







” 性能调优的王道,就是增加和分配更多的资源,如果说你的spark作业,能够分配的资源达到了你的能力范围的顶端之后,无法再分配更多的资源了,那么才是考虑去做后面的其他性能调优的点“ — 中华石杉
场景
用户session分析模块,代码已撸完,且在本地测试通过,接下来要干嘛呢?对,性能调优。
- 性能调优的必要性
传统J2EE项目重在架构与组建的可扩展性(当然,高并发网站除外),而大数据项目性能调优很关键。一个可正常运行的spark查询作业,未调优前可能要运行 18个小时,调优后可能只需要2个小时 - 写到这里,Snail感觉棒棒滴:搞scala、搞spark能真正体现一个程序员的价值. - 怎么进行性能调优
snail在[0.0.0]中引入了三级调优这个概念(哈哈,三级调优)。本文详谈第一级调优中的 最大化资源配置 . 本文中的资源是指executor数量(一般是一个worker上,一个executor,至于在一个worker上分配多个executor,snail只知道这是可行的,但是应用场景目前还不知道)、为每个executor分配的core(就是计算单元,又称做逻辑CPU)与memeory 。在进入主题前,snail打算先在本地跑跑spark内置的交互式作业spark-shell,并写一个降序排列的word count小样来回顾一下spark作业整体运行流程,以期温故而知新:
spark运行环境: 2核 4G Ubuntu 14.04 LTS
1、spark-shell 代码与执行结果
scala> val log = sc.parallelize(List("we are the one are come come one are come ont come on are"))
log: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at <console>:27
scala> val flag = log.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_+_).map(pair =>(pair._2,pair._1)).sortByKey(false,1).cache
flag: org.apache.spark.rdd.RDD[(Int, String)] = ShuffledRDD[5] at sortByKey at <console>:29
scala> flag.collect.foreach(println)
16/07/01 07:26:40 WARN SizeEstimator: Failed to check whether UseCompressedOops is set; assuming yes
(4,are)
(4,come)
(2,one)
(1,we)
(1,on)
(1,ont)
(1,the)
scala> 2、web UI 监控结果

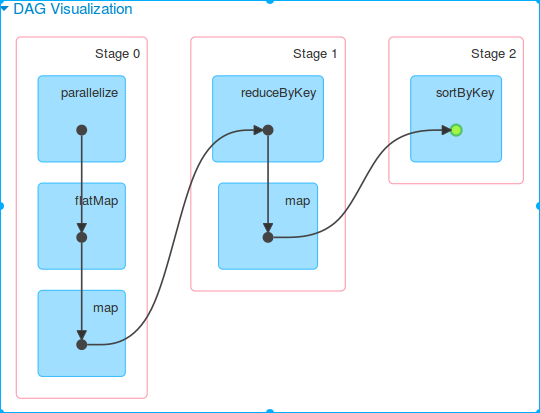
作业被2个shuffle操作,划分成了3个stage
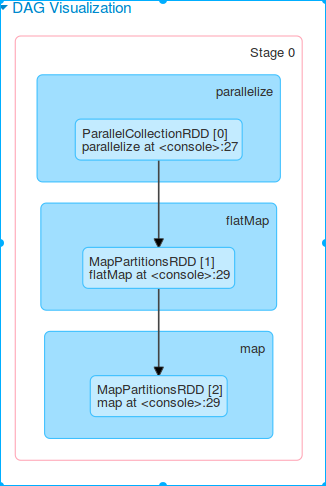

stage0中共包含2个task,在唯一的一个2core 的executor上并行运行完成
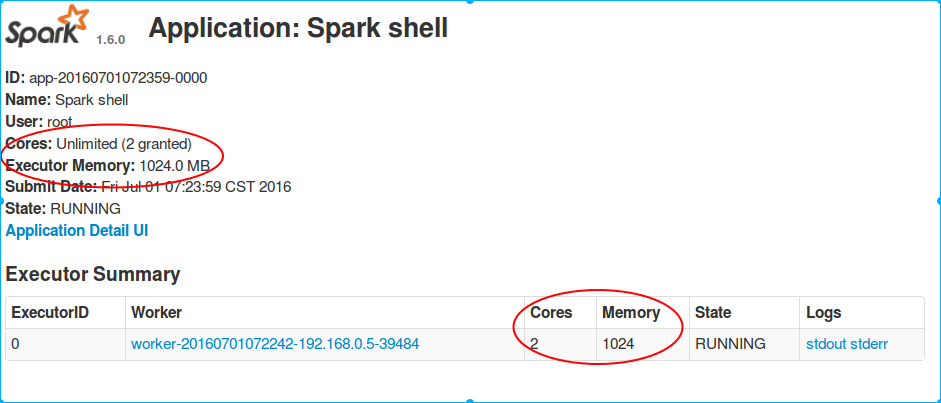
分配的资源为:一个executor 共2core 1024M内存。
分析
调节最优的资源配置涉及到三个话题:分配哪些资源、在哪里分配这些资源、分配多少资源以及为什么多分配了这些资源以后性能会得到提升?
分配哪些资源
executor、cpu per executor、memory per executor以及driver memory在哪里分配这些资源
在生产环境中,提交spark作业时,用的是spark-submit shell脚本。在这里面通过调整对应的参数实现资源分配:
/usr/local/spark/bin/spark-submit \
--class cn.spark.sparktest.core.WordCountCluster \
--num-executors 3 \ 配置executor的数量
--driver-memory 100m \ 配置driver的内存(影响不大)
--executor-memory 100m \ 配置每个executor的内存大小
--executor-cores 3 \ 配置每个executor的cpu core数量
/usr/local/SparkTest-0.0.1-SNAPSHOT-jar-with-dependencies.jar \分配多少资源
一句话,有可用资源就分配多少,具体:
第一种,Spark Standalone部署模式。公司集群上,搭建了一套Spark集群,你心里应该清楚每台机器还能够给你使用的,大概有多少内存,多少cpu core;那么,设置的时候,就根据这个实际的情况,去调节每个spark作业的资源分配。比如说你的每台机器能够给你使用4G内存,2个cpu core;共20台机器;那么可供你分配的资源是:executor = 20;平均每个executor 分配:4G内存,2个cpu core。
第二种,Yarn部署模式。查看你的spark作业,要提交到的资源队列,大概有多少资源?500G内存,100个cpu core;那么你可以这样分配:executor=50;平均每个executor分配:10G内存,2个cpu core。为什么多分配了这些资源以后性能会得到提升
并行执行能力 = 同时运行的tasks = executors * (为每个executor分配的cores)
一、增加executors
增加executor,就意味着可并行执行的task数量增多了。原来是 2个executor;2 cores & 4 G / executor .现在是 4个executor;2 cores & 4 G / executor。那么每次可并行处理的task由原来的 2*2 ,升级到现在的 4*2,并行执行能力直接翻倍。
二、增加每个executor的逻辑cpu数量
三、增加每个executor的内存量
更多的内存,意味着更少的磁盘I/O操作
1、如果需要对RDD进行cache,那么更多的内存,就可以缓存更多的数据,将更少的数据写入磁盘,甚至不写入磁盘;
对于shuffle类操作,会需要内存来存放从map端读取的数据并进行聚合,更多的内存意味着减少甚至不需要磁盘I/O操作
2、task的具体执行,可能会创建很多的对象。如果内存比较少,就可能导致:
频繁的JVM堆内存不够用 => 频繁的GC进行垃圾回收(minor GC和full GC) => GC时,task直接停止运行
总结
- 分配最多的集群资源,最多意味着最优
- 在spark-submit时分配资源
- 并行执行能力 = 同时运行的tasks = executors * (cores/executor)
传说中的shuffle调优、扩大广播变量、调节数据本地化等待时长等邪门怪招都远不及分配更多的资源对性能提升来的猛烈-性能调优从最大化资源配置开始!
Snail此刻的心情,是舒畅滴。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









