




LitePPO:揭秘RL优化LLM数学推理的"技巧陷阱"与极简解决方案
本文系统分析了强化学习(RL)优化大语言模型(LLM)数学推理任务中的技术碎片化问题,通过统一实验框架验证了主流RL技巧的适用边界,并提出仅需两种核心技巧组合的LitePPO方案。研究发现优势归一化与token级损失聚合的极简组合,在6个数学基准测试中平均准确率超越GRPO/DAPO等复杂算法,为RL4LLM领域提供了清晰的工程指南。
论文标题:LitePPO: Tricks or Traps? A Deep Dive into RL for LLM Reasoning
来源:arXiv:2508.08221 [cs.CL],链接:https://arxiv.org/abs/2508.08221
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
强化学习(RL)已被 DeepSeek-R1、OpenAI o1 等模型验证可显著提升 LLM 数学推理能力。2025 年,RL4LLM 研究呈井喷态势,但社区陷入“Trick 通货膨胀”:
- 同一问题出现矛盾的改进建议(如 GRPO 用 group-norm,REINFORCE++ 却坚持 batch-norm)。
- 实验配置、数据分布、初始化差异导致结论无法复现。
- 新技巧层出不穷,实践者难以判断“何时用、用多少”。
研究问题
- 技术碎片化:同类技术存在对立实现(如group-level vs batch-level归一化),缺乏统一评估框架验证其本质差异
- 场景敏感性:现有技巧对模型规模(4B/8B)、对齐状态(Base/Instruct)、数据难度等变量表现不稳定
- 过度工程化:主流算法(如DAPO含6种技巧)可能引入冗余组件,掩盖核心有效要素
主要贡献
- 首次大规模隔离式实验:基于开源 ROLL 框架,覆盖 4/8B Base & Instruct、三档难度数据、两大奖励尺度,完整复现并剖析 8 类主流技巧。
- 提出 LitePPO:仅组合 “Group-level mean + Batch-level std Advantage Norm” 与 “Token-level Loss” 两项技巧,在 6 个数学基准上平均超越 GRPO/DAPO,且训练曲线更稳定。
- 给出可操作的技巧指南:
- Norm:Group-mean/Batch-std 最稳健;奖励集中时去掉 std。
- Clip-Higher:只对已对齐模型有效,小模型存在 0.2→0.32 的“缩放律”。
- Token-level Loss:对 Base 模型必用,对 Instruct 模型反而略差。
- Overlong Filtering:短/中长度任务增益显著,长尾推理作用有限。
思维导图
统一实验框架
- 基础设施:基于开源ROLL框架,固定PPO损失+REINFORCE优势估计,batch size=1024(128 prompts × 8 responses)
- 模型选择:Qwen3-4B/8B的Base/Instruct版本,覆盖不同规模与对齐状态
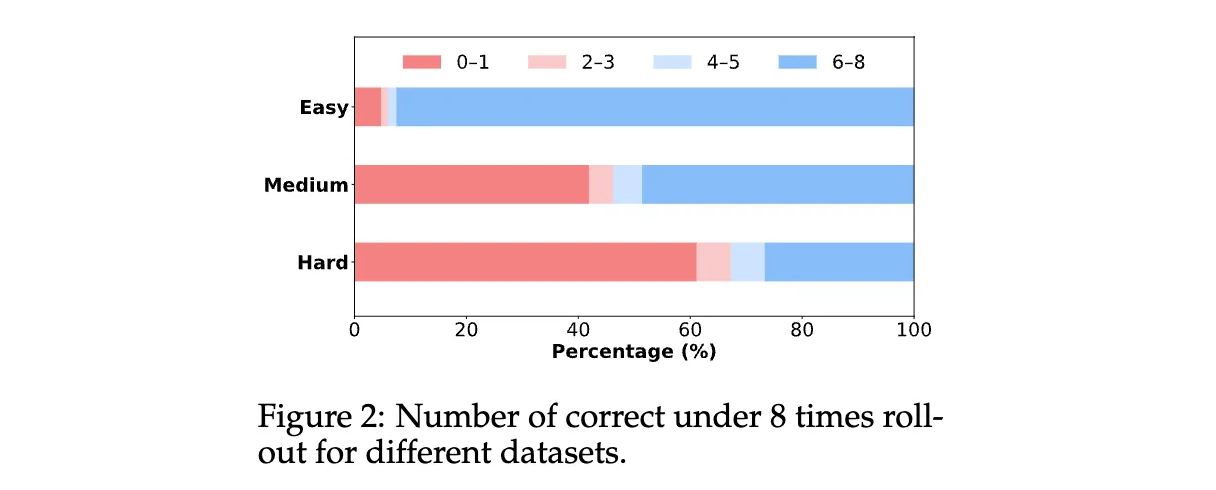
- 数据分级:从SimpleRL-Zoo-Data/DeepMath采样Easy(5k)、Medium(5k)、Hard(5k)三级难度数据,过滤二元答案噪声
- 奖励:默认 {0,1};大尺度 {−1,1}。
- 基准:MATH-500、OlympiadBench、MinervaMath、AIME24/25、AMC23。
关键分析
围绕了 4 个最常用但也最混乱的 RL 技巧——Normalization、Clipping、Loss Aggregation、Overlong Filtering——进行系统消融实验与机制剖析,最终抽象出可直接落地的 Takeaway 1~8。所有实验都在统一框架(ROLL)内完成,确保“孤立变量”的效果可被精确计量。
4.1 Advantage Normalization
| 比较维度 | Group-level | Batch-level | 混合 Robust |
|---|---|---|---|
| 奖励尺度 {0,1} | ✅ 稳定且高 | ⚠️ 易崩溃 | ✅ 更平滑 |
| 奖励尺度 {−1,1} | ✅ 依旧好 | ✅ 反超 | ✅ 最优 |
| 数据难度 Easy | ✅ 高,std 可去掉 | ❌ 易梯度爆炸 | ✅ 去 std 更稳 |
| 数据难度 Hard | ✅ 与 Batch 接近 | ✅ 与 Group 接近 | ✅ 略优 |
Takeaway 1
Group-level normalization 在任意奖励尺度下都稳健;Batch-level 只在大尺度奖励场景才能提供稳定增益。
Takeaway 2
当奖励分布极度集中(Easy 数据)时,去掉标准差项可避免放大异常梯度,提升训练稳定性。
Takeaway 3
计算均值用 group-level,标准差用 batch-level 的 Robust Norm 能进一步平滑优势信号,适用于稀疏奖励环境。
4.2 Clip-Higher
Clip-Higher 通过将 PPO 的 clip(r_t, 1-ε_low, 1+ε_high) 中 ε_high 从 0.2 提升到 0.28,甚至 0.32,来缓解熵塌陷(entropy collapse)。
| 模型类型 | ε_high=0.2 | ε_high=0.28 | ε_high=0.32 |
|---|---|---|---|
| 4B-Base | 基本无感 | 略下降 | 略下降 |
| 8B-Base | 基本无感 | 略下降 | 略下降 |
| 4B-Instruct | 标准 | +3~4% | +6% |
| 8B-Instruct | 标准 | +3% | 持平 |
Takeaway 4
只对已对齐、具备基础推理能力的模型提高 ε_high 才有效,可激发高质量探索;Base 模型本身策略熵较高,提升后收益有限甚至有害。
Takeaway 5(语言视角)
传统 clip 易把 “therefore / if / but” 等连接词的概率比剪断,限制创新推理;Clip-Higher 放宽后,被剪断的 token 从高阶语义词转为高频功能词,保留推理多样性。
Takeaway 6
小模型存在 ε_high 与性能的近似线性“缩放律”;8B 及以上模型在 0.28 左右即饱和,继续放大无收益。
4.3 Loss Aggregation Granularity
比较 Sequence-level(GRPO 默认)和 Token-level(DAPO 默认)。
| 设置 | 4B-Base | 8B-Base | 4B-Instruct | 8B-Instruct |
|---|---|---|---|---|
| Sequence-level | baseline | baseline | 最优 | 最优 |
| Token-level | +2~6% | +3~5% | 持平或略降 | 持平或略降 |
Takeaway 7
Token-level 聚合对 Base 模型显著利好,因其消除长度偏差;Instruct 模型已具备稳定结构,Sequence-level 反而保持对齐质量。
4.4 Overlong Filtering
设定最大生成长度 8k / 16k / 20k,比较“过滤/不过滤”超长样本。
| 最大长度 | 过滤效果 | 4B-Base 提升 | 8B-Base 提升 | 主要现象 |
|---|---|---|---|---|
| 8k | 显著 | +3~5% | +2~4% | 截断噪声样本,训练更干净 |
| 16k | 轻微 | +1% | +1% | 中等长度任务溢出减少 |
| 20k | 无效 | 0 | 0 | 过滤的主要为“重复-无法终止”样本,对真正长推理无帮助 |
Takeaway 8
Overlong filtering 在 中短长度推理 任务可提升准确率与清晰度;在 长尾高难度 任务中收益有限,甚至可能抑制必要的长链推理。
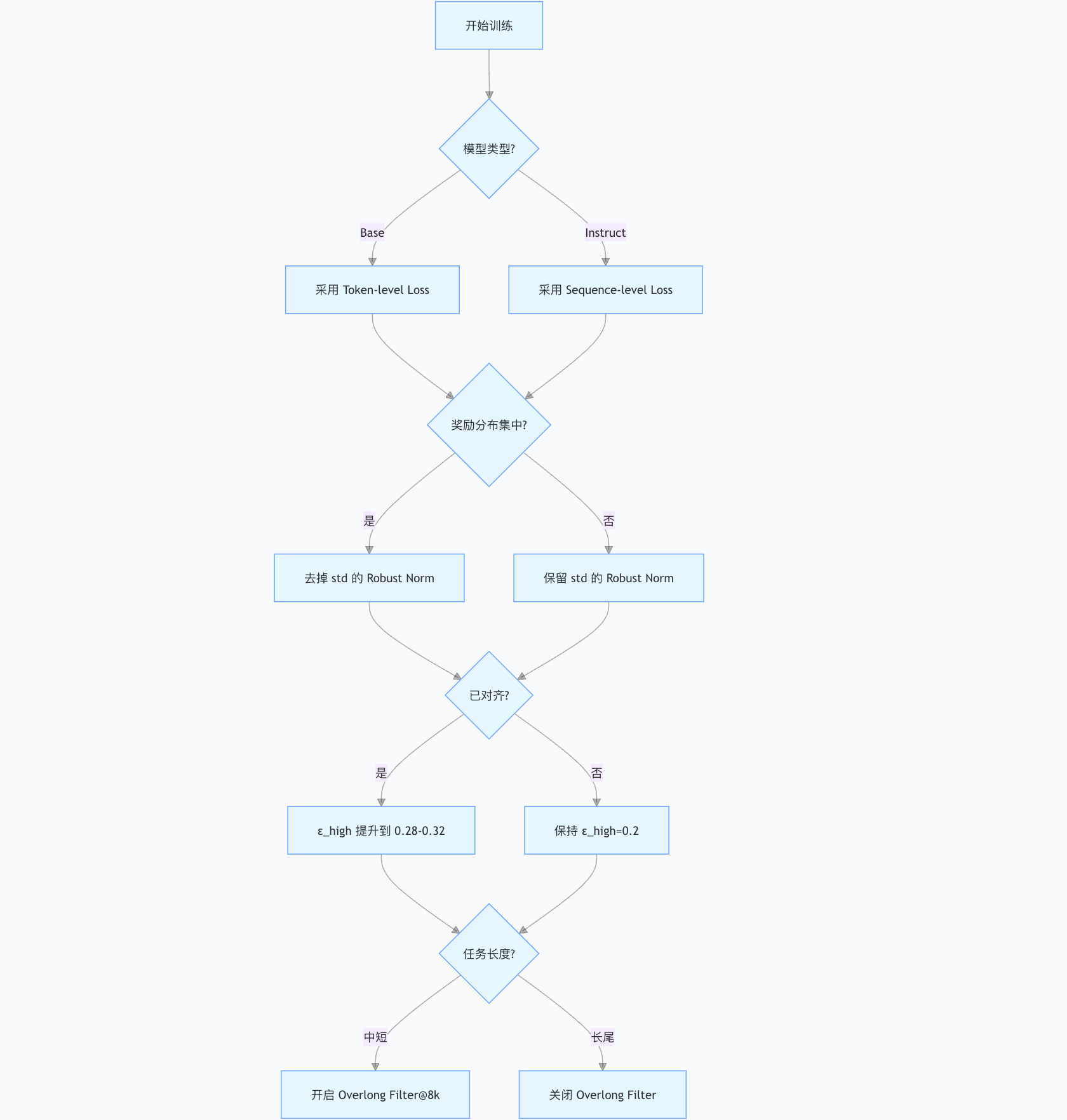
小结:把 Takeaways 串成决策树
LitePPO
实现
- 优势计算:组内均值+批标准差归一化,公式:Aklite=rk−meangroupstdbatchA_k^{lite}=\frac{r_k-mean_{group}}{std_{batch}}Aklite=stdbatchrk−meangroup
- 损失聚合:token级加权,确保长序列中关键推理步骤获得足够梯度
- 去冗余设计:移除overlong filtering等非必要组件,保留PPO原始目标函数
验证
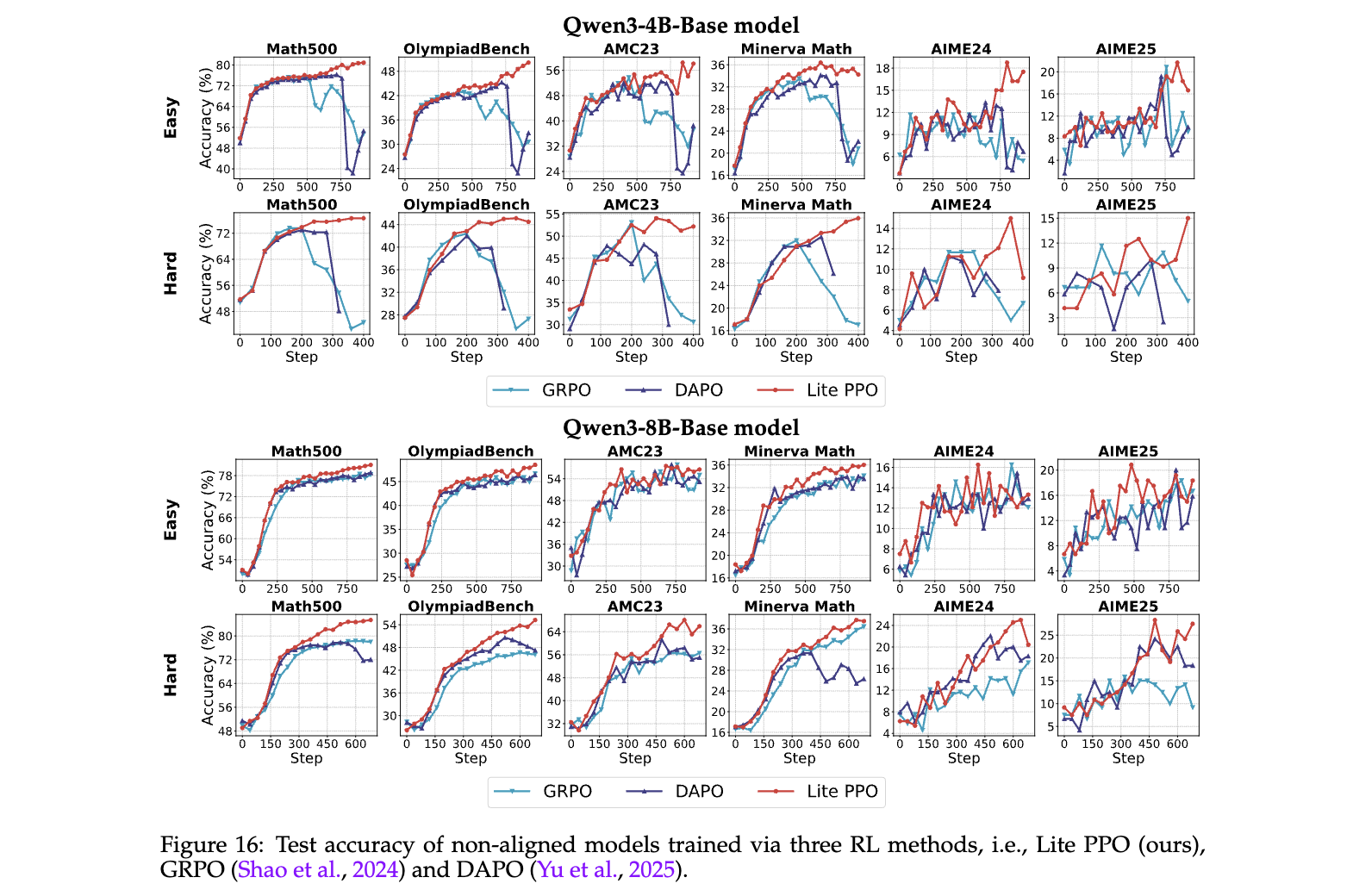
- 稳定性:在4B-Base模型上训练曲线平滑,无GRPO/DAPO的崩溃现象(图16顶部)
- 长尾性能:8B-Base在Hard数据上准确率超DAPO 2.4%,因保留复杂推理能力(图16底部)
- 计算效率:仅需PPO原始计算量的115%,而DAPO达210%
实用指南
| 场景 | 推荐技巧 | 典型增益 |
|---|---|---|
| 小规模Base模型(4B/8B) | LitePPO(组级均值+批量标准差归一化 + Token级损失) | +7.1% |
| 大规模Instruct模型(8B+) | 序列级损失 + Clip-Higher(上限0.28) | +2.3% |
| 短/中等长度推理任务 | Overlong Filtering(阈值8k) | +1.5% |
| 长尾复杂推理任务 | 禁用Overlong Filtering | +1.8% |
| 稀疏奖励场景 | 组级均值归一化(移除标准差) | +3.2% |
| 密集奖励场景 | 批量级归一化(含标准差) | +4.0% |
| 基础模型低熵探索 | 禁用Clip-Higher(保持默认0.2) | 稳定性↑ |
| 对齐模型高熵探索 | Clip-Higher(上限0.32,4B模型适用) | +2.5% |
说明:
- LitePPO 适用于未对齐的Base模型,通过混合归一化和Token级损失提升稳定性与性能。
- Clip-Higher 参数需根据模型规模调整:8B模型推荐0.28,4B模型可尝试0.32。
- Overlong Filtering 在短任务中过滤无效样本,但对长尾任务可能抑制有效推理链。
- 奖励稀疏时(如二元奖励),移除标准差可避免梯度爆炸;密集奖励时保留标准差以增强归一化效果。



















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









