







 本文介绍了一种使用Python的requests和re库自动化爬取网络小说的方法,从目标网站获取书名、章节及内容,清洗数据并保存为txt文件。通过实际代码演示了整个过程,包括获取小说列表、章节链接及内容的解析。
本文介绍了一种使用Python的requests和re库自动化爬取网络小说的方法,从目标网站获取书名、章节及内容,清洗数据并保存为txt文件。通过实际代码演示了整个过程,包括获取小说列表、章节链接及内容的解析。
前言:代码百分百手打,无抄袭
整理一下思路
1.向目标网站发起请求,获取书名,章节,内容
2.拿到内容后清洗
3.将清洗后的数据存入txt文件
用到的库:requests,re目标网站新笔趣阁
获取每一本书的url

点击全部小说
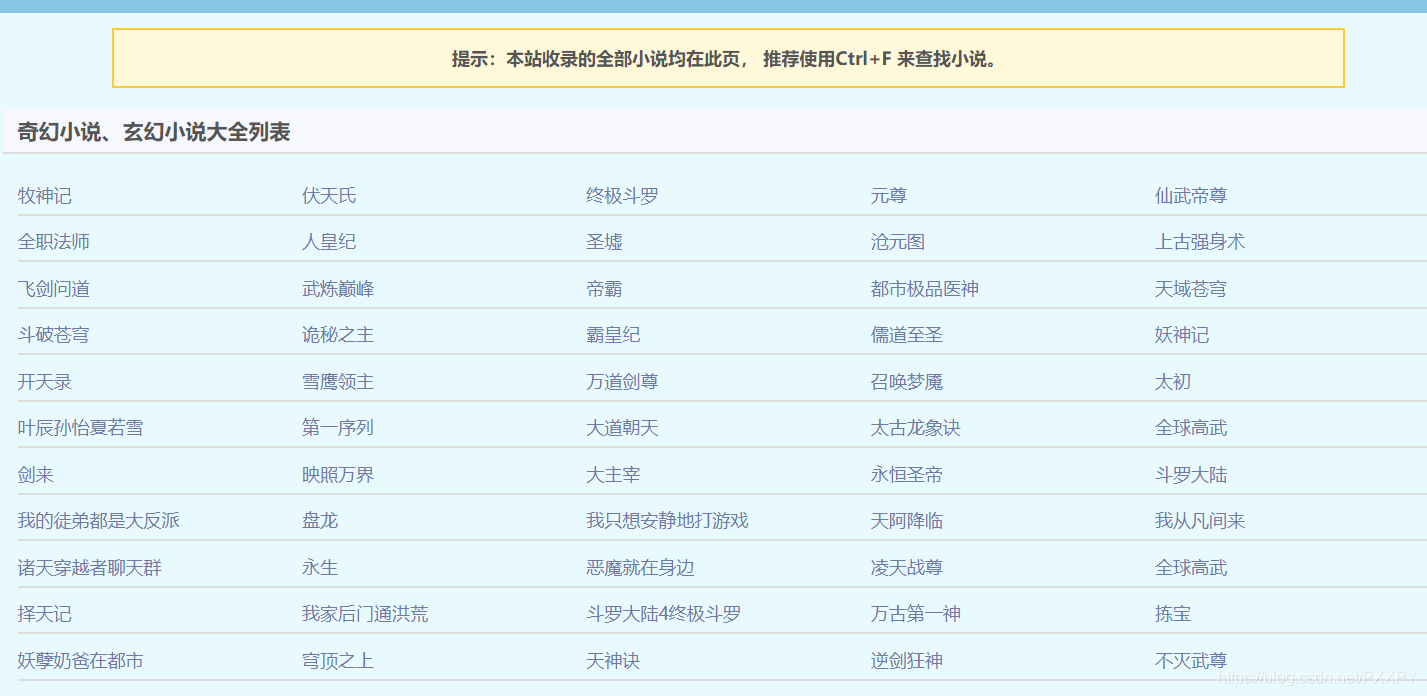
查看源代码寻找书籍url,名称
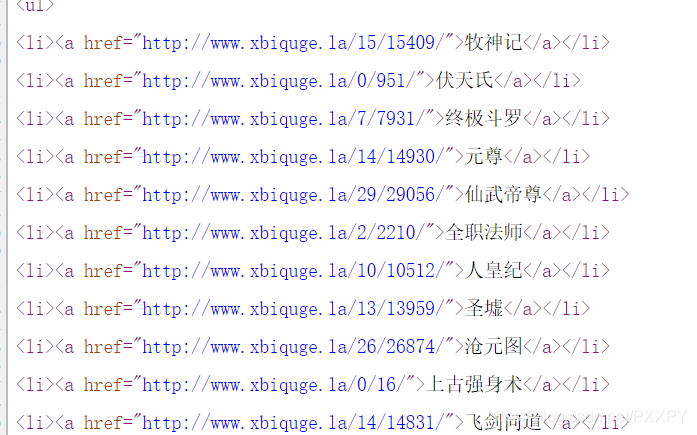
l进入小说详细页
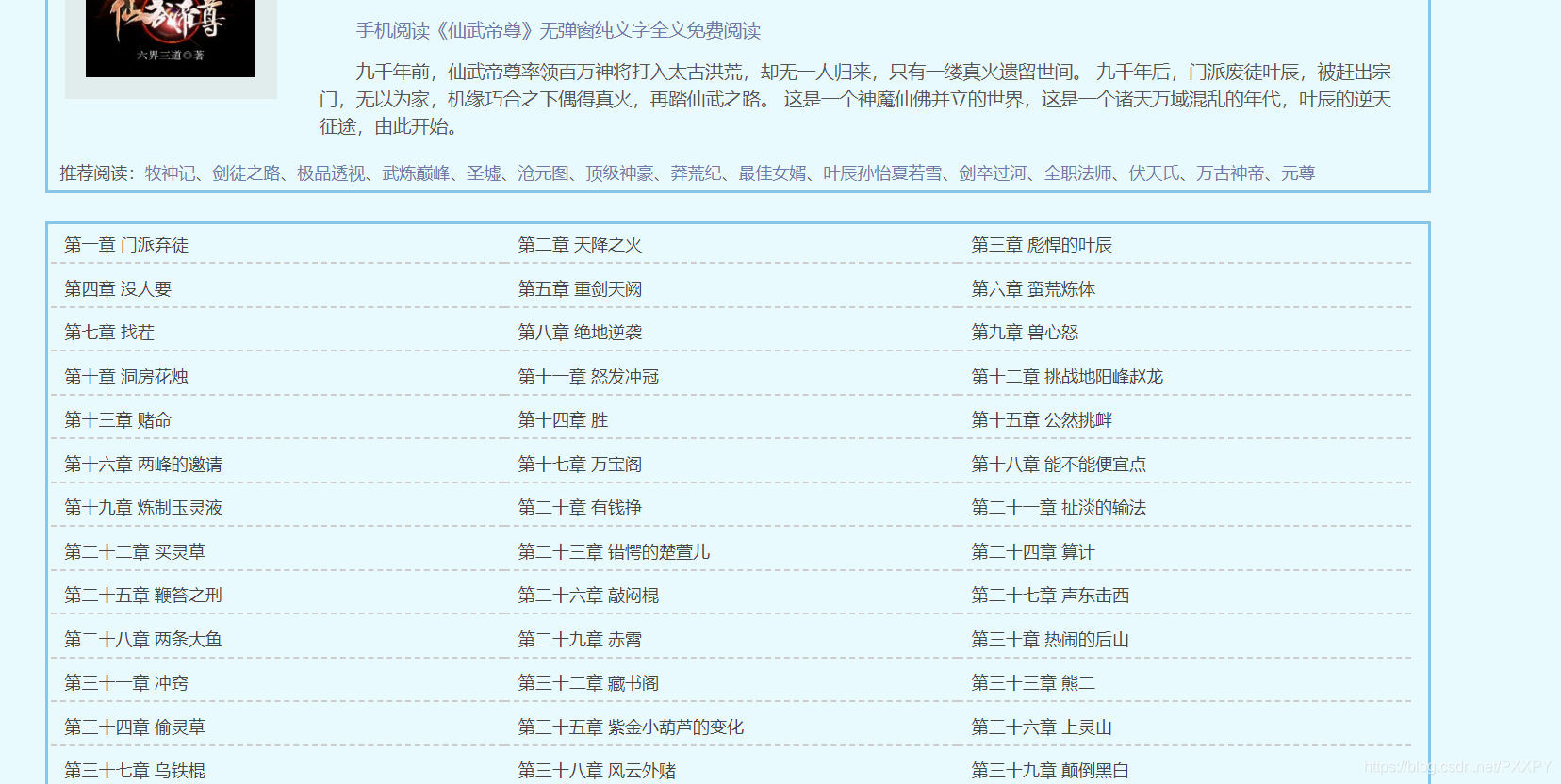
查看页面源代码,寻找章节url

获取小说详细内容
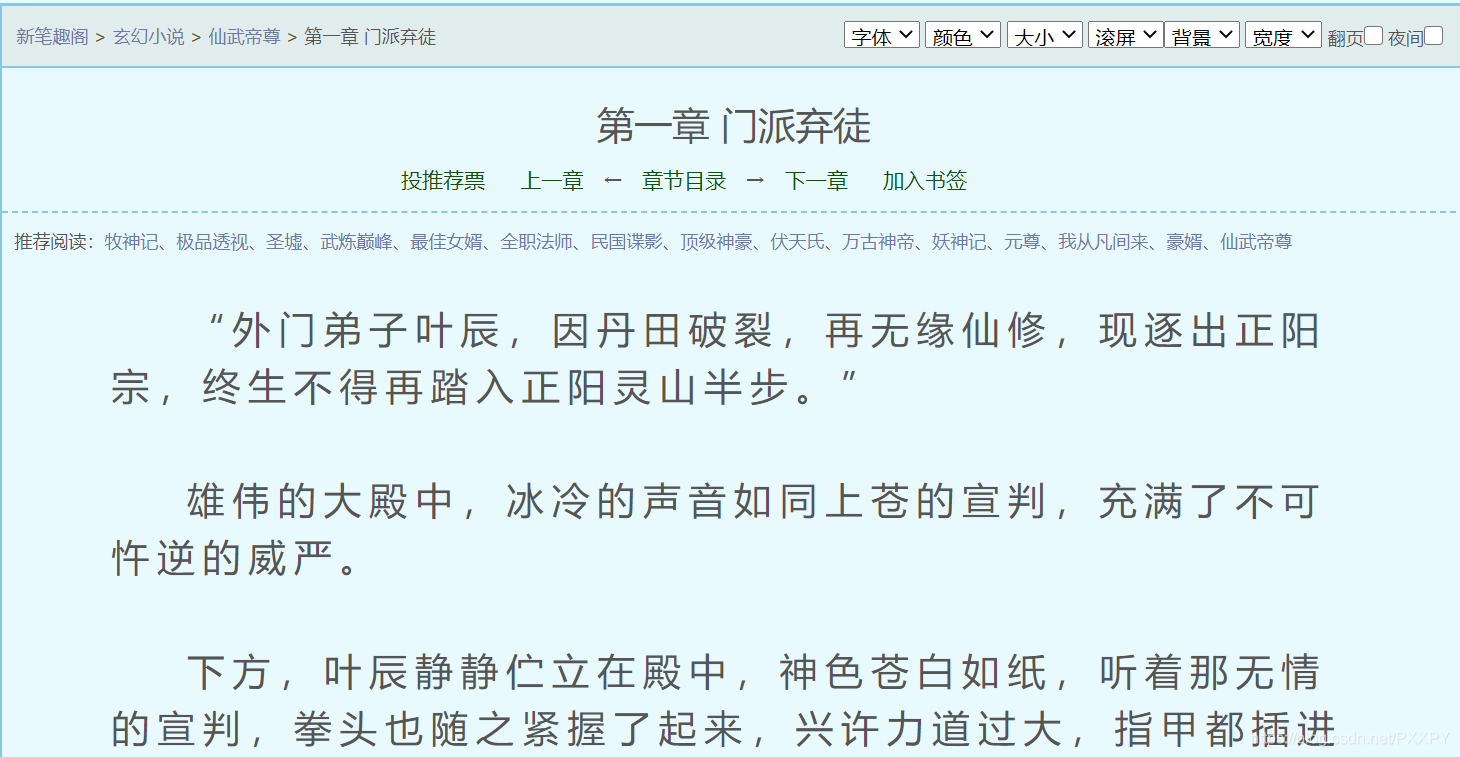

然后清洗,写入txt文件
代码贴上,实测可用人头担保🤔
import requests
import re
import time
all_info=''
url='http://www.xbiquge.la/xiaoshuodaquan/'
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 Edg/84.0.522.40'}
html=requests.get(url=url,headers=headers)
html=html.text
books_info=re.findall('<div class="novellist">(.*?)</ul></div>',html,re.S)
for book_info in books_info:
book_info=re.findall('<li><a href="(.*?)">(.*?)</a></li>',book_info,re.S)
for book_url,book_name in book_info:
html=requests.get(url=book_url,headers=headers)
html.encoding='utf-8'
html=html.text
chapter=re.findall('<div id="list">(.*?)</dl>',html,re.S)
for chapter_list in chapter:
chapter_info=re.findall("<dd><a href='(.*?)' >(.*?)</a></dd>",chapter_list,re.S)
for chapter_url,chapter_name in chapter_info:
chapter_url='http://www.xbiquge.la/{}'.format(chapter_url)
html=requests.get(url=chapter_url,headers=headers)
html.encoding='utf-8'
html=html.text
infos=re.findall('<div id="content">(.*?)</div>',html)
info=str(infos)
info=info.replace(' ','')
info=info.replace(r'\r<br />','')
info=info.replace(r'<br />','')
info=info.replace(r'&ldquo;','')
info=info.replace('amp;','')
info=info.replace('ldquo;','')
info=info.replace('rdquo;','')
info=info.replace('gt;','')
info=info.replace(r'/p&','')
info=info.replace('</p>','')
info=info.replace(r'&/p&','')
info=info.replace(r'<p>','')
info=info.replace(r'</a>','')
print('='*40)
print('正在下载'+book_name+chapter_name)
print('='*40)
f=open(book_name+'.txt','a',encoding='utf-8')
f.write(info)
f.close()
time.sleep(2)
效果图,再也不用担心闹书荒😝


由于未使用多进程,速度有点慢,别在意,下篇出个多进程…(* ̄0 ̄)ノ


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









