







SLOT:测试时样本专属语言模型优化,让大模型推理更精准!
大语言模型(LLM)在复杂指令处理上常显不足,本文提出SLOT方法,通过轻量级测试时优化,让模型更贴合单个提示。实验显示,SLOT在多个基准测试中显著提升模型性能,为大模型推理优化提供新思路。
论文标题
SLOT: Sample-specific Language Model Optimization at Test-time
来源
arXiv:2505.12392v2 [cs.CL] + https://arxiv.org/abs/2505.12392
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
大型语言模型(LLMs)在文本生成、理解等任务中展现出强大通用能力,但面对复杂指令时往往表现不佳,尤其当指令在训练数据中缺乏充分覆盖时,模型易出现格式错误或逻辑偏差。例如,Qwen2.5在处理含严格格式要求的推理问题时,常因训练数据中未涉及类似规范而生成错误答案。为提升模型对个体提示的响应精度,测试时缩放(Test-Time Scaling)策略通过分配额外计算资源优化推理,但现有测试时自适应(TTA)方法存在计算开销大、监督信号设计困难等挑战,难以在保持效率的同时实现模型对复杂指令的有效适配。
研究问题
-
现有LLM在面对复杂指令时,因训练数据中相关样本不足,常无法正确理解和遵循指令要求,如格式规范等。
-
测试时自适应(TTA)方法存在计算开销大的问题,在大规模模型上进行实例级更新成本高昂。
-
为复杂LLM任务设计有效的监督信号是一大挑战,影响模型在测试时的优化效果。
主要贡献
1. 提出SLOT框架:这是一种新颖的测试时推理方法,通过在测试时进行少量优化步骤,更新轻量级样本专属参数向量,使模型能更精准地响应单个提示,与现有方法相比,无需对整个模型进行大量更新,参数效率高。
2. 设计轻量级参数更新机制:在输出头前的最终隐藏层添加样本专属参数向量 δ δ δ,通过缓存最后一层特征,避免了完整模型的前向和反向传播,大幅降低计算开销,实现高效自适应。
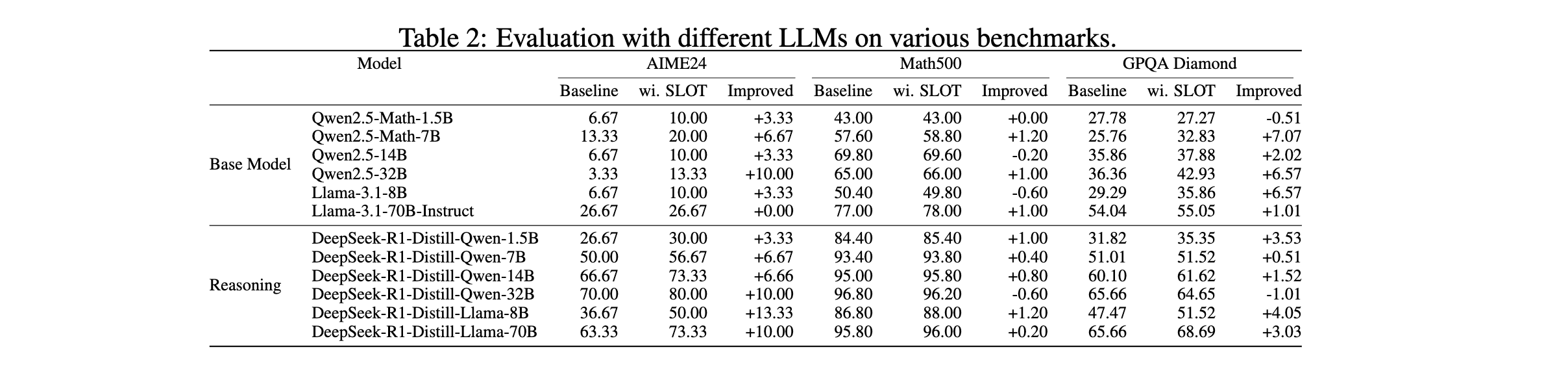
3. 广泛实验验证有效性:在多个基准和LLM上的实验表明,SLOT显著提升模型性能。例如,Qwen2.5-7B在GSM8K上准确率提升8.6%,DeepSeek-R1-Distill-Llama-70B在GPQA Diamond上取得70B级模型的SOTA准确率。
方法论精要
1. 核心算法/框架:SLOT框架包含提示阶段(Prompt Stage)和生成阶段(Generation Stage)。在提示阶段,初始化并优化样本专属参数 δ δ δ;生成阶段,重用优化后的 δ δ δ生成响应。
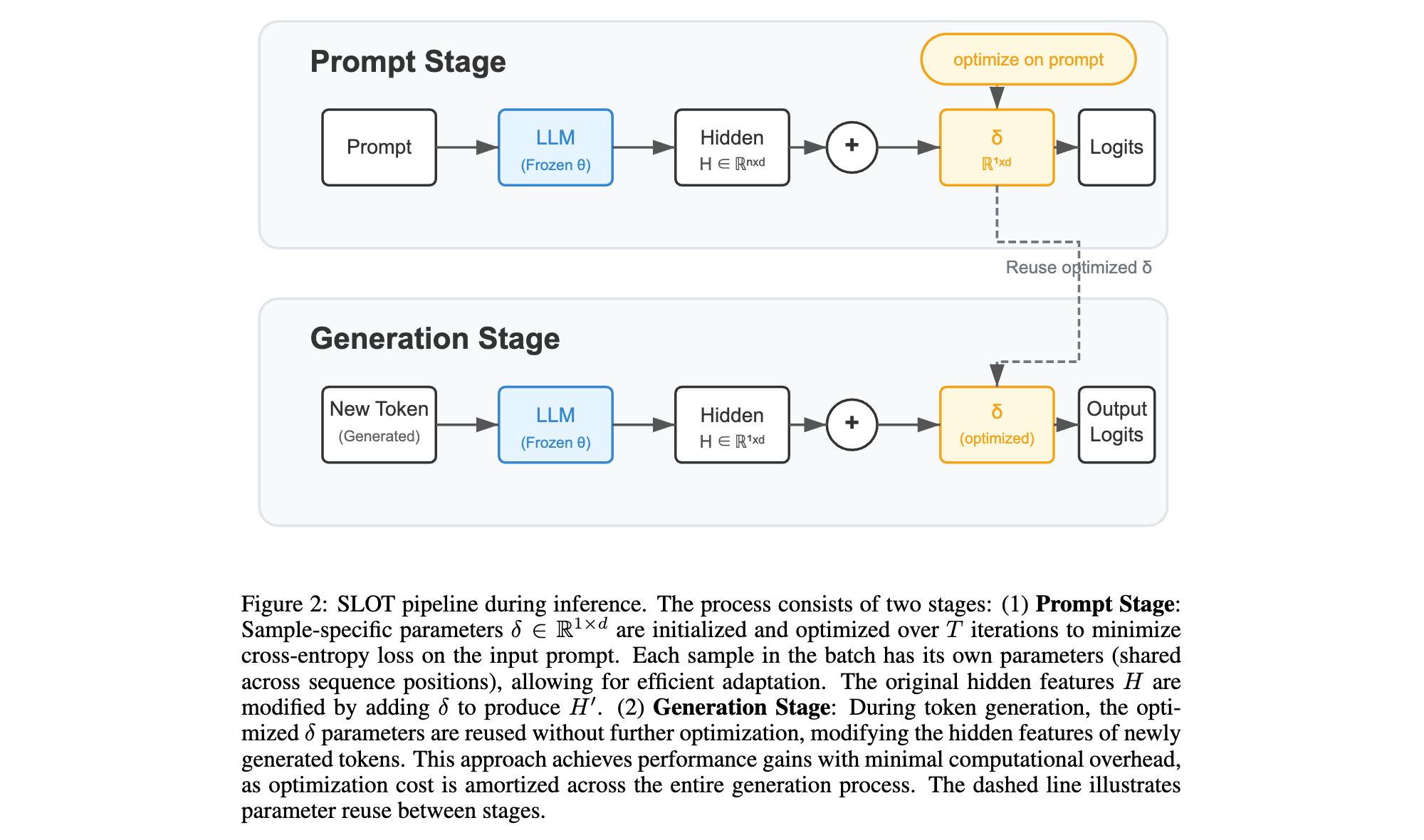
2. 关键参数设计原理: δ δ δ是一个轻量级参数向量,维度为 R 1 × d \mathbb{R}^{1×d} R1×d,通过在提示阶段最小化输入提示的交叉熵损失来优化。采用零初始化,确保初始时不影响基础模型,优化步骤数T通常设为3,学习率 η η η为0.01,使用AdamW优化器。
3. 创新性技术组合:将提示本身视为监督训练样本,仅在输入提示上进行优化,使模型更好地与给定指令对齐;通过在最终隐藏层添加 δ δ δ来调制输出 logits,形成Logit Modulation Vector(LMV),增强推理相关令牌的概率,抑制无关令牌。

4. 实验验证方式:使用多种LLM,包括Qwen系列、Llama系列、DeepSeek系列等,在多个基准上进行实验,如GSM8K、GPQA Diamond、C-Eval、AIME24等。对比基线为原始模型,不进行测试时自适应,通过答案准确率评估性能。
实验洞察
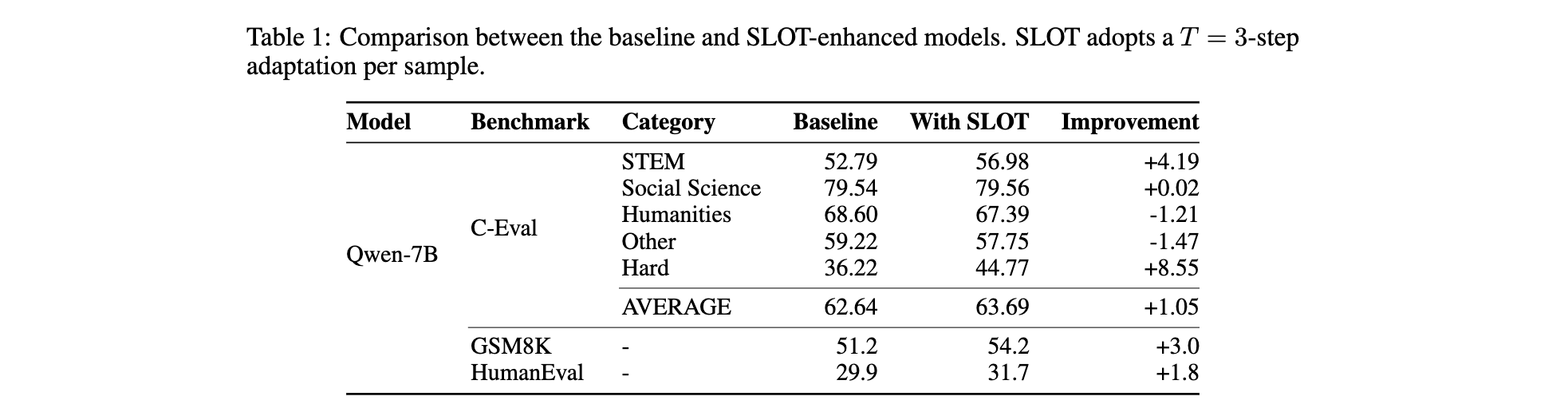
1. 性能优势:Qwen2.5-7B在GSM8K上准确率从57.54%提升至66.19%,提升8.6%;DeepSeek-R1-Distill-Llama-70B在GPQA Diamond上准确率达68.69%,为70B级开源模型新纪录;Qwen-7B在C-Eval的Hard子集上提升8.55%。
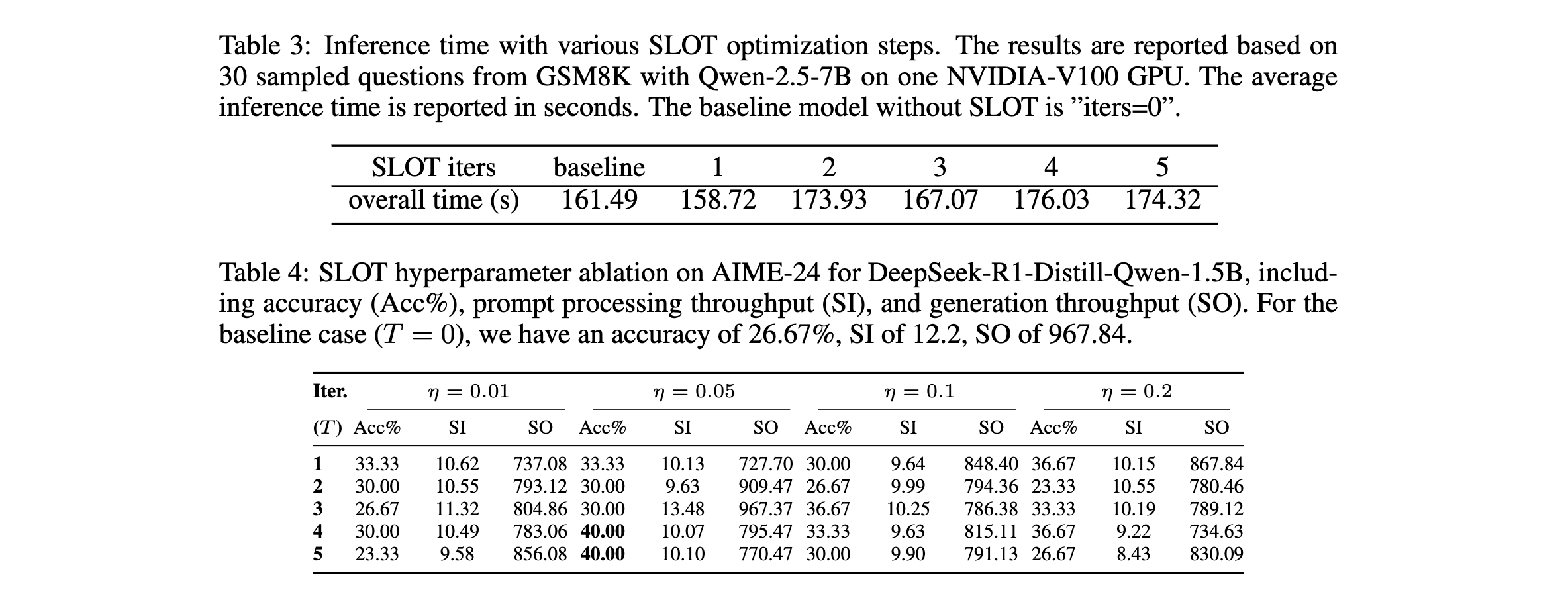
2. 效率突破:SLOT的计算开销可忽略,与基线相比,5步优化仅增加7.9%的推理时间。生成阶段,由于仅添加轻量级向量,生成速度稳定,不受优化步骤数影响。
3. 消融研究:对优化迭代次数T和学习率η进行消融实验,发现SLOT对超参数相对不敏感。如DeepSeek-R1-Distill-Qwen-1.5B在AIME-24上,T=4、η=0.05或T=5、η=0.05时准确率最高达40.00%,比基线提升13.33%。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









