






平台工程逐渐成为向企业团队交付云即服务(Cloud-as-a-Service)的实际方法。Gartner 预计,到 2026 年,80% 的软件工程企业将建立平台团队和内部开发者平台,为应用交付提供可重复使用的服务、组件和工具。虽然这一趋势听起来很理想,但现实是否如此呢?
01 共担责任将复杂性推给平台团队
事实上云提供商只负责平台堆栈的一小部分。云提供商承诺通过垂直整合的基础设施服务消除所有杂乱无章的工作,但这样我们就可以不考虑软件版本、组件兼容性、测试/验证等问题了吗?
然后出现了 Kubernetes,这是一种为灵活性而设计的工具,但不能或至少不应该垂直集成。其结果是出现了 Kubernetes 控制平面(如 EKS、GKE、AKS 和 OKE)以及一些托管附加组件(如 CoreDNS、CNI 和 KubeProxy)以及有关如何构建应用程序的一些指导。虽然这种方法为平台团队提供了引入新组件、附加组件和应用程序的灵活性,但这种灵活性的成本很高。平台团队发现他们需要负责在 Kubernetes 上运行的插件和应用程序的生命周期。这通常称为“共享责任模型”,在该模型中,客户需要使集群保持最新状态。
应用程序团队共同负责使应用程序保持最新状态,这会导致摩擦并浪费时间。一般来说,平台团队工作中进展最慢的部分需要更改应用程序。这是一个充满活力的生态系统,其中 API 和软件版本经常被弃用。让应用团队协调一致以优先考虑自己这边的变更会导致摩擦和延迟。因此,平台团队没有足够的时间来测试新的更改,从而导致错误、中断和失败,尤其是在升级期间。
因此,稳定性战胜了速度和创新。平台团队现在夹在云基础设施和应用程序业务逻辑之间,完成一项不可能完成的工作:向应用程序团队提供比昨天更好的功能和规模,并确保事情永远不会中断。这会抑制速度和创新,因为由于共同责任模型产生的摩擦和焦虑,这些团队绝大多数情况中都选择了稳定性。
02 平台的复杂性还在不断增加
Kubernetes 既复杂又灵活,但这种巨大的灵活性也带来了巨大的痛苦。CNCF 拥有一个极其丰富的组件和系统生态系统——1,000 多个组件、150 多个托管项目和来自 189 个国家的 178,000 多名贡献者。
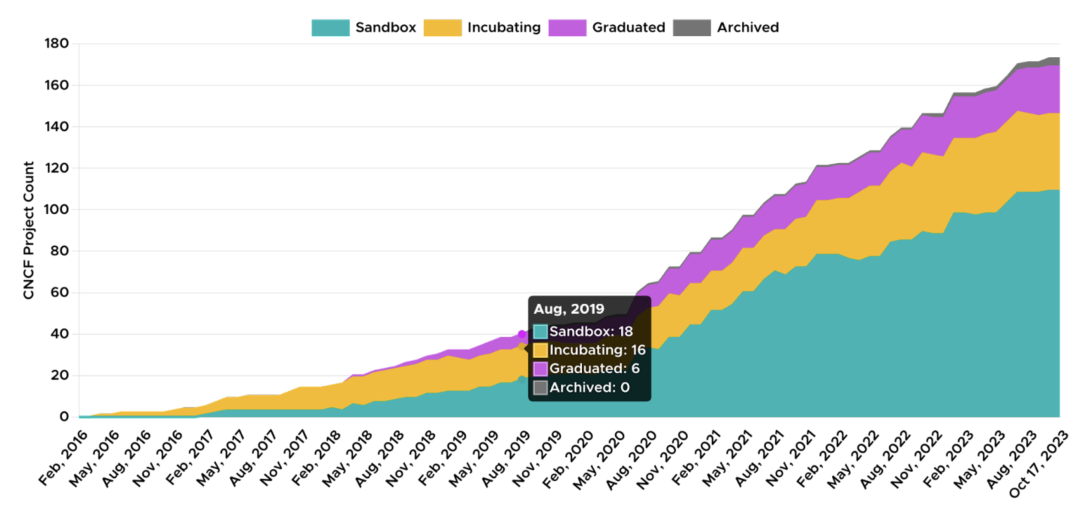
但这种前所未有的灵活性伴随着异常的复杂性。一个典型的集群至少有 20 个开源附加组件,这些附加组件具有复杂的依赖关系和独特的发布周期,必须由平台团队进行管理。一个典型的企业运行数百个集群,有些已经超过数千个集群。再加上至少五个主要云提供商和 Kubernetes 发行版,即使检索简单信息的复杂性也会呈指数级增长。
因此,平台团队通常重复无差异的繁重工作来回答琐碎的问题。全球每个平台团队都会重建电子表格、wiki、Slack 频道和一些自定义脚本来回答简单的问题,例如:我的集群上运行的 Kubernetes 版本是什么?我正在运行特定附加组件的多少个版本以及在哪里?集群的下一次升级何时到期?此次升级会影响哪些应用程序?
这种无差别的繁重工作使平台团队无暇回答更困难的问题,即所有附加组件和控制平面组件是否彼此兼容?该平台是否运行任何不受支持的软件版本?毕竟,大多数开源组件都只支持最新版本的。
03 变化是持续的且存在可用性风险
变化的驱动因素太多,但只有一个团队能影响变化。至少有四个驱动因素要求平台团队定期进行变更:
-
安全和合规团队希望在规定的 SLA 范围内修复漏洞。
-
应用程序团队希望在自己的软件交付时限内完成扩展、新功能交付和性能提升。
-
云提供商希望每个集群每年至少升级两次。
-
附加组件供应商每年发布三到四次更新,以跟上生态系统的发展。
所有这些变化的流入都必须由平台团队了解、确定优先级并执行,因为上述大多数团队从不互相交谈。
最大的变化是 Kubernetes 升级,这从来都不是一件简单的事情。每个集群每年至少进行两次 Kubernetes 升级,并且需要数月的准备工作和规划。企业领导者经常想知道为什么 Kubernetes 升级不能像 iOS 升级一样——点击一个按钮,获取新版本,然后一切正常。
结果就是,由于变化会造成破坏,因此实施变化需要很长时间。避免破坏事情的最简单方法就是什么也不做,这正是大多数团队最终所做的。他们知道,即使完成简单的任务也会导致大量工作,并且最终仍可能导致失败和中断,因此他们宁可采取安全平稳的方法。因此,唯一需要完成的任务就是强制执行的任务,例如修复关键安全漏洞、升级不再支持的 Kubernetes 版本等等。
04 团队无法快速实现自动化以支持后续任务
即使您的基础设施规模不断扩大,员工数量的增长也是不可持续的。与基础设施成比例地增加员工数量不符合平台团队的章程和愿景。自动化是答案,而实际情况是,企业常常将其他任务优先级排在前面而非自动化项目。
而且,不能把希望只寄托在招聘上。即使能拿到人手,平台人才也极其稀缺。最近的研究表明,您直接需要的两个角色位于最想要的三个软件职位中:云工程师和 DevOps 工程师。因此,招聘是一种希望,而不是一种策略——尤其是如果你不是一家大型科技公司的话。
同时,培训成本太高且耗时。如果您雇用经验不足的团队成员,则大部分培训都是在工作中进行的,这会占用工程师的宝贵时间。
最优秀的团队成员会投入到关键路径任务中,缺乏经验的员工队伍则会导致现有的具有最佳判断力的团队成员在每项任务中都陷入困境。其中大多数都是重复的任务,例如阅读发行说明、关注开源社区并参与其中,以及与云提供商的支持、产品和工程团队交谈。这种运维开销没有时间进行创新、架构改进或战略思考,而这些本来应该是这些团队成员的主要工作。在不知不觉中,最好的工程师就会过度劳累,并对组织中的单点故障感到疲倦。
因此,团队倦怠还可能会迫使企业雇用第三方服务,这也有其自身的一系列挑战和考虑因素。
05 Reactive 事件响应必要但有限
如今的平台团队依靠可观察性、监控和警报系统来减少响应延迟、提高消防效率并最大限度地减少故障影响。不幸的是,这也会导致很多问题。
这种方法意味着任何潜在的缓解措施首先需要经历事故带来的痛苦。此外,必须投入时间在网上筛选大量信息,以了解其他人是否也遇到过同样的故障,如果有,他们是如何解决的。整个过程依赖于大量的手动工作和工程资源,无法保证类似的错误和中断不会再次发生。也可见,自动化始终处于次要地位。
06 打破孤岛,无缝共享
公司的平台团队似乎不可能解决这些长期挑战,但我们相信,如果我们让平台团队能够相互“集体学习”,汲取彼此的智慧,避免彼此的错误,这些挑战是有可能被克服的。实现这一目标的技术解决方案应确保:
-
平台工程师可以从网上提供的非结构化信息中学习,而不必包揽所有的事情,例如阅读墙壁和文本墙壁只是为了更新基础设施中的单个组件,通过 CLI 和 API 跟踪版本,与 GitHub 项目维护人员交谈等。
-
不同平台团队之间的孤岛被打破,因此学习内容(风险、事后分析、根本原因等)能够以编程方式无缝共享,而无需任何团队付出任何额外的努力。















 2819
2819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









