。未来研究将聚焦于:
- 更高质量数据与更长上下文(如128K tokens);
- 强化代理任务(Agent Tasks)的环境交互能力;
- 模型压缩与边缘设备部署优化。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









